基于BERT-BiLSTM-CRF的突发公共卫生事件抽取研究*
2022-06-14李敬明朱家明
石 磊,李敬明,朱家明
(安徽财经大学)
0 引言
爆发于2019 年的新冠疫情是人类历史上最大规模的突发公共卫生事件,对人类社会的经济、政治造成了深远的影响,而且至今没有得到控制.党的十九届五中全会提出,要完善突发公共卫生事件监测预警机制,提高应对突发公共卫生事件的能力.事件抽取是自然语言处理领域的研究热点之一,其任务是从非结构化的事件文本中自动抽取出结构化的事件信息[1].在包含突发公共卫生事件的新闻、微博等自然语言文本中,由于存在复杂的语法、句法甚至网络用语等情况,难以直接对文本中的事件进行识别和分析.突发公共卫生事件抽取,是借助事件抽取技术从原本非结构化的突发公共卫生事件相关的文本中,识别事件类型、抽取事件要素,为分析和决策工作提供结构化信息,对突发公共卫生事件的检测、预警、统计等方面有着重要意义.目前,针对突发公共卫生事件抽取的研究成果较少,存在的主要问题是缺乏事件定义标准,以及抽取方法落后,导致抽取效果不理想.对此,需要先定义突发公共卫生事件的类型和结构,在此基础上提出基于BERT-BiLSTM-CRF 的管道式事件抽取模型,并构建语料对模型进行验证.
1 事件定义及语料构建
1.1 事件定义
事件的定义是事件抽取任务的基础,它可以提供结构化的事件框架,从而为事件抽取模型的设计和训练提供标准[2]. ACE2005(Automatic Content Extraction,自动内容抽取会议)定义了8 种事件类型和33 种子类型,是事件抽取研究的通用标准[3].但ACE2005 所定义的事件类型中没有包含突发公共卫生相关事件,不适合该领域的研究.由于事件类型和领域知识关系密切,因此有必要对突发公共卫生事件及其结构做出定义.根据中国《突发公共卫生事件应急条例》第二条的定义,突发公共卫生事件包括重大传染病疫情、群体性不明原因疾病、重大食物和职业中毒以及其他严重影响公众健康的事件[4].基于上述定义以及2020 年的新冠疫情,在参考ACE2005标准和相关研究的基础上,可以定义出突发公共卫生事件的8 种子事件类型,以及每种子事件的论元结构,见表1.

表1 突发公共卫生子事件类型及论元结构
从表1 可以看出,主体、客体、时间和地点是一般事件的基本论元,对于特殊事件则在此基础上做出调整.在感染、中毒和传播事件中,主体一般指人,客体一般指病毒、细菌、化学物质等;在检测、隔离、诊治和措施事件中,主体和客体分别指“实施者”和“实施对象”;在检测和诊治事件中,为了更加清晰地描述事件,增加了“结果”论元;在隔离和措施事件增加了“原因”论元.和ACE2005定义的死亡事件不同,突发公共卫生领域的死亡事件一般是由疾病或生化危害所致,这里用“原因”取代客体会更加合理.
基于上述事件定义,事件抽取模型将先对事件文本进行分类,再基于分类结果标注出触发词和论元,最后识别论元类型并填入到以触发词为核心的插槽(slot)中,从而完成事件的结构化抽取.值得注意的是,一个事件中未必会出现所有事件要素,因此模型也不必抽取所有论元.
1.2 语料构建
在移动互联网时代,由于微博的长度限制和高时效性特点,适合用作舆情分析等文本挖掘任务的语料,因此同样适用于构建突发公共卫生事件抽取的语料集.实验语料主要采集自新浪微博,采集范围限定为2020 年至今的传染病、中毒等相关话题.观察发现,实验语料的平均长度小于100 字符(新浪微博的长度限制为140 字符),结构以单句为主,且每条语料的事件主题单一.为简化问题,将每条语料作为单句处理,且仅考虑主要事件.因此将所有事件语料定义为单句、单个触发词、唯一事件类型.根据语料定义和模型要求对采集到的语料进行筛选和清洗,最后得到包含2000 条语料的实验语料集.
1.3 语料标注
事件抽取模型属于监督学习范畴,因此必须人工标注训练语料.事件语料的标注采用BIO方法[5].由于中文BERT模型是以字符作为输入数据的基本元素,因此事件语料在标注时也以字符作为基本单位.B-X 表示该字符所在片段属于X类型并且该字符位于此片段的开头;I-X 表示该字符所在片段属于X 类型并且该字符位于此片段的中间;O 表示该字符不属于任何类型.例如,用B-Trigger和I-Trigger分别标注“触发词”的开头和中间字符,用B-Subject和I-Subject分别标注“客体”的开头和中间字符.另外,每条语料的事件类型为9 种类型(8 种子事件类型+未知类型)之一,标注在语料首部.示例语料标注如图1 所示.

图1 突发公共卫生事件语料标注示例
2 模型构建
从理论上说,事件抽取任务包含4 个子任务:触发词识别、事件类型分类、论元识别和角色分类[5].事件抽取的多任务特性决定了模型在结构上可以是管道方式(pipeline)或联合方式(joint).管道方式为每个子任务设计独立的模型,模型间通过输入输出关系连接起来;联合方式则是设计1 个模型,同时服务于多个子任务.一般认为,管道方式存在误差传播问题,而联合方式可以促进子任务之间的交互.然而陈丹琦等[6]在关系抽取任务中使用管道模型,超越了之前所有的联合模型,说明适合的管道设计在特定任务上是有优势的.受此启发,事件抽取模型在预训练语言模型BERT的基础上分为3 个部分:事件分类模型、触发词及论元标注模型以及论元角色分类模型,并通过管道方式连接,模型结构如图2 所示.
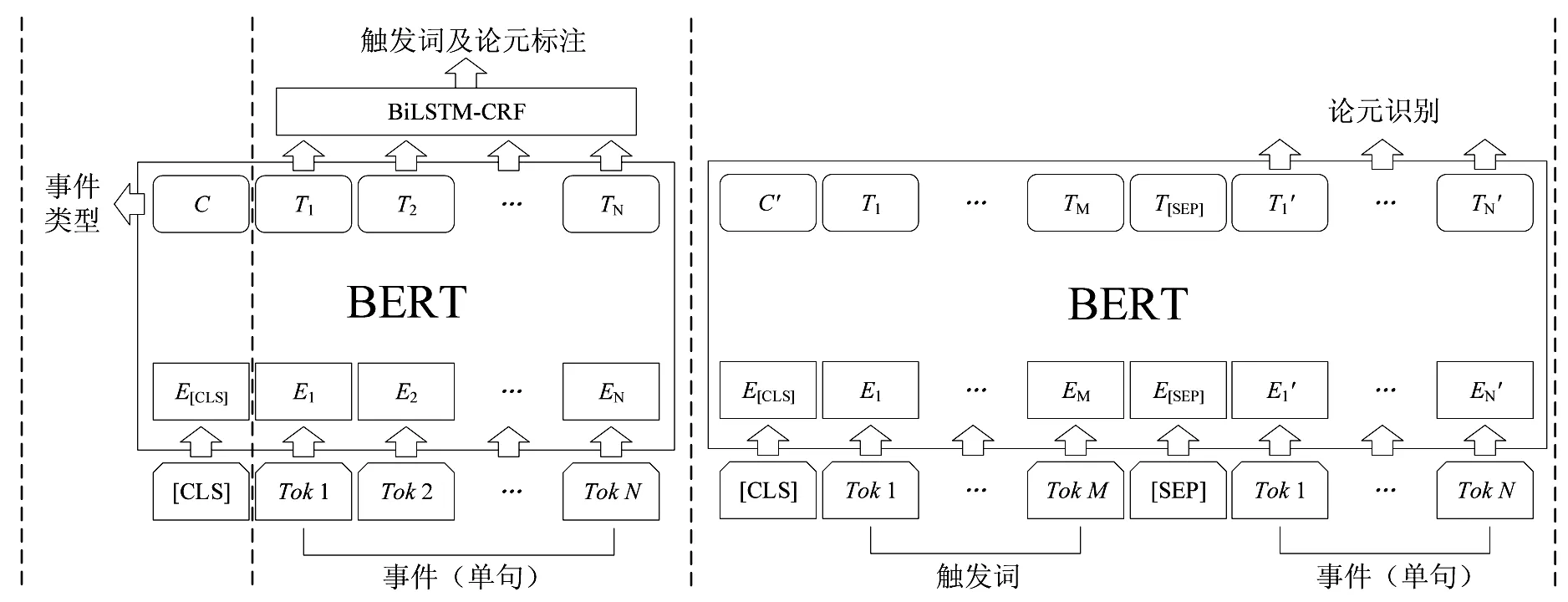
图2 基于BERT-BiLSTM-CRF的突发公共卫生事件抽取模型结构图
2.1 预训练语言模型BERT
BERT是Devlin等[7]于2018 年提出的基于Transformer[8]的预训练语言模型,在序列标注等11 项自然语言处理任务中取得了当时的最佳成绩.选择BERT作为该研究的基础模型主要出于以下两方面的考虑:一是BERT的核心,即Transformer编码器,由多头自注意力模块、前馈神经网络模块、位置编码、求和与归一化、残差连接,5 个模块组成,多项研究表明Transformer 编码器提取文本特征的能力优于LSTM 或CNN 编码器;二是BERT 所集成的两种预训练任务,MLM(Masked Language Model,掩码语言模型)和NSP(Next Sentence Prediction,下一句预测),使得BERT成为高效的迁移学习模型,经过任务微调后适用于句对关系判断、单句分类、问答、序列标注等任务,即使新任务的训练数据集较小,基于预训练结果,也能产生不错的效果.
2.2 事件分类模型
首先将事件文本分割后得到的字符序列{[CLS],Tok1,Tok2,…,TokN}输入BERT 模型,其中[CLS]是文本分类标识;经位置嵌入后到字符向量序列{E[CLS],E1,E2,…,EN};再经过BERT内部的Transformer 编码后得到文本的语义向量C和元素序列{T1,T2,…,TN}.
事件分类模型本质上要解决的是文本多分类问题,即将文本的语义向量C 经softmax 输出为9 种类型(8 种子事件类型+未知类型)之一,其条件概率如公式(1)所示:

其中K表示类别数量,pk表示样本属于类别k的概率,yk表示模型的预测结果,若预测出的类别和事件标注相同,则yk=1,否则yk=0.
2.3 触发词及论元标注模型
触发词及论元标注模型要解决的是一个标准的序列标注问题,目的是识别出触发词和所有可能的论元.由于CRF能够通过考虑相邻标签的关系获得一个全局最优的标签序列,因此模型在BERT的基础上添加BiLSTM-CRF 输出层[9].先将元素序列{T1,T2,…,TN}输入到BiLSTM网络中,得到隐层序列{h1,h2,…,hN},如公式(3)所示;再经线性变换后输入到CRF中进行标注,见公式(4)(5).
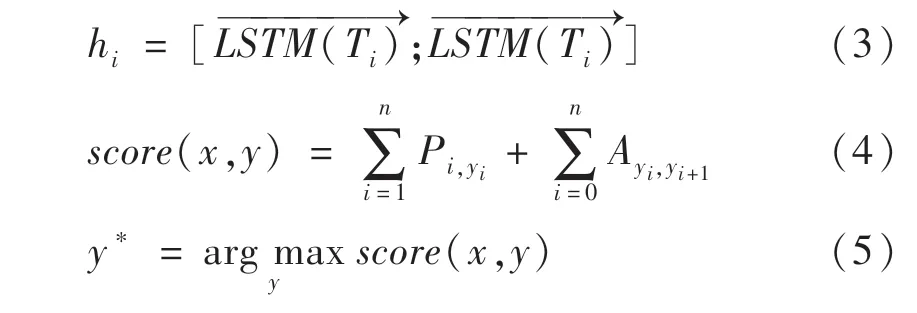
其中Pi,yi为第i个位置网络结构的预测输出为yi的概率,即为初始分数;Ayi,yi+1为从yi到yi+1的转移概率,即为转换分数;选择最大概率序列y*作为输出.
2.4 论元识别模型
由于先前假设单一事件文本仅包含单一事件和单一触发词,触发词及论元标注模型可以识别出唯一触发词,但无法确定标注出的论元是否和触发词相关,因此需要进一步解决论元识别问题.论元识别模型是在已知触发词的基础上,识别出所有和触发词相关的论元,因此可以将该任务看作是句对(词对)关系判断问题,即每个论元和触发词相关与否.利用BERT的任务微调特性,将触发词和标注后的事件文本连接后同时输入模型,中间用[SEP]分隔;经过BERT编码后,用softmax输出每个论元的起始位置的分类结果,其条件概率如公式(6)所示,损失函数如公式(7)所示.识别完成后,将论元填入以触发词为中心的槽中,从而完成事件的结构化抽取.
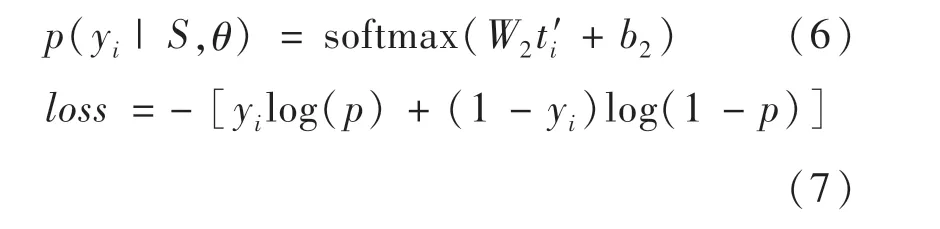
3 实验及结果分析
3.1 实验数据及参数设置
实验数据是标注后的语料集,包含2000 条语料.将数据集按9 ∶1 划分为训练集和测试集,即训练集1800 条,测试集200 条.
实验环境基于Tensorflow框架搭建,考虑到实验的数据量不大,选择谷歌的BERT-Base-Chinese作为基础模型,因为相较于Large 版本,Base版本的调试效率更高.经过大量实验,不断调整和优化参数,最终选取了实验结果最好的参数设置,具体参数见表2.

表2 实验参数设置
3.2 实验设计及评价指标
为验证模型的有效性,设计了4 组对比实验.包括经典的BiLSTM-CRF模型,引入注意力机制的BiLSTM-Attention-CRF模型,以及该文提出的BERT-CRF和BERT-BiLSTM-CRF模型.
实验采用精确率(P)、召回率(R)和F1值作为模型的评价指标,各指标的计算公式如(8)~(10)所示:

其中TP代表预测正确的正例数目,FP代表预测错误的负例数目,FN代表预测错误的正例数目.
3.3 实验结果及分析
根据表3所示的对比实验结果,发现引入了注意力机制的BiLSTM-Attention-CRF模型优于BiLSTM-CRF模型,因为注意力机制可以帮助模型找出事件文本中和当前预测最相关的部分,忽略其他部分,从而缓解BiLSTM的长距离依赖问题.基于BERT的BERT-CRF 和BERT-BiLSTM-CRF模型,在没有引入注意力机制的情况下仍然获得最优表现,可能的原因是BERT本身就是多头自注意力(Multi-Head Self-Attention)网络,自注意力机制具备事件文本内部元素之间关系的建模能力,可以帮助模型更好地利用上下文语义信息[10].值得注意的是引入BiLSTM的BERT-BiLSTM-CRF模型仅以略微优势领先BERT-CRF模型,可见BiLSTM的作用不明显,略微的差距可以通过BERT模型可微调的特性来弥补,从而可以进一步证明BERT模型的先进性和对事件抽取任务的适用性.
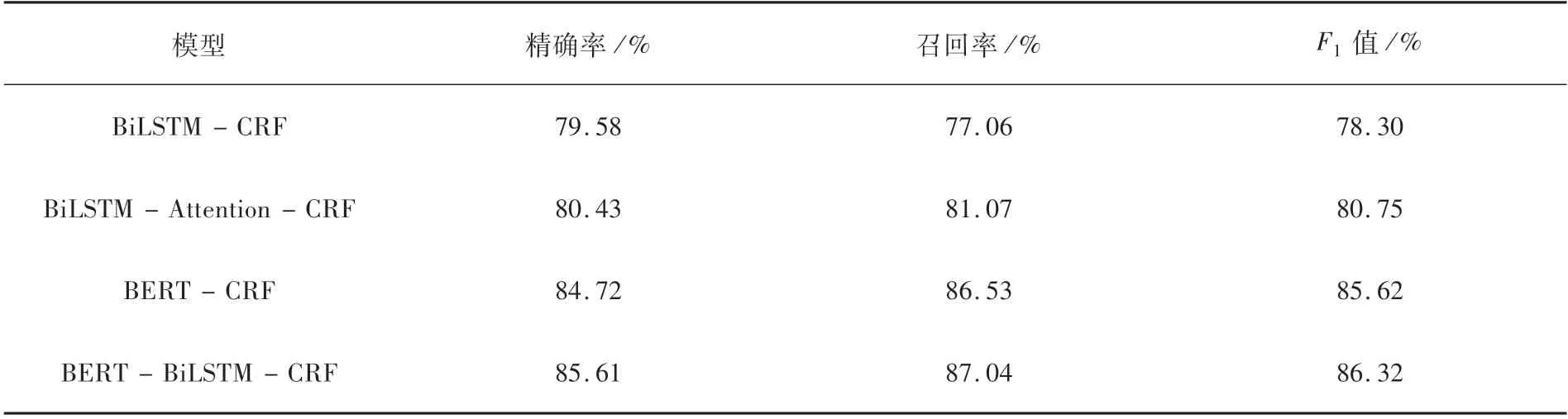
表3 对比实验结果
4 结束语
基于BERT-BiLSTM-CRF 的突发公共卫生事件抽取模型,以管道方式连接事件分类、触发词识别和论元角色分类,完成了事件的结构化抽取.该模型结构清晰,可解释性强,充分发挥了BERT模型的特点.对比实验的结果证明了该模型的可行性以及相对其他模型的优势.模型的不足之处在于管道连接方式不可避免地会加大误差累积.后续将聚焦于联合抽取模型的研究,以期进一步提升事件抽取效果.
