基于CEEMDAN分解的短时交通流组合预测
2022-06-09胡茂政
聂 铃,张 剑,胡茂政
上海工程技术大学 航空运输学院,上海 201620
随着经济的快速发展和城市化的不断推进,汽车保有量高速增长,道路交通拥堵成为焦点问题。智能交通系统(intelligent transportation system,ITS)在实时交通信息基础上,通过交通流诱导和控制,达到减少交通拥堵现象,节约出现时间的目的[1]。高效且准确的道路交通预测系统是ITS的重要组成部分[2],如何确保短时交通流预测的效果成为了当前交通流预测领域的难点,同时也是交通研究方向的热点之一。
近年来,国内外众多学者在短时交通流预测的研究方向大多采用了智能算法组合优化的方法。马秋芳在传统的神经网络基础上,引入优化后的粒子群算法建立模型[3];Qian等人利用遗传算法对神经网络的初始参数改进后进行交通流预测[4];Lu等人采用滚动回归ARIMA模型与长短期记忆(long short-term memory,LSTM)模型结合进行预测[5];杨刚等人利用优化后的粒子群与最小二乘支持向量机结合进行交通流预测[6]。这些研究表明了智能算法组合优化进行短时交通流预测效果较好,随着对交通流时间序列特点的深入研究,时间序列分解方法在交通流研究领域广泛应用。殷礼胜等人提出交通流经过经验模态分解后与改进粒子群算法优化LSSVM的组合预测算法[7];肖进丽等人采用经验模态分解结合差分进化组合优化BP神经网络进行交通流预测[8];Tian等人经过经验模态分解后,在极限学习机的基础上,结合ARIMA算法,提出一种新的混合短时交通流预测模型[9]。虽然这些短时交通流预测模型预测效果得到了提高,但很少有针对分解后的各个交通流时间序列分量的特点,建立与其适应的组合预测模型,因此如何将时间序列分解方法与预测模型更好地结合成为了交通流预测的热点研究法方向之一。
在此基础上,本文提出了基于CEEMDAN分解的短时交通流组合预测模型。首先鉴于交通流的不确定性和非线性,采用CEEMDAN算法对交通流时间序列进行分解;其次,利用PE算法对分解后的各个交通流时间序列分量分析的随机特性,根据时间序列分量的不同随机特性分为高频序列分量、中频序列分量和低频序列分量,根据高频、中频和低频序列分量的随机特性分别建立GWO-BP模型、GWO-LSSVM模型和ARIMA模型进行预测;最后叠加各个高频、中频和低频序列分量的预测结果,得到短时交通流最终预测值,并分析比较基于CEEMDAN分解的短时交通流组合预测结果与ARIMA模型、BP模型、LSSVM模型以及GWO-LSSVM模型的预测结果。
1 理论与方法
1.1 CEEMDAN算法
经验模态分解法(EMD)方法是一种处理非平稳信号的方法,根据波动尺度将复杂的原始序列分解成不同赋值的IMF分量。但EMD方法在信号分解过程中会显现模态混叠现象[10],为解决这一问题,鉴于白噪声均匀分布的特点,Wu等人在分解过程中加入白噪声,提出了集合经验模态分解法(EEMD)[11],但分解后残留的白噪声导致EEMD方法分解具有较差的完整性。Torres等人提出了自适应噪声完全集合经验模态分解(CEEMDAN)[12],将自适应高斯白噪声添加至每一阶段,有效地解决了模态混叠以及重构序列中存在残留噪声的现象,具有较好的分解完备性。
1.2 PE算法
排列熵(permutation entropy,PE)是一种度量时间序列复杂性的方法,可以表示时间序列的随机性和突变性。PE算法计算简便且运算效率高,同时针对非线性序列数据稳定性高,具有较强的抗干扰特点。PE算法的基本原理如下:
首先对交通流时间序列{X(i),i=1,2,…,}n进行相空间重构,进而得到相空间矩阵Y为:
式中,m为嵌入维数,τ为延迟时间,j=1,2,…,k。
对于重构后的相空间矩阵Y,每一行向量都可以得到一组符号序列S(g)为:

式中,j1,j2,…,j m表示重构向量各分量元素所在的列序号,g=1,2,…,l且l≤m!。
计算每种符号序列S(g)出现的概率P g(g=1,2,…,l),根据Shannon熵的形式,将交通流时间序列X(i)的第l种符号序列的排列熵H p(m)定义为:

式中,0≤H p(m)≤lnm!,当P j=1/m!时,H p(m)达到最大值lnm!。
为了方便,将H p(m)进行标准处理:

式中,0≤H pE(m)≤1,H pE(m)值的大小表示时间序列随性程度。值越大则代表序列随机程度越强,反之,随机程度越弱,呈现的规律越明显。嵌入维数m和延迟时间τ对PE算法有着重要影响。
1.3 BP算法
BP神经网络算法是一种前馈神经网络,主要学习方式为利用梯度下降算法不断迭代来优化神经元之间的权值和阈值[13]。虽然其非线性映射能力较强,但隐含层神经元的权值和阈值是随机分配的,网络结构较大且包含大量可变参数,结果容易陷入局部最优解从而导致算法过早结束,并且收敛性较差。BP神经网络包括三个网络结构:输入层、隐含层和输出层[14],输入层X=[x1,x2,…,x N1],隐含层Y=[y1,y2,…,y N2],输出层Z=[z1,z2,…,z N3],以全连接的方式连接各层之间。
1.4 LSSVM算法
SVM是应用于时间序列预测研究的一种有效模型,最小二乘支持向量机(least-squares support vector machine,LSSVM)[15]是对SVM模型的改进。LSSVM的损失函数为最小二乘线性系统,为了减少了求解过程中的计算量,采用等式约束,改变了SVM中的不等式约束。与其他预测模型相比,最小二乘支持向量机模型可以改善过度学习和训练时间长的缺点,在解决非线性问题时具有更好的精度和准确度。LSSVM的优化模型如下:
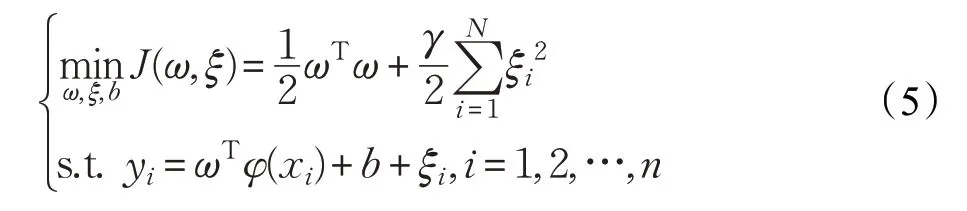
1.5 ARIMA算法
ARIMA模型是预测平稳时间序列的最常用的线性回归模型之一,由Ziegel、Box和Jenkins提出[16]。ARIMA模型虽然结构简单以及计算简便,但适用波形较为稳定的交通流数据[17]。ARMA模型通常用来分析时间序列,用ARMA(p,D,q)来表示该模型,其中p、D、q表示预测模型的结构参数,分别为自回归AR(p)、差异度D和移动平均MA(q)。当时间序列表现为较稳定时,ARMA模型能很好地进行原始数据拟合。然而,当时间序列表现为不稳定时,则需要采用差分转换过程将其转换成稳定的时间序列。ARIMA模型用于模拟差分时间序列,所以也适用于不平稳序列,这个过程为ARIMA(p,d,q),用数学表达式表示为:
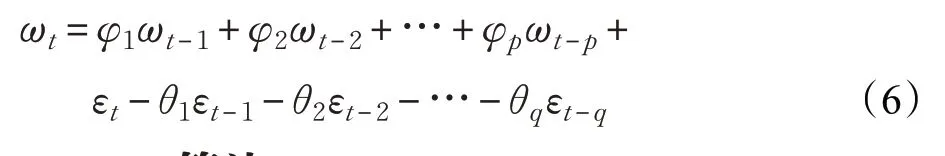
1.6 GWO算法
灰狼算法(grey wolf optimizer,GWO)是由Mirjalili等人在2014年提出的一种新群体智能算法[18],主要学习方式是模拟狼群在自然界中的种群层次结构和捕食活动。GWO算法相对于其他算法,具有较强的收敛性和稳定性。GWO算法具有接近任何非线性函数的能力,且存在参数少、全局搜索能力强的优势[19]。同时GWO算法适应性强且操作简便,易于实现,同时与其他算法较容易结合,达到提高性能的效果。
GWO算法根据社会关系将整个狼群分为四个等级,第一级为α狼,属于头狼,负责决策,决定捕食、栖息地和时间,其他狼都必须服从α狼的命令。第二级为β狼,属于协助狼,服从并协助α狼。第三级为δ狼,服从α狼和β狼,同时控制狼群的剩余部分。第四级为ω狼,ω狼没有自主决策控制能力,它必须服从狼群其他等级的狼。前三级狼有着较好的适应能力,在α狼的引导下,有组织地对猎物进行跟踪,围捕和攻击。GWO算法实现步骤如下:
假设灰狼狼群的规模为N,搜索空间为D维,第i只狼灰狼的位置表示为Xi=[x1(1),x2(2),…,xi(i)],则狼群捕猎过程包括追踪、狩猎和攻击。灰狼在发现猎物后,逐渐靠近猎物并将其包围,灰狼与猎物的距离是:

式中,t表示当前迭代次数,X(t)表示灰狼t次迭代后的位置矢量(即潜在解所在位置),Xp(t)表示猎物t次迭代后的位置矢量(即最优解所在位置),系数向量A和C的计算公式为:

式中,r1和r2表示0到1之间的随机数,随着迭代时间的增加,a从2减小到0。
根据α、β、δ这三种狼来估算猎物的位置,则其他狼的位置更新方法为:
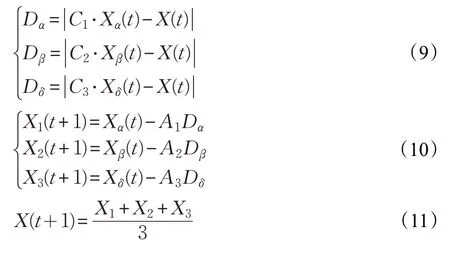
2 基于CEEMDAN分解的短时交通流组合预测模型的建立
2.1 基于CEEMDAN分解的短时交通流组合预测模型
鉴于短时交通流时间序列具有较强非线性和随机性,使用单一的预测方法进行交通流预测很难得到较好的预测效果。由于CEEMDAN分解具有良好的分解完备性,同时对原始交通流序列具有精准分解的优点,本文采用CEEMDAN分解方法对短时交通流序列进行分解得到多个分量,利用PE算法分析各个分量的随机特性,将时间序列分量分为高频、中频、低频分量。考虑到BP具备较强的非线性映射特征,采用BP算法对具有较强非线性和随机性的高频时间序列分量进行交通流预测,同时为了提高高频序列分量预测效果,在BP算法的基础上引入GWO算法优化其权值和阈值,建立GWOBP预测模型;考虑到LSSVM对于非线性波动数据具有较强的学习能力及较快的学习速度,因此采用LSSVM算法对具有一般非线性和随机性的中频时间序列分量进行交通流预测,同时为了提高中频序列分量预测效果,在LSSVM算法的基础上引入GWO算法优化其正则化参数和核函数参数,建立GWO-LSSVM预测模型;考虑到ARIMA对平稳序列具有良好的预测性能,因此采用ARIMA算法对较平稳的低频时间序列分量进行交通流预测。最后叠加各个高频、中频和低频序列分量的预测结果,得到短时交通流最终预测值。基于CEEMDAN分解的多分量组合短时交通流预测模型流程图如图1所示。
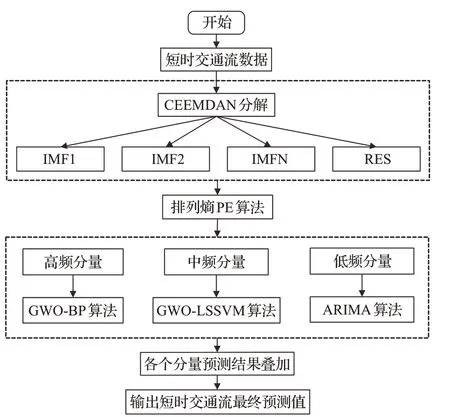
图1 基于CEEMDAN分解的短时交通流组合预测模型Fig.1 Short-term traffic flow combination prediction model based on CEEMDAN decomposition
2.2 基于CEEMDAN分解的交通流时间序列
基于CEEMDAN分解的交通流时间序列实现步骤如下:
(1)在原始交通流时间序列y(n)加入服从标准正态分布高斯白噪声序列v i(n),信噪比为ε,经过第i次分解的交通流时间序列为y i(n)。

(2)利用EMD方法分解交通流量数据,获得第1个模态分量取均值为IMF1(n)和第1个余量序列r1(n)。
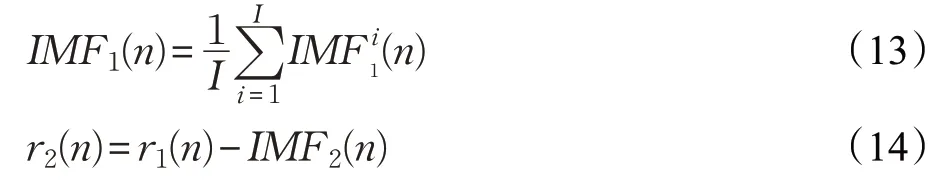
(3)进行EMD分解后的k阶IMF分量交通流数据为E k(·),第2个模态分量为IM F2(n)和第2个剩余分量序列为r2(n)。
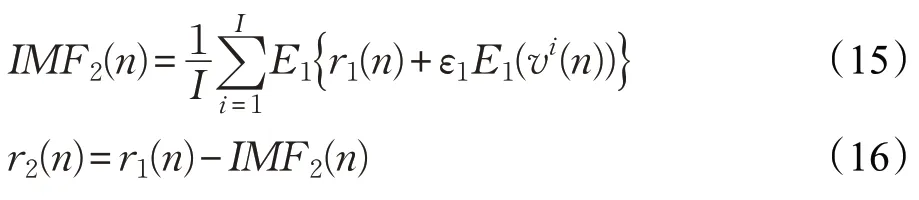
(4)第k个剩余分量序列为r k(n)和第k+1个IMF分量为IMF k+1(n)。
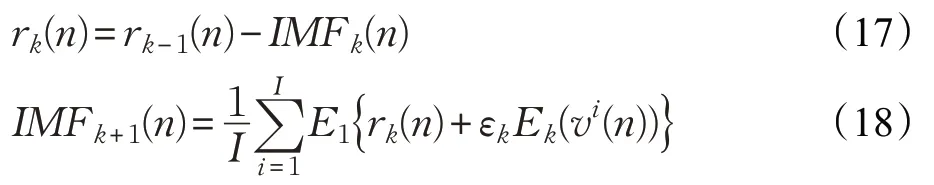
(5)重复以上步骤,直至余量不能分解,最终交通流时间序列被分解为y(n)。
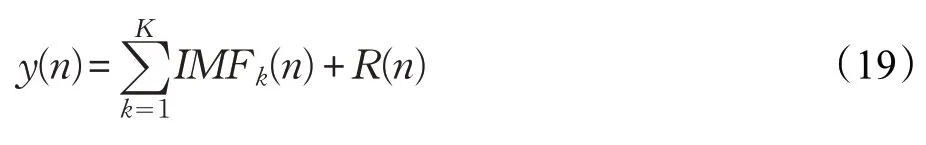
2.3 GWO-BP预测模型
GWO-BP算法的核心是将灰狼算法中种群位置信息设置为BP神经网络的权值和阈值,当灰狼在追捕猎物过程中对猎物位置的判断不断更新自身的位置,不断更新权值和阈值,最后找到最优解。针对高频序列分量的GWO-BP预测模型实现步骤如下:
(1)进行BP神经网络模型的构建。确定模型隐含层节点数目,输入和输出的参数,并对数据作预处理。
(2)GWO算法参数初始化。设定灰狼种群规模、种群搜索空间、位置信息维度、算法迭代的最大次数、灰狼狼群初始位置信息。
(3)确定适应度函数,对每个狼群个体进行BP神经网络训练,计算个体的适应度,从中选取适应度排名最高的3个灰狼,作为最优解xα、次优解xβ和第三优解xδ。
(4)更新余下灰狼ω狼个体的位置,同时计算并更新a、A和C参数。
(5)判断是否达到步骤(2)设定的算法迭代的最大次数,若达到,则终止迭代,输出最优灰狼α狼的位置,若未达到,则重复(3)至(4),直到达到步骤(2)算法迭代的最大次数。
(6)将求得的最优初始权值矩阵和阈值矩阵代入BP神经网络模型,实现GWO-BP模型的建立。
(7)将预处理后的数据输入至建立好的GWO-BP模型,即可得到各个高频序列分量预测结果,与真实值进行对比,从而验证该模型的可靠性。
2.4 GWO-LSSVM预测模型
GWO-LSSVM算法的核心是灰狼位置信息设置为LSSVM的正则化参数和高斯核函数,通过灰狼不断更新位置,更新正则化参数和高斯核函数,找到最优解。针对中频序列分量的GWO-LSSVM预测模型实现步骤如下:
(1)对数据进行预处理,通过归一化处理将交通流原始数据修改为(-1,1)区间,同时将交通流时间序列分量数据划分训练集和测试集。
(2)GWO算法参数初始化。设定灰狼种群规模,种群搜索空间、位置信息维度、算法迭代的最大次数、灰狼狼群初始位置信息。
(3)确定适应度函数。对每个狼群个体进行LSSVM训练,计算个体的适应度,由高到低排序,选取适应度排名最高的3个灰狼作为α狼、β狼、δ狼。
(4)更新余下灰狼ω狼个体的位置,同时计算并更新a、A和C参数。
(5)判断是否达到步骤(2)预先设置的迭代的最大次数,若达到,则终止迭代,输出最优灰狼α狼的位置,若未达到,则重复(3)至(4),直到达到预先设置的迭代的最大次数。
(6)将经过GWO算法获得的正则化参数γ和核函数参数σ代入LSSVM模型,实现GWO-LSSVM模型的建立。
(7)将预处理后的数据输入至建立好的GWO-BP模型,即可得到各个中频序列分量预测结果,与真实值进行对比,从而验证该模型的可靠性。
2.5 ARIMA预测模型
针对低频序列分量的ARIMA预测模型实现如下:
(1)对低频序列分量采用平稳性检验方法。首先观察低频序列分量的原始序列图,对其进行平稳性验证,如果该低频序列分量表现为不平稳时,则反复对其进行差分处理,直至低频序列分量表现平稳为止,该过程所进行的差分处理的次数即为ARIMA(p,d,q)中d的参数值。
(2)确定低频序列分量预测模型的阶数。通过观察自相关图以及偏自相关图来确定ARIMA(p,d,q)中p和q的参数值,建立一个可行性模型。通过参数估计及诊断检验过程中,从所有可行性模型中选择合适的模型。根据AIC和BIC准则选择合适的ARIMA模型。
(3)对建立的低频序列分量的预测模型诊断检验。验证所建的模型是否适用于交通流时间序列,为了保证模型的残差序列为白噪声,对模型采用显著性检验方法,同时进行假设检验。
(4)根据以上步骤,将确定的预测模型导出,作为预测的训练模型。
3 仿真结果与分析
3.1 实验数据的选取
在道路存在突发状况、信号灯配时等众多因素的影响下,道路交通流通常具有非线性和不确定性的特点。通过绘制一定时间内采集的交通流时间序列曲线,可以发现交通流具有周期性的特征,工作日(周一至周五)的交通流变化规律尤其相似。为了验证基于CEEMDAN的组合预测模型进行短时交通流预测的有效性,本文的实验数据来自于PeMS系统2018年6月4日—2018年6月8日5个工作日,5 min为采样间隔的交通流数据。
首先对道路旁车辆检测器采集的原始交通流数据进行预处理,数据处理后可以得到1 440个交通流量数据点。为了建立交通流预测模型,利用历史数据预测下一时刻的交通流。以预测点前2 h的交通流序列作为模型输入,以预测的交通流序列作为模型输出。基于上述规则,前四个工作日的1 152个交通数据点可以建立1 128个输入输出数据集,构成模型的训练集,第五个工作日的交通流数据点建立288个输入输出集,构成模型的测试集。交通流数据集分为训练集和测试集,比例为4。采样间隔为5 min,连续5个工作日的交通流时间序列曲线如图2。
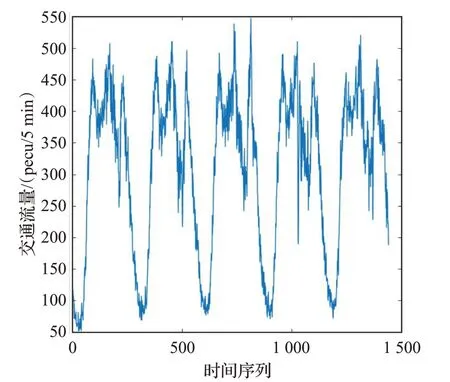
图2 5个工作日的交通流时间序列曲线Fig.2 Time series curve of traffic flow in 5 working days
3.2 基于CEEMDAN算法的交通流时间序列分解
通过MATLAB软件,采用CEEMDAN算法对交通流时间序列进行分解,在分解过程中分解过程中,加入500组白噪声信号,标准差为0.2。该算法的输入数据是以5 min为时间间隔的交通流时间序列,输出的是IMF分量。基于CEEMDAN分解的交通流各个序列如图3所示。
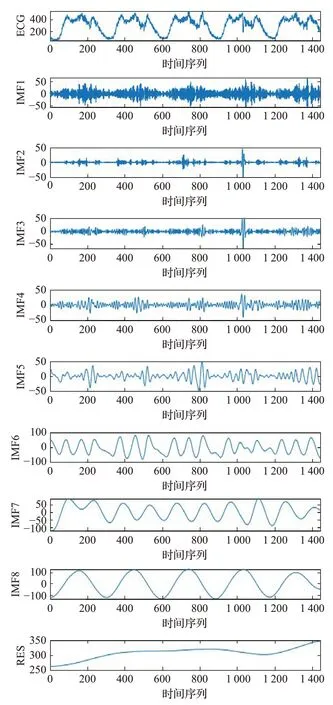
图3 基于CEEMDAN分解的各个序列Fig.3 Each sequence based on CEEMDAN decomposition
为了减少计算规模,对分解后的各个时间序列分量进行随机性分析,采用PE算法计算各个时间序列分量的排列熵,为了提高运算效率,将嵌入维数设置为m=6,延迟时间设置为t=3,通过Matlab计算得到各个时间序列分量的排列熵值,如表1所示,各个分量的标准化排列熵值的分布,如图4所示。根据分解结果和排列熵值,分析各个时间序列分量的随机性。从图4和表1可以看出,IMF1的排列熵值最大,RES的排列熵值最小,随着分量序列数的增加,排列熵值减小,表明时间序列分量的随机性逐渐减弱。IMF1~IMF3分量具有较大的随机性,列为高频序列分量;IMF4~IMF6分量的随机性一般,列为中频序列分量;而IMF7、IMF8和RES分量的随机性较弱,列为地频序列分量,为后续混合预测模型的构建提供了依据。
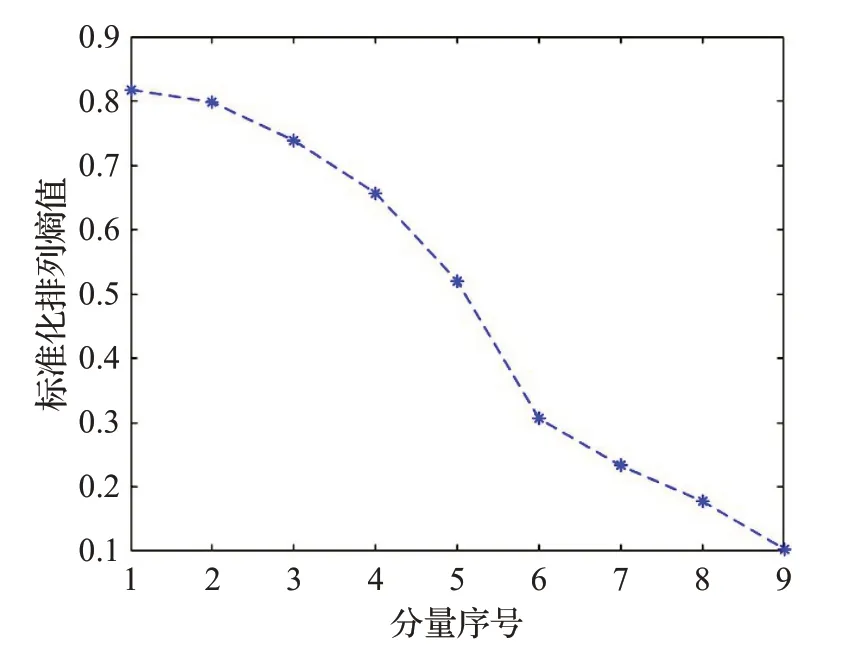
图4 各个时间序列分量的标准化排列熵值分布图Fig.4 Distribution diagram of normalized permutation entropy of each time series component
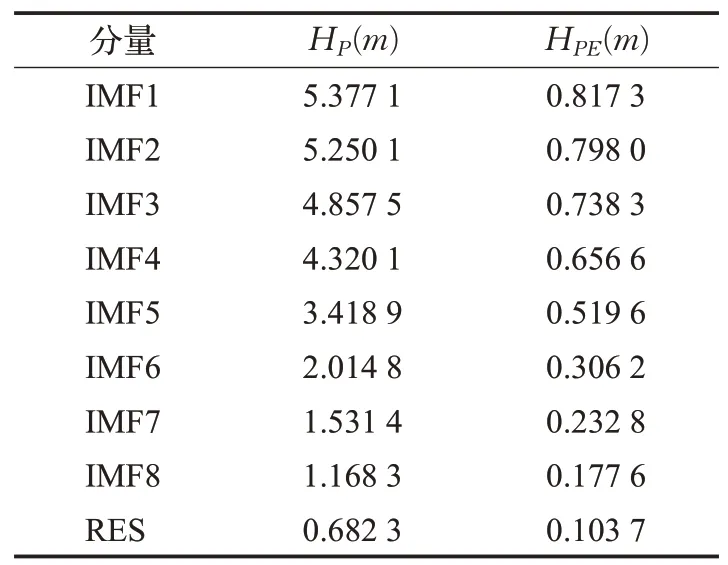
表1 各个时间序列分量的排列熵值Table 1 Permutation entropy of each time series component
3.3 基于CEEMDAN分解的短时交通流组合预测
针对交通流的高频、中频和低频序列分量的特点分别建立GWO-BP模型、GWO-LSSVM模型和ARIMA模型进行预测。对于显现较强非线性和随机性的高频序列分量IMF1~IMF3,采用GWO-BP模型进行预测;对于显现一般非线性和随机性的中频序列分量IMF4~IMF6,采用GWO-LSSVM模型进行预测;对显现较平稳的低频序列分量IMF7、IMF8和RES,采用ARIMA模型进行预测。原始交通流时间序列基于CEEMDAN算法分解的9个分量预测结果如图5所示。
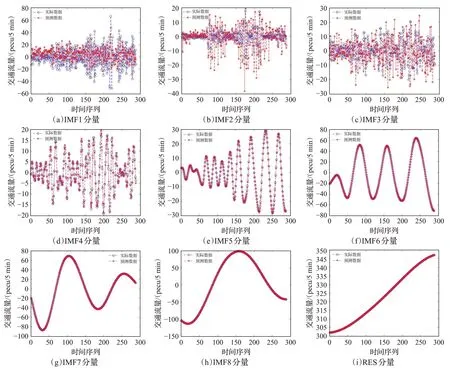
图5 各分量预测结果曲线Fig.5 Forecast result curve of each component
预测评价指标是用来分析对比预测效果的,同时可以达到验证模型的预测有效性的目的。本文采用均方根误差(RMSE)和平均百分比误差(MAPE)评价指标来评价模型预测结果。均方根误差(RMSE)评价是用来评价观测值和真实值的偏离程度,为了反映预测结果的离散程度以及预测精度。平均百分比误差(MAPE)是用来评价整体预测结果与真实值的偏离程度,为了反映模型预测结果的好坏。评价指标公式如下:
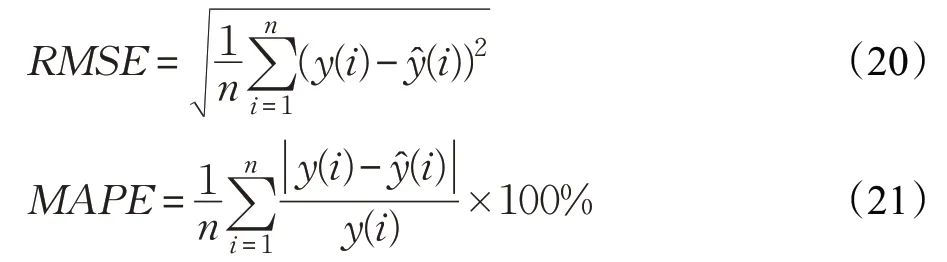
其中,y(i)表示i时刻的实际交通流量数据,ŷ(i)表示i时刻的预测交通流量数据,n表示预测样本数量。RMSE和MAPE值越小表示模型预测误差越小,预测效果越好。
为了验证本文提出的预测模型的有效性,本文将基于CEEMDAN分解的短时交通流组合预测结果与采用ARIMA模型、BP模型、LSSVM模型及GWO-LSSVM模型的预测结果进行对比,如图6所示。
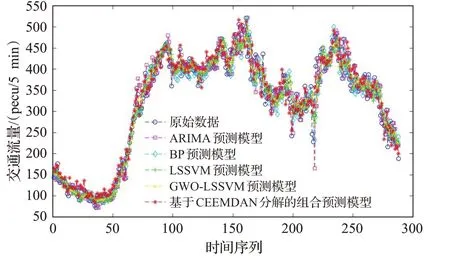
图6 各预测模型预测结果与实际值比较Fig.6 Comparison of predicted results of each prediction model with actual value
基于CEEMDAN分解的组合预测模型与其他预测模型性能对比如表2所示。
由表2的2个交通流预测结果评价指标分析出,相比于其他4个预测模型,本文提出的基于CEEMDAN分解的短时交通流组合预测模型与交通流的真实值的拟合度最好。从表2可以看出,由于交通流随机程度较大,ARIMA模型通常适用于平稳时间序列,因此采用ARIMA模型预测结果与交通流真实值的拟合程度最低。BP模型和LSSVM模型对交通流预测结果与真实值的拟合程度逐渐提高。与采用单一模型进行预测相比,采用组合预测方法,GWO-LSSVM模型对交通流真实值拟合程度进一步提升,但偏离程度仍然略高。本文提出的基于CEEMDAN分解的短时交通流组合预测模型,经过CEEMDAN序列分解,针对随机程度不同的时间序列分量建立不同的预测模型,其预测结果明显优于其他模型,预测误差最小,均方根误差RMSE为20.42,平均百分比误差为5.8%。证明了所提出的组合预测模型有效地利用了ARIMA模型处理随机性小的时间序列的优点,以及采用组合预测方法可以提高预测效果的特点。综上所述,基于CEEMDAN分解的短时交通流组合预测模型能够提升预测精度,具有良好的预测效果。
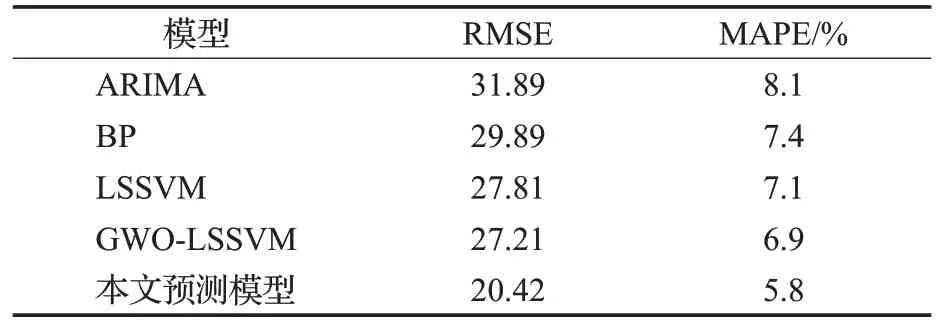
表2 预测模型性能对比Table 2 Performance comparison of prediction models
4 结束语
针对交通流数据具有非线性及随机性的特点,本文提出基于CEEMDAN分解的短时交通流组合预测模型。首先利用CEEMDAN算法对交通流原始时间序列进行分解,其次,利用PE算法对分解后的各个交通流时间序列分量分析的随机特性,根据时间序列分量的不同随机特性分为高频序列分量、中频序列分量和低频序列分量,根据高频、中频和低频序列分量的随机特性分别建立GWO-BP模型、GWO-LSSVM模型和ARIMA模型进行预测,叠加各个序列分量的预测结果,得到最终预测值。最后,通过采集的连续五个工作日的交通流进行仿真验证,结果表明,本文提出的预测模型预测精度高于其他预测模型,在一定程度上提高了预测效果。但由于本文使用的交通流数据有限,且只考虑单一路段交通流预测,并未考虑其他路段的影响,将空间位置关系的影响加入交通流预测是本文下一步的研究方向。
