森林资源调查监测中的数据耦合方法研究
2022-06-09曾伟生
曾伟生
(国家林业和草原局林草调查规划院,北京 100714)
从1973—1976年的第一次全国森林资源清查至今,我国森林资源调查监测工作已经有近50年的发展历史[1]。其中,国家层面开展的森林资源连续清查(简称一类清查)已经完成了9次,地方组织开展的森林资源规划设计调查(简称二类调查)也完成了4~5轮。由于其服务目的不同,2类调查体系一直独立运行。随着社会对森林资源的关注度日益提高,国家和地方2套调查监测体系不协同、数据不一致的问题逐渐显现[2-3],推进全国森林资源一体化监测体系建设已成为发展趋势[4-5]。
2018年国家机构改革后,自然资源部出台了《自然资源调查监测体系构建总体方案》(1)自然资源部.自然资源调查监测体系构建总体方案.2020.。2020年,国家林业和草原局按照总体方案的基本思路和职责分工,制定了《国家森林资源年度监测评价方案》(2)国家林业和草原局.国家森林资源年度监测评价方案.2020.,并在北京、浙江、广西、重庆4省(自治区、直辖市)开展试点;2021年,国家林业和草原局进一步制定了《国家林草生态综合监测评价技术方案》(3)国家林业和草原局.国家林草生态综合监测评价技术方案.2021.。这2个方案中均提到要“采取森林资源管理一张图更新与校验样地调查核实相结合的方式开展森林面积监测”“将样地监测数据和图斑监测数据耦合,实现林草资源监测数据以点推面、点面衔接”。但如何做到点面结合,方案中并未给出明确具体的方法。
本文将利用2020年国家森林资源年度监测评价北京市试点项目的相关数据资料,基于试点工作经验和做法,对森林资源调查监测中的数据耦合方法进行探讨,以期为开展国家林草生态综合监测评价的统计出数提供参考依据。
1 数据与方法
1.1 数据资料
1.1.1研究区概况
北京市位于华北大平原的西北边缘,地理坐标为39°28′~41°05′N,115°25′~117°30′E,国土面积16 410km2。属暖温带半湿润大陆性季风气候区,夏季高温多雨,冬季寒冷干燥。平原地区年均气温11~12℃,低山区8.5~9.5℃,中山区3~4℃;年降水量650~750mm,大多集中在6—8月[6]。根据第九次全国森林资源清查结果,北京市森林面积71.82万hm2,森林覆盖率43.77%,森林蓄积量2 437.36万m3[7]。
1.1.2样地调查数据
样地调查数据包括2020年国家森林资源年度监测评价北京市试点项目完成的1 705个乔木林固定样地复查资料和1 030个面积1 km2的校验样地资料,也就是本研究所称的点状数据。固定样地复查按《森林资源连续清查技术规程》[8]执行,包括样地因子调查、样木因子调查和其他调查内容。校验样地以高分遥感判读为主,对1 km2范围内的所有图斑进行全面复核,对区划不精细、属性不准确的图斑进行更新和改正;对借助高分遥感影像或相关资料在室内无法判定的或对判定结果无把握的,需到现地调查核实②。
1.1.3图斑调查数据
图斑调查数据包括2019年完成的全市森林资源规划设计调查(简称二类调查)数据和2020年、2019年完成的北京市森林资源管理“一张图”更新数据(分别更新至2019年底和2018年底),也就是本研究所称的面状数据。森林资源管理“一张图”更新数据是在2014年二类调查数据的基础上逐年更新而来。2019年二类调查数据是北京市的最新调查数据,相对于年度更新数据更为准确可靠。
1.2 基本方法
国家森林资源连续清查,是基于系统抽样方法同时对面积和蓄积数据进行估计,各省主要数据有精度保证,也是目前最权威的数据,但落实不到具体地块。而地方二类调查,是基于小班调查方法对面积和蓄积进行调查,数据能落到每个小班地块,但数据的准确程度受诸多因素影响,也难以得出各省主要数据的精度指标[2]。如何将宏观层面的点状数据与微观层面的面状数据有机结合起来,解决长期存在的国家与地方森林资源两套数、两张皮的问题,一直以来都受到广泛关注,也有学者在努力探寻解决之法[3,9-10]。本研究提出以校验样地作为点面数据耦合的桥梁,基于校验样地修正更新森林面积,基于地面样地分层估计森林储量(蓄积量、生物量、碳储量),构建点面数据有机结合、总量数据分级控制的一体化监测体系。
1.2.1基于校验样地的面积估计
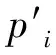

(1)
式中:每种二类调查地类的面积成数pj是已知的,它相当于每种地类(可视为分层抽样的“层”)所占的权重;转移概率pij从转移矩阵算出,相当于第j层中目标地类i的抽样估计成数。因此,(1)式相当于分层抽样的成数均值计算公式[11-12]:
(2)
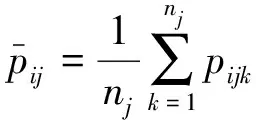
其方差可按分层抽样计算,计算公式为:
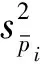
(3)
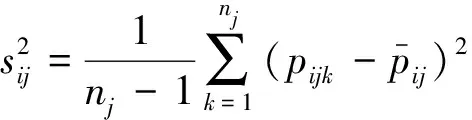
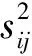
基于校验样地按分层抽样方案进行估计时,每一层内的均值和方差可按系统抽样计算。但是,由于落在每个层的样地面积大小不等,从严格意义上讲,应该按不等群的整群抽样计算才是合适的。其均值和方差的计算公式[13-14]为:

(4)
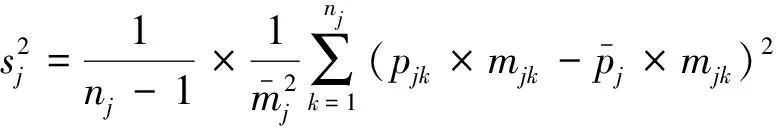
(5)
式中:mjk为第j层第k个校验样地(视为由mjk个1hm2的样地组成的整群样地)中的样地个数(等于以公顷为单位的面积值),pjk×mjk也就是第k个校验样地中目标地类的面积。
1.2.2基于分层抽样的储量估计
以森林三储量(蓄积量、生物量和碳储量)估计为例,将北京市全部乔木林固定样地,按起源分成天然林、人工林2个类型,或按行政区域分成若干个副总体,采用分层抽样公式计算每公顷储量和方差[11-13]:
(6)
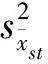
(7)
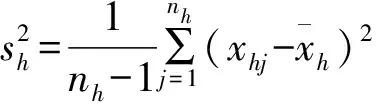
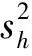
分层抽样估计时,层的划分要考虑样本的支撑程度,原则上每个层的估计值应当达到预定的精度要求,如85%或80%以上。各层的权重(wh)可根据森林资源二类调查或“一张图”各类型(天然林、人工林)或各副总体乔木林面积数据计算。根据(6)式、(7)式即可计算乔木林每公顷储量估计值的相对误差和抽样精度。将乔木林每公顷储量再乘以全市乔木林面积,即可得到全市的总储量(蓄积量、生物量和碳储量),其精度可由乔木林面积精度和每公顷储量精度联合估计。
2 结果与分析
2.1 面积估计结果
以北京市2019年二类调查数据、2019年森林资源管理“一张图”更新数据和2020年一张图更新数据共3套面状数据为基础,利用1 030个1km2校验样地主要地类的转移矩阵数据(基于二类调查数据的转移矩阵,如表1所示),分别估计森林面积和乔木林面积。按分层抽样计算时,分层数量不同,其计算结果是略有差异的,一般不宜划分过多的层。作为对比,基于前述3套数据,按3种分层方案计算乔木林、特殊灌木林及森林面积,结果如表2所示。
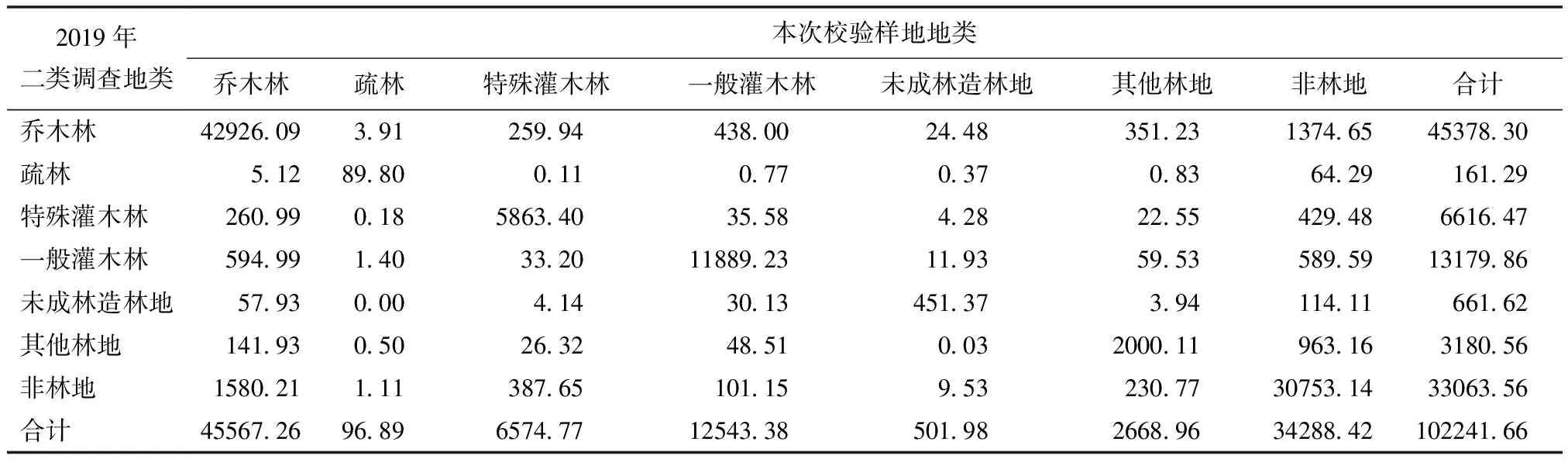
表1 基于2019年二类调查数据和校验样地数据的转移矩阵
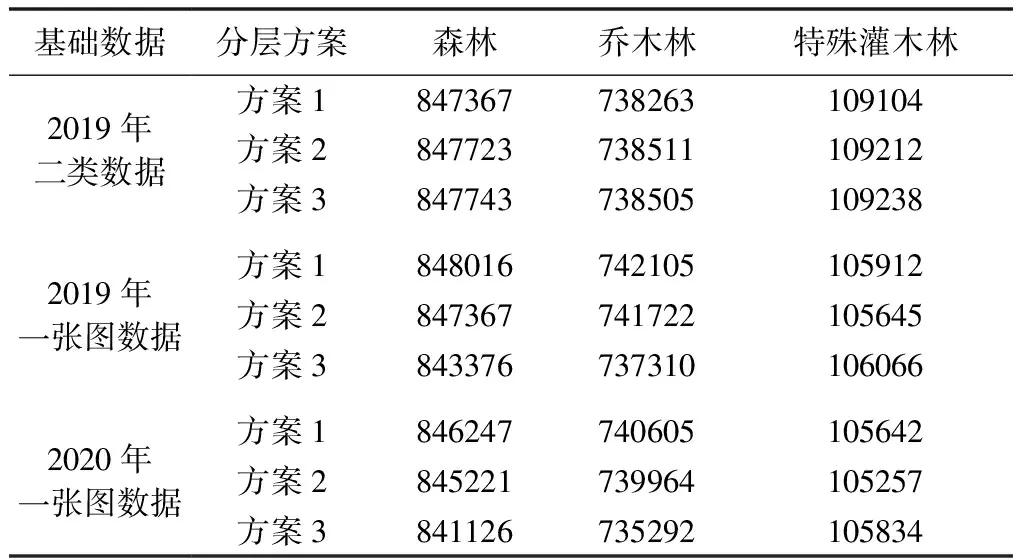
表2 不同分层数量的森林面积计算结果对比
从表2可知,分层数量多少对计算结果的影响不大,尤其是基于2019年二类数据的计算结果,3套方案差异很小。综合考虑基础数据质量及计算工作量,拟采用2019年的二类调查数据作为与校验样地联合估计的基础数据。因为重点关注的是森林面积和乔木林面积,下面进一步对森林和乔木林面积的不同估计方案进行对比分析。表3列出了按不同分层方案和抽样估计方案的计算结果。
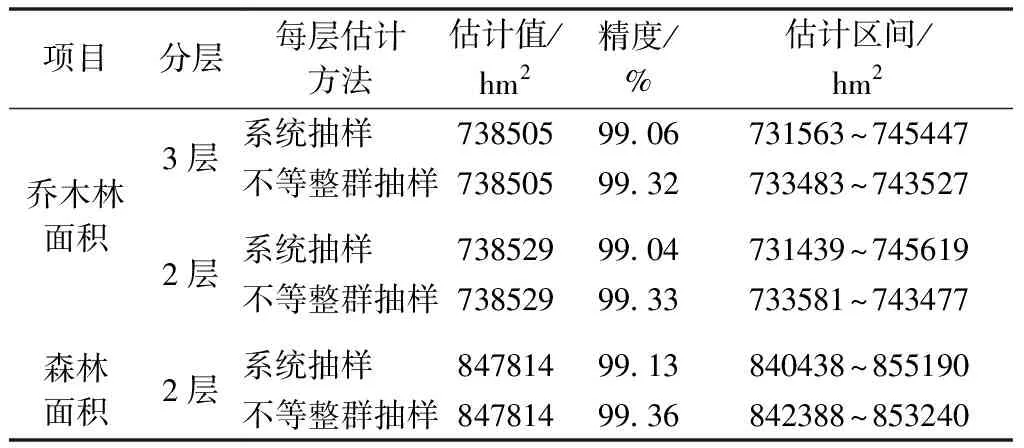
表3 不同分层方案和抽样估计方案的计算结果对比
通过表3、表2的各项对比分析可知,分层抽样中的“层”并非越多越好,按地类分多个层与分2个或3个层相比差异很小;通过点面结合,森林面积和乔木林面积的估计精度达到99%以上。因此,计算森林面积和乔木林面积时,只需分别按森林、非森林和乔木林、非乔木林分2个层即可;每层的均值和方差可按系统抽样近似计算,采用严格意义上的不等整群抽样计算的抽样精度要略高于按系统抽样计算的抽样精度。
2.2 储量估计结果
将北京市2020年完成的1 705个乔木林固定样地(剔除非乔木林样地),分成天然林、人工林2个类型(因为商品林比例很少,不再分公益林和商品林),分别代表2个层;按行政区域分成延庆、怀柔、密云、昌顺平(昌平、顺义、平谷)、门&房(门头沟、房山)、其他8区(东城、西城、朝阳、丰台、石景山、海淀、通州、大兴)6个副总体,按分层抽样公式计算每公顷储量(蓄积量、生物量和碳储量)和抽样精度;将乔木林每公顷储量再乘以全市乔木林面积,即可得到全市的总储量(蓄积量、生物量和碳储量),其抽样精度可由乔木林面积精度和每公顷储量精度联合估计。表4为基于分层抽样统计的森林储量结果。
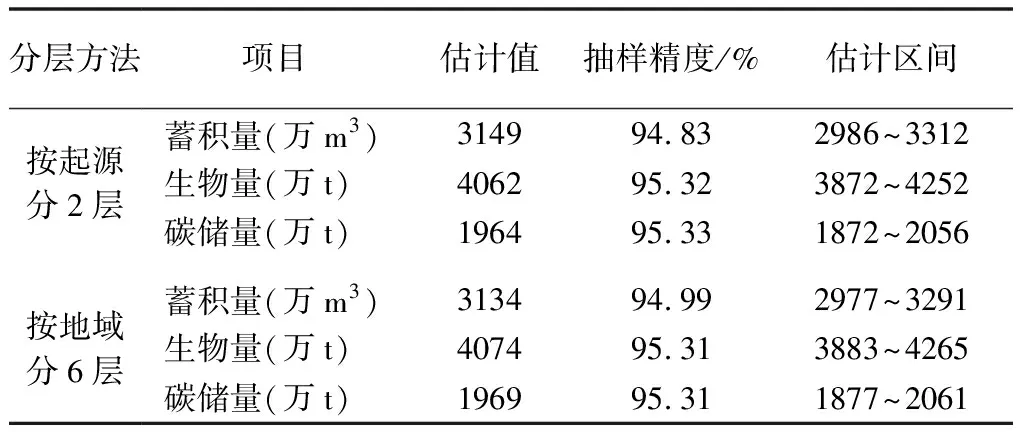
表4 基于分层抽样的森林储量统计结果
从表4可知,按起源分2个层或按地域分6个层,其计算结果差异很小,全市3项储量指标的抽样精度都在95%左右。为了解决国家与地方森林资源2套数的问题,储量的分层抽样方法应当考虑按地域分层。如北京市按地域分为6个副总体,可保证每个副总体的储量估计精度在85%以上。以这6个副总体的抽样估计数据作为点面数据的耦合节点,向上按分层抽样得出全市的总量估计值,向下按总量控制对各区二类数据进行平差并落实到图斑或小班,从而保持上下各级数据之间的衔接。
3 讨论与结论
3.1 讨论
自1973年的全国林业调查工作会议以来,我国的森林资源调查一直分为森林资源连续清查、森林资源规划设计调查和森林资源作业设计调查3类。由于作业设计调查主要为森林经营单位的造林、抚育、采伐等专项活动服务,与森林资源调查监测有关的通常是指前面2类,也常简称为一类清查和二类调查。由于一类清查和二类调查是2套体系,其成果数据不完全一致是正常的。但毕竟调查的对象都是森林资源,如果调查范围和调查时间一致的话,其主要资源数据应该是大体一致的。如果不一致,说明至少其中的1套数据有问题。有学者分析2套数据不一致的因素包括技术标准、调查时间和调查质量3个方面[2],为此提出通过产出1套综合数据以解决二者的协调性问题[3],以及借鉴国外森林资源清查中的相片样地或景观样地设计,提出衔接一类清查和二类调查的大样地设计新方案[9]。后来大样地调查方案在广东开展了应用试点[15],并在全国森林资源宏观监测中得到进一步的推广应用[14,16]。本文的校验样地,就是衔接一类清查和二类调查的大样地,它既是抽样调查样本,又含有区划调查内容,是介于一类样地调查和二类小班调查之间的中间形式。如果2套数据在正常的抽样调查允许误差内,通过校验样地的应用,可以将点面数据有机结合起来;但如果2套数据相差过于悬殊,可能难以一步衔接到位,则需采取分步实施的做法。
另外,一类清查和二类调查数据要实现完全的衔接也是不现实的。一类清查以抽样调查为基础,以样地为调查单元,工作量较小,林分和单木水平的信息比较精准;而二类调查以区划调查为基础,以小班为调查单元,工作量较大,林分和单木水平的信息比较粗放。因此,2套数据的衔接,首先是寻找合适的耦合点,通过点面数据的结合,产出总量指标,以保证主要指标(如森林覆盖率和森林蓄积量2项约束性指标)的一致性。主要指标往下细分的各类构成数据,还是可以按2套体系分别产出,做到数据互补和信息共享即可。
最后需要说明的一点是,本文的相关估计结果仅作为方法研究之用,不作为评估北京市森林面积和森林储量的依据。
3.2 结论
基于本文的研究,可以得出以下结论:
1)校验样地可检测森林资源“一张图”或二类调查数据的质量,修正和更新数据存在的错误和不足,是控制总体森林面积的重要手段,也是实现点面数据耦合的重要构件。
2)地面样地既可为总体森林储量估计提供基础数据,又可实施分级控制,将总体统计数据逐级落实到图斑,是推进森林资源一体化监测的坚实基础。
3)基于校验样地修正更新森林面积数据、基于地面样地分层估计森林储量数据的基本技术思路,在实践中是可行的。
4)基于校验样地计算森林面积和乔木林面积时,只需分别按森林、非森林和乔木林、非乔木林分2个层即可;计算每层的均值和方差时,应当采用不等整群抽样估计方法。
