基于深度强化学习的无信号交叉口车辆协同控制算法
2022-06-09蒋明智吴天昊
蒋明智,吴天昊,张 琳
(北京邮电大学,人工智能学院,北京 100876)
0 引言
智慧城市的一个重要标志是城市交通智能化和汽车网联化,实现网联汽车在无信号交叉口高效智能地协同通行已成为当今国内外的研究热点。同时,以车车通信(Vehicle-to-Vehicle,V2V)、车路通信(Vehicle-to-Infrastructure,V2I)为基础发展起来的车路协同系统使得多车协同控制成为可能[1-2]。
目前,无信号交叉口车辆协同控制方案主要分为传统数学模型和人工智能强化习方法两大类。前者主要包含基于协商调度[3-5]、基于规划[6-7]、基于模型预测[8]和安全场论[9-10]等方法,这类方法对车辆通过交叉口场景的轨迹、时间和次序进行建模求解,来获取车辆通过交叉口的控制策略。但是随着交叉口车流量的增加,基于传统数学模型方案所需的计算量往往呈指数级上升,因此这类方案不适用于较高车流量的交通场景[11]。深度强化学习(Deep Reinforcement Learning,DRL)以其独特的决策能力可以获得更好的控制策略[12-13],常用 的RL 算 法 有DQN(Deep Q Network)、PPO(Proximal Policy Optimization)和DDPG(Deep Deterministic Policy Gradient)等。Kai 等[14]采用DQN将交叉口导航问题建模为多任务学习问题;Shu等[15]提出了一个迁移-RL 框架,来提高自动驾驶车辆在无信号交叉口的控制性能和学习效率;Guan等[16]提出了一种基于模型加速的PPO 算法,解决了集中式控制方案中计算效率低的问题。目前大部分基于DRL的控制方案还主要局限于单车智能或者固定车辆数目的交叉口场景,在多车协同和适应动态高车流量的真实交叉口场景方面的研究还比较少。此外,无信号交叉口冲突点之间会形成多组交织环,交织环中的车辆会阻碍其他方向的车辆进入或驶出交织环,当交通流量较大时,交织环内的车辆可能会由于相互影响而无法正常驶出,而入口车流又不断驶入,则会造成交叉口严重的堵塞现象,称为“死锁”现象。“死锁”现象不仅严重影响通行效率,而且会增大交叉口车辆碰撞风险[17],对协同控制算法的性能带来了较大的挑战。
Wu 等[18]提出了多智能体协同深度确定性策略梯度算法(Cooperative Multiagent Deep Deterministic Policy Gradient,CoMADDPG),在双向单车道无转向的无信号交叉口场景实现了动态交通流场景下多车协同通过冲突区域。但是该算法存在值函数网络过早收敛的问题,导致多车协同控制精度较低且无法应对交叉口的“死锁”现象,当面临较大交通流量或复杂交叉口时,会出现碰撞情况。此外,该算法只是从安全性角度对多车协同驾驶进行优化,在车辆行驶综合性能方面表现不足。
本文基于DRL针对动态车流量的复杂无信号交叉口场景研究多车协同控制算法,其主要贡献点如下:
(1)提出了一种基于强化学习的渐进式价值期望估计的多智能体协同控制(Progressive Valueexpectation Estimation Multi -agent Cooperative Control,PVE-MCC)算法,该算法设计了渐进式价值期望估计策略,实现值函数网络的渐进式学习,并结合泛化优势估计算法[19],提高模型训练的稳定性和策略收敛精度。
(2)从安全性、通行效率和舒适度三个方面设计了多目标奖励函数引导策略优化,实现在提高车辆安全性的同时,兼顾交通效率和乘客舒适感。
(3)针对交叉口易出现的“死锁”现象设计了启发式安全干预策略和“死锁”的检测-破解策略,通过链表环形检测算法实现对“死锁”的检测和破解,进一步提高车辆行驶的安全性。
(4)搭建了双向六车道无信号交叉口仿真实验平台,从算法收敛稳定性、综合控制性能和协同控制精度三个方面,验证了本文所提算法的有效性,并开源了该平台和算法代码。
1 强化学习方法建模
1.1 问题描述
假设交叉口场景内所有车辆均为智能网联汽车,所有车辆之间均可通信且无时延和干扰,车辆通过交叉口时,具有明确的驾驶意图(如直行、左转或右转)。本文以车辆状态信息作为状态输入,加速度作为动作输出,引入DRL 实现车辆在无信号交叉口的协同控制策略。DRL 算法一般用于求解马尔可夫(Markov)决策过程,而求解该过程要求随机过程具有Markov 性,即系统下一时刻的状态只取决于当前时刻的系统特性,与之前任何时刻无关。在交叉口车辆的协同控制过程中,t时刻的交通状态是交通参与者状态的集合,状态信息包括加速度、位置、速度、车道等,可以发现,状态st由t-1 时刻车辆的动作所决定,而与之前的任何时刻的动作无关,因此,可以认为交叉口车辆的协同控制过程具备Markov 性。车辆在t时刻的纵向控制可以表示为:

式中:st表示t时刻交叉口的车辆状态;at表示决策模型在st下的决策加速度表示预训练的决策模型,该决策模型可以根据当前时刻的交叉口车辆状态,对驾驶行为做出决策;pt+1表示t+1时刻车辆与交叉口的距离;vt+1表示下一时刻的速度;T表示控制周期。
本文设定典型的双向六车道无信号交叉口作为实验场景,在交叉口场景中,车辆具有直行、左转、右转三种驾驶轨迹,忽略超车和换道行为[20],车辆保持固定轨迹通过交叉路口,并采用车辆纵向动力学线性模型来描述车辆的动力学特性[21]。无信号交叉口场景及车辆运动示意图如图1所示。

图1 无信号交叉口场景及车辆运动示意图
考虑到交叉口场景中交通状态空间大,车辆的加速度控制属于连续动作空间,而且要实现多车协同控制,本文在DDPG 算法的基础上设计了PVE-MCC 算法进行求解。PVE-MCC 算法采用actor-critic 双网络结构,并引入目标网络解决模型更新时的波动性问题。算法中包含的四个网络分别为动作网络π、目标动作网络π′、值函数网络Q和目标值函数网络Q′。此外,该算法挑选固定数量的车辆作为决策参考车辆,使值函数网络进行价值评估时,除了考虑自身的动作,还结合决策参考车辆的动作对协同性进行评估,来达到多车协同控制的目的。假设训练样本来自策略β,该算法的目标函数为:

式中:ω和ω′分别为值函数网络Q和目标值函数网络Q′的参数;θ为动作网络π的参数;ct=[a′1,a′2,…,a′N]表示t时刻N辆决策参考车辆的动作集;γ为折扣因子;rt为t时刻环境的即时奖励。
1.2 状态空间和动作设计
本文采用虚拟车道映射的方法,将有冲突关系的两个车道以冲突点为结点进行旋转投影,映射为一条虚拟车道,在虚拟车道上将不同车道的车辆构建前后车关系,通过实现虚拟车道上的车辆保持合理间距来避免冲突点处的横向碰撞问题,即将二维的碰撞问题简化为一维碰撞问题求解。令目标车辆i的信息集合Ii=[pi,vi,ai,li],pi、vi、ai、li分别为位置、速度、加速度和车道;状态空间为为车辆i在虚拟车道上最邻近的N辆车的状态信息;为车辆i在虚拟车道上最邻近的N辆车的动作集。决策车辆的动作为加速度ai,,am和aM分别为加速度的最大值和最小值。
1.3 多目标奖励函数设计
动作网络π的终极目标是使得期望累计回报最大,期望累计回报为:

式中:Gt为累计回报;rt+k为t+k时刻的即时奖励,因此,奖励函数的设计直接决定了动作网络的收敛方向。
本文从安全性、交通效率和舒适性三个方面设计了多目标奖励函数。
(1)安全性
安全性是车辆行驶最重要的考虑因素,目标车辆与其在虚拟车道中最邻近车辆的预计碰撞时间(Time to Collision,TTC)和相隔距离Sd被作为安全性的评估因素。安全性问题的奖励函数表示为:

式中:pi(t)和vi(t)分别是目标车辆i的位置和速度和分别是其最邻近车辆的位置和速度;rTTC(t)和分别是在时间和空间维度上的奖励函数;dthr和tthr分别为判定是否安全行驶的距离和时间阈值,当低于这个阈值时,认为行驶状态有碰撞风险,则奖励函数生效,对策略模型的决策进行惩罚,否则安全性奖励函数不生效,使模型更注重其他优化目标的学习;α为非线性伸缩因子。
(2)交通效率
当所有车辆都能以最大速度通过交叉口时,交通通行效率最高,本文以车辆的归一化速度作为车辆效率的奖励因素,以rE(t)作为效率的奖励函数,表示为:

式中:vM和vm分别是交叉口的最大和最小限速。
(3)舒适性
加速度变化率(jerk)对人体驾驶舒适度有直接的影响,常被用于作为驾驶舒适度的衡量指标,本文对舒适度的奖励函数rjerk(t)定义为:
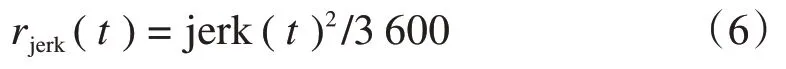
式中:3 600是将数值区间归一化到[0,1],本文设置的车辆控制周期是0.1 s,加速度最大最小值分别是-3 m/s2和3 m/s2,jerk(t)2最大值为3600。
(4)多目标奖励函数
当目标车辆发生碰撞或者驶出交叉口时,本文采用常量作为奖励值,将安全性、效率和舒适度奖励函数汇总后的多目标奖励函数表示为:

式中:φe和φj分别是交通效率和舒适性奖励对应的权重系数。
1.4 动作网络和值函数网络设计
算法由动作网络Actor 和值函数网络critic 组成,actor网络根据状态对车辆做出动作决策,critic网络结合状态信息和决策参考车辆的动作集对actor 做出的动作进行Q值评估。st状态空间为长度28的一维数组,由目标车辆和6辆决策参考车辆的状态信息组成;ct为长度为6的一维数组,表示决策参考车辆的动作。采用全连接神经网络层提取特征,并对每层数据进行归一化处理,Relu 作为激活函数,详细网络结构见图2。

图2 神经网络结构
2 渐进式价值期望估计的多智能体协同控制算法
2.1 泛化价值期望估计
值函数网络critic 利用时序差分法(Temporal Difference,TD-error)根据当前时刻价值和下一时刻价值估计得到目标价值。TD-error是蒙特卡洛法和动态规划法的结合,但是这种方法在值函数网络学习欠佳时,会存在较大的价值估计偏差,容易导致模型学习波动大、学习缓慢和陷入局部最优解。而泛化优势估计(Generalized Advantage Estimation,GAE)算法可以有效地平衡值网络函数估计目标价值带来的偏差和方差[18],PVE-MCC 算法结合GAE进行改进可提升训练的稳定性。
定义动作集[at,ct]的优势价值估计为rt+γQω′(st+1,at+1,ct+1)-Qω(st,at,ct),可以发现,是一个γ-just的估计函数,接下来考虑多步价值估计的情况,用表示n步的优势函数估计:

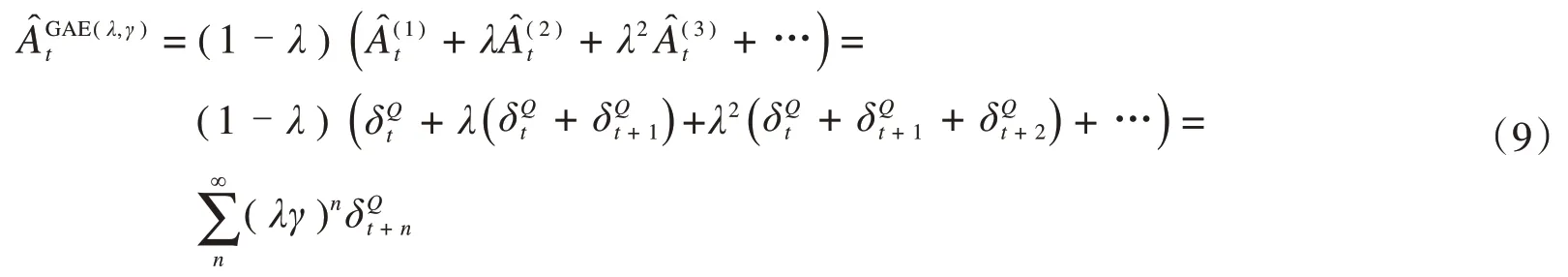
2.2 渐进式价值期望估计策略
在Actor-Critic 双网络结构中,动作网络的目标是最大化价值期望,而值函数网络的目标是最小化价值期望误差,其中折扣因子γ表示下一时刻价值期望相对于当前时刻的权重,γ值越大,表示越重视长期得到的回报,γ越小,则越重视短期的回报。
当训练前期值函数网络还没收敛时,如果γ值设置过大,容易造成TD-error 不稳定,使值函数网络训练波动,因此,此时γ值设置不应过大,应该加强真实环境奖励值的引导,即先关注短期回报。但是当值函数网络学习到一定程度时,应该逐步加大γ值,增强对长期期望的学习。这种先易后难的学习思想与人类的学习习惯也是一致的,这样更有益于模型收敛精度。基于这种思想,本文通过动态调整折扣因子,实现对价值期望的渐进式估计,表示如下:

式中:γM为最大折扣因子;eposide为训练幕数;δ1和δ2为调整参数;当eposide=0 时,γ0=tanh(δ1/δ2)×γM。从公式可以看出,折扣因子γ随训练批次eposide的增大而非线性增大,eposide越大,增长越缓慢。γ值越大,表示越关注长期期望,对策略收敛精度要求也更高,模型学习也更缓慢,为了减小波动,此时γ不能增长过快。
2.3 策略更新
PVE-MCC 算法采用off-policy 的训练策略,将动作策略与环境交互产生的样本存入经验池中,每次优化时从经验池中随机抽取一部分样本进行策略优化,这样既提高了样本的利用率,同时可以减少一些不稳定性。目标网络更新方面,采用滑动平均的方法更新目标网络,降低目标网络参数的更新速率,使值函数网络模型在一定程度上减少波动,令计算更稳定。为了解决确定性策略探索不够充分的问题,采用了o -greedy 的探索方法,通过为确定的行动增加噪声来增加模型的探索能力。
综上,PVE-MCC算法伪代码见图3所示的算法。

图3 PVE-MCC算法伪代码
2.4 安全干预策略
动作网络π的策略由神经网络参数通过梯度更新逐步优化而来,因此不能保证决策动作的绝对安全,本文采用了基于运动学的停车距离算法来计算紧急制动所需的最小安全距离dsafe,当车辆i与前车距离低于dsafe时,用最小加速度强制制动,表示如下:

式中:RT为反应时间;vi、vi-1表示本车和前车速度;vm表示最低时速;am为最小加速度;dfront表示与前车距离。
2.5 “死锁”检测-破解策略
本文提出一种基于链表环形检测算法的“死锁”检测-破解策略来提前降低碰撞风险。首先以双向单车道直行交叉口场景为例,描述“死锁”的形成、检测和破解过程,该策略流程示意图如图4所示。

图4 冲突点“死锁”现象检测-破解流程图
流程具体细节如下:
(1)具有冲突关系的车辆以冲突点为旋转中心,映射到冲突车道中形成虚拟车,与冲突车道中的实体车呈现前后车关系,形成虚拟车道。
(2)根据链表检测成环的思想,将虚拟车道采用链表表示,车辆为结点,从任一结点向前查询有限步,如果能回到起始结点,则表明这部分车辆形成“死锁”环,如图4 中的步骤2:V2车通过S1、S2、S3、S4检测后,又回到V2,此时,V1、V2、V3和V4车辆就形成“死锁”环。
(3)当交叉口车流量达到一定程度时,车车间形成“死锁”环很普遍,所以本文只对环中车车平均间隔不足以保证安全通过交叉口时或破解成本较低时,进行死锁环破解,破解方法为找到环中间隔最小的两辆车,强制改变相对位置。
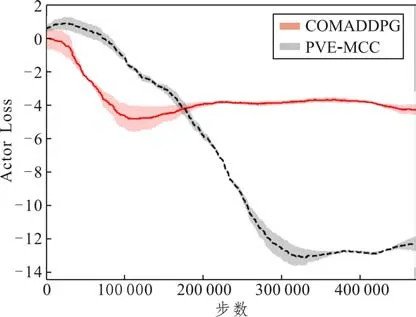
假设“死锁”中的车辆数目为m,环中车车间隔为S=[S1,S2,…,Sm],当min(S) 式中:dmin为最小间隔;dmean为平均间隔和为间隔最小的前后车加速度输出;考虑对舒适度的影响,此处采用增量法对加速度进行改变,al为每次调节的加速度增量。 为了验证所提算法在无信号交叉口场景的协同控制性能,本文基于python3.5 开发了双向六车道无信号交叉口仿真实验平台,设定车辆进入交叉口的时间服从泊松分布,且交通流量大小可控。该平台简化了交通环境和车辆物理模型,采用纵向车辆动力学线性模型来描述车辆的动力学特性,该平台具有运行效率高、灵活性强、轻量级、易于部署等特点,适合用于验证多车纵向协作性能。本文将此部分实验涉及的仿真平台和PVE-MCC算法源码,以及相关训练和测试数据文件开源到github 平台,具体地址链接为:https://github.com/Mingtzge/PVE-MCC_for_unsignalized_intersection。 本文以适用动态车流无信号交叉口场景的CoMADDPG 算法[14]作为对比方案,设计了三个实验验证本文所提PVE-MCC算法的性能: (1)实验一验证算法的收敛性和稳定性,从训练过程中奖励值上升曲线、碰撞率和损失Loss 曲线的变化情况三个方面进行体现和说明。 (2)实验二验证综合控制性能,针对不同级别的车流量,将所提算法从安全性、交通效率和驾驶舒适性方面进行对比。 (3)实验三在更高车流量场景和更复杂无信号交叉口场景中对比两个方案的协同控制性能,以验证所提算法的协同控制精度。 其中,实验一和实验二为了避免更换交叉口场景带来的算法通用性的影响,将PVE-MCC 算法应用到CoMADDPG 算法一致的交叉口场景中进行实验对比,该场景为双向单车道无转向的无信号交叉口。第三个实验场景为双向六车道带直行、左转、右转的无信号交叉口。 实验模仿了真实道路的交通流场景,每个车道的车进入交叉口的时间序列Tseq=[t1,t2,…,tn],每个车道的Tseq随机生成,且服从泊松分布,为了保证车辆进入交叉口时不发生追尾情况,限制了同一车道前后车到达间隔时间不低于。Tseq的生成方式表示为: 式中:FR为交通流量(车辆数目/车道/h);R为服从(0,1)正态分布的随机变量。可以通过改变FR获得不同交通流量的车辆到达时间序列,实现对不同交通流场景的测试目的。测试时,在不同大小交通流量的场景下对本文所提算法进行了长时间测试,每个场景测试时长为1 h。训练时,通过预生成长时间的时间序列,实现不间断的在线训练。无信号交叉口场景相关参数见表1 仿真环境参数部分。计算机环境:训练和测试均采用单GPU 进行计算,GPU 型号为NVIDIA TITAN XP,GPU 内存为12 G,CPU 型号为E5-2620 v4,主频2.10 GHz。 表1 算法和环境参数 续表1 对于实验一,图5展示的是不同算法的神经网络模型在训练过程中每一幕(连续训练6 000 步为一幕)交叉口碰撞率的变化情况,图6 展示了环境平均奖励值随训练过程的变化情况,图7 和图8 展示的是Actor 和Critic 网络的Loss 曲线的变化情况,图6、7、8中阴影为波动范围,实线为移动平均,本实验训练时长为75 h。从碰撞率的变化情况看,PVE-MCC和CoMADDPG算法在训练前期都具有收敛迹象,但是后者在收敛后仍然处于波动状态,陷入了局部最优解,而前者则可以保持稳定的性能。从图6 可以看出,CoMADDPG 算法似乎收敛速度更快,但是当算法收敛后,奖励值便过早停止增长了,而PVE-MCC 算法可以保持稳定增长,并最终保持在了一个更高的数值。同样地,从图7和图8也可以看出,CoMADDPG算法的critic和actor网络的Loss 曲线过早地停止下降,说明此时神经网络参数已经无法优化到更优的策略。出现这种现象的主要原因还是Critic 网络无法保持长期精细的学习,而Actor 网络的Loss 来自critic 网络的输出,后者的性能对前者有决定性的影响。而PVE-MCC 算法则这对这一缺点进行了针对性的改进和设计,首先采用GAE 算法对价值估计偏差进行弥补,减少网络的波动性,再通过PVE 策略由短期估计到长期估计渐进式地改变Critic 网络的价值期望目标,使其具有持续学习的能力。从实验结果看,PVE-MCC 算法达到了预期的目的,相对于CoMADDPG 算法,在收敛性和稳定性方面具有更优的性能。 图5 交叉口碰撞率随训练过程的变化 图6 平均奖励值随训练过程的变化 图7 Actor网络Loss曲线随训练过程的变化 图8 Critic网络Loss曲线随训练过程的变化 对于实验二,以车辆的平均通行延迟时间作为通行效率指标;以每辆车的加速度变化率绝对值之和表示该车的舒适度,该数值越低表示驾驶舒适度越好,最终以所有车舒适度的平均值作为总体舒适度的评价指标;采用安全通过率作为安全性指标;不同的交叉口吞吐量表示不同的交通流量大小。本实验具体数据统计在表2,从数据上看,CoMADDPG 算法在交通流量大于一定数值时,提前出现了碰撞,说明本文所提PVE-MCC 算法在安全性方面性能更优,且可以适应更高车流量的交叉口场景。在通行效率和舒适度方面,图9比较了两种算法中车辆平均通过交叉口所延迟的时间,该值为平均通行时间与最快通过时间的差值。最快通过时间是车辆从进入交叉口开始,以最大加速度通过的时间,从图9 中可以看出,PVE-MC 算法的通行效率明显优于对比算法,与最快通过时间只有较小的差距。图10统计了不同交通流量大小下车辆舒适度的平均值,可以看出,PVE-MCC算法的驾驶舒适度优于对比算法,交通流量越大,差异越明显。 图9 通行效率对比 图10 舒适性对比 表2 PVE-MCC与CoMADDPG算法性能对比 对于实验三,为了验证本文所提算法的协同控制精度,将PVE-MCC 算法应用到了更高车流密度和更复杂的双向六车道带转向的无信号交叉口场景,具体数据见表3。从数据可以看出,即使在较高车流量和更复杂的交叉口场景中,本文所提算法在综合控制性能方面依然可以保持较好的性能,说明PVE-MCC算法具有良好的协同控制精度。 表3 双向六车道无信号交叉口场景PVE-MCC算法性能 此外,对多目标优化奖励函数而言,不同优化目标的权重配置对于深度强化学习算法的训练以及最终的性能有直接的影响。针对效率奖励值权重和舒适度奖励值权重的设置,本文对[0.5,1.0,2.0,3.0,5.0,7.0 ]6 组参数两两组合进行了36 组实验,其中效率奖励值权重设为2.0,舒适度励值权重设为3.0,筛选出相对最优的权重组合。 本文基于深度强化学习针对城市道路无信号交叉口提出了一种渐进式价值期望估计的多智能体协同控制算法PVE-MCC。PVE-MCC 算法设计了泛化优势估计和渐进式价值期望估计策略,在减少值函数网络的波动时,将价值期望由短期到长期渐进式地过渡,使其可以保持持续性的学习能力,避免了过早地陷入局部最优解,使算法策略在稳定性和收敛精度方面均得到了有效地提升。在算法综合控制性能验证方面,PVE-MCC 算法设计了安全性、效率和舒适度多目标优化奖励函数和基于启发式规则的安全干预策略,提高了算法综合控制性能。此外,本文设计开发了双向六车道无信号交叉口仿真平台,在该平台测试了PVEMCC算法应对更高车流密度和更复杂的交叉口场景的能力,实验结果展示该算法在各个实验指标均能表现出较好的性能,说明了该算法具有良好的协同控制精度。仿真平台和算法代码已开源。未来的研究将在本研究的基础上对算法的实用性和通用性做进一步探讨。
3 仿真验证
3.1 实验设置



3.2 实验结果和分析







4 结论
