联合生成对抗网络和检测网络的SAR图像目标检测
2022-06-08韩子硕王春平
韩子硕,王春平,付 强,赵 斌
(陆军工程大学石家庄校区 电子与光学工程系, 河北 石家庄 050003)
合成孔径雷达(synthetic aperture radar, SAR)是一种主动式的微波成像传感器,可以全天候、全天时地执行遥感监视任务[1],其多极化和高分辨率成像模式为对地监测提供了大量可利用数据。以此为基础,SAR图像目标检测技术得以蓬勃发展,并广泛应用于军事和民用领域。然而,由于SAR图像复杂的内在特性和较差的观测效果,传统的目标检测算法[2-5]收效甚微。随着深度学习算法的崛起,启发于神经网络在可见光图像目标检测领域的巨大成功,研究人员开始将其应用于SAR图像目标检测当中,并取得了一定成果,例如车辆检测[6]、舰船检测[7-8]、地质检测[9]等。
深度学习在可见光图像目标检测领域所取得的成就,得益于大数据为其提供源源不断的训练样本,而相较于可见光图像数量多、易收集的特点,SAR图像因获取方式单一、代价大,目前公开数据却很少。除此之外,执行数据注释也是一项非常耗费精力和成本的任务。因此,研究人员开始追求以有限数据获取高效网络模型的方法,进而数据增强技术应运而生。目前应用较多的数据增强技术可分为三类:仿射变换[10-11]、数据合成[12-13]和数据生成[14-15]。仿射变换通过图像旋转、拉伸、剪切、色彩变换、区域擦除等图像处理操作获取扩展图像,但其不能深层次地挖掘目标图像特征,因此目标多样性并没有发生根本变化,甚至当使用大量扩展图像训练深度学习模型时,网络将产生过拟合现象[16]。数据合成通过将目标切片随机镶嵌于新的背景当中获取扩展图像,但其并不能保证合成图像能够始终精确地模拟原始图像的视觉环境,而且此方法还需要大量的外部数据支持[17]。数据生成主要是通过生成对抗网络(generative adversarial network, GAN)来生成新的图像,其强大的特性以及逼真的新生图像,深受业界人士追捧。
GAN由Goodfellow等[18]于2014年提出,并应用于视觉图像生成,从此许多基于GAN的衍生模型相继而来。深度卷积生成对抗网络[19](deep convolutional GAN, DCGAN)用卷积神经网络(convolutional neural network, CNN)和全局池化层分别代替GAN中的多层感知机和全连接层,以稳定GAN的训练过程。Arjovsky等[20]提出的WGAN,通过更加科学地度量生成数据与真实数据之间的差异, 很大程度上缓解了梯度消失和模式坍塌问题。Andrew等[21]提出的BigGAN,通过扩大网络批处理数量和增加卷积通道,并以截断技巧平稳训练过程,使GAN性能得到大幅提升。Zhang等[22]将注意力机制引入GAN中,使网络能够自我学习应该关注的区域,像素之间的空间关联性也得以增强,解决了卷积结构所带来的感受野受限问题。Karnewar等[23]提出的MSG-GAN,允许梯度流从鉴别器到生成器在多个尺度上流动,为高分辨率图像生成提供了一种稳定的训练方法。随着GAN模型的不断优化,生成图像愈加逼真,其常被应用于各种预测任务,如:文本检测[24]、字体识别[25]、目标检测[26]、人体姿势估计[27]等。Gaidon等[28]指出用生成数据对神经网络进行预训练,可提升网络性能。
基于以上分析,本文提出将GAN应用于SAR图像目标检测中,并将其与超快区域卷积神经网络(faster region-based convolutional neural network, Faster R-CNN)相结合,构建集数据增强与目标检测于一体的深度学习模型,目的是在数据样本有限的前提下,高效完成目标检测任务。其中,提出了基于自我关注机制的深度卷积生成对抗网络(self-attention DCGAN, SA-DCGAN),生成高质量的数据样本,并利用概率等价类属标签分配策略充分挖掘生成的无标签图像潜力, 进而对原始训练集进行数据扩充,最后通过特别设计的Faster R-CNN实现SAR图像目标检测。
1 整体网络框架
为了更加直观地展现本文用于SAR图像的半监督目标检测算法,图1给出了所提算法的基本网络框架。训练过程如下:首先,利用原始训练集对特别设计的Faster R-CNN检测网络进行训练;然后,利用SA-DCGAN生成新的图像样本,并输入检测网络中进行预测,为其生成一个含类别概率和目标位置信息的标签文件;最后,用生成图像扩充训练集,并对检测网络进行微调。下面详细介绍整个过程的具体实现。
1.1 SA-DCGAN
GAN主要包括生成器和鉴别器两个模块。生成器以随机噪声或向量为输入来生成新的图像。鉴别器用于判断输入图像的真假。训练过程中,生成器的目标是尽量生成逼近真实的图像去欺骗鉴别器,鉴别器的目标则是尽量将生成图像与真实图像区别开来,双方相互博弈。在理想状态下,生成器足以生成以假乱真的图像。随着CNN所展现出的强大优势,许多基于GAN的图像生成模型,均利用卷积层来构建生成器和鉴别器,以解决GAN训练不稳定的问题。因此,本文设计了所需的DCGAN模型,并在每一卷积层后引入自我关注模块进行辅助,称之为SA-DCGAN。
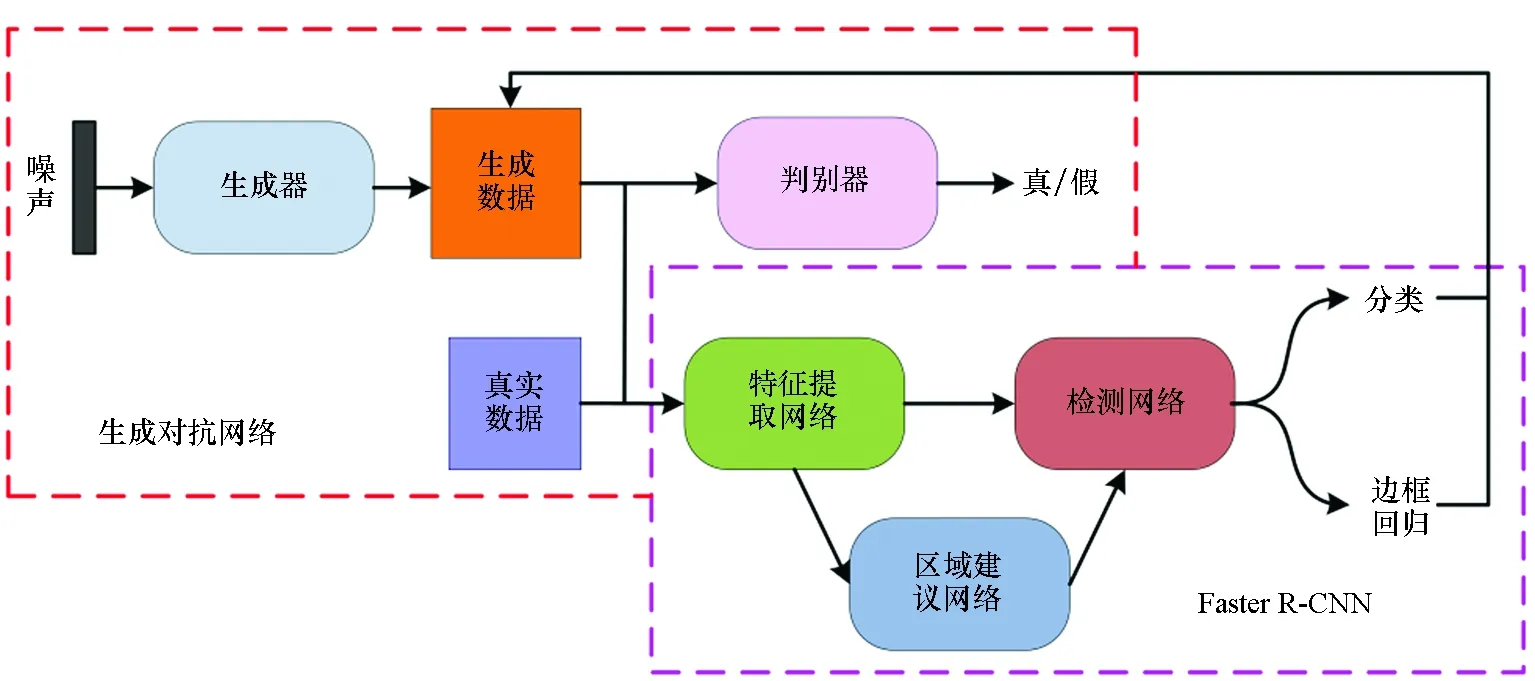
图1 算法整体框架Fig.1 Overall framework of algorithm
1.1.1 DCGAN
DCGAN采用CNN代替原始GAN中的多层感知机,并去掉了CNN中的池化层,另外以全局池化层代替全连接层,有力解决了训练不稳定、生成过程不可控、解释性差等缺点。图2展示了本文所用DCGAN的基本架构。生成器以一个100维的随机向量为输入,并利用线性变换将其放大至4×4×1 024大小,然后通过5个核大小为5×5、步幅为2的反卷积操作,将其扩展为128×128×3的图像矩阵。生成器输出层使用Tanh激活函数,其余层使用ReLU激活函数。与生成器结构相反,鉴别器通过5个卷积操作提取训练集和假图像特征,经sigmoid函数后,输出判定结果,其所有层均使用LeakyReLU激活函数。值得注意的是,除生成器的输出层和鉴别器的输入层外,其他层之后均进行批归一化处理,以确保网络有足够的梯度。
1.1.2 自我关注模型
DCGAN虽在图像生成领域取得了重大进步,但受CNN卷积核限制,其感受野较小,很难表述不同图像区域之间的依赖性,且无法对含有较多几何或结构约束的类别进行建模,而自我关注模型可有效捕捉图像全局依赖性[29]。自我关注生成对抗网络[22]在可见光图像生成中,取得了长足进步,但将其应用于SAR图像生成却效果欠佳。因此,本文将自我关注模型引入DCGAN每层卷积操作之后,构建SA-DCGAN模型,提升网络全局建模能力。自我关注模型如图3所示,其实现过程如下:
输入:特征图u∈C×N,其中C表示特征图通道数,N表示特征点位置数。
步骤1:将u通过两个1×1卷积转换为特征空间f和g,f(u)=Wfu,g(u)=Wgu,其中Wf∈和Wg∈表示1×1卷积的权重矩阵,表示卷积通道数。
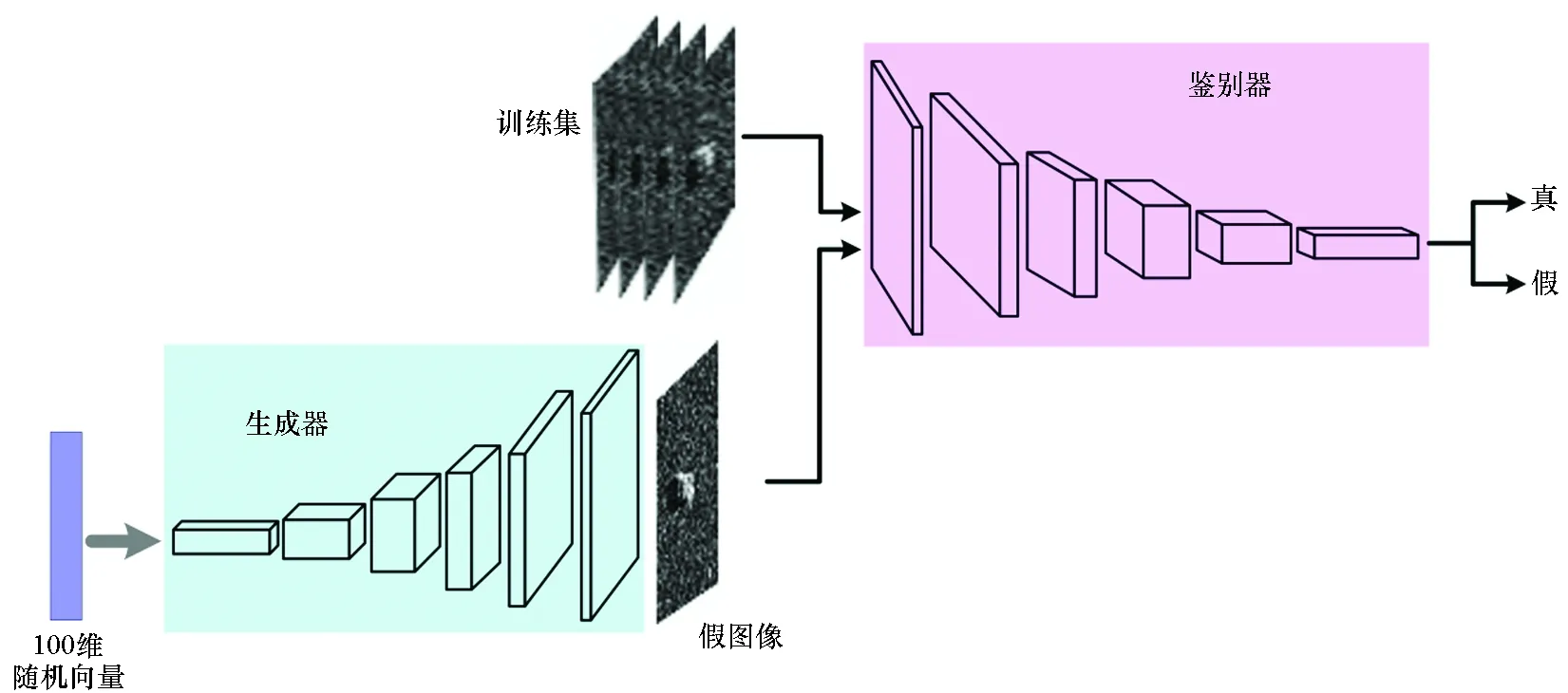
图2 DCGAN基本架构Fig.2 Framework of DCGAN
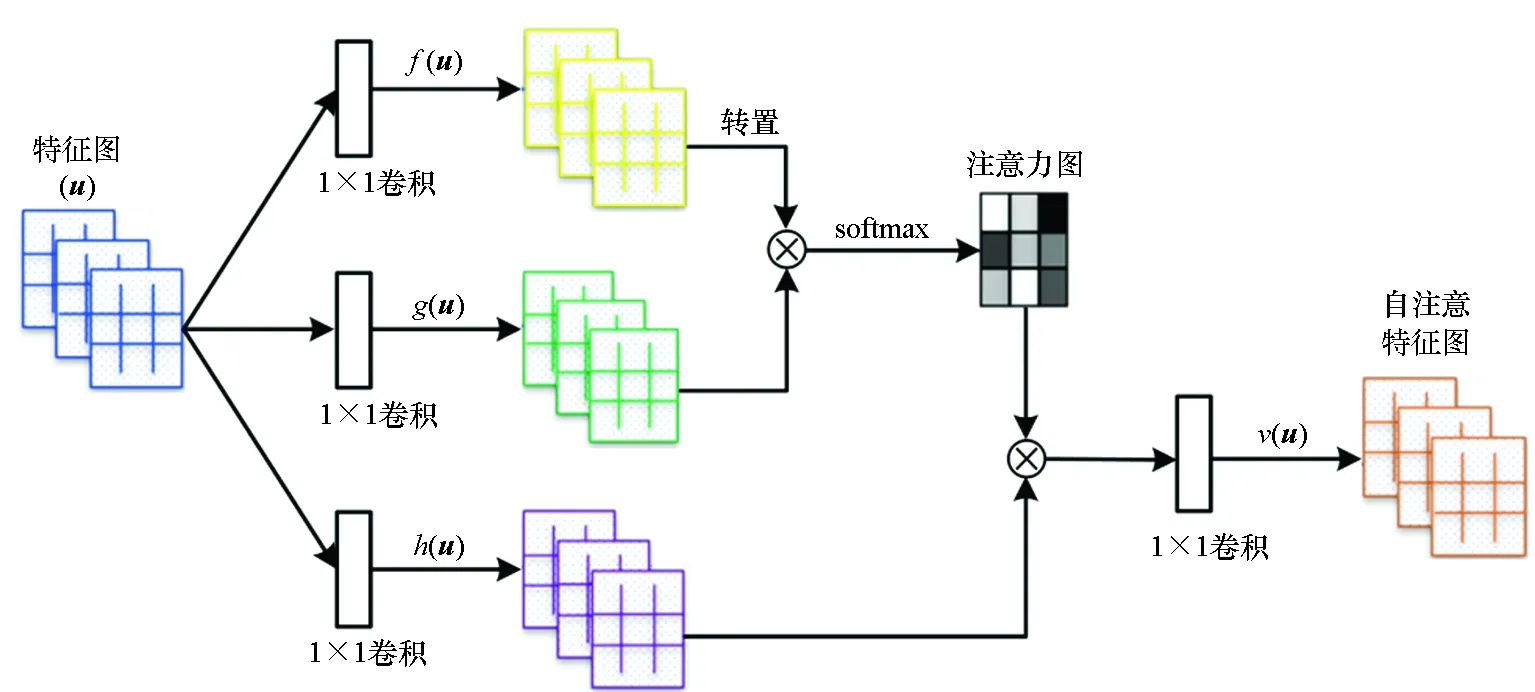
图3 SA-DCGAN中引入的自我关注模型Fig.3 Self-attention model introduced in SA-DCGAN
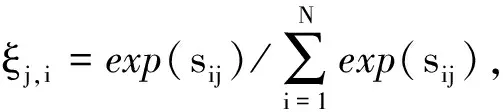
步骤3:计算自我关注特征图o=(o1,o2,…,oj,…,oN)∈C×N,其中和Wv∈同样表示1×1卷积的权重矩阵。
步骤4:将自我关注特征图o乘以占比参数γ后,与原始特征图u相加,其结果作为自我关注模块的最终输出,可表示为:ζi=γoi+ui,其中γ为可学习参数,初始化为0。
1.1.3 SA-DCGAN训练设置
在训练之前,首先将训练图像转换为128×128大小,并映射至[-1, 1]范围。所有卷积层初始化参数均从均值为0、标准差为0.02的正态分布中随机采样得到,批量大小设置为128。LeakyReLU激活函数中α取值为0.2。训练过程中,采用Adam优化器[30](β1=0,β2=0.9)加速网络训练,并设置生成器学习率为0.000 1、鉴别器学习率为0.000 4,两者相互交替训练。网络生成对抗损失函数采用Hinge-loss[31]:
LD=-(q,d)~pdata{min[0,-1+D(q,d)]}-
(1)
LG=-z~pz,d~pdataD(G(z),d)
(2)
1.2 基于Faster R-CNN的目标检测网络
Faster R-CNN模型共包含三个模块:特征提取网络、区域建议网络(region proposal network, RPN)和检测网络,具体框架结构见图4。
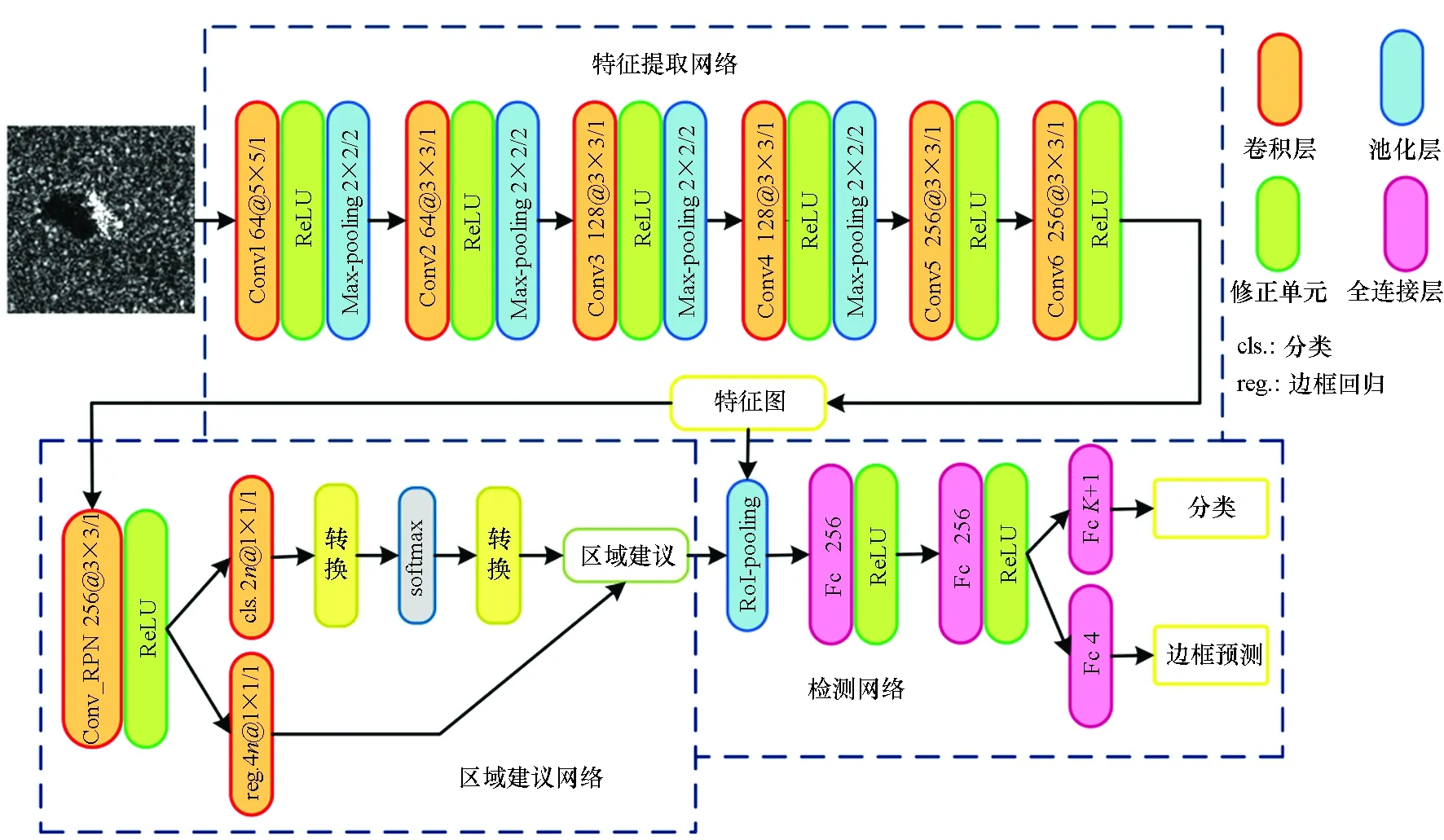
图4 Faster R-CNN框架Fig.4 Framework of Faster R-CNN
1.2.1 特征提取网络
特征提取网络旨在获取输入图像特征,为RPN和检测网络提供表征能力强大的特征图。本文设计的特征提取网络共有6层(Conv1~Conv6),包括6个卷积层,除第一层卷积核大小为5外,其余层卷积核大小均为3,卷积核滑动步长取1,卷积核个数依次为64、64、128、128、256、256。在前四层卷积之后紧接着最大池化层Max-pooling,池化层大小和滑动步长均为2。所有层都使用ReLU作为激活函数,并且在ReLU之后执行批归一化。
1.2.2 区域建议网络
RPN作为整个框架的重要组件,通过合理的锚框设置来快速完成高质量候选区域提取,为检测网络提供合理化建议。设置锚框比例为{1 ∶1, 1 ∶2, 1 ∶3, 1 ∶5, 5 ∶1, 3 ∶1, 2 ∶1},尺度取{102, 162, 322, 482, 642}。在特征提取网络输出的特征图上,以滑窗操作生成多个锚框,经一个3×3卷积层后,通过两个全连接层为每个锚框分配一个二进制类标签(是/不是目标)和四个参数坐标(x,y,w,h),其中(x,y)表示RPN预测的边框中心点坐标,w和h分别表示宽与高,具体过程如图5所示。
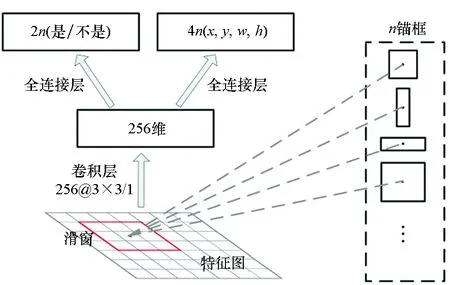
图5 RPN示意Fig.5 RPN schematic diagram
在RPN训练阶段,为了提升计算效率,需要将所有的锚框分为正样本和负样本。正样本定义为:与任意地面真值交并比(intersection-over-union, IoU)大于0.7的锚框。负样本定义为:与所有地面真值IoU均小于0.3的锚框,其余非正非负的样本被舍弃。从正负样本中随机抽取256个作为一个小批量训练集,正负样本保持1 ∶1比例,如果正样本个数小于128,则用负样本填补。RPN网络初始学习率为0.001,每20 000次迭代将当前的学习率除以10,初始预训练最大迭代次数为40 000,二次训练最大迭代次数为20 000。通过RPN提取到的候选区域之间会有大量的重叠,基于候选区域分类得分,采用非极大值抑制(non-maximum suppression, NMS)去除重叠的候选区域,并将得分最高的前200个候选区域作为感兴趣区域(region of interests, RoIs)输入检测网络中。
1.2.3 检测网络
检测网络训练参数设置方式与RPN一致,初始预训练最大迭代次数为60 000,二次训练最大迭代次数为30 000。检测网络和RPN共享特征提取网络,并采用交替方式进行训练[32]。
1.2.4 概率等价类属标签分配
目前,为数据增强生成的无标签图像添加类属标签共有三种处理方法:一是新增类处理[33],即在原始数据集上新增加一个类别,将所有新生样本均归为这一类别;二是最大概率类属标签分配[34],即根据新生样本在网络中的预测结果,将其归为预测可能性最大的类别;三是标签平滑正则化处理[26],即将新生样本所属类别概率平均分配至所有类,假设原数据集共有K类,那么新生样本属于第i类的概率为1/K。另外,对于新生样本中目标位置信息,均采用网络预测的方式进行标定。
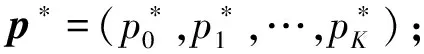
1.2.5 损失函数
Faster R-CNN需完成目标分类和定位两项任务,因此使用多任务损失函数,包括分类损失(class loss)和边框回归损失(bbox regression loss)两部分,定义为:
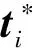
(a) 真实图像(a) Real image (b) 生成图像(b) Generated image图6 真实图像与生成图像的类属标签分布Fig.6 Distribution of the labels of real images and generated images
式(3)中Lcls和Lreg分别定义为:
(4)
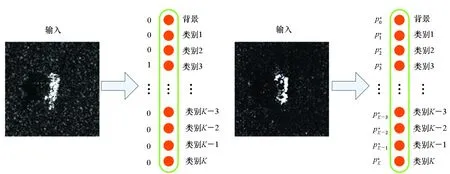
Lreg(t*,t)=(1-η)sL1(t*-t)+
εηsL1(t*-t)
(5)
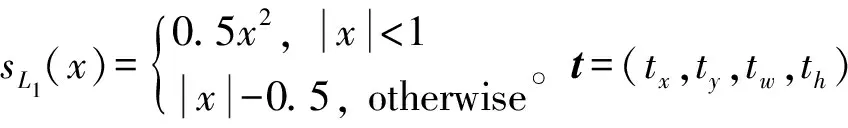
(6)
(7)
式中:x、xa和x*分别表示预测框、锚框和标记框的中心点横坐标;y,w,h的定义方式同上。
2 实验设置及评估
所有实验均在配置为E5-2630v4 CPU、NVIDIA GTX-1080Ti GPU (11 G video memory)、64 GB RAM的图形工作站上进行,以深度学习框架TensorFlow[35]为编译工具完成。
2.1 数据集
为了验证本文算法的有效性,在实验中使用了移动和静止目标获取与识别(moving and stationary target acquisition and recognition, MSTAR)数据集和SAR舰船检测数据集(SAR ship detection dataset, SSDD)。
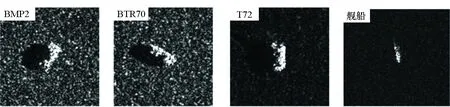
MSTAR数据集由美国国防高级研究计划局和空间实验室发布。该数据集由X波段、HH极化方式、0.3 m×0.3 m高分辨率聚束式合成孔径雷达采集得到,共包括10类典型军事目标在0~360°不同方位角下的静止切片图像。实验过程中,使用BMP2、BTR70、T72图像切片作为实验对象,图7所示为这三类军事目标在真实场景下的可见光图像及其SAR图像。数据集详细信息见表1。

图7 BMP2、BTR70和T72的SAR图像和光学图像Fig.7 SAR image and optical image of BMP2, BTR70 and T72
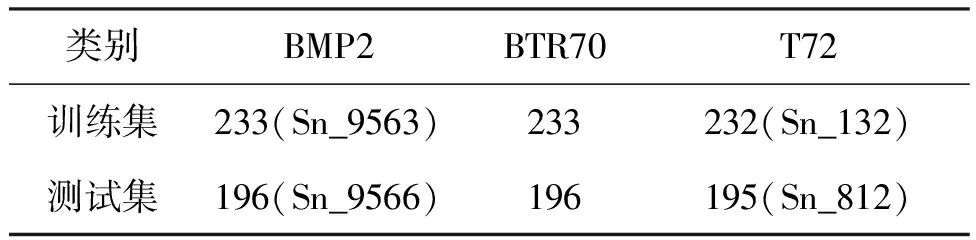
表1 MSTAR数据集详细信息
SSDD数据集是由Li等[36]构建的SAR图像舰船检测数据集,共包含2 456艘舰船的1 160张图像切片。该数据集中的图像切片收集于RadarSat-2、TerraSAR-X和Sentinel-1。数据集中图像分辨率和尺寸均不固定,样例见图8,其详细信息见表2。

(a) 高分辨率图像(a) High resolution image

(b) 中分辨率图像(b) Medium resolution image

(c) 低分辨率图像(c) Low resolution image图8 SSDD数据集样例Fig.8 Samples of SSDD dataset
表2 SSDD数据集详细信息
2.2 评估参数
为定量分析SA-DCGAN性能,使用费雷切特初始距离[37](Frechet inception distance, FID)和最大均值差异[38](maximum mean discrepancy, MMD)两项指标对模型进行评估。FID计算的是真实图像和生成图像在特征层面的距离,MMD用于判断两个分布之间的相似程度。FID与MMD的值越小说明真实图像与生成图像越相似。
为了验证网络检测性能,使用平均精度(average precision, AP)和mAP两项指标对其进行评估。这两项指标均由真阳性(true positive, TP)、假阳性(false positive, FP)、假阴性(false negative, FN)、真阴性(true negative, TN)四个分量计算获得。TP和FP分别表示正确预测和错误预测的数量,FN表示漏检数量。精确率P和召回率R定义为:
(8)
(9)
AP可反映网络对单个类别的检测性能,是检测领域常用的一种统计量,其值越大说明网络性能越好。
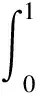
(10)
mAP是数据集所有类AP的均值,用于评估网络的全局性能。
3 实验结果及分析
3.1 SA-DCGAN性能评估
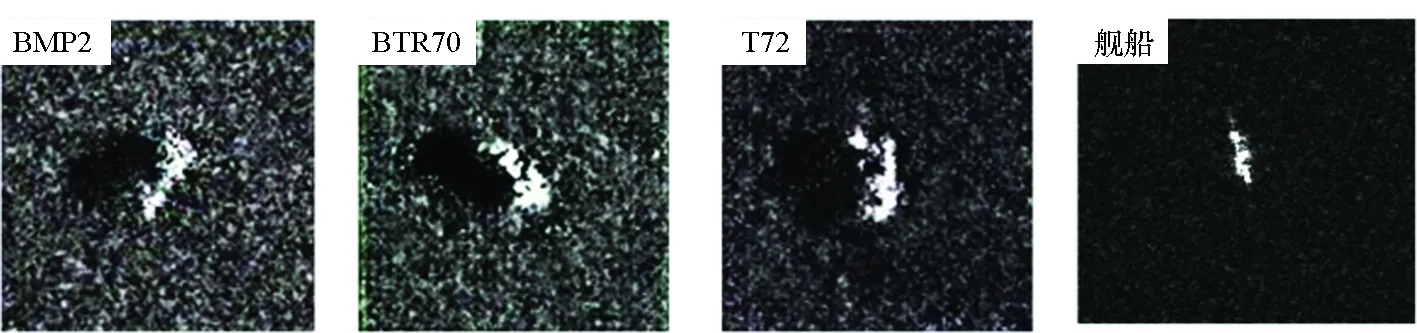
本文通过将SA-DCGAN与SAGAN[22]、DCGAN[19]进行比较来验证所提生成对抗网络模型的优越性。三种方法的定量分析见表3,生成图像示例见图9。通过表3可以看出,无论是MSTAR数据集还是SSDD数据集,SA-DCGAN生成图像的FID和MMD都明显低于其他两种方法,说明本文设计的生成对抗网络模型效果最优。MSTAR数据集图像包含目标、阴影、背景三个要素,而SSDD数据集图像包含目标、船尾迹、背景三个要素。由图9可知,SAGAN生成图像的目标几何外观发生严重畸变,但对各数据集中三要素刻画比较成功,三要素对比度强于DCGAN。DCGAN生成图像虽在外观上较SAGAN有良好改善,但三要素边界混淆严重,甚至船尾迹发生丢失。SA-DCGAN生成图像的目标外观和三要素边界均与真实图像逼近,甚至T72炮管的阴影和船尾迹呈现均清晰可辨。
GAN可以产生逼真的样例,但训练过程却十分困难,很容易出现不收敛的情况。良好的GAN训练态势,需要确保鉴别器损失不能一直下降,而生成器损失不能一直上升,理想情况下,两者最终都应在某一数值附近波动。图10展示了SA-DCGAN在MSTAR数据集和SSDD数据集上的损失曲线,其中黄色曲线为生成器损失,蓝色曲线为鉴别器损失。由图可知,损失曲线在两个数据集上的走势基本一致,随着训练轮次的增加,最终生成器损失逐渐收敛于8附近,鉴别器损失逐渐收敛于0.6附近,说明SA-DCGAN训练情况理想。虽然良好的收敛性并不能证明网络的性能,但多个数据集上相同的损失曲线收敛态势可以侧面说明所提模型具有优异的普适性和鲁棒性。
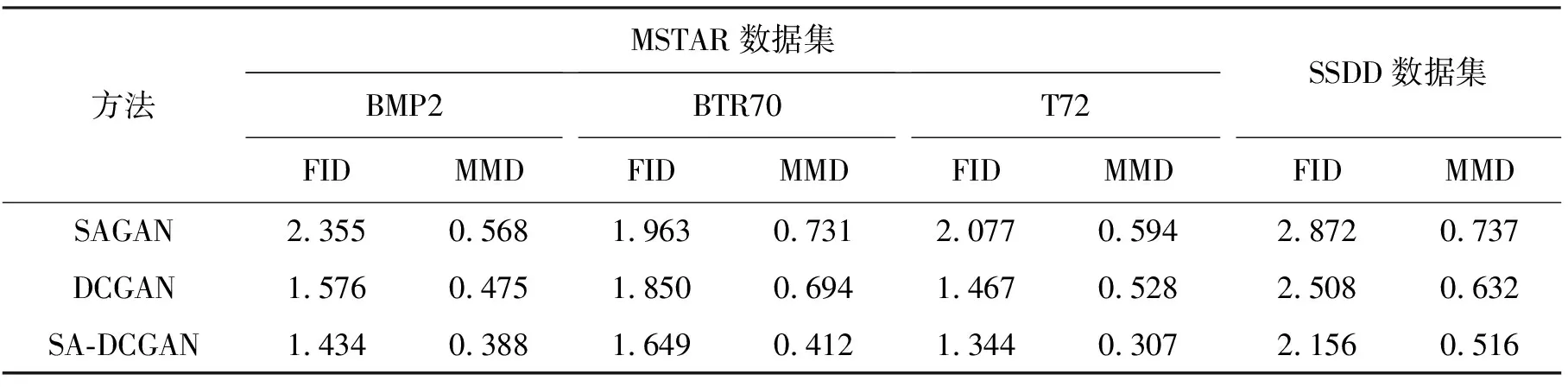
表3 三种GAN的性能对比
(a) 真实图像(a) Real images

(b) DCGAN生成图像(b) Images generated by DCGAN

(c) SAGAN生成图像(c) Images generated by SAGAN
(d) SA-DCGAN生成图像(d) Images generated by SA-DCGAN图9 生成图像示例Fig.9 Examples of generated images
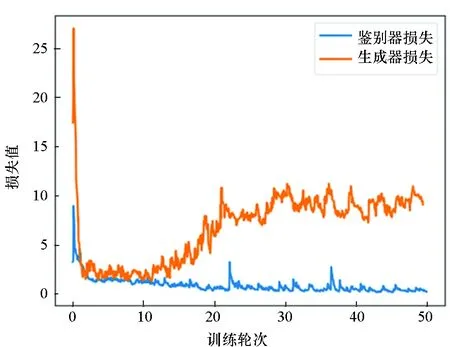
(a) MSTAR数据集上的损失曲线(a) Loss on MSTAR dataset
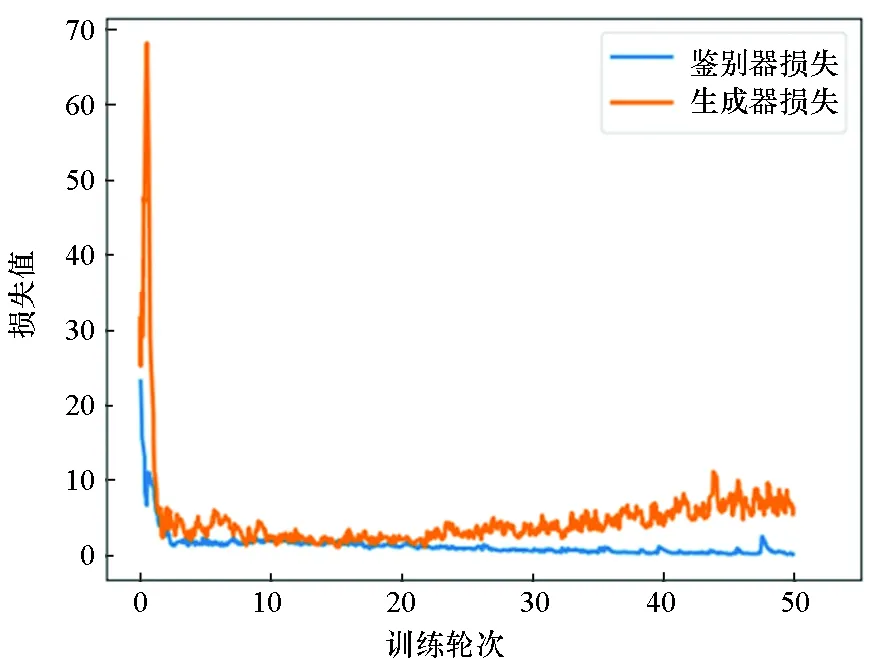
(b) SSDD数据集上的损失曲线(b) Loss on SSDD dataset图10 SA-DCGAN的损失曲线Fig.10 Loss of SA-DCGAN
3.2 训练集中生成图像占比对检测性能的影响
本小节在MSTAR数据集和SSDD数据集上分别进行四组实验来验证使用生成样本扩充训练集对网络检测性能的影响。各实验在原始训练样本的基础上扩充不同数量占比的生成图像作为训练集,以所提网络框架为训练和检测模型,实验设置和参数均保持一致,根据最终检测结果确定最优生成样本占比。四组实验的训练集中原始图像与生成图像比例分别为1 ∶0,2 ∶1,1 ∶1,2 ∶3。表4列出了两个数据集在不同生成图像占比下的网络检测结果。对于MSTAR数据集,由于样本相对简单且干扰信号少,因此当训练集中原始图像与生成图像比例为2 ∶1时,检测结果就可达到最优,而随着生成图像占比继续增加,混淆信息也随之增多,网络性能开始下降。对于SSDD数据集,由于目标尺度多样,原始训练集中缺少一些姿态目标,因此当原始图像与生成图像比例为1 ∶1时,检测网络才达到最优。根据以上实验结果和分析,此后的基于所提网络模型的检测任务,MSTAR训练集中生成图像占比设置为1/3,SSDD数据集中生成图像占比设置为1/2。
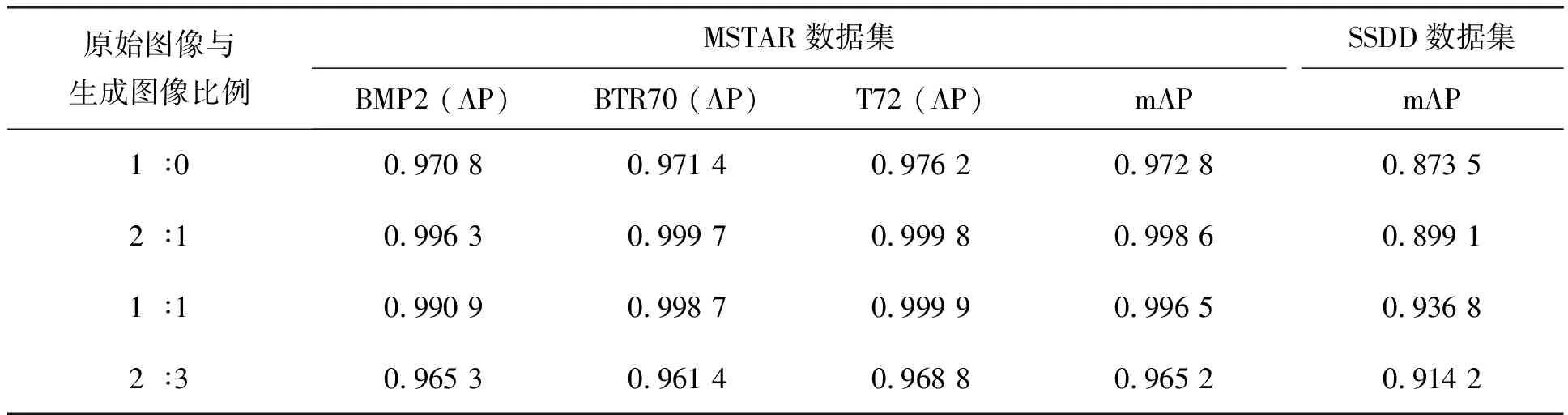
表4 不同生成图像占比下的检测结果
3.3 不同类属标签分配策略对检测性能的影响
本小节分别将最大概率类属标签分配[34]、新增类处理[33]、标签平滑正则化处理[26]和概率等价类属标签分配4种策略应用于网络检测模型,来验证所提标签分配策略的优越性。表5列出了所提网络模型应用不同类属标签分配策略处理生成图像时,其在两个数据集上的性能表现。由表可以看出,应用概率等价类属标签分配策略的网络模型在MSTAR数据集和SSDD数据集上均得到了最优的检测结果。
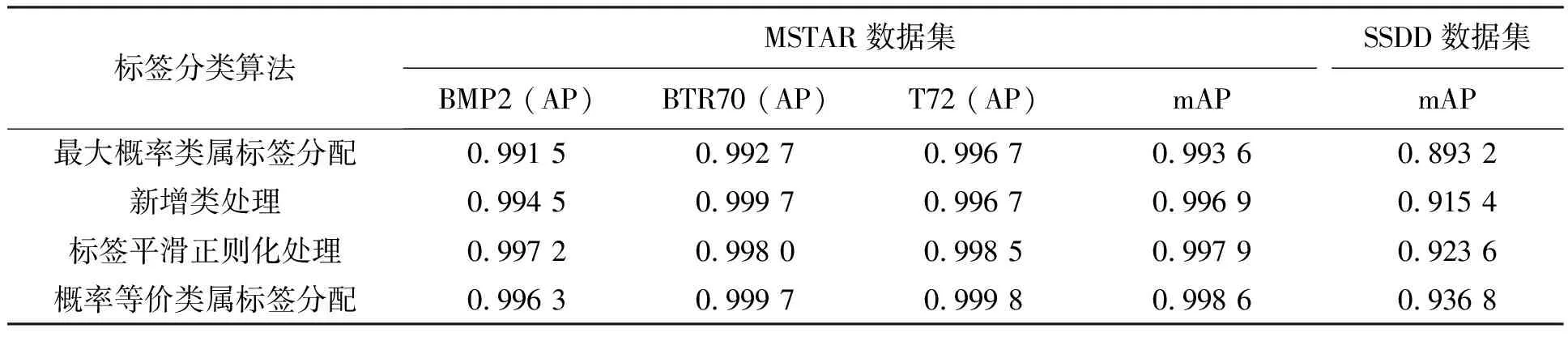
表5 不同类属标签分配策略下的检测结果
3.4 与其他检测算法比较
本小节通过将所提网络模型与Light level CNN[39]、单发多盒检测器(single shot multi-box detector, SSD[40])、改进Faster R-CNN[41]进行比较验证算法的有效性。表6列出了不同网络模型的检测结果及平均检测一幅图像(从输入至输出)所需的时间,图11展示了本文算法在两个数据集上的检测结果示例。Light level CNN的结构相对简单,包括2个卷积层、2个池化层和2个全连接层,在MSTAR数据集和SSDD数据集上复现检测结果,mAP分别达到0.922 9和0.826 3。SSD为单阶段网络模型,通过在不同尺度的特征层上对目标进行检测来提升网络性能,在两个数据集上的mAP分别达到0.956 9和0.870 9。改进Faster R-CNN利用初始网络扩展ResNet101感受野来提取丰富的图像特征,并利用感兴趣区域对齐单元完成特征池化,其在两个数据集上的mAP分别达到0.984 7和0.923 0。相比其他三种算法,本文算法的检测结果最优。从各网络模型检测一幅测试图像所需平均时间看,SSD时间损耗最小,Light level CNN和本文算法时间损耗相近,而改进Faster R-CNN时间损耗最大。由以上比较分析可以得出,本文检测模型虽然简单,但在GAN的支持辅助下,同样可以获得较优的检测结果,且检测时间损耗远远小于性能相近的其他模型。
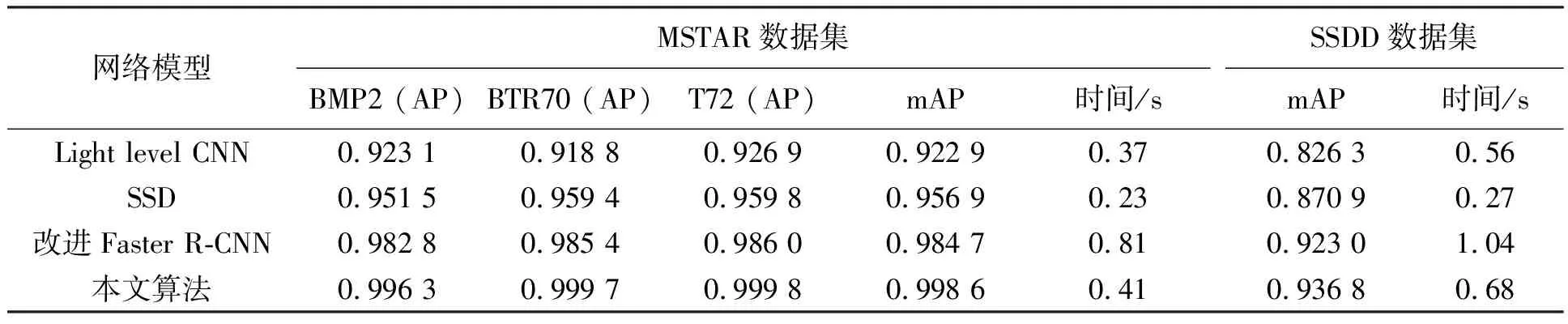
表6 不同网络模型的检测性能

(a) MSTAR数据集检测结果(a) Detection results of MSTAR dataset

(b) SSDD数据集检测结果(b) Detection results of SSDD dataset图11 本文算法检测结果示例Fig.11 Examples of detection results of the proposed algorithm
4 结论
针对SAR图像目标检测中,样本数据获取困难且数量有限的问题,本文提出了一种联合生成对抗网络和检测网络的深度学习模型,可以在有限数据条件下,稳定提升检测性能。所建网络框架首先利用基于注意力机制的深度卷积生成对抗网络合成高质量新生样本,并通过概率等价类属标签分配策略为每个新生样本提供注释信息,再用一定比例的生成图像扩充原始训练集,有效提升Faster R-CNN检测性能。多组基于MSTAR数据集和SSDD数据集的实测实验数据证明,所提SA-DCGAN模型可生成逼近真实图像的合成样本,为原始训练集提供扩充数据。概率等价类属标签分配策略无须人工注释,即可为新生样本提供注释信息,满足训练要求,后经定量分析最优生成图像占比,并以此扩充原始训练集,训练特别设计的Faster R-CNN检测网络。相较于Light level CNN、SSD和改进Faster R-CNN模型,本文所提模型可以在较少时间损耗的前提下,高效完成目标检测任务。
所提网络模型虽然取得了优异的检测结果,但其高光表现以大量的训练前准备工作为基础。此外,为有效利用新生样本而提出的概率等价类属标签分配策略,虽无须人工添加注释信息,但其需要原始检测网络具有较高的检测性能。另外,将基于一个数据集训练的模型用于相似数据集检测,其检测结果还不是很理想(如,使用AIR-SARShip数据集[42]对SSDD训练的模型进行验证,其mAP值达到0.784 2)。下一步工作,将着重加强三方面的研究:一是进一步融合生成网络和检测网络,简化训练前准备工作;二是进一步探寻有效利用新生样本的方法,令其适用于多种网络模型;三是进一步研究网络模型在相似数据集之间的可推广性。
