DTZH1505:大规模开源中文普通话语音库
2022-06-09王丽媛王大亮齐红威
王 东,王丽媛,王大亮,齐红威
1.西藏民族大学 信息工程学院,陕西 咸阳 712082
2.数据堂(北京)科技股份有限公司,北京 100192
语音识别技术作为人工智能技术中的重要组成部分,是人机交互的核心组件之一。语音识别技术的发展具有很长的历史,其演变过程历经了以下几个阶段:从1990年至2010年,统计学习模型(主要是GMM-HMM模型)长期占据主流地位;从2011年至2014年,深度学习开始渗入到语音识别技术中;从2015年至今,端到端的深度学习模型在语音识别研究中广为使用。现在,几乎所有的语音技术研究都直接或间接采用神经网络模型[1-3],语音识别准确率得到了明显提升,这得益于算法、算力、数据的飞速进步。不同于统计学习模型,神经网络模型的训练需要更大规模的数据来驱动。然而,绝大多数中文语音数据集是商用的,其费用之昂贵使许多对中文语音识别感兴趣的研究人员望而却步,导致许多创新的想法得不到很好的验证。
“数据开源”活动极大地缓解了因数据集过于昂贵而无法获取的问题,同时吸引了越来越多的人员进行中文语音识别相关方面的研究。其中,openslr(http://www.openslr.org/)是支持这一活动的一个平台。表1列举目前主流的开源中文语音数据集。其中,最早开源的中文语音数据集是清华大学发布的thchs30[4],它极大地推动了中文语音识别研究的发展。其创建的最初目的是为了弥补863CSL数据集中音素不均衡的缺点[5],所以在设计语料时,它旨在寻求句子数量与音素覆盖率之间的平衡,选择的语料内容多为从新闻中获取的长文本。接着,希尔贝壳也发布了两个语音数据集aishell1[6]和aishell2[7],上海原语公开了primewords_set1,冲浪科技发布了ST-CMDS语音数据集。
作为全球使用最广泛的语言之一,中文相比于其他语言具有更丰富的词汇、特殊的声调表示、独特的声韵母结构等特性,这使得中文语音识别研究更加具有挑战性。然而,相较于工业级别的英文开源语音数据集如librispeech[8]和tedlium[9-11],中文开源语音数据规模仍太小。此外,中文普通话口语语料库的建设仍相对滞后,口语中经常出现语误,对语音的文字转写和标注费时费力,要求较高,这些因素均制约了口语语料库的建设,这已成为目前语音识别逐渐渗透实际应用(比如智能客服、语音交互)的一大羁绊。
为缓解以上问题,本文向学术界开源目前规模最大的中文普通话语音数据集DTZH1505。它记录了6 408位来自中国八大方言地域、33个省份的说话人的自然语言语音,时长达1 505 h,语料内容涵盖社交聊天、人机交互、智能客服以及车载命令等。该数据集可应用于多个领域,比如在语言学与社会学领域,可用于语料库语言学、会话分析、二语习得、语言类型学以及方言学等学科的研究;在计算机科学领域,可用于语音识别、说话人识别、说话人质量评估、情感识别等应用的研究。
1 数据集构建
1.1 文本语料设计
语料的设计取决于其服务的目标任务,如连续语句更适用于连续语音识别任务,而说话人识别任务只需要孤立词[12]。理想情况下,一个标准的语料库应该同时适用于上述两种情景。国内的许多语音识别研究人员在这方面做了很多努力,比如社会科学院语言研究所创建的“863连续语音数据库”863CSL[13]包含了1 500句文本,加上thchs30数据集中的1 000句文本,二音子、三音子的覆盖率可分别达到73.4%、16.8%,然而这些语料多为从新闻中摘取的长文本,绝大多数内容为政治、经济、文化等方面的书面用语。
现在,随着语音识别技术的逐渐成熟,语音识别应用也越来越深入到人们的日常生活中,其中,人机交互、智能客服等应用已成为语音识别技术的主要涉足领域。本文聚焦于目前最新的语音识别需求,通过一系列的设计与制作生成了大规模的音素平衡自然语料库,详细制作过程如图1所示。
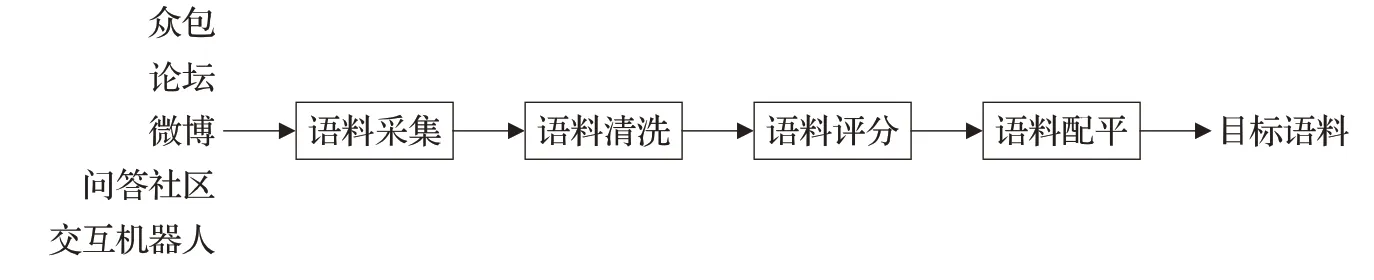
图1 文本语料设计流程图Fig.1 Text corpus design flow chart
1.1.1 文本语料采集
本文通过互联网抓取技术,从论坛、微博、问答社区、交互机器人等开放网站或平台,搜集大量来自不同社会场景中的自然文本语料,初步构建了自然语境下的中文口语化原始语料库,其所涵盖的场景如表2所示。
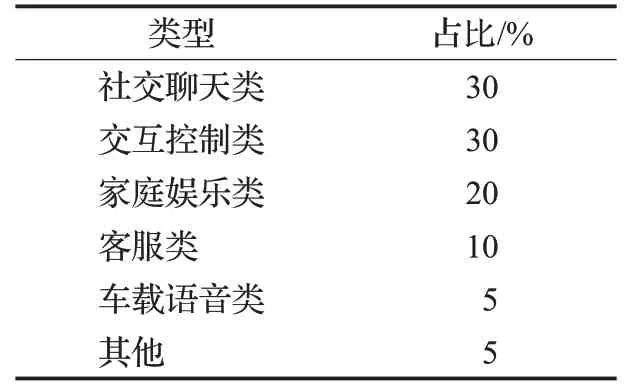
表2 原始语料文本分类统计表Table 2 Social scenes coverage of original text corpus
1.1.2 文本语料清洗
按照标点符号切割文本,过滤长度在5~30之外的句子,并进一步进行拼写纠错、语义完整度检测、语义滤重、文本脱敏等一系列文本清洗,生成待筛选的干净语料集。
首先,本文采用n元语法模型,即N-Gram语言模型来消除大部分中文拼写错误。使用自有语料训练3-gram语言模型,并利用模型对语句中的词打分,将得分低的位置视为待纠错位置,基于SIGHAN 2013 CSC语料构建候选集,从中选择困惑度最高的句子。
其次,本文基于语义分析算法,对语料中文本的语义完整度进行打分,认定得分较低的文本为语义不完整,并去除该文本。同时,本文根据语义框架的相似度计算,去除语义相同的文本,从而实现文本的语义滤重。
最后,本文基于关键字匹配的过滤算法,识别出语料中可能影响到个人隐私、财产、企业信息、国家安全的敏感信息以及反动、色情、暴力等不良内容,并剔除含有敏感信息和不良内容的句子。拼写纠错及语义分析、文本脱敏的实现效果如表3所示。

表3 语料清洗效果演示表Table 3 Presentations of text corpus cleaning
1.1.3 文本语料评分
语料评选是语料库设计的重要环节,自然语境下的平衡语料库的构建则需要考虑多种因素。一方面,语音流中的协同发音现象对连续语音识别具有重要影响,而对中文来说,单个音素具有不稳定性,因此,本文选取二音子及三音子作为反映协同发音的声学基元。
在语音学层面,以基本音子为基础,考虑两个相邻音子,即形成一个二音子(也称双音子);同时考虑左、右相邻音子,即形成三音子。对应到声学层面,二音子描述了两个相邻音子间的稳定阶段,而三音子描述了一个音子的稳定阶段及左、右两边音子的过渡阶段。因此,二音子和三音子对于连续语音流中的协同发音现象具有更好的描述能力。普通话含有37个基本音子[14],按照音子在音节中的位置,又可细分为表4中的三类音子。表5列出了部分音节及对应的音子、二音子、三音子形式。

表4 音子分类表Table 4 Categories of Phones
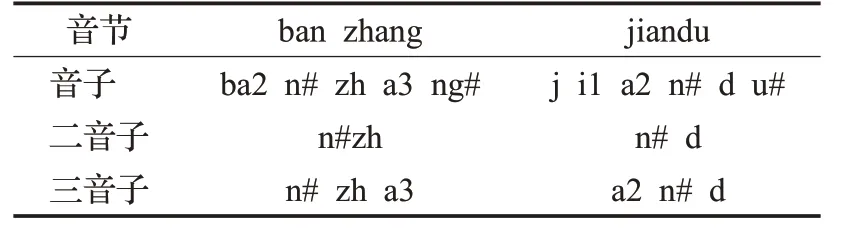
表5 音节、音子、二音子、三音子部分对应表Table 5 Correspondence of syallables,phones,diphones,triphones
另一方面,中文的音节具有独特的声韵母结构,因此,本文也选择音节作为衡量语料库平衡性的标准之一,此外,在人们的日常用语中,声调也具有特别的意义,因此,有调音节也被考虑在内。表6为对文本进行分析的示例,包括原始文本、文本分词、文本词性、文本中字词的有调音节、文本中的二音子序列及三音子序列共6层结构。

表6 文本分析结构表Table 6 Text analysis structure table
本文将无调音节、有调音节、二音子和三音子作为声学基元,对每条句子计算其贡献分数,即含有出现次数越少的声学基元的句子的贡献分数越高。最后,分数靠前的句子优先被选出来。本文着重研究口语中的语音协同发音现象,因此设置无调音节、有调音节、二音子、三音子的权重分别为0.2、0.2、0.3、0.3。各声学基元的贡献分数计算方法见公式(1),整句文本的计算方法见公式(2),其中,s是该句文本中对应声学基元的贡献分数,I是当前已选语料集中含有的对应声学基元的个数,n代表声学基元的种类,wn是指对应声学基元的权重,s n是指对应声学基元的贡献分数,S即该句文本所具有的贡献总分数。

1.1.4 文本语料配平
为避免语料集在不同场景中的分布出现失衡,本文对打分后的语料集再次进行文本分类,按照在语料采集阶段中设定的各场景文本占比率由领域专家补充配平语料,调整语料的场景类别和音素分布的倾斜性。本文最终得到30万条文本,使得在保留语料自然性的基础上,最大限度地实现音素平衡,详情请见表7。

表7 DTZH1505文本语料库音素覆盖情况Table 7 Phonetic coverage of DTZH1505
1.2 语音采集场景
语音采集场景是由录音设备、录音软件、环境布置、朗读脚本和被采集人构成。本文通过分布式的众包模式,进行大规模语音数据采集。
语音采集环境均为底噪介于10~40 dB、混响时间小于1 s的安静室内。为避免出现回声及混响,录制室内被要求放置一定量的填充物,比如日常家具。在正式录制语音数据之前,自主研发的一款手机终端录音软件可以测试录制环境的底噪是否满足上述要求,并且只有当说话人的语音样例数据达到检测标准后,才可开展正式的语音录制。
在数据录制过程中,本文采用Android手机、iOS手机、录制启停控制器及提词器搭建了一个综合录制平台,说话人被要求采用正常语速朗读提词器的文本内容,说话人与手机之间的距离被严格控制在20~30 cm,如图2所示。不管是Android手机还是iOS手机,采集的语音均是16 kHz,16 bit的单通道wav格式。录制所用设备的详情如下:
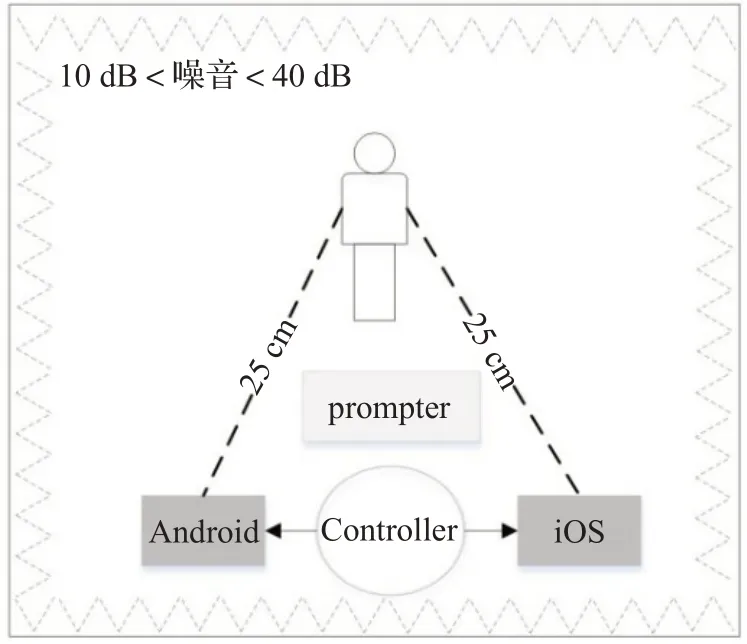
图2 录制环境示意图Fig.2 Map of recording environment
Android手机:基于Android系统的移动通讯设备,包括华为、中兴、三星、联想、HTC、酷派、小米等机型。
iOS手机:基于iOS系统的移动通讯设备,包括iPhone8、iPhone7、iPhone6、iPhone5等机型。
启停控制器:语音录制平台控制终端,用于检测环境噪音,控制多设备同步采集。
提词器:语音录制辅助工具,用于自动显示待朗读文本,并提供计时提醒和语速检测功能。
1.3 录制人员
数据库服务的目标任务同样决定了说话者的数量,例如,语音识别任务对说话者的数量没有过多要求,但说话者身份识别任务则要求有更多的说话者[15]。本文建立数据集的目标在于为更多领域的研究提供数据支撑。在本数据集中,共采集了6 408位来自中国八大方言地域、33个省份的说话人,说话人分布详情见图3。由图3可看出,说话人的性别分布均衡(男为2 999,女为3 301),年龄涵盖了各个层次段。
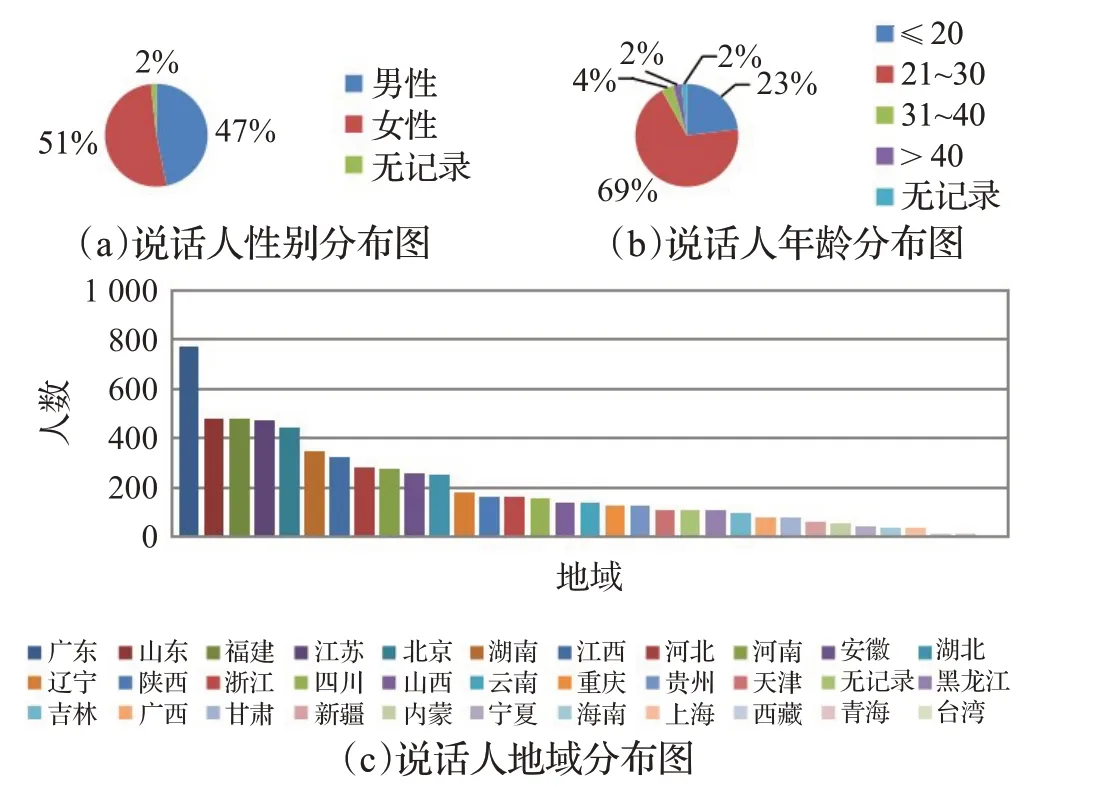
图3 说话人分布详情图Fig.3 Details of speakers’distributions
1.4 语音标注
为确保语音标注的准确度,本文采取了多轮次的数据标定工艺过程,具体包括以下步骤:
第一步,由专业人员在标注平台对每句音频转写其真实的发音文本,在该阶段,标注人员负责核查音频的真实内容,并判断音频的有效性。如图4所示,图中的右半部分显示了每段音频的元数据,包括文件名称、预设朗读内容及说话人信息。图中的左半部分为音频的语音转写及质检工作区,最上面一行为该段音频的时域波形图,紧接着下面为标注人员转写的语音真实文本及是否是有效语音的判定。所有的音频均按照详细的标注规范进行统一的标注,具体包括:
严格化:若音频含有严重喷麦、语音失真、噪音明显、口齿不清等问题,则视为无效语音。
全面化:标记有效语音段内的即时噪音,如笑声、咳嗽、打喷嚏等。
规范化:比如根据说话内容区分标注汉字“幺”和“一”,英文单词间留有空格,但与汉字之间不留空格,英文缩略词的字母之间不留空格,但全大写。
口语化:细化到儿化音,比如下班儿、一点儿。
真实化:所听即所写,比如网址www.bbb.com标注为“三W点儿BBB点儿COM”。
第二步,由专业质检人员对标注语音分别按照100%、50%、10%的比例进行多轮抽样质检,以检查人工转写的正确率。图4中的左下部分为语音质检的工作区,质检人员再次检查语音转写的正确性,判断其中是否包含噪音、突发噪音、背景噪音、喷麦、空旷回音、电流干扰、文本错误、非本土人等错误。
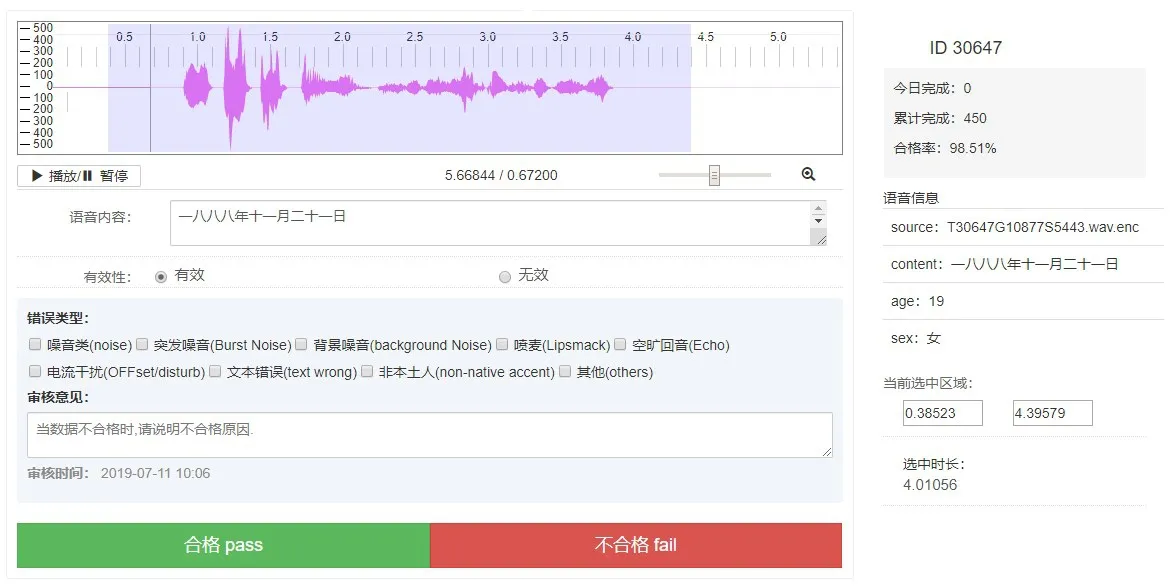
图4 语音标注及质检一体化平台Fig.4 Integrated speech annotation and quality inspection platform
经过严格的语音标注及质检,本文从最初采集得到的原始音频数据中筛选出了大约1/2的合格语音数据,这些合格数据达到了98%的转写准确率。
1.5 数据开源
经过大规模的录制及后期严格的语音转写,本文最终构建含有1 505 h语音时长的大规模中文普通话语音数据集——DTZH1505,该数据集含有以下文件:
音频数据:记录说话人的发音内容,格式为16 kHz 16 bit单通道的wav文件。
标注文本:记录每条语音的转写文本。
标签文本:记录与每段音频相关的音频格式、说话人信息、采集设备等元数据信息。
目前,该数据集已经面向学术研究开放,可通过官方网址https://www.datatang.com/opensource获取该数据集。
1.6 中文通用语言模型
现在主流的基于深度学习的语音识别模型可分为两大类,一种是利用深度学习模型取代原来的GMM部分,即DNN-HMM模型;另一种是端到端的深度学习模型。尽管目前端到端的语音识别系统尝试以单个系统的方式联合学习声学模型及语言模型,但语言模型具有对模型输出文本进行解码和修正的作用,因此仍是目前提升语音识别效果的关键因素。另一方面,建立保留语料自然性的大规模平衡口语语料库仍需不断扩充其库容量,语料数量太小,某些词语的出现频率就会大大降低。因此,只有依赖大量的实际用例,才能够支撑通用的中文口语语言模型研究。
本文以上文描述的DTZH1505数据集中的自然口语语料(超过105万条文本,共超过500万词汇)为基础,训练中文口语基准语言模型,并在此基础上,不断叠加另外的130万条取自于对话、车载、通用场景下的文本以及9 000万条社交场景下的文本数据,以不断提升语言模型效果,不同量级中文口语语料库(Chinese spoken corpora,CSC)的数据详情见表8。
本文利用Kaldi工具[16]训练基于上述语料库的三元文法语言模型,采用了Kneser-Ney平滑算法,将未登录词映射到UNK,生成ARPA格式的语言模型。同时,本文利用集外的1万条对话场景下的文本作为测试集,计算以上3种语言模型的困惑度(PPL),以此评估语言模型的性能,评估结果详见表8。
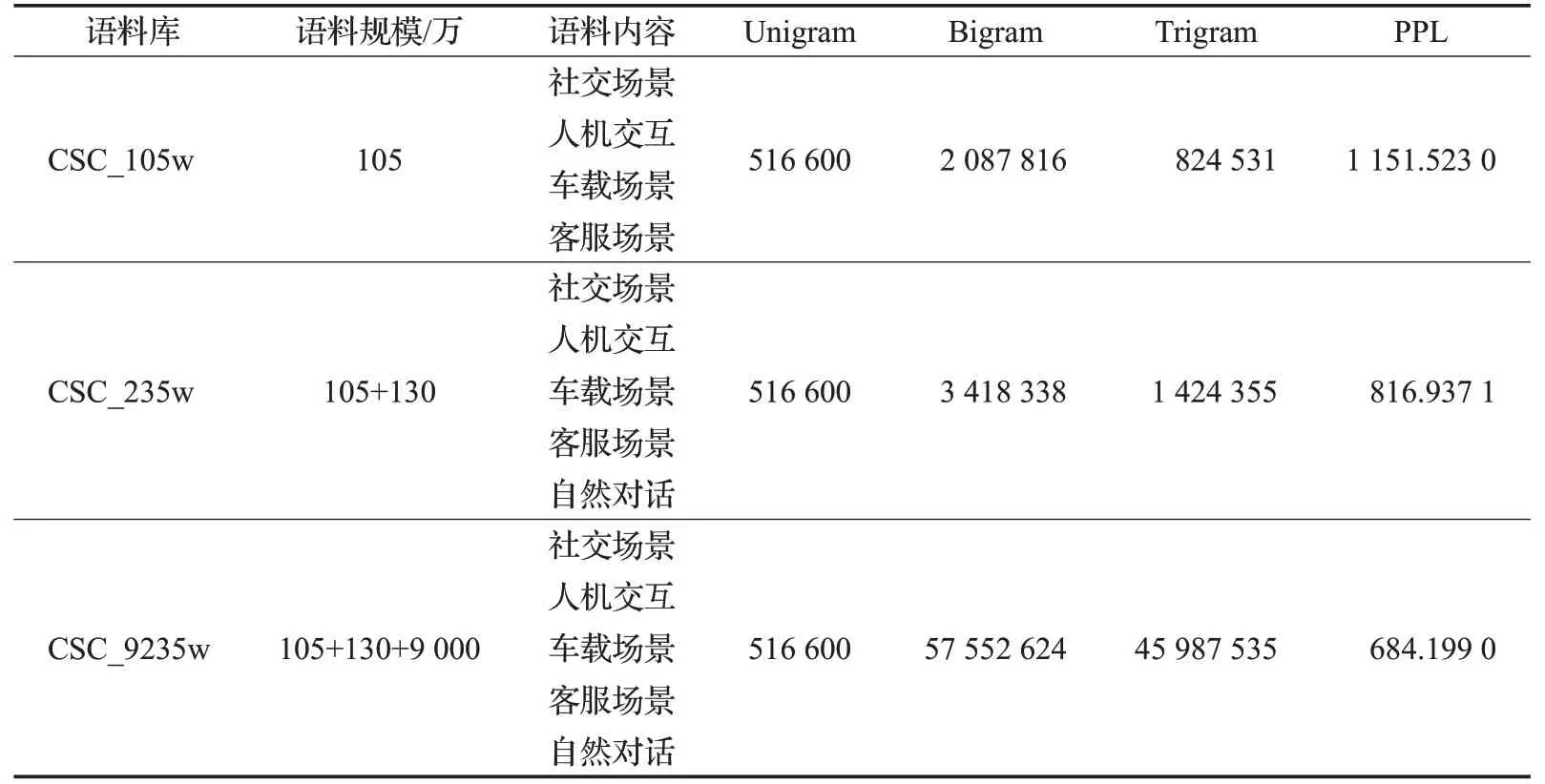
表8 语言模型测试结果Table 8 Evaluation results of language models
根据语言模型的测试效果可知,随着口语语料的增加,中文口语语言模型效果具有显著的提升,并且在9 235万条文本、超过1.6亿词汇的训练下,语言模型的困惑度较基准语言模型降低了40.6%。
语言模型的改进同时增强了语音识别模型效果。与语音数据集一样,本文也将优化后的中文语音识别模型开源到Kaldi平台(http://kaldi-asr.org/models/m10),有关实验过程及结果在下章详细介绍。
2 语音识别实验
2.1 基准实验
为了验证DTZH1505数据集的品质,本文基于Kaldi开展一系列语音识别基准实验。本实验的声学模型训练部分又分为基于概率统计的高斯混合-隐马尔可夫(GMM-HMM)模型与基于深度学习的深度神经网络-隐马尔科夫(DNN-HMM)混合模型两个阶段。
GMM-HMM模型使用的是13维MFCC与3维pitch特征,训练过程又可分为以下几个阶段,由部分数据快速启动单音子模型的训练。
(1)采用类似的方法快速启动三音子模型的训练。
(2)使用全部数据集进行三音子模型的整体训练。
(3)利用线性判别分析LDA算法对上下文的多帧数据进行降维,结合最大似然线性变换MLLT算法进行说话人无关的全局变换。
在DNN-HMM模型训练阶段,输入特征是40维高精度MFCC特征与3维pitch特征,表征说话人信息的i-vector[17]特征也作为输入用于DNN的训练。实验采用时延神经网络(TDNN)[18]搭配链式模型(Chain model)来训练声学模型。在实验过程中,本文也采取了数据增强方法来扩展训练集。
在本实验中,所有数据集被按照7∶1∶2比例划分成训练集、验证集、测试集,表9为基于该数据集进行语音识别的字错误率(CER),用以表征语音识别的效果。其中,aishell2的测试结果来自于文献[7]中与其训练集数据来源相同的iOS测试集。
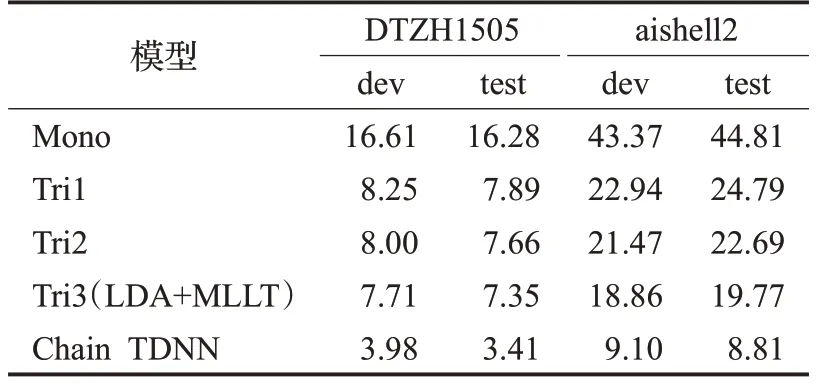
表9 基准实验结果Table 9 Benchmark experiment results %
从实验结果中可以看出来,DNN-HMM模型的识别性能大大超过GMM-HMM模型的识别性能,同时,基于本文创建的中文语音数据集的字错误率降低至3.41%,相比于同类型的中文开源语音数据集aishell2,字错误率降低了61%,这也说明了该数据集的品质。
2.2 模型优化
语言模型是影响语音识别效果的关键因素之一,语言模型的提升不仅在于算法的改进,更在于丰富、完备、优质的语料库的支撑。如1.6节所述,更多优质的语料的加入,大大提升了语言模型的性能。本文在2.1节所述基准实验的基础上,利用优化后的语言模型分别测试在ST-CMDS及thchs30数据集上的语音识别效果,见表10。
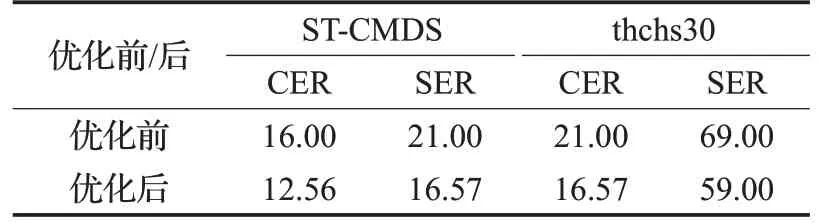
表10 模型优化后的语音识别结果Table 10 Speech recognition results after model optimization %
ST-CMDS数据集的语料以日常用语为主,而thchs30数据集的语料以新闻类长文本为主。从表10可以看出来,基于DTZH1505数据集训练的基准语音识别模型可以在不同语料领域均有很好表现,并且在优化了语言模型之后,字错误率均降低了21%左右,从而验证了该语音识别模型的通用性。
3 总结
本文介绍了一个大规模开源中文普通话语音数据集DTZH1505,详细描述了数据集设计及制作的过程。该数据集包含了6 408位说话人,录音时长达1 505 h,标注准确率达98%,覆盖主流移动设备,采集标签达30项,可广泛用于语音识别、声纹识别、说话人质量评估、语料库语言学、会话分析、二语习得、语言类型学等研究。本文在最后基于该数据集进行语音识别基准实验,并对比目前同规模中文语音数据集的语音识别效果,从而验证该数据集的品质。同时,本文在该数据集的基础上增加大规模文本语料,训练出更通用的中文口语语言模型,进一步提升了语音识别效果。为了便于研究和使用,该数据集及中文语音识别模型已开源,以推动中文语音识别技术研究的发展。
