基于SQL 模版的大数据批处理设计与实现
2022-06-06曾姣艳高宋俤曾美艳
曾姣艳,高宋俤,曾美艳
(1.福州外语外贸学院 大数据学院,福建 福州 350003;2.福州悟理妙信息科技有限公司,
福建 福州 350003;3.郴州职业技术学院,湖南 郴州 423000)
本文选择了使用ANTLR 解析的Hive、Spark SQL、Presto 来搭建基于SQL 模版的大数据批处理平台,用SQL 语言作为调用接口。使用ANTLR 解析工具给重新定制SQL 语句以及对SQL 语句的二次解析带来了极大的便利。上游使用SQL 实现ETL,下游使用SQL调用计算引擎来设计与实现大数据平台。基于SQL 语句的规则,业务方通过编写特定的注释标识符选择底层计算引擎。大数据平台负责解析SQL 模版以及注释标识符,从上游业务库抽取业务数据(ETL),通过路由转发到底层计算引擎,从而完成数据分析及数据质量监控等各项功能。
1 相关工作
Apache Hive™数据仓库软件支持使用SQL 读取、写入和管理分布存储中的大型数据集,并提供了一个命令行工具和JDBC 驱动程序,方便用户连接到Hive[1],可以在Hadoop 的Mapreduce、Spark、Tez 计算引擎之上运行。Hive 将SQL 语句转化成底层计算引擎可识别的程序,极大地降低了开发难度,减少了代码量。
Presto 是一个开源的分布式SQL 查询引擎,适用于交互式分析查询,数据量支持GB 到PB 字节。Presto 以分析师的需求作为目标,期望响应时间小于1 s 到几分钟。Presto 终结了数据分析的两难选择:要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案[2]。Presto 和Hive 都是由Facebook 公司开发的,两者之间有很多的共性。
Spark SQL 是Spark 中的一个模块,允许用户运行SQL/HQL 查询,可以使用Spark SQL 处理结构化和半结构化数据[3]。Spark SQL 与Hive 相似,支持SQL 读取、写入和管理分布存储中的大型数据集,但Hive具备切换执行引擎的能力。
ANTLR 是一个强大的解析器生成器,可以用来读取、处理、执行或翻译结构化文本或二进制文件。在学术界和工业界,ANTLR 广泛用于构建各种语言、工具和框架。Hive 和Pig 的语言以及用于Hadoop 的数据仓库和分析系统都使用ANT‐LR。Lex Machina 使用ANTLR 从法律文本中提取信息。Oracle 在SQL Developer IDE 及其迁移工具中使用ANTLR。NetBeans IDE 使用ANTLR解析C++。Hibernate 对象-关系映射框架中的HQL 语言是用ANTLR 构建的[4]。Presto 和Spark SQL同样使用ANTLR作为SQL语句的解析工具。
在丁岩等人[5]提出的统一SQL 引擎研究与设计的方案中,给出了上层SQL 代理层、中层SQL 统一服务层以及下层计算引擎和存储层的设计思路。核心的SQL 统一服务层完成了对各大组件SQL 语句差异的屏蔽,实现了业务方调用的SQL 的统一化。但因适配不同组件SQL 语句的差异性,使得实现成本较高、难度较大。本设计与文献[5]的目标相近,都是为了实现通过对外提供SQL 接口的大数据平台,降低平台的使用难度,但设计方法以及组件的选型是有差异的:采用SQL 模版和基于ANTLR 解析的SQL 计算引擎组件来搭建大数据平台。SQL 语句直接使用底层自身引擎提供的组件(因为ANTLR 解析的Hive、Spark SQL、Presto 差异极小)降低对SQL 语句的侵入性,利用ANTLR对3 个组件使用的SQL 进行二次解析和定制化开发,帮助平台解决业务层面上的数据权限及因SQL语句带来的各种问题。
2 设计与实现
大数据业务的处理平台通常有3类。第1类是实时数据处理:业务指标需要在秒甚至是毫秒级别内得出结果;第2 类是批量数据处理:此类数据比较大,早期的Hadoop 就是针对此类业务开发出来的,用于处理大批量的离线数据;第3 类是面向数据分析师的即席查询业务:数据分析师可以在平台上直接输入SQL 语句,在秒级下得到分析结果,但因一次性处理数据量也较大,亦可归纳为大数据批处理一类。
调质效果对于沉性水产饲料水中稳定性的研究也表明了在生产膨化沉性料的过程中,调质效果的关键作用。Eugenio Bortone等[8]对调质时间和机械能输入对膨化虾料水中稳定性带来的影响,进行了实验研究。分别对4组实验(PPC、PPO、LSME和MSME)进行了对比研究,实验结果如图4所示。
2.1 架构设计
本平台(如图1)底层计算基于Hive、Spark‐SQL、Presto,上层使用SQL语言作为调用接口的大数据批处理平台。虽然Hive 并不是真正意义上的计算引擎,其自身依赖底层(类似Hadoop MapRe‐duce 或Tez 计算引擎),但为了方便描述,将Hive、Spark SQL 和Presto当作同一个层级的计算引擎看待。业务方根据自身计算任务的效率要求,通过SQL标记的方式,自主选择计算引擎进行计算。大数据平台语句解析层根据标记不同,选择计算引擎完成SQL语句的分发。
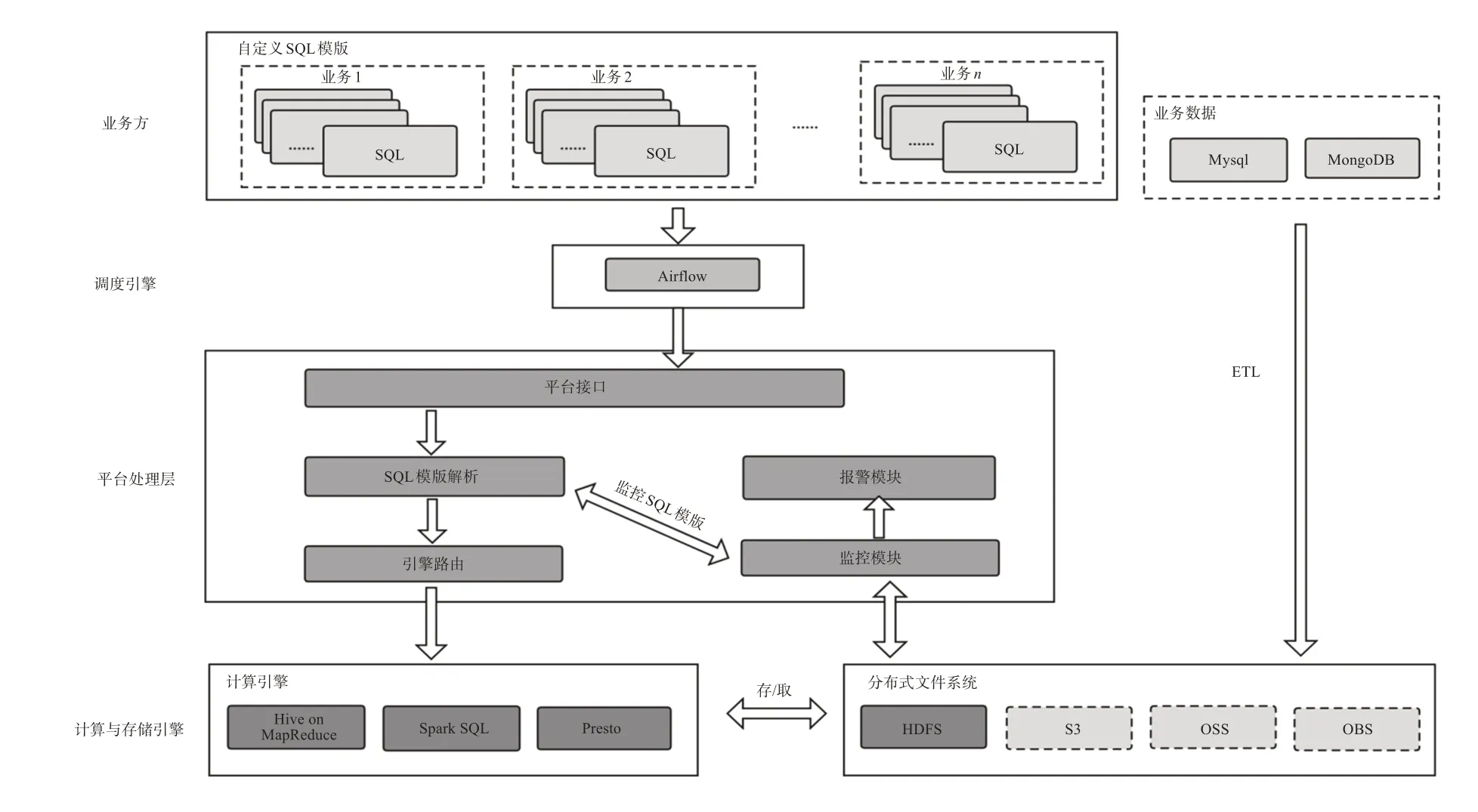
图1 大数据平台架构
大数据平台的数据一般来源于两部分:一是业务数据,一是用户的行为数据。用户的行为数据通常会在生成数据时,使用Flume等工具直接写入到大数据平台数据仓库中,而业务数据需要从业务方的数据库中同步抽取到数据仓库中[6]。大数据开源工具Sqoop[7]专门用于业务库与数据仓库之间的数据同步迁移,然而重新使用一款新的组件会提高额外的学习成本,增加系统的复杂度,也不易于开发与维护。为了简化平台的复杂度,平台中引入了基于SQL 语句的ETL 方法,实现从不同的业务数据源(Mysql、MongoDB)拉取、转换、加载到数据仓库的功能。
为保证业务的运行结果符合预期,平台还需要实现数据质量监控的功能。其实现方式同样使用SQL 语句,由业务方自行编写,平台根据SQL 运行的结果来判断是否发送告警信息,各业务方需要提供回调接口来接收平台的报警信息。
业务方各作业的工作方式一般是使用DAG图来组织调用的,DAG 的每一个节点都代表不同的、独立的SQL 语句作业。为了满足业务方各作业有效运作,平台方引入了Airflow[8]作为作业调度器。选用Airflow 的目的是基于Airflow 灵活、可编程式的特点,方便平台开发者修改DAG 图的组织样式、配置参数,实现未来可视化式的DAG 图等功能。
2.2 SQL模版设计
在实际业务中,有大量的场景需要定时、定量完成计算。业务方需要在作业提交之前提供SQL语句模版,先行存放在平台规约好的分布式存储文件中。SQL语句模版中包含可替换的变量,变量由平台解析层完成解析、具体赋值。赋值后的SQL语句交给平台路由模块,由路由模块完成路由转发到底层计算引擎的工作。
平台中SQL 模版变量用占位符${变量名}来表示,其定义为两种类型变量:业务方自定义的变量和时间变量。
自定义的变量主要是指业务方SQL语句中易变的信息值,比如服务器地址、数据库名、数据版本号等。如SQL语句中:
CREATE OR REPLACE TEMPORARY VIEW video_view USING com.stratio.datasource.mongodb
OPTIONS(host '${content_center_url}',data‐base'${content_center_db}',collection'video');
语句的含义是业务方从MongoDB中将数据拉取到数据仓库。占位符${content_center_db}和${content_center_url}绑定了具体服务器的地址、数据库名信息。这类变量要求业务方在提交Airflow JOB的时候一并上传。
时间变量包含系统时间和时间周期数据。在业务方实施具体数据分析时,通常会根据当下时间选取一定时间范围内的数据,比如昨日日活、7 日留存、30 日留存等这类的业务指标,都有时间范围和启动时间点的要求。系统时间通常无法由业务方在提交job 的时候定义,业务方只能定义时间周期数。时间变量使用占位符${time.yyyyMMddHHmm}来表示当下系统时间,时间粒度由业务方自行决定,平台方可支持的最小粒度为分钟。同时,时间变量占位符还提供了基本加减运算,增加时间定义的灵活性,方便业务使用。下面SQL 语句表示拉取最近半个月数据进行计算:

其中占位符${time.yyyyMMdd-15d}表示当下日期的前15 d 的时间,倘若要表示昨日的时间,可以用占位符${time.yyyyMMdd-1d}来表示。
2.3 支持业务方的数据拉取
大数据分析的业务数据通常存放在各自业务库中,为了结合用户的行为数据进行分析,必须从业务库中拉取数据进入数据仓库中。平台使用SQL 语句模版完成ETL 的任务,目前平台的设计主要支持Mysql和MongoDB这两种业务库。
从业务库拉取数据分成两步,同一个作业中的语句中间用“;”隔开。
步骤1:定义视图,如下:

步骤2:从视图拉取数据,并写入到数据仓库中。下列语句展示了从视图tmp_dim_region 中拉取数据,并插入到数据仓库中的具体实现过程。

同理,还可以从MongoDB 中拉取数据写入到数据仓库中,也是两个步骤,语句写法相似。
CREATE OR REPLACE TEMPORARY VIEW article_view USING com.stratio.datasource.mongodb

2.4 基于ANTLR解析与定制SQL语句
企业内部各大业务的数据统一写入到一个数据仓库中,平台方并没有要求业务方提交的SQL语句需要进行数据访问范围的限制,如果语句被路由直接转发到计算引擎上,各大业务就可以直接访问整个数据仓库的数据(整个公司的数据)。而在实际项目运行过程中,业务方想跨业务访问其他业务的数据,通常是不被允许的。业务间数据互通,需要由业务方授权或者上层决策者同意才能访问,技术上需对数据权限进行规约限定。而数据的访问限制,不应该在业务方的SQL 语句中体现,底层平台数据对业务方是透明的。为了解决SQL 语句数据访问权限的问题,在大数据平台中增加SQL二次解析功能,对业务方提交的SQL 语句进一步解析、定制组装来限定数据范围,再由路由模块交给计算引擎去处理。
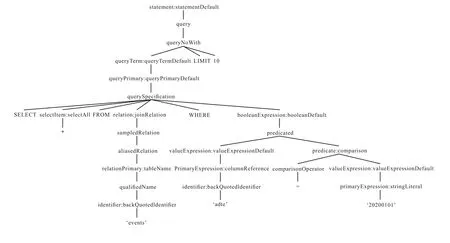
在数据仓库中,各大业务的行为数据通常会按照同一种schema 存入到数据仓库行为表(events)中,使用业务的appid 来区分不同业务记录。业务方提供的语句通常形如SELECT* FROM `events`WHERE `date`='20200101',如果平台没有加入权限限制,则会拉取出整个数据仓库中所有业务的'20200101'这一天的数据。这不但不是业务方想要的结果,反而会给大数据平台带来IO 上的压力。大数据平台需要通过对SQL 语句进行二次解析、重新定制修改语句来解决数据权限方面的问题。但是,并不能简单地在末尾加上条件限制,如针对语句SELECT * FROM `events` WHERE `date`='20200101'LIMIT 10做限定,简单地在语句末尾加上WHERE`appid`='000001',明显不符合SQL语句规范。
所以,利用ANTLR 对原业务语句进行语法树的解析(如图2),需要在querySpecification节点下,WHERE 关键字后面,添加合适的限制条件才能生成符合标准的SQL 语句。平台通过ANTLR 提供的接口,完成数据权限的设置,图3 给出了加上条件限定后的正确语法解析树。
