基于遗传算法优化BP 神经网络的电信客户流失预测研究
2022-06-13张三妞
张三妞
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
随着世界经济的发展,客户流失问题逐渐受到人们的重视[1-3]。电信公司为此提出了3个主要策略,即获得新客户、追加销售现有客户以及延长客户的保留期。考虑到每种策略的投资回报率(Return on Investment,RoI)价值,延长客户的保留期是最有利的策略,其成本远低于获得新客户[4-6]。对于电信客户流失预测,国内外有大量的研究。为了处理电信客户流失的多维数据,肖等人提出了一种集成方法,将元代价敏感学习、半监督学习以及Bagging 集成等技术相结合,设计了代价敏感的客户流失预测半监督集成模型[7]。张等人将生存分析与深度学习理论相结合,即运用深度学习模型对电信客户流失数据进行建模,根据建模中客户的生存状态和时间对电信客户进行解析,从而判断出客户是否流失[8]。在电信客户流失预测中,客户信息特征具有多维性和复杂性,数据处理对客户流失预测的准确性具有较大影响。基于以上问题,结合国内外电信客户流失预测算法,提出遗传算法优化BP 神经网络的耦合模型。
1 相关技术原理
1.1 BP 神经网络原理
反向传播(Back Propagation,BP)神经网络于1986 年由Rumelhart 和McCelland 领导的科学家小组提出,是一种按误差逆传播算法训练的多层前馈神经网络。BP 神经网络能学习和存贮大量的输入与输出模式映射关系,无需事前揭示描述这种映射关系的数学方程。其学习规则是使用最速下降法,通过反向传播不断调整网络的权值和阈值,从而使网络的误差平方和达到最小[9]。BP 神经网络拓扑结构可分为3层,分别是输入层、隐藏层以及输出层。其中,隐藏层的神经元个数计算公式为:

式中:m为输入层节点的个数,n为输出层节点的个数,a一般取1 ~10 内的整数。隐藏层的个数越多,误差范围越小。
1.2 遗传优化算法
遗传算法是模拟达尔文生物进化论中自然选择和遗传学机理等生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。依据BP 神经网络的拓扑结构,确定优化BP 神经网络权值阈值的参数个数,从而确定遗传算法中个体的编码长度,再根据适应度函数计算个体的适应值,经过选择、交叉、变异操作得到最优的权值阈值。
1.2.1 轮盘赌算法
轮盘赌算法是为了防止适应度数值较小群体中的个体被直接淘汰而提出的,每一个个体被选中的概率与其适应度函数值大小成正比关系。适应度数值越高,它被选中的概率就越大。设某一个体xi的适应度值为f(xi),则部分被选中的概率为:

累计概率为:

式中:xi和xj都表示某个个体。
首先,计算每个部分的被选中概率p(xi)和累积概率q(xi)。其次,随机生成一个数组m,数组m中的元素取值范围为[0,1]。若累积概率q(xi)大于数组中的元素m[i],则个体xi被选中;若小于m[i],则比较下一个个体xi+1,直至选出一个个体为止。最后,若需要选择N个个体,则将上述步骤重复N次即可。
1.2.2 两点交叉算法
两点交叉是指在个体染色体中随机设置两个交叉点,然后进行部分基因交换。先从编码串中不定向选出两个交叉点,再对两个交叉点进行部分染色体交叉,交叉后产生新个体,如图1 所示。其中,左侧为交叉前的个体,右侧为两点交叉后产生的新个体。

图1 两点交叉示例
1.2.3 高斯变异
高斯变异是指进行变异操作时,用符合均值为μ、方差为S2的正态分布的一个随机数替代原有的基因值。根据正态分布的特性,高斯变异重点搜索原个体附近的某个局部区域。高斯概率密度公式为:
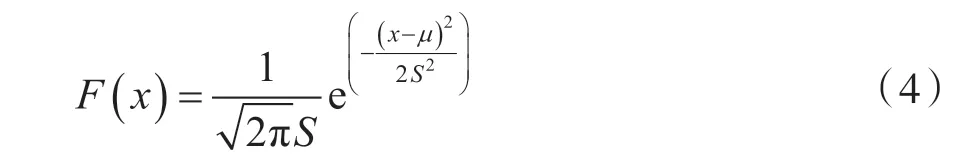
其中,标准高斯概率密度的μ和S分别设置为0 和1。高斯变异不仅提高了优化算法的优化精度,而且有利于跳出局部最优区域。
2 模型与实验分析
本文使用的电信流失客户数据集来自Kaggle 平台,共有7 043条用户样本,其中未流失客户5 174人、流失客户1 869 人。每条样本包含21 列电信客户特征,特征信息可分为客户基本信息、开通业务信息、签署的合约信息以及目标变量。遗传算法优化BP 神经网络的电信客户流失模型如图2 所示。
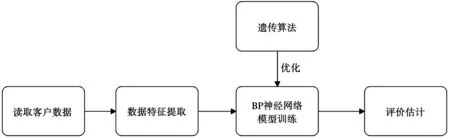
图2 遗传算法优化BP 神经网络的电信客户流失模型
读取电信客户流失数据并进行特征提取,特征提取过程包括可视化分析、皮尔逊相关系数判断、独热编码处理以及归一化处理。电信客户流失数据信息特征如表1 所示。
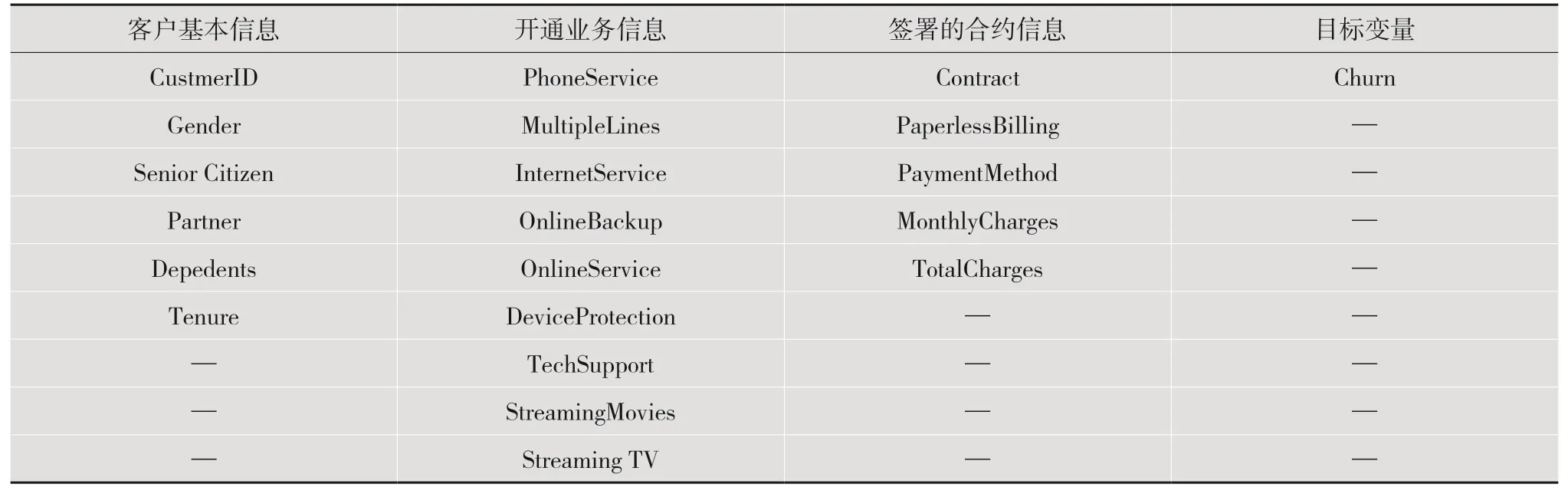
表1 电信客户流失数据信息特征
皮尔逊相关系数(Pearson correlation coefficient,PCCs)又称皮尔逊积矩相关系数,两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商,取值范围为[-1,1][10]。根据电信客户流失数据信息,TotalCharges、Tenure 以及MonthlyCharges特征为数值特征,对这3 列特征建立皮尔逊相关系数矩阵,如图3 所示。

图3 皮尔逊相关系数矩阵
由图3 可知,TotalCharges 与Tenure、Monthly Charges 相关性较大,相关系数超过0.6,容易引起预测结果降低,故删除TotalCharges 冗余特征。基于遗传算法优化BP 神经网络的电信客户流失预测中,将电信客户流失真实值分别与BP 模型预测值、遗传算法优化BP 模型(GABP)的预测值进行对比,结果如图4 所示。

图4 BP 模型与遗传算法优化BP 模型的预测值和真实值对比
电信客户流失数据经归一化处理后的目标变量存在两个数值1 和0,其中1 表示流失的客户,0 表示未流失的客户。根据图4,基于遗传算法优化BP 神经网络的电信客户流失预测值比基于BP神经网络的电信客户流失模型的预测值更接近于真实值。BP 模型与遗传算法优化BP 模型的预测值和真实值误差对比如图4 所示。
模型预测值与真实值的误差越接近0,模型效果越好。当误差为0,表示预测值等于真实值。由图5 可知,基于遗传算法优化BP 神经网络的电信客户流失预测误差比基于BP 神经网络的电信客户流失预测误差更接近于0,表示遗传算法优化BP神经网络的模型效果好于单独的BP 神经网络模型。将两种模型的平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)进行对比,MAE 和RMAE 的值越小越好,具体结果如表2 所示。

图5 BP 模型与遗传算法优化BP 模型的预测值和真实值误差对比

表2 模型对比分析
根据表2,GABP 模型的准确率高于BP 模型的准确率,在电信客户流失预测中具有更优的效果。
3 结 语
通过遗传算法优化BP 神经网络来构建电信客户流失模型,采用数据可视化分析法去除冗余特征,同时运用皮尔逊相关系数去除相关系数较大的特征,提高了数据预测的精准性。运用遗传算法优化BP 神经网络的权值阈值,其结果优于传统BP 神经网络,提高了电信客户流失的分类准确率和预测精准性,具有一定的使用价值。
