基于空地信息互补的无人车路线规划
2022-06-10陆晨飞
陆晨飞,张 浩
(1.南京工业大学 机械与动力工程学院,江苏 南京 211800;2.江苏省工业装备数字制造及控制技术重点实验室,江苏 南京 211800)
人工智能和网络通信等技术的进步,推动着无人自主系统的不断发展。空地机器人协作是无人自主系统的关键部分。空地机器人协作在进行环境信息感知和任务规划时能够优势互补,空地机器人能为地面机器人提供近空环境信息,同时地面机器人也能搭载进行环境感知的重要传感设备,完成自主导航任务,到达指定目标区域。因此,在灾害救援方面,空地机器人协作能为恶劣环境下的救援提供更为安全可靠的解决方案;在军事领域,空地平台的构建更是提高了人们在地形侦察与野外作战方面的能力。
对此,国内外研究人员提出了不同方案,美国陆军研究实验室构建了空地机器人自主协作系统,通过在特定区域开展侦察任务,实现了待搜索目标的识别与定位[1]。美国弗吉尼亚理工大学无人系统实验室针对室外的局部地形,通过全球定位系统准确定位的同时,实现了地面无人车快速有效地自主导航[2]。兰州理工大学在室内小范围实验环境下,基于视觉感知,对空地协作下的机器人路径规划展开研究,进一步提高了地面机器人的自主导航性能[3]。以上国内外学者主要是针对空地机器人的环境探测、自主导航进行研究,但都是针对某个局部特定环境,对于大范围室外环境下的机器人自主协作与导航研究较少。在局部小范围情形下,地面机器人借助自身搭载的传感器所能观测到的环境特征有限,无法在短时间内对周围环境实现完整建模,因而地面机器人很难在全局上引导路径规划器规划合适路径,使得机器人在后期进行局部路径规划时容易陷入局部极值问题。对于室内等特定环境下的自主导航情形,机器人能够观测到的点、线等特征不易受光照变化和复杂地形制约,相反,在大范围室外场景中的点、线及纹理特征易受到光照变化限制,因此地面机器人在使用激光雷达等依赖于光反射原理获取环境特征数据的传感器对周围环境建模时,会引发错误的数据关联问题,难以满足导航要求;同时,大范围场景中的特征数量易受复杂地形影响而大幅下降,进而缺少有效的环境特征用于对周围环境建模。但是,机器人在大范围室外应用场景下的自主规划与对环境建模能力,对执行全面的地形侦察或大范围环境搜索任务都十分关键。因此,提升室外地面场景特征的稳健性和准确性,对机器人执行自主规划任务与提高其对周围环境进行完整观测的能力有很大帮助。
本文主要针对大范围室外场景条件下的全局环境特征提取方法进行研究。借助空中机器人完成目标物的检测定位及全局场景图像的获取,通过改进图像配准算法并借助图像融合,提升提取场景特征的鲁棒性,从而获得稳定有效的全局环境信息,指导地面无人车在大范围场景下的路线规划。
1 空地机器人协作框架
空地机器人协作流程如图1所示。由图1可知:空中无人机采集图像序列及视频帧图像,通过无线自组网电台,实现无人车和地面计算平台等节点的数据传输共享,地面计算平台同时负责硬件系统与软件方案的系统集成;通过机器人操作系统(ROS)实现基于消息通信的分布式节点组建与调用,基于目标检测深度网络的YOLO-v3模块完成对视频中目标物的检测任务[4-6];当无人机位于目标物上方并成功检测到目标物后,通过建立相机投影及坐标转换模型获取无人机全局坐标并发送至地面无人车;由图像拼接模块完成对无人机图像序列拼接,提取全局场景信息;由地面无人车的全局及局部路径规划模块,将速度指令输送至底盘执行机构,直到无人车到达目标位置。因此,本文主要对大范围室外场景下的目标物检测与定位、地面场景特征提取及无人车路线规划3个模块展开研究。
2 全局环境信息获取
2.1 图像序列获取与目标检测定位
在摄影测量方面,无人机展示出巨大潜力[5]。针对野外环境拍摄任务,四旋翼无人机可快速获取环境图像序列,而后对场景中的河流、道路、建筑物等采用数字图像处理,快速提取目标特征,且无须进行几何及相机位姿估计与调整。
根据无人机拍摄方式不同,图像序列的采集大致可分为定点全景图采集及多视点碎片化采集两种。由于地面无人车自主导航需要完整的全局环境,采用搭载有减震云台相机的四旋翼无人机对地面目标场景进行多次定点拍摄,图2所示的椭圆ABCD为无人机能够覆盖的最大拍摄区域,由于拍摄时飞行高度较高,可将所拍摄地面场景看作平面,同时保证了每次取景能够覆盖更多场景区域。
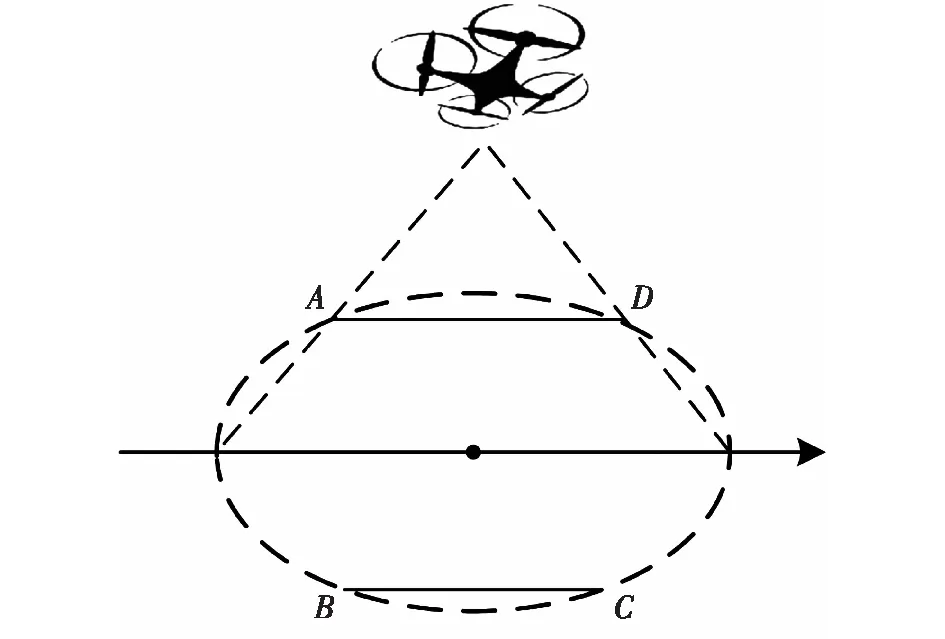
图2 无人机航拍图像获取Fig.2 Acquisition of images of unmanned aerial vehicle
在室外场景下,地面物体呈现出更多不确定性和复杂纹理,且易受光照强度变化影响,为目标检测任务带来一定困难。目标检测算法可分为基于特征、基于知识和模型及基于神经网络的算法,其中,基于神经网络的目标检测过程为通过建立目标检测模型,输入待分类图像,借助分类器实现目标识别。当前基于深度卷积网络的目标检测主要有两大类:一类为基于区域的检测方法,如Faster-RCNN(快速卷积神经网络)[7]与Corner-Net[8],该法将特征提取、区域预测等整合到一个网络中,有利于小目标检测但无法具备较好的实时性;另一类是基于回归的目标检测,如SSD[9]与YOLO[4,10-11],可选用基于Darknet框架下的YOLO-v3模块进行一次卷积操作,就可完成目标检测,在保证实时性的同时可获取较高准确率和鲁棒性。
YOLO-v3模块使用维度聚类提取所有类别对象所在边界框,选择logistic替代softmax分类器,通过回归计算每个边界框中物体类别的置信度。本文所需检测的物体类别与已有训练模型数据集相近,训练数据量相对较小,可通过迁移学习使用预训练模型,则改变所需的输出类别个数,就能在YOLO-v3已有的预训练权重基础上,针对场景中待检测目标数据集进行训练。将地面车辆作为检测目标,通过labellmg工具对所搜集的500张待检测图片进行标注,并生成对应注释文本文件,每张均含有待测图像边界框信息。在配备图形处理器(GPU)加速的Intel i7、主频3.2 GHz、16 GB内存计算机上训练模型,并进行测试,所得检测结果如图3所示。
使用准确率和召回率评价YOLO-v3的分类性能,在83.15%的准确率下,YOLO-v3仍有88.23%的较高召回率。同时,检测速度为每秒20帧,满足地面计算平台的实时性要求。
当无人机检测到目标后,还需根据像点位置计算地面目标物空间位置。在摄影测量学中,相机摄影中心与相片的转换关系由内方位元素,即相机内参矩阵(K)给出。描述摄影中心与相片在全局坐标系(XG,YG,ZG)(国际通用的以地球质心为原点的WGS-84坐标系)位姿关系的参数为外方位元素,由六自由度旋转与平移变换给出。减震云台相机在飞行拍摄过程中的姿态仍会发生平移与旋转运动,如图4所示,设外方位元素的3个角元素为(α,β,γ);3个线元素为(XO,YO,ZO),即相机光心的空间位置坐标;相机坐标系为(XC,YC,ZC),则转换关系如式(1)所示。
(1)
式中:R为由角元素构成的3×3旋转矩阵。

图3 YOLO-v3地面目标检测结果Fig.3 Ground target detection result by YOLO-v3
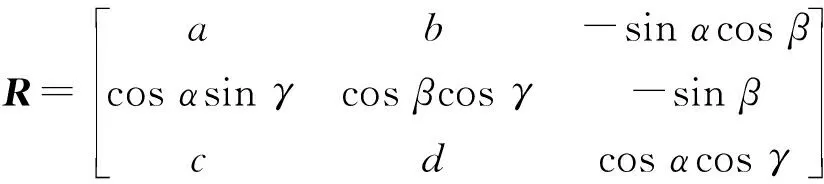
(2)
式中:a=cosαcosγ-sinαsinβsinγ,b=-cosαsinγ-sinαsinβcosγ,c=sinαcosγ+cosαsinβsinγ,d=-sinαsinγ+cosαsinβcosγ。
参考点Aref的全局坐标(XA,YA,0),在相机坐标系下的坐标(XAC,YAC,ZAC),Aref的像点坐标在物理成像平面内以齐次坐标形式表示为(u,v,1)T,由此可得到
(3)
由相机投影模型中全局坐标系与相机坐标系的转换关系可得矩阵方程(4)。
(4)
由式(2)解算得到无人机质心的全局坐标,即检测到目标物的实际空间位置。

图4 坐标转换模型Fig.4 Coordinate transformation model
2.2 场景图像拼接
四旋翼无人机在进行拍摄时,获取的原始图像是按照拍摄时间顺序排列的。通过控制无人机姿态和飞行速度,设置相同拍摄间隔,进行连续拍摄,最大程度上保证相邻图像之间具有视野重叠区域[12]。
图像拼接算法主要用于发现具有不同重叠程度图像间的对应关系,分为直接法和基于特征的拼接方法,进而融合生成全景图。直接法是基于灰度不变假设,根据像素灰度信息,通过最小化光度误差得到图像间的变换关系。基于特征的拼接方法是通过获取点、线或图像中的几何实体特征,建立匹配关系,来完成对图像的配准,选择基于特征的拼接策略时,可进一步融合配准后图像,最终获取完整的场景信息。
在平面特征匹配中,使用圆柱坐标投影建立相机的纯平移模型。通过式(5)和(6)将输入图像扭曲为圆柱坐标形式,可快速地使用纯平移模型配准图像。假设此时摄像头的光轴与Z轴对齐,相机焦距为f,则对应的图像某像素点(x,y)的射线形式为(x,y,f),将其投影到如图5所示的单位半径圆柱面上,可由角度(θ)和高度(h)参数化表示为

(5)
(6)
式中:x、y分别为图像中像素点的横纵坐标;x′、y′分别为像素点在圆柱坐标系下的横纵坐标;h为图像某像素点在单位半径圆柱面上的高度;s为尺度因子,通常设定其值与相机焦距(f)相等,以最大程度减少图像中心附近的失真。

图5 柱面坐标投影模型Fig.5 Projection model to cylindrical coordinates
基于特征的拼接方法中,特征点的提取和描述尤为关键。文献[13]提出了一种基于加速鲁棒特征(SURF)的快速概略拼接方法,该方法使用模板匹配获取匹配点对,具有较高的实时性,但点对的匹配缺乏一定的鲁棒性。文献[14]将待拼接图像按照重叠程度分为不同区域,实现了较高精度的配准与图像拼接,但无法保证每次拼接的稳定性。本文首先通过尺度不变特征变换(SIFT)算法提取图像中的关键点,并生成特征描述子[15],同时提出一种基于稳健映射函数模型的误匹配剔除方法,增强点对匹配的可重复性,同时为计算上述平移模型参数提供更多稳健的正确匹配点对,最终通过加权平均融合[16],去除拼接缝隙,进一步平滑所拼接图像。
Lowe[15]提出的SIFT特征点具有尺度及旋转不变性。SIFT在不同尺度的高斯差分图像上搜索局部极值,同时消除边缘响应值。通过比较局部图像像素梯度方向,确定关键点的主方向以获取旋转不变性,使得每一关键点都包含有尺度、位置及方向信息,并生成128维特征描述子,由最近邻搜索获得两幅图像的初始匹配点对。给定由SIFT获取的初始匹配点对(p,p′),其中p=(u,v),p′=(u′,v′)。支持向量回归方法(SVR)在函数估计等方面显示出稳健特性[17-20],本文首先使用SVR建立匹配点对映射模型,如式(7)所示。

(7)

计算进行一次匹配的映射残差(δi),如式(8)所示。
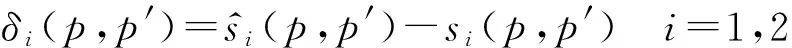
(8)
为进一步剔除误匹配点对,引入Tukey双权估计函数[9],根据计算所得的残差大小,为每一匹配点对分配合理权重,并设定阈值,剔除外点,完成映射函数估计的迭代过程。随着迭代次数的增加,映射函数模型将逐渐逼近真实的点对映射模型,迭代终止时所得点对集合即为提纯所得结果,图6为使用上述方法所得场景匹配效果,可以看出改进算法剔除了绝大部分误匹配点对。

图6 基于点对映射模型的场景图像配准结果Fig.6 Registration result of scene images based on correspondence function model
表1为保持SIFT算法中初始匹配点对的距离比值为0.8的情况下,对相同两幅待匹配图像连续提纯5次,并与随机采样一致性算法(RANSAC)[21]、M估计方法(M-estimators)[22]及最小中值法(LMedS)[23]的结果进行对比。匹配点对映射模型在保留更多正确匹配点对的同时,具有更好的匹配稳定性和可重复性,为之后变换模型的建立提供了更加准确的几何约束。

表1 同一匹配点对图像连续提纯5次的匹配数
在完成全景图初始拼接的过程中,通过改进配准方法,在拼接过程中提供了更多稳定匹配点对,提高了拼接的准确性。然而,由于拍摄场景仍存在光照强度或传感器误差等因素,造成融合结果出现色彩不连续或图像模糊。本文采用多频段图像融合,一方面该方法具有更加出色的细节捕获能力,另一方面也满足实时性要求。多频段图像融合将图像的信号分解为若干不同分辨率下的频段,然后对应在每个频段进行融合[24]。使用上述拼接方法及融合策略,对24张无人机航拍图进行测试,融合前后的效果对比如图7所示,可以看出融合后的拼接图像中局部模糊区域与拼接裂缝出现较少。

图7 多频段融合前后效果对比Fig.7 Comparison of results before and after multi-band fusion
2.3 场景特征提取
无人车在野外环境下进行自主导航的前提是已知场景的全局信息,通过自身搭载的传感器,进一步精确感知周围环境,从而完成自主导航。然而,室外场景特征通常都较为复杂,会随着场景的亮度变化而发生变化。Wang[25]提出使用最小二乘法与模板匹配提取特征,该方法可提取到质量较高且稳定的环境特征。Wu等[26]针对室外场景下光照变化的情形,提出使用全卷积网络训练高分辨率特征图,进行图像分割与特征提取。本文通过对拼接后的野外地形进行区域分割,通过形态学滤除背景噪声,从而得到全局场景信息。
图像分割是后期进行图像处理的首要步骤,其中,聚类分割方法是基于被选择的不同特征和相似性度量准则[27]建立的,所获得的每一个类都代表着不同的图像类别和属性。本文采用k(聚类中心数)-均值聚类方法对拼接图像进行分割。针对分割后所得图像仍具有大量噪声这一情况,对图像二值化处理后并采用中值滤波滤除噪声。通过形态学处理,采用开操作进一步平滑道路边缘轮廓,由闭操作填补分割过程中留下的图像间隙及孔洞。
使用无人机对大学校园室外场景采集图像序列,经上述拼接算法处理并调整大小后,所得全景图及灰度图如图8(a)与8(b)所示;由k-均值聚类方法对灰度图进行分割后如图8(c)所示,当聚类中心数取为4时,能够较好地将图中道路与树木等不同场景分割开来,但仍存在噪声;图8(d)为二值化操作后的图像;图8(e)为经过膨胀和腐蚀处理后的场景特征,可知已去除大部分背景噪声;图8(f)为进一步使用形态学组合运算去除细小物体,使得道路特征更为清晰,且足够平滑。

图8 全局场景特征提取Fig.8 Extraction of the global scene features
3 无人车路线规划
3.1 基于采样的路径规划方法
无人车实现室外自主导航主要分为3个部分:①针对整个全局目标区域的路线规划,为无人车提供全局道路信息;②车体自身的路径规划,该过程可将已规划完成的全局路线分段处理,再实现全局路径规划;③动态规划与避障,即通过自身携带的传感器进行局部的路径规划与避障操作。文献[28]提出的MHA*(Multi-heuristic A*)算法及文献[29]提出的A*-Connect算法均使用了网格搜索方法,并构建了启发式函数,实现全局路径规划。然而,基于分辨率完备性的网格搜索算法需要提前对环境进行显式建模,很难完成复杂环境下的规划任务;相反,基于采样的规划算法,不需要对环境的障碍物进行精确建模,其状态空间为机器人所有可能出现的平移或旋转运动的位姿集合,即构成了位形空间,此时,地面机器人可看作是其中一点,则整个运动规划问题变为从机器人的初始位形到目标位形中寻找一条无碰路径。因此,引入基于采样的规划算法,为地面无人车规划出全局环境下的行进路线,从而为后期进行自主避障与动态路径规划提供可靠的全局引导信息。
概率路线图法(PRM)是由Elbanhawi等[30]提出的。传统PRM方法的实现主要分为两个阶段:离线学习阶段及路径搜索阶段。离线学习阶段完成路线图的构建,对位形空间进行一定时间的随机采样,保留自由空间中的采样点,丢弃处于障碍物空间的采样点;在路径搜索阶段采用多查询策略,所使用的路径搜索算法可以为A*或其他搜索算法[30]。采样策略使得PRM方法能够在复杂环境下快速找到可行解,然而由于采样点存在随机性,其生成路径通常具有较多转折点(图9),对于具有动力学约束的地面机器人,很难满足其动态特性。

图9 多查询PRMFig.9 Multi-query PRM
3.2 改进算法及仿真分析
针对传统PRM方法在路径搜索阶段存在较多转折点这一问题,同时为了权衡路径规划效率,本文引入了基于网格搜索的滑动窗口方法(DWA)[31],其轨迹评价函数的基本形式如式(9)所示。
G(v,w)=k1×heading(e,w)+k2×dist(e,w)+
k3×velocity(e,w)
(9)
式中:G(e,w)为生成路径的轨迹评分,heading(e,w)为行进方位角评价函数,dist(e,w)为当前轨迹与最近的障碍物之间的距离,velocity(e,w)为当前行进轨迹的速度大小,e为搜索时的行进速度,w为行进方位角,k1、k2、k3分别为各个评价指标的权重系数。
DWA根据评价函数计算一组轨迹中的得分最大值,从而挑选出一条最优行进轨迹。根据PRM方法生成路径,着重针对查询阶段中的启发式函数进行改进。传统PRM方法使用节点间欧氏距离度量一个节点向下一个节点搜寻的代价,而改进启发式函数通过引入滑动窗口的方法形成评价函数,当进行下一次路径搜索时,综合考虑选择新节点加入队列的目标偏向代价、距离代价及路径转折代价,如式(10)所示。
H(x,y)=k1×bias(x,y)+k2×dist(x,y)+k3×turn(x,y)
(10)
式中:H(x,y)为一个节点向下一个节点进行路径搜寻的总代价;bias(x,y)为目标偏差函数,该函数给出所选择的新节点与目标点的偏差角度θ,偏差越小,该项得分越高,dist(x,y)函数为新节点到目标点的欧氏距离,距离目标点更近,得分越高;turn(x,y)为路径转折函数,可用于计算在加入新节点后,与前一个进入队列的节点形成的路径转折角度(δ),考虑路径转折角度的大小,能够保证路径存在的同时,减少路径转折次数。
为验证改进算法的有效性,使用设置500×500的像素地图进行仿真,一次采样数为50个点,3个权重系数分别设置为0.5、0.3、0.5,3种地图下对比结果如图10所示。由图10可知:在A、B、C 3种模拟场景下,通过改进的PRM方法,减少了路径中不必要的转折点,有利于缩短规划路径长度和计算时间。

图10 3种地图下的改进算法仿真结果对比Fig.10 Simulation comparison of the improved algorithm under 3 maps
表2列出了针对3种复杂场景下,分别使用传统PRM方法、快速搜索随机树(RRT)[32]、Visibility PRM[33]和改进PRM方法,连续进行50次路径规划的仿真结果对比。由表2可知:改进启发式函数的规划方法在路径转折点数量上有所减少,同时,由于改进算法进一步权衡了目标偏向和节点间距离度量比重,路径长度总体上获得了17%的改进效果,转折点数量的减少也可节省一部分规划时间。
3.3 全局场景路线规划
图11为由上述方法规划地面无人车行进至目标区域的全局路线,蓝色与红色星号分别代表地面无人车的起始和目标位置。由图11可知:所用方法选择了最短路线进行规划,为地面无人车后期进行自主导航提供了一条安全可行的全局路线。

图11 全局场景下的路线规划结果Fig.11 Route planning result under global scene

表2 50次规划仿真对比结果
4 平台搭建与测试
硬件平台由如图12所示的地面无人车、大疆精灵3A四轴飞行器、无线自组网电台以及配备Intel i7、3.2 GHz主频、16 GB内存的计算机等构成。地面无人车配备有可实现自主导航所需的激光雷达、全球定位系统(GPS)、惯性测量单元及里程计等传感器,用于控制无人机的安全飞行高度,环绕场景区域飞行的同时,将实时存储所拍摄图像及视频,并回传至地面计算机实现场景信息的提取及目标空间位置解算,可大幅减少空中机器人计算负载。

图12 协作平台示意图Fig.12 Schematic diagram of collaboration platform
在机器人操作系统(ROS)中,使用WGS-84坐标系和geographiclib python库,能准确地将导航目标点的GPS坐标转换为ROS参考系下的坐标值,并下发给无人车move_base导航包。在节点launch文件中设定好无人车出发点经纬度坐标,地面无人车获取目标经纬度后下达gps_goal指令给无人车,驱动其向目标区域行进。考虑到GPS精度,在实际测试中选取了具有较长路线长度的场景区域,总长约500 m,确保无人车能够准确检测到从出发点到目标点的经纬度读数变化。
图13为测试过程中地面无人车的部分行进过程图,在已规划的全局路线下,地面无人车可顺利进行自主导航并到达指定目标位置。

图13 地面无人车部分行进过程Fig.13 Part of the driving process of unmanned ground vehicle
5 结论
1)构建了空中旋翼无人机及地面机器人的协作框架,根据无人机回传的视频帧图像,借助YOLO-v3深度学习网络完成地面目标物的检测识别,可获得较高的识别准确率,同时建立相机投影与坐标转换模型,确定了目标物所在地理位置。
2)建立了由SIFT算法获取到的特征匹配点对之间的稳健映射函数模型,在获得更多正确匹配点对的同时,增强了所提取到图像特征点的稳健性,减少了全局场景图的拼接缝隙与拼接图像模糊区域的出现频率,图像分割算法使得图像特征间差异更为明显,从而提升了地面场景特征提取的鲁棒性和准确性。
3)改进了基于采样的路径规划方法,所规划路径的长度整体减少了17%,可为无人车提供一条全局场景下的无碰撞路线。通过对主要模块的仿真实验与测试平台的构建,增强了地面机器人对大范围室外场景的适应性和自主导航能力。
