基于LUR模型下PM2.5浓度的空间分布模拟分析
2022-06-10杨明亮朱宗玖
杨明亮,朱宗玖
(安徽理工大学电气与信息工程学院,安徽 淮南 232001)
0 引言
随着我国经济快速发展,大气颗粒物中空气动力学直径≤2.5µm的细颗粒物(PM2.5)已成为我国大气的首要污染物[1]。PM2.5不仅会造成雾霾影响城市道路交通,也会对人体的呼吸道以及肺部器官造成严重危害[2]。因此,对PM2.5进行监测分析具有重要意义。
目前国内外对PM2.5监测的手段是以传统地面监测站点为主,但是监测站的建设成本过高,且大多分布在城市地区,不能有效覆盖更广泛的区域[3]。采用无人机和车载移动监测也是一种重要的方式,但存在无法长时间监测PM2.5浓度的问题[4]。国内外学者开始利用有限的监测站数据并通过神经网络、大气数值模拟、扩散模型、土地利用回归模型(LUR)等方法进行研究区内PM2.5浓度的空间分布模拟[5]。其中LUR模型最早由Briggs等[6]提出,是一种利用监测站点数据及周边相关影响因素结合ArcGIS平台预测研究区域PM2.5浓度空间分布的方法。LUR模型不仅考虑到影响PM2.5的因素,而且得到的模拟值和空间分辨率也较高,已成为大气污染物浓度模拟的最有效方法之一[7]。
当前,国际上已广泛运用LUR模型对PM2.5和NOX污染物浓度的空间分布模拟,且模拟效果较好[8,9]。我国由于对大气污染防治的起步较晚,国内只有李杰[10]、阳海鸥等[11]及王佳佳等[12]利用LUR模型成功地模拟了不同城市的PM2.5浓度空间分布。但是,与城市尺度下PM2.5浓度空间分布模拟相比,区域尺度下PM2.5浓度空间分布模拟易受到不同地区之间自然环境、社会经济、污染排放等因素影响,模拟难度较大。目前,国内只有少量学者提出了对区域尺度PM2.5浓度的模拟[13]。因此,本文将LUR模型应用到安徽省污染较重的皖北地区,研究LUR模型在区域尺度下的适用性,并进一步分析PM2.5浓度在不同季节下空间分布特征。
1 材料与研究方法
1.1 研究区概况
皖北地区位于长江三角洲,由安徽省北部的宿州、淮北、亳州、阜阳、蚌埠、淮南六市组成。地形以平原为主,气候适宜,拥有丰富煤、铁、铜等矿产资源。近年来皖北抓住“一带一路”的发展机遇,经济发展迅速。伴随经济发展,其环境问题日渐严重,空气质量恶化,给当地居民的生活环境造成严重影响。因此,本研究选择安徽省污染较重的皖北地区,通过分析每个季节以及年均PM2.5浓度,建立LUR模型模拟皖北地区PM2.5浓度,为皖北地区大气污染治理提供科学依据。
1.2 数据来源及预处理
1.2.1 PM2.5浓度及气象数据
安徽省皖北地区共有23个国控空气质量监测站点和20个省控空气质量监测站点,研究区及站点分布如图1所示。其中蚌埠田家炳中学和宿州远航博物馆的国控站点由于改建,导致2018年数据缺失,故本研究采用剩余21个国控站点和20个省控站点2018年1–12月的空气质量数据(数据来自安徽省生态环境厅http://sthjt.ah.gov.cn/index.html)。通过对数据汇总统计,得到41个监测站点的四季和年均PM2.5浓度数据。气象数据来源于国家气象科学数据中心(http://data.cma.cn/),采集皖北地区23个气象站点2018年1–12月观测数据,包括气压、风速、气温、相对湿度、降水量共5类,通过对数据计算统计得到气象数据的四季和年均值。
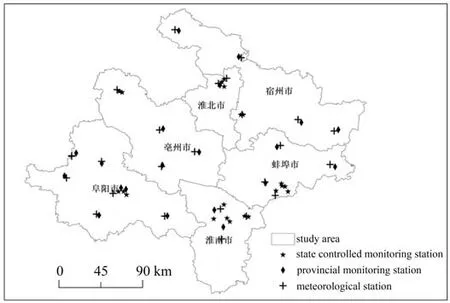
图1 研究区域以及站点分布Fig.1 Distribution of study area and stations
1.2.2 土地利用类型
采用清华大学宫鹏等[14]结合10 m分辨率Sentinel-2影像开发出的2017全球10 m分辨率土地利用数据,参考皖北地区土地利用的具体情况,利用Arcgis10.6将皖北地区的土地利用类型分成农田、森林、草地、灌木、湿地、水体、不透水面、裸地8类,如图2所示。
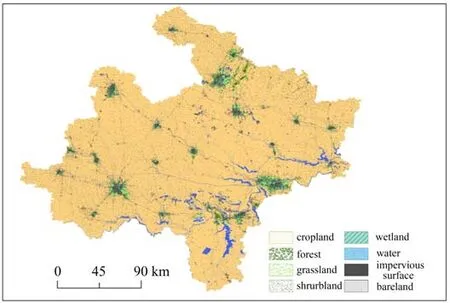
图2 皖北地区土地利用分布Fig.2 Distribution of land use in Northern Anhui
1.2.3 道路数据
道路数据来自于OpenStreetMap的矢量路网,通过对矢量路网进行裁剪、拼接得到了研究区的路网数据。选取其中的高速公路、干道、一级公路、二级公路和三级公路5类数据。
1.2.4 其他数据
高程数据通过数字高程模型DEM获取,采用来自Earth Data的中国陆域范围30 m分辨率的数据,数据源是NASADEM。人口数据来自于由美国能源部橡树岭国家实验室(ORNL)开发的Land Scan人口密度数据集。污染源数据来自于安徽省环保厅印发的2017年国家重点监控企业名单,通过高德地图定位经纬度,选择研究区内的38家国家重点废气污染企业。
1.2.5 缓冲区半径及影响因子
参考目前区域尺度缓冲区半径的设置[15],选取0.5、1、1.5、2、3、4、5 km作为缓冲区半径。利用Arcgis10.6以监测站点为中心,分别生成土地利用、道路、污染源的缓冲区,统计缓冲区土地利用类型的面积作为土地利用因子,道路分类的长度作为道路因子,废气污染企业个数作为污染源因子。气象因子通过Kriging插值法对气象站点的四季和年均值进行插值模拟,监测站所在位置的数据即为气象因子。高程因子和人口因子直接提取监测站点所在位置的高程及人口数,最终得到土地利用、道路、污染源、气象、高程及人口这6类影响因子。
1.3 研究方法
1.3.1 LUR模型构建
采用的LUR模型基于ArcGIS与SPSS平台构建,该多元回归模型监测的PM2.5浓度为因变量,道路、气象、DEM高程、人口和污染源等对PM2.5浓度可能产生影响的因素为自变量。LUR模型的基本形式为

式中y为因变量,即监测到的PM2.5四季和年均值;x1,x2,...,xn为自变量,即各类影响因子;α1,α2,...,αn为待定系数;β为随机变量。构建LUR模型一般有两类算法,一种是前向算法[16],一种是后向算法[17,18]。为了降低模型出现同一变量不同缓冲区(如1.5 km和2 km草地面积)共线性的可能性,也为了提高模型的精确性,最终采用广泛使用的后向算法构建模型,步骤如下:
1)在SPSS中对土地利用因子、道路因子、污染源因子98(14×7)个,加上气象因子、人口因子及高程因子7(5+1+1)个,共105个自变量进行双变量相关性分析;2)去除与假定相关性质(表1)不同以及相关性异常的自变量;3)在剩余的自变量中找出每类影响因子同PM2.5浓度相关性最高的变量(如2 km二级公路长度);4)去除同类影响因子中同PM2.5浓度相关性最高的变量皮尔森系数大于0.6的变量(如3 km二级公路长度);5)把剩余的变量与PM2.5浓度在SPSS中进行逐步线性回归,即可得到LUR模型。

表1 模型中自变量描述Table 1 Description of the independent variables in the model
1.3.2 模型验证
目前国内外学者关于验证LUR模型的方法主要有以下五种。第一种是留一检测误差法[19],即只保留一个站点的数据,用其他站点的数据构建回归方程,对比保留站点的模拟值与实际值来验证模型的精度。这种方法简单易操作,但检测样本过于单一,结果不具有普遍性,简单来说就是一个站点的检测不足以验证模型精度的问题。第二种方法是留一交叉互验[20],即在上述留一检测误差的基础上,把每个监测站点都重复一遍。这种方法虽然繁琐,但可以有效验证模型精度,适用于少量监测站点的研究。第三种方法是直接用各站点的数据构建回归方程,对比模拟值和实际值[21]。这种对比方法简单明了,但是由于使用所有监测站点数据构建模型,模型的精度可能会受到影响。第四种方法是K折交叉验证[22,23],将监测站点分成k组,交叉验证k次,这种方法适用于监测站点过多、工作量过大的研究。第五种方法是留出验证法[24],即随机选取部分站点的数据作为验证数据,剩余站点数据进行训练。因为用于研究的站点数不多,故本研究采用留一交叉互验的方法,并通过调整R2、均方根误差(RMSE)、模拟精度R2这3项指标验证模型。
1.3.3 PM2.5浓度模拟
在ArcGIS中将皖北地区划分成5 km×5 km规则格网点,通过回归方程计算出PM2.5模拟浓度值给每个格网点赋值,再利用Kriging插值法就可以得到研究区的PM2.5浓度空间分布。
2 实验结果与讨论
2.1 PM2.5浓度统计
根据41个监测站2018年1–12月PM2.5的日均浓度数据计算出PM2.5月均浓度,结合我国PM2.5空气质量二级标准值(35µg·m−3)及世卫组织制定的第三阶段PM2.5年均浓度指导值(15µg·m−3),可以得到研究区PM2.5整体的变化趋势。由图3可知,皖北地区的PM2.5浓度整体偏高,41个监测站点的年均值为55µg·m−3,全年多数时间都超出国家空气质量二级标准浓度限值,更是大幅超出了世卫组织制定的第三阶段指导值,皖北地区空气质量问题不容乐观。

图3 PM2.5月均浓度变化Fig.3 Changing trend of monthly PM2.5concentration
2.2 双变量相关性分析
在SPSS中将PM2.5浓度与各影响因子进行双变量相关性分析,得到相关系数。由于变量过多,这里只列出进行多元线性回归的变量。如表2所示,不透水面、二级公路、三级公路、气压、人口、废气污染企业与PM2.5浓度呈正相关性;草地、湿地、水体、风速、相对湿度、降水量与PM2.5浓度呈负相关性,这与之前的假定相关性质(表1)基本一致。而与一些学者研究结果不同的是[25],研究区内森林、灌木及DEM高程却呈现与PM2.5浓度相关性不高的现象。分析其原因发现,这与皖北地区的地形有关,皖北地区以平原为主,地势平坦,森林及灌木覆盖面积较少,所以会呈现相关性不高的现象。
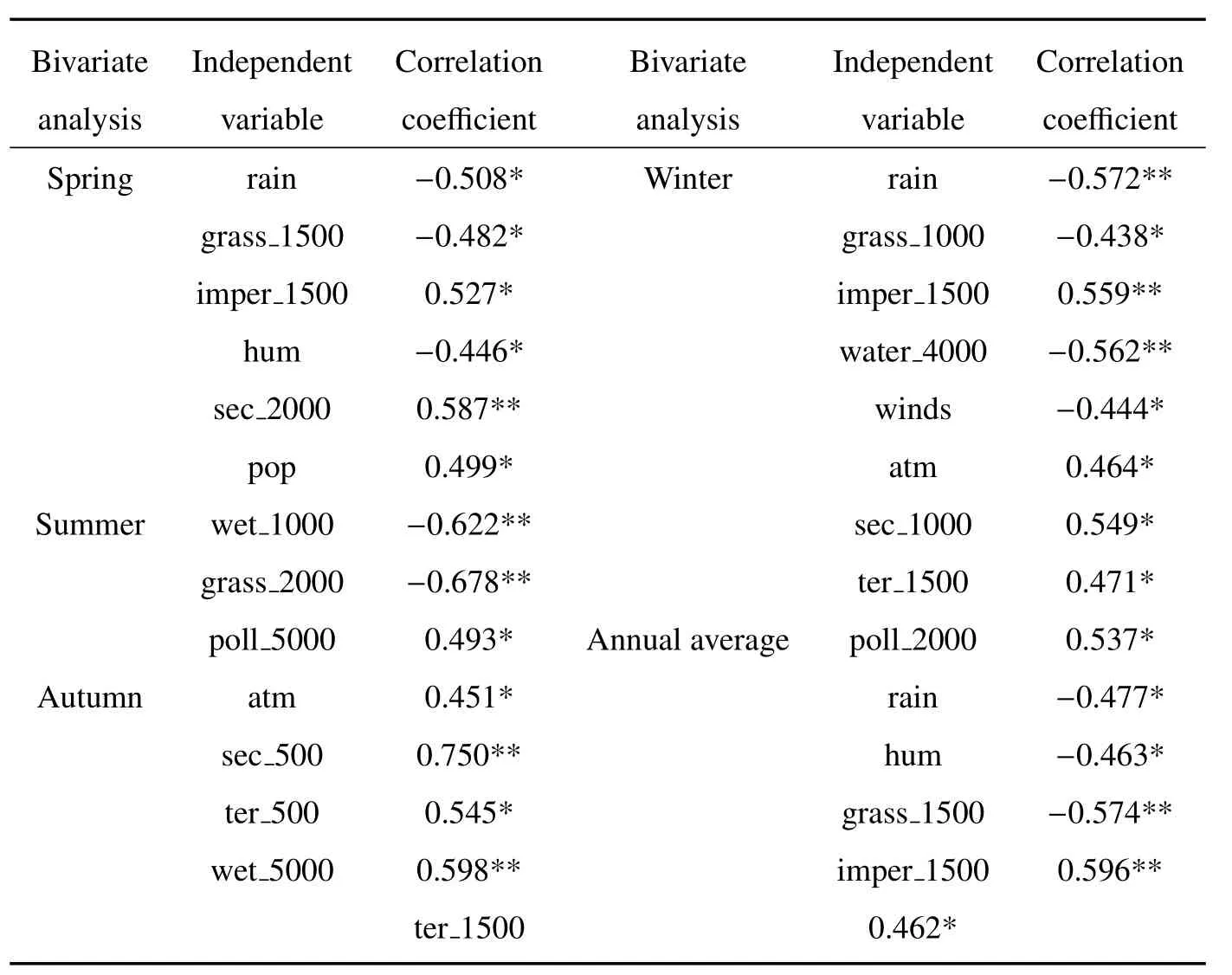
表2 PM2.5浓度与影响因子双变量相关分析结果Table 2 Result of bivariate correlation analysis between PM2.5concentration and impact factors
2.3 四季及年均LUR模型
建立LUR模型的过程中,考虑到PM2.5浓度受季节影响较大,因此采用春、夏、秋、冬及年均PM2.5浓度与相应的剩余变量建立了四季和年均LUR模型。模型的回归结果如表3所示,表中回归结果的各项参数介绍如下:1)B表示回归系数,是各个自变量在回归方程中的回归系数,正负值表示自变量对因变量有显著的正负向影响,但基于B并不能反映各个自变量对因变量影响程度的大小,需借助标准回归系数Beta,此时数值越大表示对自变量的影响更大;2)Standard Error是标准误差;3)t是T检验的值,用来计算P值;4)P即T检验的显著性检验P值,小于0.05则说明自变量对因变量具有显著影响;5)VIF是方差膨胀因子,用于共线性诊断,当0 通过表3中标准回归系数Beta可以看出各项进入LUR模型的自变量对回归结果的贡献率。春季LUR模型自变量贡献率从高到低分别为:降水量、人口数量、相对湿度、2 km缓冲区内二级公路长度;夏季LUR模型自变量贡献率从高到低分别为:2 km缓冲区内草地面积、1 km缓冲区内湿地面积、5 km缓冲区内废气污染企业个数;秋季LUR模型自变量贡献率从高到低分别为:气压、风速、0.5 km缓冲区内二级公路长度;冬季LUR模型自变量贡献率从高到低分别为:气压、风速;年均LUR模型自变量贡献率从高到低分别为:1.5 km缓冲区内草地面积、2 km缓冲区内废气污染企业个数、相对湿度、1.5 km缓冲区内三级公路长度、2 km缓冲区内湿地面积。其中道路因子参与春、秋、年均LUR模型的构建,且对研究区PM2.5浓度有加剧作用,原因是机动车排放的尾气及驾驶中产生的扬尘是PM2.5污染的重要来源[27];气象因子参与春、秋、冬及年均LUR模型的构建,其中降水量、相对湿度、风速对研究区PM2.5浓度具有抑制作用,原因是相对湿度增大会使大气颗粒物吸湿生长、变大,当相对湿度进一步增大,会加速颗粒物沉降[28,29];降水对大气颗粒物具有清除作用,导致了PM2.5浓度降低[30];风速大,对流旺盛,PM2.5不容易堆积,也可以降低PM2.5的浓度[31]。土地利用因子中的草地、湿地参与夏、年均LUR模型的构建,尤其是草地和湿地在夏季对PM2.5浓度影响很大,这与夏季湿地草木生长旺盛有很大关系。人口和废气污染企业对PM2.5浓度也具有加剧作用,这与废气污染企业超标排放有关,也与废气污染企业和人口密集区一般都处于城市地区(城市土地利用以建设用地为主,草地与湿地的覆盖面积较少)的情况有关[32]。 表3 PM2.5多元线性回归结果Table 3 The results of PM2.5stepwise multiple linear regression 模型最终回归结果的调整R2分别为 0.828(春)、0.731(夏)、0.831(秋)、0.775(冬)、0.892(年均),夏、冬LUR模型的影响因子整体可以解释70%以上PM2.5浓度的变化,春、秋、年均LUR模型的影响因子可以解释80%以上PM2.5浓度的变化,说明模型整体拟合程度较高,解释能力很强。 由于皖北地区监测站点数目不多,故模型验证的方法采用留一交叉互验的方法,将41个监测站点分成训练集(40个)和验证集(1个),用训练集构建模型,然后利用模型计算出验证集站点的PM2.5预测值,对比验证集的预测值与真实值,重复41次得到均方根误差(RMSE)与模拟精度R2。均方根误差RMSE分别为6.34 µg·m−3(春)、7.01 µg·m−3(夏)、6.28 µg·m−3(秋)、6.71 µg·m−3(冬)、5.33 µg·m−3(年均),模型验证散点图如图4所示。从图4可以看出,四季及年均LUR模型的模拟精度R2分别为0.825(春)、0.730(夏)、0.834(秋)、0.772(冬)、0.897(年均),年均LUR模型模拟精度最高,春、秋两季模拟精度其次,夏、冬两季最低。 图4 PM2.5监测值-预测值散点图。(a)春季;(b)夏季;(c)秋季;(d)冬季;(e)年均Fig.4 Scatter plots of observed versus predicted PM2.5concentration.(a)Spring;(b)summer;(c)autumn;(d)winter;(e)annual average 参考目前LUR模型研究结果,如许刚等[13]基于土地利用回归模型模拟京津冀PM2.5浓度空间分布的调整R2为0.805,均方根误差RMSE为14.2µg·m−3,模拟精度R2为0.79;宋万营等[25]基于LUR模型的大气PM2.5浓度分布模拟与人口暴露研究:以湖北省为例的调整R2为0.604,标准误差为5.97;与上述结果相比,本研究模型的调整R2解释性强,均方根误差RMSE误差小,模拟精度R2高,模型的精度可以得到保障。 为进一步分析皖北地区四季及年均PM2.5浓度的空间分布,在ArcGIS中将皖北地区划分成5 km×5 km规则格网点,采用回归方程计算出PM2.5模拟浓度值并给每个格网点进行赋值,再利用Kriging插值法得到皖北地区的PM2.5浓度空间分布。从图5(a)-(d)可以看出,不同季节下皖北地区PM2.5浓度呈现明显不同的空间分布特征,春、冬两季PM2.5污染主要集中在北部区域的亳州、淮北、宿州3市,这是因为北部区域地势平坦,来自北方的大量污染颗粒物在风力的汇聚作用下,导致了PM2.5浓度升高[33]。夏季PM2.5污染最严重区域是拥有大量煤矿的淮南市,其PM2.5浓度高的原因与煤矿开采中产生的扬尘有关[34]。秋季PM2.5污染主要集中在以农业生产为主的阜阳市,其原因是秋耕秸秆的大量燃烧使得PM2.5浓度升高[35]。 为验证模型模拟空间分布的准确性,将LUR模型计算得出的年均PM2.5预测值与监测站点监测的年均PM2.5真实值进行插值,得到如图5(e)所示的年均PM2.5预测值空间分布图和如图5(f)所示的年均PM2.5真实值空间分布图。通过对比插值后的浓度空间分布图,可以看出年均PM2.5预测值分布和年均PM2.5真实值分布基本保持一致,整体呈现北高、南低的现象。 该研究的局限性在于皖北地区监测站点数量不多,一定程度限制了模型的精度。而且通过研究对比5个LUR模型的模拟精度可以看出,春、秋及年均模拟精度较高,夏、冬两季相对较差,这可能与周边区域的污染迁移有一定联系[36]。夏冬两季周边一些经济发达的地区燃煤量大幅上升,风向带动大量污染颗粒物进入研究区,导致局部区域PM2.5浓度大幅上升,进而影响了研究区的模拟精度。因此在区域尺度LUR模型建模时,不仅要考虑到研究区内的影响因素,还要考虑周边区域以及风向因子的影响,进一步解析PM2.5污染产生的源头。同时本研究构建LUR模型时采用的是线性回归的方法,线性回归不能完全解释PM2.5浓度与影响因子之间的联系,可以考虑使用非线性回归的方法构建模型,或者通过结合机器学习的算法改进LUR模型,也可以进一步扩展影响因子的类别以及突出时空分异来提升模型的解释性。 图5 皖北地区PM2.5浓度空间分布模拟与验证。(a)春季;(b)夏季;(c)秋季;(d)冬季;(e)年均预测;(f)年均真实Fig.5 Simulation and verification of spatial distribution of PM2.5concentration in Northern Anhui.(a)Spring;(b)summer;(c)autumn;(d)winter;(e)annual average forecast;(f)annual average real value 1)研究区PM2.5年平均浓度为55µg·m−3,超出国家年平均浓度标准35µg·m−3,更远超于世卫组织年平均浓度的10µg·m−3,研究区空气质量问题不容乐观。 2)在双变量相关性分析中,不透水面、二级公路、三级公路、气压、人口、废气污染企业与PM2.5浓度呈正相关性;草地、湿地、水体、风速、相对湿度、降水量与PM2.5浓度呈负相关性。研究区内森林、灌木及DEM高程与PM2.5浓度相关性不高,分析原因发现,与皖北地区的地形地貌有关。 3)建立的 LUR 模型调整R2分别为 0.828(春)、0.731(夏)、0.831(秋)、0.775(冬)、0.892(年均);均方根误差 RMSE 分别为 6.34 µg·m−3(春)、7.01 µg·m−3(夏)、6.28 µg·m−3(秋)、6.71 µg·m−3(冬)、5.33 µg·m−3(年均);模拟精度R2分别为 0.825(春)、0.730(夏)、0.834(秋)、0.772(冬)、0.897(年均),模型表现较好,具有较强的解释力。 4)模拟的PM2.5浓度整体呈现北高、南低的特点。此外,不同季节下呈现明显不同的空间分布特征,这与来自北方的大量污染颗粒物、当地的煤矿开采、秋耕秸秆燃烧等潜在污染源有关。

2.4 模型验证

2.5 四季及年均PM2.5模拟
3 讨论

4 结论
