基于多尺度轮廓增强的RGB-IR双波段图像语义分割算法
2022-06-09谷小婧顾幸生
朱 浩,谷小婧,蓝 鑫,顾幸生
(华东理工大学信息科学与工程学院,上海 200237)
1 引 言
语义分割是计算机视觉领域的一个热点研究方向,已广泛应用于机器人,医学以及自动驾驶等领域[1-5]。开发可靠的自动驾驶应用是一个具有挑战性的任务,因为无人车辆需要对周围环境进行感知、预测,然后计划并进行决策。仅利用可见光图像进行语义分割无法确保自动驾驶系统的鲁棒性,因为可见光图像的成像会受到周围环境的影响,例如大雾等能见度低的场景、夜间等光照亮度低的场景或强曝光的光照度过高的场景。因此,结合多模态的信息来提升分割的鲁棒性逐渐受到人们的关注[6-8]。
近年来,部分研究者引入红外图像以弥补仅使用可见光图像造成的缺陷。可见光的波长范围在0.4~0.76 μm之间而红外线的波长范围在0.1~100 μm之间,补充了绝大部分可见光之外的信息,并且在光照条件较差的情况下,可见光捕捉到的信息将会很少,而红外图像根据高于绝对零度的目标发射的热辐射强度成像,在各种不同的光照条件下都能提供较完整的信息,加入红外图像作为可见光图像的补充可以增加在各种光照干扰条件下输入信息的完整性。因此,基于可见光-红外双波段图像实现语义分割有望提高自动驾驶系统的鲁棒性。
然而,更多模态意味着更多的信息[4],这其中既有互补的信息也有冗余的信息,将什么信息进行融合,何时进行融合,以及如何进行融合是目前RGB-IR双波段语义分割问题面临的挑战。根据何时融合,可以把当前工作的网络结构分为三类:解码端融合,编码端融合,以及编码-解码器端融合。解码端融合的工作包括:Ha等[9]提出的MFNet,网络在下采样的过程中用跳跃连接融合了两个模态的特征,并采用具有空洞卷积的mini-inception模块构建独立的编码器来处理可见光和红外图像,随后在解码器部分进行特征融合,由于未采用预训练模型,虽然速度具有优势,但是精度较低。Lyu等[10]的FuNNet在解码过程中融合了两个波段的信息并使用分组卷积,减少了模型的参数量。Liu[11]等提出的PSTNet引入全局语义信息来增强分割效果。编码端融合的工作包括:Sun等[12]提出的RTFNet使用预训练的ResNet[13]作为编码器。Zhou[14]提出的MFFENet使用DenseNet[15]来更好地提升模型精度。Xu[16]提出的AFNet在编码器的底部对两个波段的特征图进行融合,大大减少了模型的参数量。编码端-解码端融合的工作包括:Sun[17]提出的FuseSeg在编码器中将两个波段的特征图相加,并且将对应的特征图和解码端的特征图进行融合,使得下采样的信息不被丢失。
本文提出了一种基于多尺度轮廓增强的RGB-IR双波段图像语义分割算法。该算法首先在编码器之间通过各个尺度的融合特征预测不同尺度的目标轮廓,再利用多尺度轮廓信息来逐步增强特征图的轮廓信息。在融合了多阶段多尺度特征图的信息之后,我们通过位置注意力和通道注意力来获得更有价值的像素和通道并对特征进行增强。在公开数据库上取得了57.2的最高Miou,在自建数据库上也取得了最好的分割精度。
2 基于轮廓增强的双波段语义分割算法
2.1 模型整体架构
语义分割模型有多种形式[9,12-14,17-18]。由于含有纹理信息的低层特征在语义分割中起着至关重要的作用,本文考虑在整个下采样过程中提取不同尺度的语义轮廓信息并进行监督。通过将更精确的语义轮廓信息有效地和特征图进行融合,提高物体轮廓的精确度。整体架构如图1所示。

图1 模型整体架构Fig.1 The architecture of the model
本文模型使用两个独立的DenseNet121作为特征提取器,DenseNet[15]网络中的每一层都直接与其前面的层相连,实现特征的重复利用,同时每一层都非常窄即只学习非常少的特征图以达到降低冗余性的目的,DenseNet相比于Resnet达到相同精度参数量更小[17]。考虑到RGB图像的特征比IR图像的特征更丰富,因此我们采用不对称网络结构,一条支路单独提取RGB波段的特征,另一条支路提取IR和融合波段的特征。我们提取骨干网络每个DenseBlock的输出特征,并分别标记为(FRGB,i,i=1,2,3,4),(FIR,i,i=1,2,3,4),相比于输入图像分别有(4,8,16,32)的下采样率。我们将双波段特征融合之后送入语义轮廓增强模块(EEFM)来预测并增强融合特征的轮廓。对于最顶层的特征图,我们使用空洞空间卷积池化金字塔[19](1、6、12,18,24的膨胀系数)来扩大感受野,在较小分辨率的特征图上提取对整个图像有指导意义的信息。Fconcat由各个阶段不同尺度的特征图上采样到相同大小之后级联在一起获得,它同时包含有较低层的轮廓信息,较高层的整体语义信息。随后SAC模块从像素维度和通道维度对Fconcat进行增强。最后通过四倍的参数可学习的转置卷积来把特征图上采样到原图大小。
2.2 语义轮廓增强模块(EEFM)
语义分割模型需要分割出不同目标,但当不同目标具有相似颜色或外观时,通常不能很好地将其分割。因此,如何准确地分割出目标轮廓是分割问题面临的一个挑战。
基于以上动机,本节提出语义轮廓增强模块,结构如图2所示。利用网络预测各个尺度的轮廓信息,并通过轮廓标签进行监督,从而显式地让网络学习轮廓信息,以约束不同尺度融合特征的轮廓。
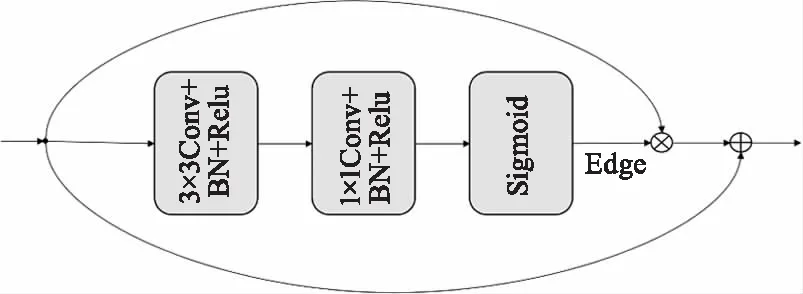
图2 轮廓预测模块Fig.2 Edge enhance fusion module
首先输入双波段融合之后的特征图,通过3×3卷积处理两个波段融合的特征,增加感受野,接着使用1×1卷积得到一个一通道的特征图,该特征是否为轮廓的概率由Sigmoid激活函数计算得到。得到的语义轮廓信息与输入的融合特征图进行像素点乘来增强特征图的轮廓,最后将轮廓增强后的特征图与输入的特征图相加形成一个残差连接来避免信息丢失。
预测得到的轮廓通过真实轮廓标签进行监督,轮廓标签可以利用语义标签得到,语义轮廓监督损失函数使用二元交叉熵,公式如式(1)所示:
(1)

使用这种设计具有两种好处:(1)通过交叉熵损失进行监督,显式约束轮廓信息,利用梯度反向传播优化编码器的特征。(2)重建后的特征包含有增强过的语义轮廓信息,并且不会丢失特征图原有的特有信息。
目前有许多研究工作开始从轮廓信息入手通过约束物体的轮廓来改善分割精度。Li[20]等人在提取特征的过程中提取轮廓信息并进行融合,轮廓提取采用预训练好的轮廓网络,提取的轮廓并未用标签进行监督,计算量大。Fan[21]等人在提取特征的过程中,通过标签对轮廓进行监督,但不重新将提取的轮廓与特征进行融合。J Fontinele[22]等人将轮廓信息作为一条完整的信息支路来传递并与特征进行融合,参数量为一条支路的两倍,计算量大。Zhou[14]等人在输出层对轮廓进行约束。考虑到经过约束的轮廓含有更准确的轮廓信息,因此可以将其用于增强融合特征的轮廓。与上述文献不同的是,本文在下采样过程中预测不同尺度融合特征的轮廓信息并将其送回网络,对图像特征的轮廓进行多次增强,以此来提高网络对物体轮廓的分割精度,并且提出了一个非常轻量的轮廓预测模块。
2.3 位置和通道注意力模块
注意力机制可以看作一种特征重加权的方式,不仅可以在通道上进行重加权,也可以在空间位置上进行加权[10],从而令网络更加注意权重大的区域。
为了提高多尺度融合特征图的精确度,本文受SENet[23]启发,从位置和通道两个方面来对特征图进行加权,提出了一种新的位置和通道注意力模块SAC来增强多尺度融合特征图,如图3所示。

图3 位置和通道注意力模块Fig.3 Spatial and channel module
在图3中,前端网络产生的特征图首先会通过位置注意力模块。位置注意力分为两条支路,上方的支路提炼信息并直接将通道数降到输入特征图通道数的1/4。另一条支路先将通道数降到输入特征图的1/2再通过卷积变为输入特征图通道数的1/4并通过Sigmoid函数来体现出空间位置上更应该被关注的地方,得到位置信息的权重。随后将位置信息的权重与上方支路的结果进行点乘来增强特征图的空间位置信息。同时我们考虑不同的通道所含有的信息应该受到不同程度的关注,因此我们将位置信息增强过后的特征图送入通道注意力模块。首先对特征图进行平均池化来获得一个大感受野里的代表性信息,之后将其通道数提炼到原有通道数的一半,使用Relu激活函数增加其非线性特性,再通过1×1的卷积重新将通道数增加到原有的数量并通过Sigmoid函数来获得不同通道的权重分布,最后使用得到的通道权重对通道进行加权。
3 实验结果及分析
3.1 数据集介绍
本章实验主要在两个可见光-红外语义分割数据集上展开。第一个数据集是文献[4]中发布的一个公开可用的数据集,以下称为PublicDataset。该数据集包含1569对可见光和红外图像,其中包含白天拍摄的820对图像,夜间拍摄的749对图像。包括八类物体被标注,即汽车,人,自行车,路沿,汽车站,护栏,路障,和障碍物。未标记的像素占所有像素的大部分。数据集的图像分辨率为480×640。实验中遵循文献[4]中提出的数据集分配方案,50 %的图像用于训练,25 %的图像用于验证,其余图像用于测试。
第二个数据集是自建数据集,以下称为EcustDataset,这是课题组自行构建的包含541对图像的数据。它是在夜间拍摄的城市街景图像的数据集,所用的可见光拍摄设备为索尼A6000微型单反,FLIR Tau2336红外热像仪相机。图像的分辨率为300×400。该数据集中有13个类被标记,即汽车、自行车、人、天空、树、交通灯、道路、人行道、建筑物、栏杆、交通标志、柱子和公共汽车。对于场景中不属于上述物体或难以辨识的物体,将其设置为空类,即不进行标注。在模型训练与评估的过程中不包括空类。实验中将EcustDataset分为两部分。训练数据集由400对图像组成,其他141对图像被分为测试数据集。
3.2 实验设置及评价指标
本文实验环境的基本配置是Intel i7-8700 CPU,一张NVIDIA GTX 2080Ti显卡,系统为Ubuntu16.04,构建模型使用的PyTorch版本为1.2,CUDA使用10.0版本,cuDNN使用7.6版本。使用PyTorch提供的预训练权重DenseNet121来训练网络。训练阶段使用带动量的SGD优化器,该优化算法更容易跳出局部最优值或梯度为零的鞍点处。文中所有模型包括对比算法的训练超参数采用统一的设置,训练批大小设为4,动量和权重衰减分别设为0.9和0.0005。初始学习率r0=0.01,训练周期设为tSmax=100。采用“poly”学习策略来逐步降低学习率,如公式(2)所示:
(2)
在训练过程中,每个训练周期之前输入的图片被随机打乱。使用随机水平翻转和随机裁剪来进行数据增强。EcustDataset的输入图像通过镜像填充扩大到320×410,PublicDataset的输入分辨率为原始分辨率。
网络的主损失函数是交叉熵损失函数,如公式(3)所示:
(3)

Ltotal=Lce+λLedge
(4)
其中,λ表示轮廓监督损失函数的权重。
本文实验采用平均交并比(mIoU)来评估语义分割的性能。它的计算公式如下:
(5)
其中,N是类的数量,Pij是属于第i类被预测为第j类的像素数。对于PublicDataset,将未标记的像素也考虑到计算指标中。以上评价指标在分割结果中的得分越高,代表算法分割精度越好。
3.3 实验结果及分析
3.3.1 先进算法对比及分析
本文先对比分析了不同先进算法的实验结果,对比算法包括本文提出的算法、MFNet[9]、PSTNet[11]、RTFNet[12]、FuNNet[10]和FuseSeg[17]和MFFENet[14]。表1和表2展示了不同网络在PublicDataset和EcustDataset测试的定量结果。

表1 不同分割算法在PublicDataset上的对比结果Tab.1 Results of different algorithm tested on PublicDataset

表2 不同分割算法在EcustDataset上的对比结果Tab.2 Results of different algorithm tested on EcustDataset
相比于采用了DenseNet161的FuseSeg,本文算法使用参数量更小的DenseNet121在EcustDataset和PublicDataset上取得了具有竞争力的预测结果。我们的模型在“广告牌”、“自行车”和“建筑物”“围栏”等轮廓特征较明显的类别上具有较好的预测能力。对于“路标”等小类别,采用轮廓增强的方法也有助于模型进行分割。其他类别上我们模型的分割结果也具有竞争力。语义分割中常用的评价指标mIoU在所有算法中达到了最高水平。
图4展示了算法在PublicDataset数据集上的定性结果。第一列中汽车顶部的轮廓更加接近真实标签,第二列中错分的像素较少,第三列路障的直线边缘不合理的弯曲更少,第四列人的头部轮廓更加合理。图5展示了算法在EcustDataset数据集上的定性结果。图中第一列错分的像素相比其他模型明显较少,车的轮廓精确,路边围栏的轮廓也更加合理,第三列中“自行车”的轮廓最完整,行走路人的脚部细节也被较好的分割出来。第四列中“汽车”的分界也较为明确,证明了轮廓增强的有效性。很显然我们的模型在分割具有显著轮廓的物体时,例如路锥的倾斜直线轮廓,汽车的顶部,汽车的轮胎,自行车的轮胎等,具有明显的分割优势。

图4 不同算法在PublicDataset上的定性结果Fig.4 The qualitative results of different algorithm tested on PublicDataset

图5 不同算法在EcustDataset上的定性结果Fig.5 The qualitative results of different algorithm tested on EcustDataset
在两个数据库上比较的具体结果显示在表1及表2中。对比算法中,MFFENet[14]包含有两种模型,MFFENet(S)是指只使用语义标注进行监督的结果,MFFENet(M)是指使用语义标注,语义轮廓标注,显著性标注同时进行监督的结果。实验中发现,PublicDataset中“护栏”一类有一些0.0的mIoU结果并且结果普遍偏低,正如文献[9]中讨论的一样,数据集中的类是非常不平衡的。“护栏”类所占的像素最少,因此可以认为是由于训练数据不足,导致模型对该类不熟悉。从表1及表2中可以看出,我们的模型使用了较少的语义标注达到了较好的分割水平。“挡车器”、“路锥”和“障碍物”等边缘较为平直的物体的分割性能相较不使用语义轮廓信息的模型提升明显,其他类别也能取得有竞争力的结果,评价指标mIoU在所有算法中也达到了最高水平。
3.3.2 模型消融实验及分析
为了评估本文提出的各个模块,本节进行了消融实验,通过移除网络的不同部分来验证模块的有效性。
表3展示了消融实验结果,我们选择在PublicDataset上进行消融实验来验证我们设计的模块的有效性。基线模型是一个简单的U-net形网络,两个独立的DenseNet121提取的特征相加之后直接通过卷积和转置卷积上采样到原图大小。
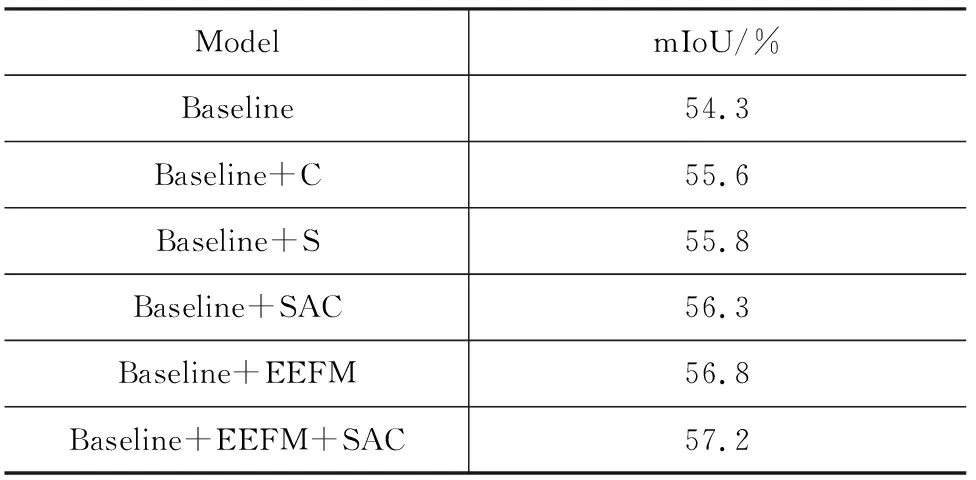
表3 PublicDataset上的模型消融实验Tab.3 Ablation studies on PublicDataset
首先研究本文提出的轮廓预测模块,轮廓预测模块带来了大约2.5 %的mIoU提升,可以看出,轮廓监督损失函数通过梯度反向传播改善了编码器的特征,提升了网络性能。然后研究本文提出的位置和通道注意力模块,通过位置注意力和通道注意力加权,模型性能由54.3 % mIoU提升至56.3 % mIoU。同时我们也探究了只使用位置注意力或通道注意力对模型分割能力的影响,注意力机制不完善使得精度提升不明显。图6中我们给出了实验对比的各个算法的参数量和mIoU的直观图示,显然我们的模型在综合性能上具有优势,在相对较少的参数量下取得了最好的分割精度。

图6 不同算法参数量和mIoU对比Fig.6 The compare of different algorithm on mIoU and parameters
3.3.3 损失函数权重影响分析
由于本文实验使用了多个损失进行监督,因此设计对比实验验证损失函数权重对算法的影响。实验中保持分割损失权重为1,改变轮廓监督权重λ。观察不同轮廓监督权重对分割精度的影响,从而得到合理的轮廓监督权重设置。实验结果如表4所示。通过表4数据可知,当轮廓监督权重过小或过大时,模型分割性能都会有不同程度的下降,可能的原因是权重过小时损失对模型影响不够充分,权重过大时影响了主任务(分割任务)提取的特征,因此,当有多个损失函数时,相互之间的权重需要找到一个权衡,才能使得模型性能最优。

表4 损失函数权重λ对比实验Tab.4 Comparison of different weights of λ
4 结 论
针对双波段图像语义分割目标轮廓易混淆的问题,本文提出了一种基于多尺度轮廓增强的RGB-IR双波段图像语义分割算法,在不同尺度的特征图上预测不同尺度的轮廓,利用预测的轮廓信息来加权特征图,增强了双波段融合特征的轮廓。最后将多尺度融合的特征进行位置信息和通道信息的加权,来获得更准确地分割结果。通过实验证明了本文算法的有效。在较小的参数量下在公开数据库中取得了57.2 %的最优mIoU,综合性能最优。设计的不同的消融实验验证了所提出模块的有效性。通过改变损失函数权重,分析了分割监督与轮廓监督不同权重下,算法性能的变化。
