高亚硝酸盐胁迫下日本囊对虾肝胰腺的转录组分析
2022-06-06陈亭君栗志民刘建勇梁彩凤
陈亭君,栗志民,袁 乐,刘建勇,梁彩凤
(广东海洋大学 水产学院,广东 湛江 524088)
日本囊对虾(Marsupenaeus japonicus)是全球最具有经济价值的甲壳类动物之一,广泛分布于印度-西太平洋、日本、中国和澳大利亚等地区[1-4],养殖规模呈逐年升高态势,其养殖方式包括集约化和半集约化养殖[5]。国内对该虾类的养殖方式已逐渐由室外土池养殖转变为室内高集约化养殖,以满足市场日益增长的需求[6-7]。要提高集约化养殖的生产效率和经济效益,水质控制格外重要[8]。近年来,在集约化养殖中,由于过多的投饵量和不彻底的养殖池排污,使高含氮(N)排泄物和残饵在水体中累积,超过了养殖水体中亚硝化细菌和硝化细菌的代谢能力,使得亚硝酸盐氮的质量浓度达到了较高水平[9-10]。
亚硝酸盐氮是氨氧化成硝酸盐的中间产物,它使氧合血蓝蛋白转化为脱氧血蓝蛋白,降低血淋巴对氧的亲和性,降低机体的输氧能力,最终造成水产动物缺氧甚至死亡[11-13]。大量研究已经证实亚硝酸盐氮对多种虾类具有较强的毒性[14-18],包括损坏器官[19]、生长和发育变慢[20-21]、降低存活率[22]和免疫能力[23-24]等。值得一提的是,盐度下降会导致虾类对亚硝酸盐的耐受性降低[15,25],pH下降时亚硝酸盐应激会导致虾类氮的排泄、离子调节和气体交换被干扰,并可能导致载氧能力下降[26]。过去的研究中,发现亚硝酸盐胁迫对日本囊对虾的免疫和代谢均能产生影响,在亚硝酸盐胁迫下,日本囊对虾血淋巴中氧血色素苷、蛋白质,以及氧血色素苷/蛋白质的比值减少,氮代谢和酸碱平衡发生改变,渗透压降低,尿素增加[27-29]。血淋巴亚硝酸盐和血淋巴尿素随环境亚硝酸盐和暴露时间的增加而增加[29]。此外,Zheng等[30]克隆了与凋亡相关的基因caspase-3和DAD-1,初步探讨了亚硝酸盐胁迫对免疫相关基因和凋亡相关蛋白的遗传响应的分子机制。
在甲壳类生物学领域,利用转录组测序技术(RNA-seq)研究基因表达已广泛用于比较生理学、生态学、进化、环境监测和商业化养殖中[31]。近年来,关于亚硝酸盐胁迫下甲壳类转录组的研究仅见于凡纳滨对虾(Litopenaeus vannamei)[32]和日本沼虾(Macrobrachium nipponense)[33],研究显示凡纳滨对虾和日本沼虾在亚硝酸盐胁迫下的免疫相关通路和凋亡通路非常活跃,已筛选得到许多与免疫反应、解毒、凋亡途径相关的候选基因。然而,有关亚硝酸盐胁迫下日本囊对虾的分子机制仍然知之甚少。甲壳类动物的肝胰腺不仅是重要的消化器官,在脂质、碳水化合物等代谢过程中起重要作用,而且是不可或缺的免疫器官,跟解毒和免疫息息相关[33-34]。因此,本研究通过转录组测序技术获得在高亚硝酸盐胁迫下日本囊对虾肝胰腺转录组信息,为探讨高亚硝酸盐胁迫下的分子机制、丰富cDNA 数据库的信息、识别免疫和凋亡等通路的差异基因提供分子证据。
1 材料和方法
1.1 实验材料
由广东国联水产有限公司提供第3代健康的120日龄混合家系日本囊对虾,其平均体长(49.28±4.79)mm,平均体重(1.39±0.38)g。实验前,将日本囊对虾在水温(28±0.2)℃、盐度(29.8±0.2)、溶解氧(Dissolved Oxygen,DO)6.0 mg/L条件下于水泥池中驯化7 d,以减轻应激反应。
通过预实验,确定高亚硝酸盐胁迫质量浓度为80 mg/L(在此质量浓度下,胁迫96 h 的存活率约为80%)。实验分为对照组(CG)和高亚硝酸盐组(N)。以新鲜海水作为对照(亚硝酸盐质量浓度<0.02 mg/L)。采用分析纯(NaNO2)溶于新鲜海水配制质量浓度为2 000 mg/L母液,贮藏于阴暗干燥环境备用,实验时通过稀释母液配制高亚硝酸盐(80 mg/L)。
采用1 500 L塑料桶进行对照组和高亚硝酸盐组实验,其他实验条件与驯化条件一致。实验期间不投饵,持续96 h,每24 h用高亚硝酸盐试纸测定1次质量浓度,以保持恒定水平。实验设置3个重复组。于6、12、24、48和96 h分别从高亚硝酸盐组(N6、N12、N24、N48和N96)和对照组(CG6、CG12、CG24、CG48和CG96)取样,每个时间点各取9尾虾采集肝胰脏,保存于含1 m L RNAhold的离心管中。样品在4℃下保存过夜,然后在-20 ℃下保存,直到提取RNA。
1.2 RNA提取及Illumina测序
利用TRIzol试剂(Invitrogen,US)从肝胰脏中提取总RNA,用1%琼脂糖凝胶电泳检测RNA 降解和污染状况。分别通过NanoPhotometer®分光光度计(Implen,CA,USA)和Qubit®RNA Assay Kit and Qubit®2.0 荧光计(Life Technologies,CA,USA)检查RNA 纯度和浓度。采用生物分析仪2100系统(Agilent Technologies,CA,USA)中的RNA Nano 6000 检测试剂盒评估RNA 完整性。本研究使用Illumina®的NEBNext®UltraTMRNA Library Prep Kit(NEB,USA)生成,共构建了10个文库。首先,利用带有Oligo(d T)的磁珠从1μg总RNA 中富集有poly-A 尾的m RNA;然后,加入Fragmentation Buffer,将m RNA 随机断裂成200 bp 左右的小片段;第3 步,采用SuperScript Double-Stranded cDNA Synthesis Kit(Invitrogen)试剂盒,加入六碱基随机引物(Illumina),以m RNA 为模板反转录合成第1链cDNA,进行第2链合成,形成稳定的双链结构;第4步,双链的cDNA 结构为黏性末端,加入End Repair Mix将其补成平末端,随后在3'末端加上1个A 碱基,用于连接Y 字形的接头,具体步骤参见试剂盒说明书;最后,Agencourt AMPure XP(Beckman Coulter,Brea,CA,USA)对PCR 产物进行纯化,并在Agilent 2100生物分析仪系统上对文库质量进行评估。库检合格后,把不同文库按照有效浓度及目标下机数据量的需求混合(pooling)后,使用NovaSeq6000仪器进行(Illumina,美国)测序。
1.3 测序数据过滤和组装
为了得到高质量的测序数据,必须将测序得到的原始测序序列(Sequenced Reads)或粗读本(Raw Reads)过滤为净读本(Clean Reads):①去掉含测序接头(Adapter)的读数;②去掉N(N 代表无法确定碱基信息)的比例>10%的读数;③去除低质量读数,即碱基质量(Phred score,Qphred≤20的碱基数占整个碱基的50%以上的读数)。同时,计算clean reads的Q>20、30的碱基,以及G 和C的数量总和占总的碱基数量的百分比(Q20、Q30和GC含量)。所得到的高质量clean reads用于后续分析,并采用Trinity软件对claan reads进行组装[35]。
1.4 基因差异表达分析及功能注释
首先,利用bowtie2软件[36]将净读本比对到转录组序列上;然后,使用RSEM[37](http:∥deweylab.biostat.wisc.edu/rsem/)对bowtie2软件的比对结果进行统计,进一步得到每个样品比对到每个基因上的read count数目,并对其进行(Fragments Per Kilobase Million,FPKM)转换[38]。先使用edgeR v.3.0.8软件和1个尺度归一化因子调整每个序列库的读计数,而后采用TMM 对read count数据进行标准化处理,再使用DEGseq对N 组和GC组之间的DEGs进行差异分析,需q值(q-value)结合差异倍数(Fold Change,FC)来筛选,q≤0.05且|log2FC(Sample2/Sample1)|(基因表达量差异倍数是以2为底数的对数值)≥1,则该基因为显著差异表达基因[39]。
基于非冗余蛋白质数据库(Non-Redundant Protein Sequence Database,Nr)、非冗余核苷酸数据库(Nucleotide Sequence Database,Nt)、蛋白质和真核生物的同源群(eu Karyotic Ortholog Groups/Clusters of Orthologous Groups of Proteins,KOG/COG)、蛋白质家族(Protein family,Pfam)、京都基因与基因组百科全书(Kyoto Encyclopedia of Genes and Genomes,KEGG)[40]和GO(Gene Ontology,GO)数据库[41]对基因功能进行注释。
1.5 荧光定量验证转录组数据
随机选择9个DEGs,进行qPCR 验证,分别是:ATP 结合盒转运蛋白(ATP-binding cassette transporters,ABC transporters)、二氢嘧啶脱氢酶(dihydropyrimidine dehydrogenase,DPD)、酚氧化酶原b(prophenoloxidase b,proPO b)、长链脂酰辅酶A 脱氢酶(long-chain specific acyl-Co A dehydrogenase,LCAD)、细胞色素家族(cytochrome P450,family 2,subfamily J,CYP2J)、质子偶联氨基酸转运蛋白4(Proton-coupled Amino acid Transporter 4,PAT4)、甜菜碱同型半胱氨酸S-甲基转移酶(betaine-homocysteine S-methyltransferase,BHMT)、C型凝集素(C-type lectin,CLEC)和磷酸烯醇丙酮酸羧基激酶(phosphoenolpyruvate carboxykinase,PEPCK),对上述9个DEGs进行qPCR 验证。利用Primer 5.0软件设计特异性引物(表1),送至生工生物工程(上海)股份有限公司合成。
qPCR 使用TransStart Tip Green Super Mix(北京全式金生物科技有限公司)试剂,以延伸因子1α(EF1α)为参考基因,通过罗氏LightCycler480 II实时荧光定量PCR 系统进行扩增。扩增在384孔板上进行,反应总体积为10μL,包括:1μL cDNA、每个基因特异性正向和反向引物各0.2μL、5μL TransStart Tip Green qPCR Super Mix和3.6μL无酶水。qPCR 步骤为:94 ℃30 min;94 ℃5 s,60 ℃15 s,72 ℃10 s(45个循环);95 ℃10 s,65 ℃60 s,95 ℃1 s。相对表达量采用2-ΔΔCT法计算,数据为平均值±标准差(Means±SD),通过SPSS19.0软件中的单因素方差分析(one way ANOVA)进行统计学检验,差异显著性为P<0.05,差异极显著为P<0.01。
2 结果
2.1 转录组的测序和从头组装
转录组测序后,从CG 组和NG 组构建的10个文库中共产生961 590 184个raw reads,除去包含适配器序列或poly-N 序列的读取和原始读取中的低质量读取,共获得920 785 608个clean reads。在所有的文库里,碱基质量及组成分析显示,各样品Q30均≥93%,GC 含量为50.29%~52.95%(表2)。利用Trinity软件对获得的clean reads进行组装,去除冗余之后分别获得74 856条转录本(Transcripts)和46 308条单基因簇(Universal Gene,Unigenes)。转录本的N50长度(将转录本按照长度从长到短排序,依次累加转录本的长度,当累计转录本长度达到转录本总长的50%时,拼接的转录本的长度为N50,可用于评估拼接效果)和N90的长度分别为2 408和470 bp,unigenes的N50和N90的长度分别为1 833和435 bp。对组装出来的unigenes进行长度分布统计,其最小长度为301 bp,分布在300~500 bp的有18 954条,占总数的40.93%,数量最多;大于2 000 bp只有6 323条,只占总数的13.65%,平均长度为1 300 bp(表3和表4)。将Trinity软件拼接得到的转录本序列,作为后续分析的参考序列。

表3 拼接长度分布Table 3 Splicing length distribution

表4 长度频数分布Table 4 Length frequency distribution
采用单拷贝直向同源数据库BUSCO 对拼接得到的unigenes进行拼接质量评估,结果显示:有978个BUSCO 被完全覆盖,完全匹配到的单拷贝(Complete and Single-Copy)的unigenes为902 条,占总数的92.2%;多拷贝(Complete and Duplicated)、部分片段匹配(Fragmented)和没有匹配(Missing)的unigenes分别为28、26和22条,分别占总数的2.9%、2.7%和2.2%(表5)。

表5 拼接转录本BUSCO 评估Table 5 Busco evaluation of splicing transcripts
2.2 基因的功能注释
将拼接得到的48 807条unigenes通过NR、NT、Swiss-Prot、PFAM、KO、KOG 和GO 七大数据库进行基因功能注释,注释到的unigenes 数量(比例)分别为:25 833(55.78%)、21 342(46.08%)、22 628(48.86%)、25 015(54.01%)、3 615(7.8%)、9 474(20.45%)和25 015(54.01%)条。在7个数据库中至少注释到1个数据库的unigenes数量为34 361条,占总数的74.2%,而在7个数据库都注释到的unigenes数量为1 501条,占unigenes总数的3.24%(表6)。其中,比对到NR 数据库的数据根据物种来源来分析,注释到前3位的物种分别是美洲钩虾(Hyalella azteca),日本囊对虾(Marsupenaeus japonicus)和凡纳滨对虾(Litopenaeus vannamei),匹配unigenes数量分别占总数的31.6%、14.4%和6.6%(图1)。
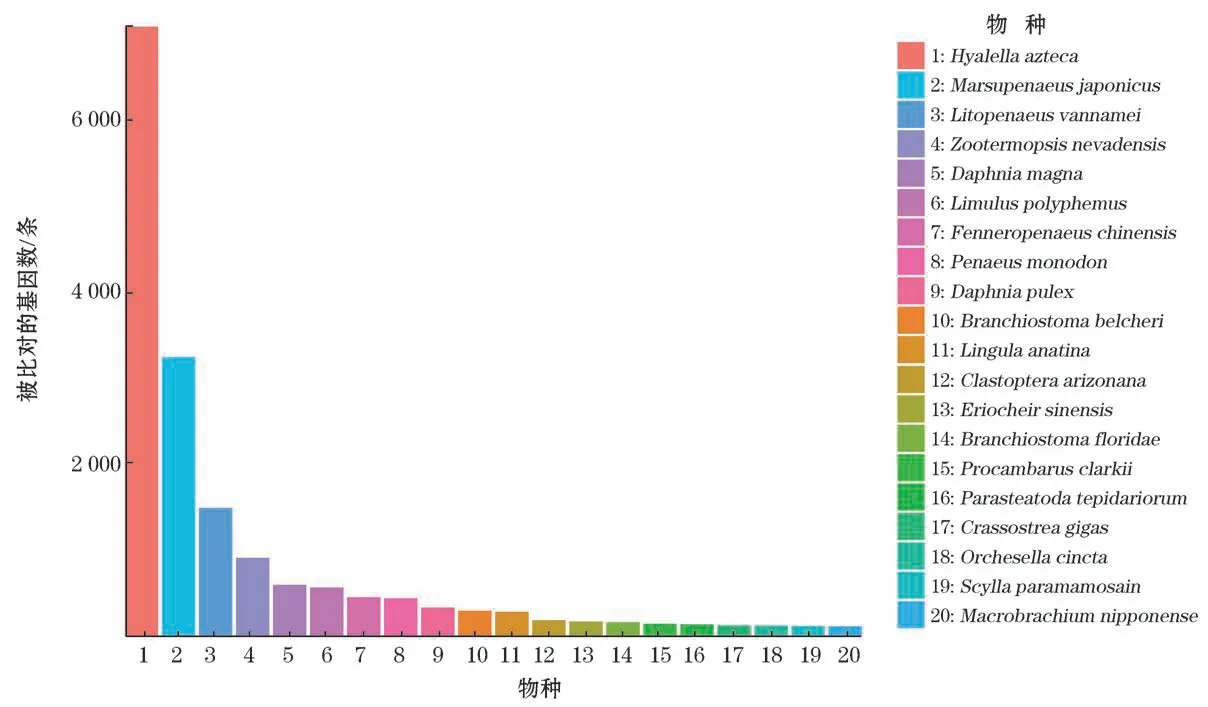
图1 NR 库比对物种分布Fig.1 Comparable species distribution in the NR database

表6 基因注释成功率统计Table 6 Statistics of success rate of gene annotation
将全部unigenes进行GO 数据库比对,结果显示:一共有25 015条unigenes被成功注释和分类到生物过程(Biological Process)(25个亚类)、细胞组分(Cellular Component)(20个亚类)和分子功能(Molecular Function)(10个亚类)三大类中。在生物过程中,参与细胞过程(GO:0009987)、代谢过程(GO:0008152)、单细胞组织过程(GO:0044699)最多,分别注释到14 335(57.31%)、13 080(52.29%)和12 325(49.27%)条unigenes;在细胞组分中,主要与细胞组分(GO:0044464)、细胞(GO:0005623)和膜(GO:0016020)有关,分别注释到6 724(26.88%)、6 724(26.88%)和5 159(20.62%)条unigenes;在分子功能中,主要与结合功能和催化活性有关,分别注释到11 937(47.72%)和11 516(46.04%)条unigenes(图2)。

图2 GO 注释分类统计Fig.2 Classification statistics of GO annotation classification statistics
将unigenes与KOG 数据库进行比对,结果显示,9 474条unigenes被成功注释并按26个KOG 进行分类:①注释到一般功能预测(General Function Prediction Only)的unigenes最多,为1 364 条,占总数的14.40%;②翻译后修饰、蛋白质转化和分子伴侣(Posttranslational Modification,Protein Turnover,Chaperones)、信号转导机制(Signal Transduction Mechanisms)、氨基酸运输和代谢(Amino Acid Transport and Metabolism)及翻译、核糖体结构与生物发生(Translation,Ribosomal Structure and Biogenesis)注释到的unigenes分别有957(10.10%)、882(9.31%)、801(8.45%)和718(7.58%)条;③未知蛋白(Unamed Protein)注释到的unigenes最少,仅占总数的0.02%(图3)。

图3 KOG 注释分类统计Fig.3 Classification statistics of KOG annotation
对3 615条unigenes进行KO 成功注释后,根据unigenes参与的KEGG 代谢通路进行分析,将其分为细胞过程(A)、环境信息处理(B)、遗传信息处理(C)、代谢(D)和有机系统(E)五个分支,分别占总unigenes的13.67%、12.72%、16.74%、53.72%和23.82%。代谢通路的过程很多,其中富集的前3条通路分别为碳水化合物代谢(Carbohydrate Metabolism)、信号转导(Signal Transduction)和氨基酸代谢(Amino Acid Metabolism),富集的unigenes数量分别为364(10.07%)、362(10.01%)和332(9.18%)条。另外,信号转导(Signal Transduction)和免疫系统(Immune System)通路也被显著富集(图4)。
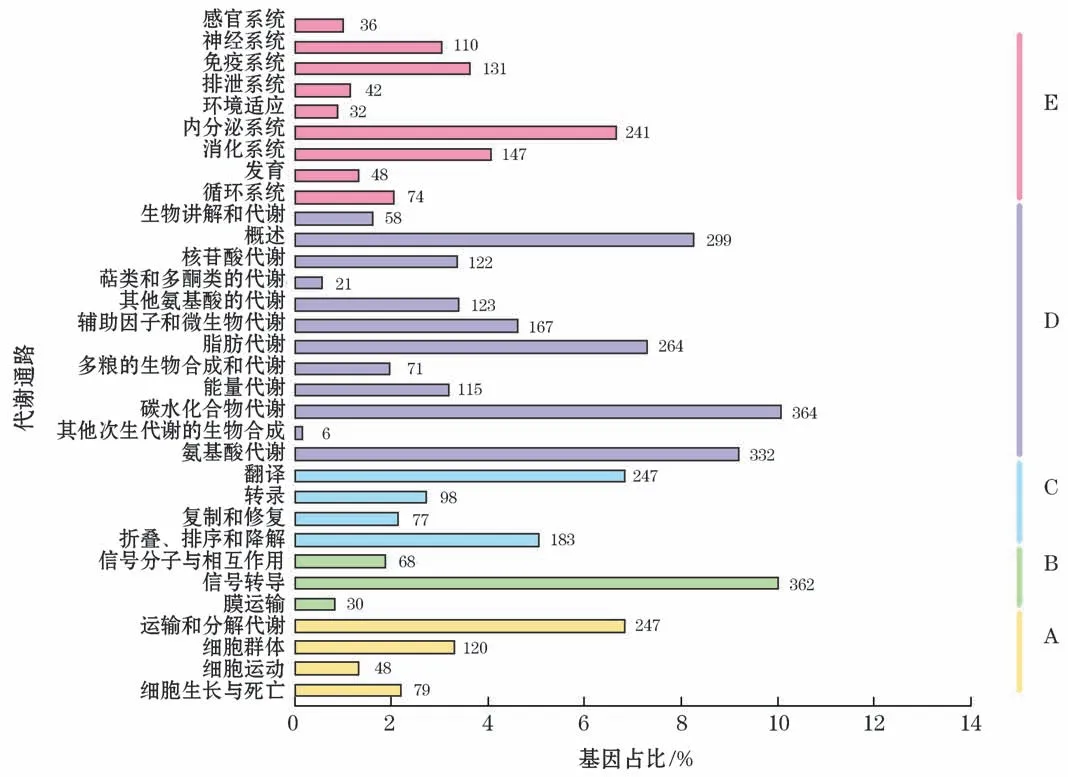
图4 KEGG 代谢通路分类统计Fig.4 Classification statistics of KEGG metabolic pathway
2.3 差异基因表达分析
针对日本囊对虾在5组不同处理时间进行了N 组和CG 组两两比较分析,识别出亚硝酸盐胁迫下发生变化的基因,并绘制火山图(图5)。结果显示,日本囊对虾在亚硝酸盐协迫下N 组与CG 组两两相比共筛选出3 733个差异表达基因(Differentially Expressed Genes,DEGs);与对照组相比,N6、N12、N24、N48和N96组分别识别出593、606、1 089、497和988个DEGs(表7),其中差异基因数量最多的为N24(1 089个),最少的为N48(497个)。总的来说,下调的DEGs数量(1 943个)比上调的DEGs数量(1 830个)多,在N12、N48和N96组,下调的DEGs比上调的多,而在N6和N24组则相反。
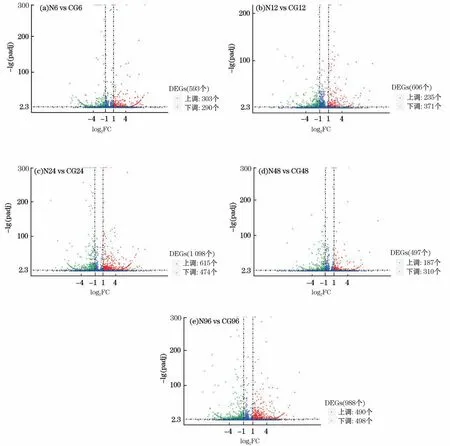
图5 差异基因的火山图Fig.5 Volcano map of differential genes
将N6 vs CG6、N12 vs CG12、N24 vs CG24、N48 vs CG48和N96 vs CG96各组的DEGs数量进行统计,绘成韦恩图(Venn Diagram),找到在亚硝酸盐胁迫下5 组不同处理时间的19 个共同DEGs(图6)。把DEGs分别与NR、NT、KOG/COG、PFAM、Swiss-Prot、KEGG 和GO 七个数据库进行比对和功能注释,至少注释到1个数据库的概率分别为89.88%、89.93%、90.36%、89.54%和90.49%(表7)。19 条共同的DEGs注释和上下调情况如表8,结果显示有8个假定蛋白基因(Hypothetical Protein),其他的多为免疫基因,如ATP结合盒转动体(ATP-binding cassette transporter)、C 型凝集素(C-type lectin)、磷酸烯醇丙酮酸羧激酶醇(phosphoenolpyruvate carboxykinase)、磷脂氢过氧化物(phospholipid-hydroperoxide glutathione peroxidase)、谷胱甘肽过氧化物酶(prophenoloxidase b)和预测:细胞色素P450 9e2 亚型X1(cytochrome P450 9e2isoform X)等。
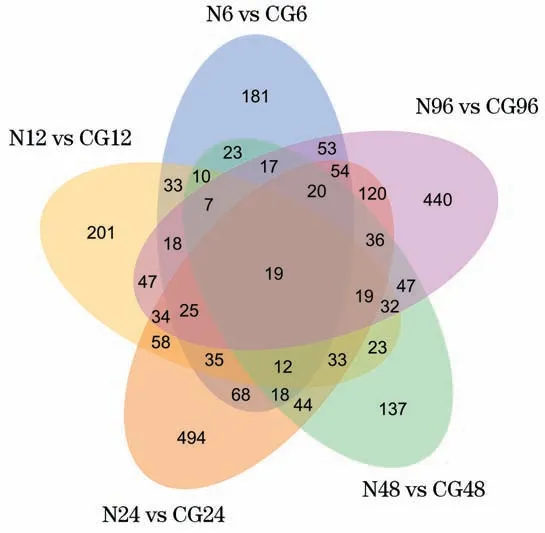
图6 差异基因韦恩图Fig.6 Venn diagram of DEGs

表7 DEGS的数目及注释率Table 7 Quantity and annotation rate of DEGs

表8 不同胁迫时间下共同差异基因筛选情况Table 8 Screening of common differential genes under different stress times
2.4 差异基因的GO 功能分类和KEGG 富集分析
对N6 vs CG6、N12 vs CG12、N24 vs CG24、N48 vs CG48和N96 vs CG96五组比较所得的DEGs分别进行GO 富集分析,共富集到1 758~2 399个GO terms type。DEGs富集到生物过程中的数量最多,占总数的58.76%~61.06%,分子功能次之(表9)。对5组显著富集(P<0.05)的GO 相关的上调基因(红色)和下调基因(蓝色)的分类统计做成柱状图(图7),由图7可见,N24 vs CG24组DEGs显著富集到生物过程、细胞组分和分子功能,其他组富集到生物过程和分子功能;在生物过程中,几丁质代谢过程、含氨基葡萄糖的复合代谢过程和氨基糖代谢过程富集到所有组中;另外,氧化还原过程在N6 vs CG6、N12 vs CG12和N48 vs CG48组中显著富集且富集到DEGs最多;在分子功能中,氧化还原酶活性、铁离子结合、血红素结合和几丁质结合富集于所有组中;在N24 vs CG24中富集到最多DEGs的3个细胞组分是细胞外区、线粒体和线粒体部分。


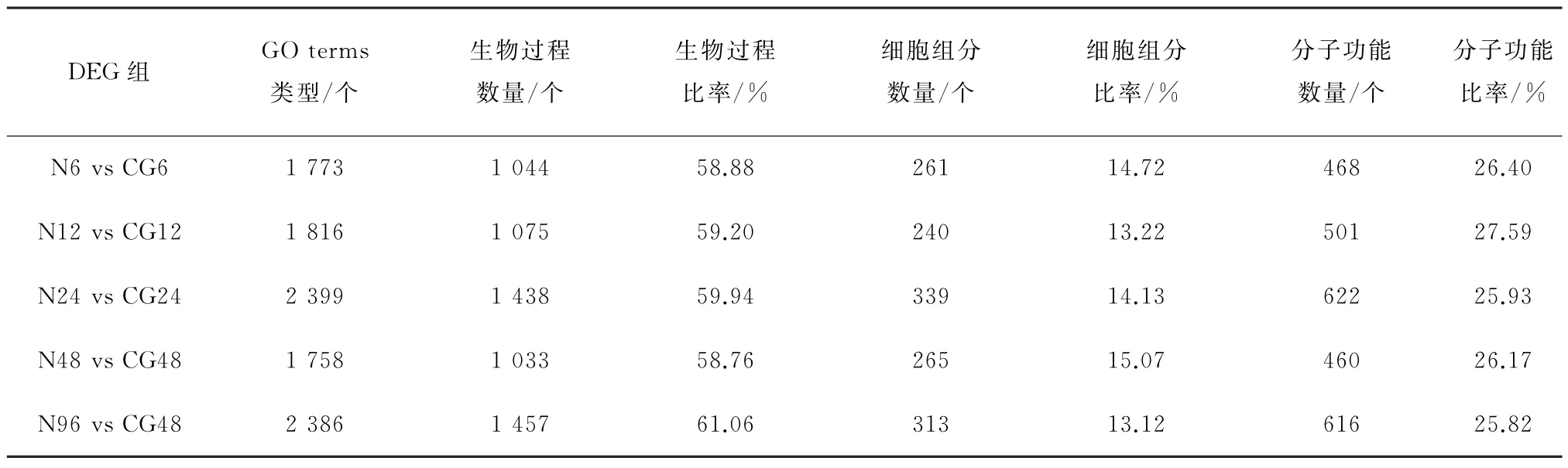
表9 差异基因GO 富集分析Table 9 GO enrichment analysis of differential genes
对N6 vs CG6、N12 vs CG12、N24 vs CG24、N48 vs CG48 和N96 vs CG96 的DEGs数量分别进行KEGG 通路富集分析,结果显示,分别有82、100、174、73和166个通路发生激活或抑制。对每组的前20个(top20)通路富集做散点图(图8)。如图8所示,发生显著富集的KEGG 通路有溶酶体(ko04142)、TGF-β信号通路(ko04350)、AMPK 信号通路(ko04152)、PI3K-Akt信号通路(ko04151)、p53信号通路(ko04115)、过氧化物酶体(ko04146)、吞噬体(ko04145)、细胞凋亡(ko04210)、PPAR 信号通路(ko03320)、胆碱代谢(ko05231)、亚油酸代谢(ko00591)、精氨酸和脯氨酸代谢(ko00330)等。

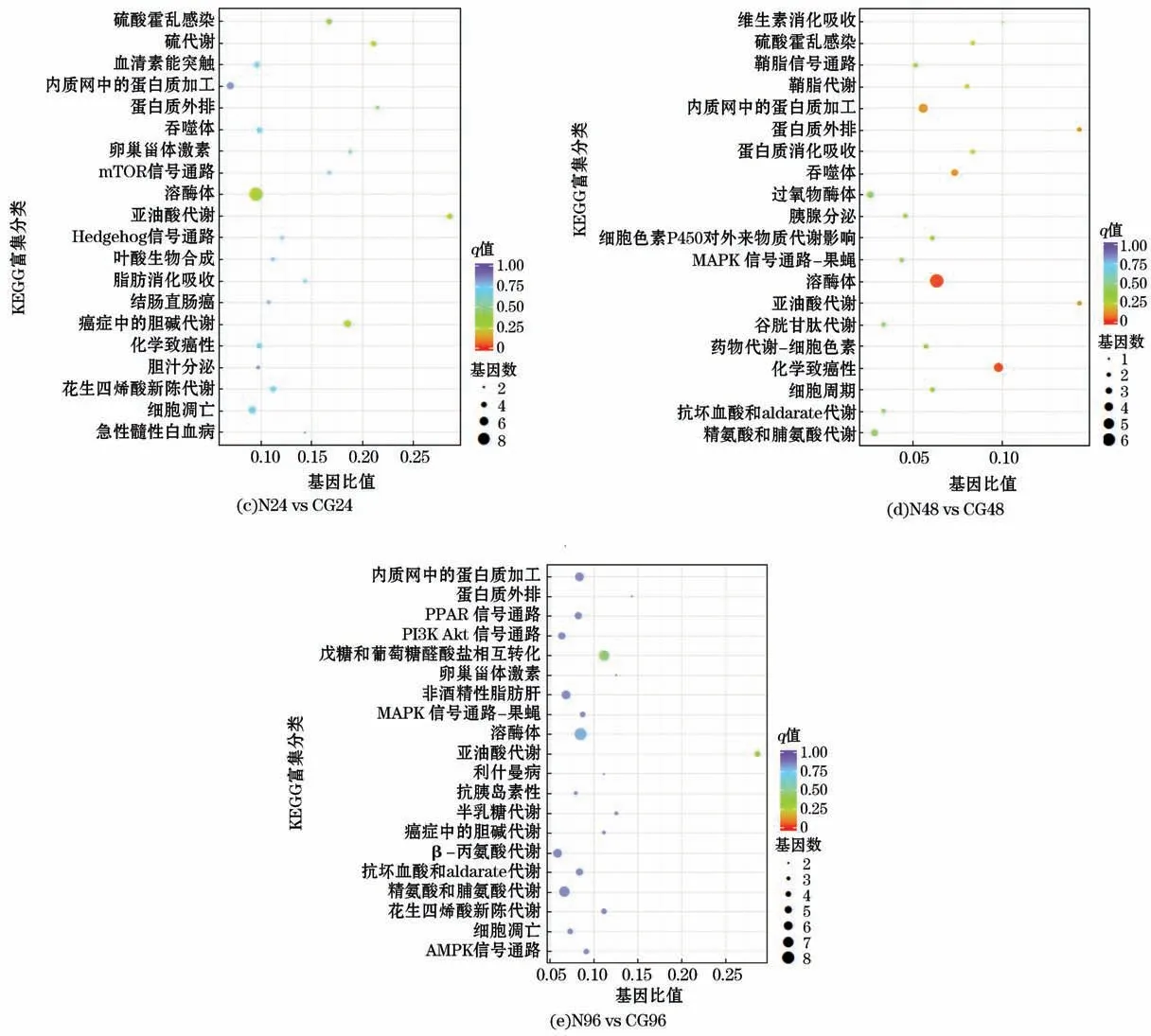
图8 差异基因KEGG 通路富集散点图Fig.8 Enrichment scatter plot of differential genes in KEGG pathway
2.5 qPCR验证RNA-seq
采用qPCR 检测在高亚硝酸盐胁迫下9 个差异基因(DPD、ABCH、Pro POb、ACADL、CYP2J、PAT4、BH MT、CLEC和PEPCK)的表达情况。qPCR 结果显示,基因在不同时间的高亚酸盐胁迫下,呈现显著上调或下调(P<0.05或P<0.01),且与RNA-seq趋势一致。这一结果进一步验证了RNA-seq的可靠性和准确性(图9)。
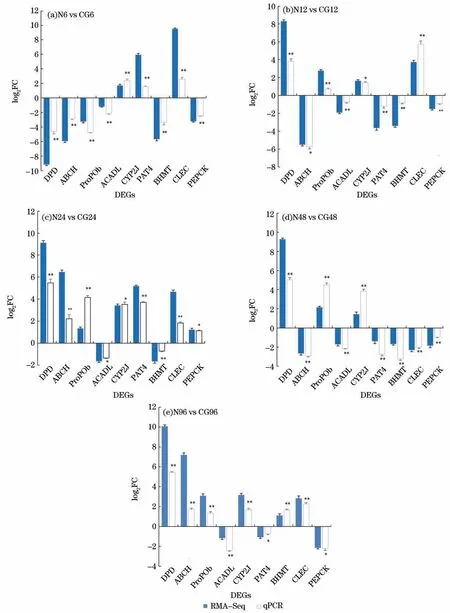
图9 9个差异表达基因的qRT-PCR 与转录组的比较Fig.9 Comparison of 9 DEGs by qRT-PCR and transcriptome
3 讨论
日本囊对虾集约化的养殖模式容易引起亚硝酸盐的积累,从而影响该虾类的健康养殖[14]。为了在分子水平上更好地了解虾类对亚硝酸盐胁迫反应,采用转录组测序研究高亚硝酸盐胁迫下日本囊对虾调控机制和差异基因表达。研究利用Illumina测序平台,获得了不同时间(6、12、24、48和96 h)高亚硝酸盐胁迫下日本囊对虾肝胰腺的转录组数据。通过Trinity软件对获得的净读本进行组装,去除冗余之后获得46 308条unigenes,N50和N90分别为1 833 bp和435 bp,平均长度为1 098 bp。墨吉明对虾(Fenneropenaeus mer-guiensis)的转录组获得41 877条unigenes,N50为1 533 bp[42]。凡纳滨对虾的转录组获得52 073条unigenes,平均长度为520 bp,N50为745 bp[43]。日本囊对虾组装的unigenes数量比凡纳滨对虾少,而比墨吉明对虾多,但组装长度大于凡纳滨对虾和墨吉明对虾。采用BUSCO 对拼接得到的unigenes进行质量评估,结果显示有978个BUSCO 被完全覆盖,完全匹配到的unigenes为902条,占总数的95.1%,部分片段匹配和没有匹配的unigenes分别占总数的2.7%和2.2%。因此,认为该转录组具有高质量的组装拼接数据。
甲壳类动物缺乏适应性免疫系统,而完全依赖于先天免疫系统抵制入侵的病原体或响应环境胁迫[44-45]。甲壳类动物免疫学研究主要集中在识别感染过程中激活的防御机制和生化途径,如凝集素、酚氧化酶原系统(proPO)、吞噬和包围等[46-47]。例如,中国对虾被WSSV感染后,吞噬体、补体和凝血级联反应等与免疫应答有关的通路以及免疫基因可被激活[48]。本研究对差异基因进行KEGG 注释,发现吞噬体(ko04145)通路在6、24和48 h时被富集,且该通路的差异基因显著上调,这表明在高亚硝酸盐胁迫下通过激活吞噬体通路来参与免疫调节应答,这与中国对虾相似。另外,还发现大量与免疫相关其他的通路,如溶酶体(ko04142)、TGF-β信号通路(ko04350)、PI3K-Akt信号通路(ko04151)、p53信号通路(ko04115)、吞噬体(ko04145)、细胞凋亡(ko04210)、PPAR信号通路(ko03320)等。Guo等[32]研究了高亚硝酸盐胁迫凡纳滨对虾的转录组同样发现了凋亡信号通路、p53信号通路、PPAR 信号通路、MAPK 信号通路以及吞噬作用通路,这与本研究一致。而溶酶体(ko04142)、TGF-β信号通路(ko04350)在亚硝酸盐胁迫日本沼虾的转录组中也被富集到[33]。这些研究结果表明,亚硝酸盐胁迫下,对虾的这些免疫通路起着至关重要的作用,具体的机制还有待进一步研究。
根据差异基因韦恩图以及注释结果,我们选择了9个DEGs进行qPCR分析,结果显示高亚硝酸盐胁迫后,这些参与免疫应答的基因表达水平均发生显著变化。Wei等[49]和Wang等[50]研究表明,C型凝集素在先天性免疫中起着重要的作用,能有效识别和消灭病原体。当细菌感染凡纳滨对虾[48]和中国对虾[50]时,C型凝集素基因的表达水平会升高。在本研究中,C型凝集素基因的表达水平呈现上升-下降-上升的趋势,在早期(6~24 h)显著上调,到48 h时受到抑制,而96 h时又显著上调。墨吉明对虾的C型凝集素基因表达量在感染弧菌后的早期(12 h前)显著上升,而在24和48 h时下降[51],与本研究类似。因此,C型凝集素基因在对虾环境胁迫下起着重要的调节作用。甲壳类动物的酚氧化酶原(pro PO)系统在非自我识别与宿主免疫反应中起重要作用[52-54]。Prophenoloxidase b有助于甲壳类动物血浆的黑色素化,为先天免疫系统的一个主要组成部分[55]。在本研究中发现,Prophenoloxidase b的表达水平在亚硝酸盐胁迫下早期显著下调,12 h之后显著上调,推测酚氧化酶原b(ProPO b)基因主要通过促进表达来参与免疫应答。同时,在共同差异基因中还发现了与免疫相关的磷脂氢谷胱甘肽过氧化物酶(Phospholipid Hydroperoxide Glutathione Peroxidase,PHGPx)和细胞色素P450(cytochromeP450)异构体基因。谷胱甘肽过氧化物酶(Glutathione Peroxidase,GPx)在脂质和过氧化氢的解毒过程中起重要作用,脂质和过氧化氢在吞噬或生理代谢过程中,随着谷胱甘肽的氧化而迅速形成[56]。PHGPx是谷胱甘肽过氧化酶(GPx)家族中的一种抗氧化酶,它能降低磷脂的过氧化氢,维持生物膜的完整性[57]。已有研究表明,在LPS应激下,拟穴青蟹(Scylla paramamosain)肝胰腺中的PHGPx表达水平分别在6和12 h显著上调,之后表达量逐渐下调至正常水平[58]。在本研究中发现PHGPx在亚硝酸盐胁迫下表达量呈现上调和下调交替的现象,与拟穴青蟹中PHGPx的表达情况类似,推测PHGPx在日本囊对虾的免疫调节中起着重要作用。细胞色素P450(CytochromeP450)是一种重要的解毒酶,在甲壳类动物体内外源性和内源性化合物的生物转化中起着重要作用[59-60]。在共同差异基因中发现一个细胞色素P450的异构体基因,该基因的表达水平在高亚硝酸盐胁迫6~96 h内显著上升。在凡纳滨对虾转录组中同样发现了很多与P450相关的基因,这些发现为深入研究无脊椎动物的解毒反应提供了丰富的信息[31]。因此,推测这些免疫基因可能参与了亚硝酸盐胁迫的免疫应答,具体功能仍需要进一步研究。
