基于句法特征的突发自然灾害网络舆情事件识别方法研究
2022-06-06陈健瑶夏立新舒怡娴
陈健瑶 夏立新 舒怡娴


摘 要:[目的/意义]从事件文本句法特征视角出发,提出一种面向突发自然灾害的网络舆情事件识别方法,使得从小规模数据集中精准的识别事件成为一种可能。[方法/过程]通过数据采集和事件语义标注构造训练集,接着提出了一种面向突发自然灾害网络舆情事件识别的句法特征提取方法,利用句法特征提取方法从训练集中提取事件句法构造事件句法特征库,同时以句法向量的形式表示待测事件文本,最后利用事件句法与待测句法的句法相似度计算识别事件。[结果/结论]以“台风利奇马”事件为例,证明了本研究提出的事件识别方法能够精准地从突发自然灾害网络舆情文本中识别事件,同时通过对照试验证明了在训练集规模较小的情况下,句法特征优于文本特征的事件识别方法。
关键词:事件识别;突发自然灾害;网络舆情;句法相似度
DOI:10.3969/j.issn.1008-0821.2022.06.002
〔中图分类号〕G250.2 〔文献标识码〕A 〔文章编号〕1008-0821(2022)06-0017-10
Abstract:[Purpose/Significance]This paper proposes a method for network public opinion event recognition of sudden natural disasters based on syntactic features.[ Methods/Process]The training set was constructed through data collection and event semantic annotation,and then a syntactic feature extraction method for network public opinion event recognition of sudden natural disasters was proposed.The syntactic feature extraction method was used to extract the event syntax from the training set,construct the event syntax feature library,and represent the event text in the form of syntactic vector;Finally,the syntactic similarity between event syntax and the syntax to be tested was used to calculate and identify events.[ Results/Conclusion]Taking“typhoon lichima”as an example,through test set D2.It is determined that the optimal similarity of“typhoon lichma”event recognition was 0.93.Under this similarity,from the test set D2 55 events and 82 non events were identified in test set D2、D3 the F1 values of the experimental results were 0.851 and 0.929 respectively.At the same time,the comparative experiment shows that the syntactic feature is better than the text feature in the case of small training set.It provides a new reference for the research of network public opinion of sudden natural disasters.
Key words:event identification;sudden natural disaster;internet public opinion;syntactic similarity
我国是世界上突发自然灾害事件频发的国家之一,且灾害事件种类多、灾情造成损失严重。仅在2019年一季度,我国发生的各种自然灾害就造成全国139.6万人次受灾,87人死亡,1.3万人次紧急转移安置,直接经济损失27.9亿元[1],频发的自然灾害给广大人民群众的生命和财产安全带来了极大的威胁。突发自然灾害事件发生后,经由社交媒体的传播,相关灾害事件在网络上引起网民热烈的讨论,得益于社交媒体平台的广泛参与性,网民们在网络上发表着自己对灾害事件的看法或是评论,形成了灾害网络舆情。一方面,灾害网络舆情有利于相关受灾情况和求助信息的传播,在一定程度上缓解了信息闭塞的问题;另一方面,一些未经证实的信息容易在网络上引起一系列的链式反应,进而演变成网络谣言,如果这些网络谣言不及时得到处理,将会引发社会公众的恐慌,甚至影响到地区和国家的和谐稳定。
突发自然灾害网络舆情事件识别能够很好地解决灾害信息中的谣言问题,舆情管理工作者利用事件识别方法从海量的灾害舆情网络文本中识别出网民们热烈讨论的事件,通过对真实灾害情况进行比对,就能发现网民所关注热点中所存在的谣言或者可能潜在成为谣言的信息,进而阻止这类信息的进一步传播。除此之外,利用事件识别方法还能够从灾害网络舆情文本中识别能反映公众态度、舆论走向的事件,进而理清灾害网络舆情的来龙去脉。
因此,事件识别方法对于灾害网络舆情研究工作十分重要。本文通过对网络舆情事件文本句法特征进行研究,以句法特征表示事件文本的内在特征,提出一种适用于特定灾害网络舆情的事件识别方法,从海量的災害网络舆情文本中识别出舆情事件,为灾害网络舆情的进一步研究提供参考。684ED746-DECC-4521-AA5E-60CB09745A21
1 相关研究
突发自然灾害事件关乎人民群众的人身安全和财产安全,因此其所对应的突发自然灾害网络舆情所需要的政府引导与监督要高于其他领域的网络舆情,社交媒体在突发自然灾害网络舆情的演化中应当扮演信息传递和信息交流的角色,而不是谣言和恐慌制造的平台。对于突发自然灾害网络舆情,事件识别研究能够提升政府部门应对突发自然灾害的网络舆情的管理能力,降低为应对突发自然灾害网络舆情中虚假信息所耗费的成本,防止灾害舆情“二次伤害”,合理引导疏解民众负面情绪。
1.1 突发自然灾害网络舆情研究现状
相关学者对我国突发自然灾害网络舆情的研究已取得一定的进展。在突发自然灾害事件网络舆情情感研究方面,金占勇等[2]构建基于LSTM和Word2vec的突发灾害事件网络舆情多情感识别模型,实验结果表明,其所建立的模型在情感识别效果上优于TF-IDF文本向量化方法、基于卷积神经网络以及传统的机器学习方法。陈凌等[3]构建一种用于分析用户情绪上下文的长短期记忆模型(LSTM),对网络舆情用户情感倾向性和公众情感趋势进行分析与预测。刘雯等[4]将情感分析和时间序列分析共同引入到对灾害网络舆情的分析中,以雅安地震为例,建立不同情感舆情走势的时间序列模型并进行预测。
在突发自然灾害网络舆情风险监测研究方面,秦琴等[5]从突发自然灾害的灾害要素、信息特征、媒体传播和受众倾向4个角度,构建了网络舆情风险监测指标体系,并通过具体的量化分析方法保证了指标体系的合理性。张宇等[6]在舆情监测指标构建基础上,提出基于加速遗传算法的BP神经网络(AGABP)风险评估方法,实验结果显示,其所构建的AGABP模型在收敛速度、评估准确度方面优于BP神经网络、逻辑斯蒂曲线,能够用于震灾网络舆情风险管理实践中。刘悦等[7]提出并设计了基于大数据分析法的重大自然灾害事件网络舆情信息智能监测平台,实验结果表明,改进设计平台可有效对自然灾害网络舆情信息进行监测,效果远胜于传统监测平台。
在突发自然灾害网络舆情传播演化及路径分析方面,张岩等[8]将情感分析模型、动态演化模型、话题聚类模型、网络社团模型结合地理可视化技术应用到台风的灾害评估中,并以台风“山竹”事件为例,从情感值与讨论热度两个角度入手,完整地展示本次事件网络舆情的演化过程。李纲等[9]采用生存分析法和内容分析法,描述地震灾害事件和台风灾害事件的网络媒体报道的生命周期,探索影响生存过程的因素,并总结了两类灾害的媒体报道周期特征。王晰巍等[10]应用社会网络分析方法,以“雅安地震”事件为例对新媒体环境下自然灾害舆情传播路径及网络结构进行实证研究,结论显示,自然灾害网络舆情传播受到传播媒介类型的影响。金占勇等[11]运用全面数据分析法,对6·23盐城龙卷风袭击事件的网络舆情传播进行实证研究,得出网络舆情传播具有信息老化、官方传媒信息掌控力更强、舆论引导者舆情传播动力机制不同、舆情传播内容选择多样化等结论。冯小东等[12]将自然灾害的影响程度与网络舆情热度联系起来,指出自然灾害的影响程度与网络舆情热度在时间和空间两个方面存在相关性,并且相关性随着自然灾害强度的增加而增加。
从近些年学者的研究可以看出,关于突发自然灾害网络舆情研究已取得较大的进展,但是关于突发自然灾害网络舆情事件识别的研究较少。因此,本文试图探究一种适用于突发自然灾害下的网络舆情事件识别方法。
1.2 事件识别方法研究现状
事件抽取任务于2005年起被纳入ACE评测会议[13],ACE认为,事件是事物状态的改变或事情的发生,并将事件抽取任务定义为从非结构化的文本中识别并抽取事件信息并结构化表示,包括事件触发词、事件类型、事件元素、元素角色[14]。在框架表示事件抽取的研究中,Petroni F等[15]提出一种从新闻报道和社交媒体中抽取突发事件的框架表示,用于公共安全预警、政府组织决策支持等。Yang H等[16]在2018年提出一种从金融机构的公告信息中抽取金融事件的框架表示方法,用于辅助决策和市场预测等。刘振[17]采用条件随机场方法和语义角色标注技术,构建模型进行训练和学习,提出科技事件抽取框架,实现科技事件抽取系统,取得了一定的抽取效果。在实例表示事件抽取的研究中,Huang L等[18]提出一種全新的自由事件抽取范式,可以同时从任意输入语料中抽取事件和发现事件模式,利用符号特征和分布式语义来检测和表示事件结构;Zhou D等[19]提出一种基于词嵌入的非参数贝叶斯混合模型用于事件抽取,其中,事件的数目可以自动推断,并且可以正确地处理同一命名实体的词法变化问题。
在中文事件抽取任务方面,Chen Z等[20]提出一个中文事件抽取系统,指出汉语触发标记中一个特定语言问题,然后致力于讨论词法、句法和语义特征在触发标记和参数标注中的贡献;Zeng Y等[21]在Chen Z等[20]的字符序列标注方法基础上,使用双向长短期记忆网络和条件随机场[22]抽取句子特征,通过卷积神经网络抽取上下文语义特征,进而实现中文事件的抽取;Lin H等[23]提出一种Nugget Proposal Networks(NPNs)方法,它可以直接提出以每个字符为中心的、不受单词边界限制的整个金块来解决单词触发不匹配问题;Li P等[24]提出两种新的推理机制,通过汉语触发器内部的合成语义和触发器之间的语篇一致性来探索汉语的特殊性。
从现有的事件识别研究可以看出,当前有关事件识别技术已取得一定的进展,且国内学者对于中文事件抽取的研究也取得较为成熟的进步,但同时有关中英文事件抽取的研究也存在一定的问题,就是大多数方法依赖于大规模的训练数据集以保证识别结果的准确性。如果将这些方法直接应用于突发自然灾害网络舆情事件的识别中,可能会在舆情初期面临数据量不足的问题。
1.3 句法特征相关研究
当前关于句法特征的研究大多为利用依存句法分析进行信息抽取或识别,在这方面的研究中,李纲等[26]利用句法特征依存句法分析,设计情感标签抽取算法,实现对抽取出的情感标签地过滤。王娟等[27]利用短语的内部结构和句法功能,分析情感评价对象及其对应的评价短语在句中的句法位置,并结合情感句中词性和词对间的依存关系进行情感评价单元的抽取,最终提升情感评价的整体准确率。任彬等[28]利用依存句法分析,从社交媒体中匹配相关信息,实验证明该方法相比传统方法提升信息抽取准确率。霍珺等[29]采用空间句法分析,为图书馆内部空间在可达性方面的效能评价提供一种客观、量化、图示化的手段。唐晓波等采用依存句法分析来改进传统文本相似矩阵,在此基础上运行聚类算法,挖掘出热点主题。俞琰等[30]利用依存句法分析抽取中文专利术语,过程包括依存句法分析、剪枝、生成依存子树3个主要步骤。684ED746-DECC-4521-AA5E-60CB09745A21
可以看出,依存句法分析利用句法特征能够有效地提升信息抽取的准确率,这是因为句法特征能够直观地表达事件内部的语义结构和语法逻辑。因此,本研究认为,句法特征也能够较好地表示事件特征,并提出一种基于句法特征的舆情事件识别方法,以事件的句法特征表示事件语义结构的逻辑关系,使得事件识别重心绕过了文本特征,聚焦于事件语词之间的句法结构,增强突发自然灾害网络舆情事件识别方法的广泛适用性,为突发自然灾害网络舆情进一步研究提供参考。
2 基于句法特征的突发自然灾害网络舆情事件识别模型构建
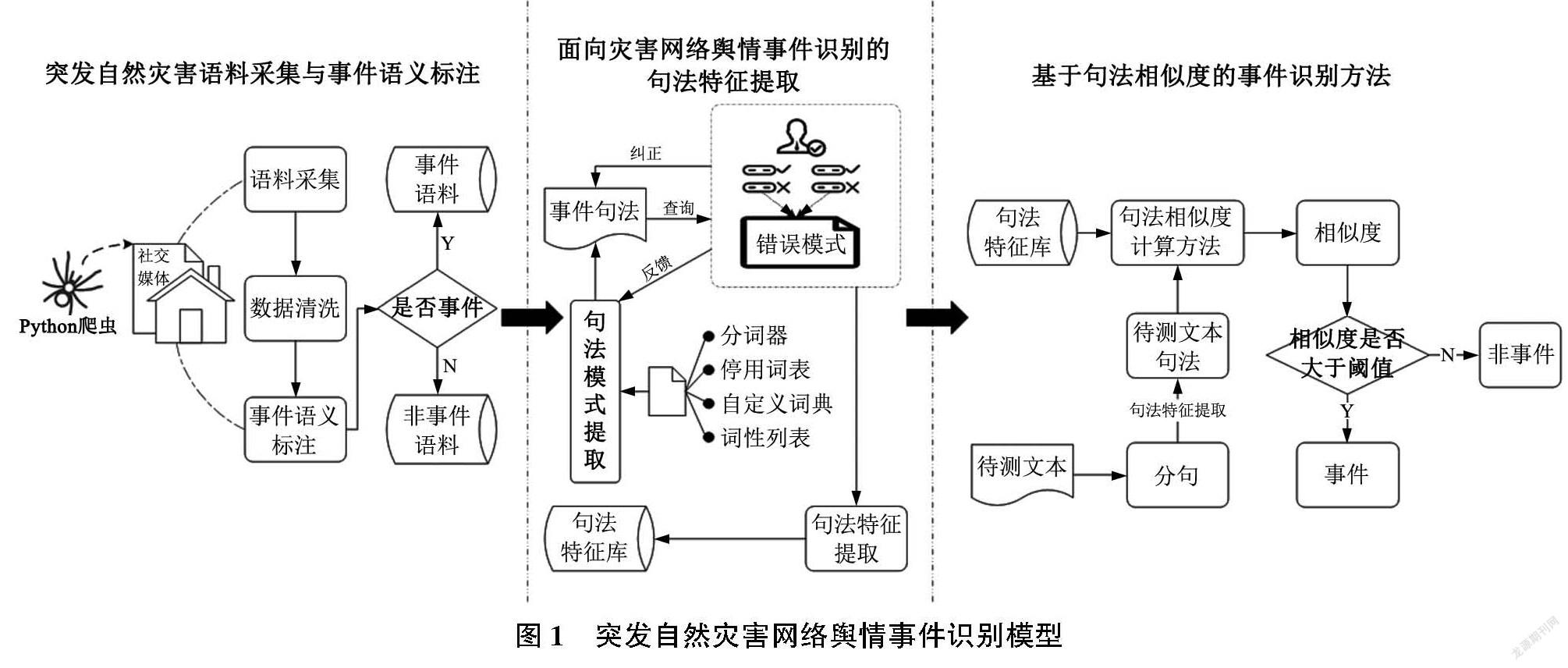
本文构建基于句法特征的突发自然灾害网络舆情事件识别模型,如图1所示,该模型的核心内容是以事件的句法特征表示事件内部的语义逻辑结构从而达到事件识别的目的。模型分为突发自然灾害语料采集与事件语义标注、面向灾害网络舆情事件识别的句法特征提取和基于句法相似度的事件识别方法。首先通过网络爬虫获取训练集语料和测试集语料,测试集语料也就是待识别所包含事件的文本,对语料进行清洗,并对训练集进行人工事件语义标注,获取其中的事件与非事件文本;接着对所标注的事件文本进行句法特征的提取,通过人工识别错误句法特征来降低获取事件句法特征的误差率,最终获得的句法形成事件句法特征库;最后对测试集中的待测文本也进行句法特征提取,将所获取的测试集句法特征与事件句法库中的句法进行相似度计算,句法特征是某一文本本身的特征,而句法相似度是两个不同文本之间通过一定方法所获得的句法特征相似度,相似度越高说明两个文本之间句法特征越为接近,当待测文本与已知事件句法相似度超出模型所设定的阈值时,就可以认为待测文本属于事件文本,相似度阈值通过多次实验确定。
2.1 突发自然灾害语料采集与事件语义标注
通过网络爬虫采集特定突发自然灾害语料,再经由事件语义标注从灾害网络舆情语料中提取一定数量的已知事件作为训练集。灾害网络舆情文本包含大量的实体信息,例如地点实体、时间实体、人物实体、动作实体等一系列的信息,这些信息相互组合形成了灾害网络舆情事件。同时,由于社交媒体文本的随意性和不规范性,一些无实际意义的文本和不能表达出事件信息的文本也充斥在这些实体信息的周围,事件语义标注将这些由实体信息组成的事件从非事件的文本中提取出来。
事件语义标注的过程由人工进行,为了确保标注结果的一致性和无人为差异性,本文定义以下几条事件语义标注注意事项,如表1所示。
2.2 面向灾害网络舆情事件识别的句法特征提取
句法特征提取的目的是为了将已知事件或未知语句中的句法提取出来,方便进行下一步的事件识别。已知事件或未知语句都可以通过分词操作形成一个由词语组成的集合,每一个词语都对应着相应的词性,按照语句分词顺序所构成的词性序列就形成了语句的句法特征。语句的句法特征从语义逻辑层面表达了句子的内在逻辑,这与事件具备一定的语法逻辑是相吻合的,因此可以使用语句的句法特征进行事件识别。同时,使用句法表达事件特征有效地降低了事件的文本维度,使得由成千上百个单词排列组合形成的事件简化为由十几个词性排列组合形成的句法,这也降低了事件识别对于训练集规模的要求,有利于解决灾害网络舆情初期文本语料不足的问题。
对已知事件或未知语句进行句法特征的提取,例如已经经过词性标注的事件文本:
E=[“利奇马”:n,“移出”:v,“浙江”:n,“向”:p,“偏北”:f,“方向”:n,“移动”:v]
对其进行特征提取后得到事件句法特征向量:
P=[n,v,n,p,f,n,v]
在进行事件的句法特征提取时,通过人工纠错的方式减少事件句法特征的误差。例如某些词语存在一词多义的现象,不同的分詞工具可能对于一词多义的词语默认词性不同,这就造成人工语义标注的正确事件经过句法特征提取后产生了错误的句法特征,因此通过人工检查出这些错误的句法特征,将其加入到“wrong_pattern.txt”错误句法词典中,使程序再次遇到相同的错误句法后不再提取;根据2.1所定义的事件语义标注注意事项第2条,所推导出的事件是真实发生过或正在发生的事件,一些未来发生或者否定式的触发词可能会给事件识别的过程带来偏差,例如Jieba分词工具将“不能”“希望”的词性都定义为“v”,这样程序会将这些词语与其他触发词等同起来。为了减少这类词语带来的误差,本文将这类不能表示事件是真实发生过或正在发生的触发词定义为词性“o”,通过区分开这类词语词性来提升模型识别事件的精确性。本文所进行事件句法模式提取的具体过程如算法1所示。
算法1:语句句法特征提取
输入:sentences[0..n-1]:包含n条待处理语句(sentence)的数组;wrong_patterns[0..m-1]:包含m条人工识别错误句法(wrong_pattern)的数组;f1(sentence):对文本进行分词的函数;f2(word):对语词进行词性标注的函数;
输出:patterns事件句法集
1: function Pattern(sentences[0..n-1]:array of sentence;wrong_patterns[0..m-1]:array of wrong_pattern;f1:function;f2:function):patterns;
2: var
3: words[0..m-1]:包含m个词的数组;
4: nominal:词性标注序列;
5: begin
6: for i←0 to n-1 do
7: pattern ← null
8: words[0..m-1]← f1 (sentences[i])684ED746-DECC-4521-AA5E-60CB09745A21
9: for i←0 to m-1 do
10: nominal ← f2(words[i])
11: pattern ← pattern + nominal
12: if pattern not in patterns and not in wrong_patterns then
13: patterns ← patterns+pattern
14: end if
15: return patterns
16: end
2.3 基于句法相似度的事件识别方法
句法相似度计算的目的是为了得到待测事件与事件句法库中已知事件句法特征的相似度。相似度计算度量方法中,余弦相似度度量最为贴近本研究的句法相似度计算方法,因此,本文选用余弦相似度作为相似度计算方法。由于事件文本中必定包含表示一个或多个动作或者状态改变的触发词,因此选用σ作为触发词变量,若待测事件句法Pd=[x1,x2,…,xi]中不包含触发词,触发词变量赋值为0;反之,触发词变量赋值为1。同时待测事件句法与事件句法库Pt={P1,P2,…,Pn|Pi=[y1,y2,…,yi],i≤n}进行余弦相似度计算,取Pd和Pi最大余弦值为最终相似度,计算方法如式(1)。
cos(θ)=∑ni=1(xj·yj)∑ni=1x2i·∑ni=1y2i·σ(1)
句法特征向量的相似度能够从语义层面表达两个事件在语法规则和语言形式描述方面的相似度,句法相似度越大表明待测事件句法与事件句法库中的事件句法越接近,当相似度为100%时,表明相同的事件句法已经存在于句法库中,因此设置适当的相似度阈值作为最终的判断标准十分重要,最终所计算的句法相似度大于阈值,即可判定待测文本为事件文本,相似度阈值利用训练集通过多次实验获得,取最优相似度为最终阈值。
事件句法相似度计算算法如算法2所示。
算法2:事件句法相似度计算
输入:patterns[0..n-1]:包含n条事件句法特征(pattern)的数组;sentence:待测文本的语句句法;f1(sentence):输入句法中含有触发词σ,返回1,否则返回0;f2(pattern,sentence):计算两个事件句法的余弦相似度;
输出:cos事件句法相似度
1: function Cos(patterns[0..n-1]:array of pattern;sentences:text to be tested;f1:function;f2:function):cos;
2: var
3: σ:触发词识别变量;
4: cos:句法相似度;
5: temp:临时变量;
6: begin
7: for i←0 to n-1 do
8: pattern ← patterns[i]
9: σ ← f1 (sentence)
10: temp ← f2(pattern,sentence)
11: temp ← temp·σ
12: if temp>cos then
13: cos ← temp
14: end if
15: return cos
16: end
3 基于事件识别模型的突发自然灾害网络舆情事件识别实证研究——以“台风利奇马”为例
2019年,第9号台风“利奇马”在浙江省温岭市城南镇沿海登陆[25],因其巨大的破坏力和持久性在社交媒体中引发了长时间的讨论,产生了丰富的突发自然灾害下的网络舆情语料。因此,本文以“台风利奇马”事件为例,借助本文构建的基于句法特征的突發自然灾害网络舆情事件识别模型进行实证研究,验证所提出的灾害网络舆情事件识别模型的有效性,将模型转化为“台风利奇马”网络舆情事件识别的具体识别步骤,如图2所示。
3.1 数据采集与句法模式提取
通过自主编写Python爬虫从新浪微博采集“台风利奇马”相关话题下的微博文本语料信息,共得到3 556条有效微博内容。针对事件识别模型对训练集和测试集的不同要求,将所采集到的微博内容划分为3个文档:训练集D1、测试集D2、测试集D3,其中,训练集D1用以构造灾害舆情事件句法库,测试集D2用以确定最优相似度阈值,测试集D3用以从中识别出灾害舆情事件。
训练集D1按照2.1所提出的事件标注注意事项,共标注事件2 027件。再通过2.2所提出的句法特征提取方法,将这些事件转换为句法特征,经过人工纠错以及排除因分词工具产生的错误句法后,成功构造了一个包含1 752条有效句法的句法特征库,句法特征库中的句法特征集用P1={P1,P2,…,Pn|Pi=[x1,x2,…,xi],i≤n}表示。事件与句法库中句法对应情况(部分)如图3所示,其中,空白部分表示因误差产生错误句法而不进入句法库的情况。684ED746-DECC-4521-AA5E-60CB09745A21
3.2 相似度阈值确定
句法相似度衡量当前待测事件句法与已知事件句法库中的最高相似度,因此设定一个相似度阈值作为待测事件是否是真的事件显得尤为重要。笔者认为,针对不同特定突发自然灾害网络舆情,其最优相似度有所差别,需要通过实验获得特定突发自然灾害网络舆情下的相似度阈值。
测试集D2经过事件标注后得到99件事件、102件非事件,对标注结果进行句法特征提取获得句法特征集P2=[x1,x2,…,xi],部分标注事件结果及对应句法如图4所示。
根据2.2所提出的句法相似度计算方法计算P2=[x1,x2…,xi]与句法特征库P1={P1,P2,…,Pn|Pi=[x1,x2,…,xi],i≤n}的相似度,取最高相似度为最终相似度,部分计算结果如表2所示,其中id范围1~99为事件、id范围100~201为非事件。
根据测试集D2句法相似度计算结果,确定适用于突发自然灾害事件“台风利奇马”的最优相似度。按照步长0.01在区间[0,1]中依次取最优相似度值,以F1值为判断指标,能获得最高F1值的相似度即为最优相似度,F1值的计算方法如式(2)所示:
F1=2PRP+R(2)
其中,P、R分别代表查准率和查全率。
经实验计算,以“台风利奇马”突发自然灾害事件为例的文本语料中,最优相似度的值为0.93,在此基础上测试集D2的F1值、P值、R值分别为0.851、0.835、0.869,具体实验结果如图5所示。从图5可以看出,P值随着相似度的增大而减小,而R值随着相似度的增大而增大,这就说明相似度越大就有越多的事件能被识别出来,但是也降低了其准确性,只有当相似度阈值为0.93时,才能达到最优结果。
3.3 事件识别结果分析
通过测试集D2确定“台风利奇马”事件识别最优相似度为0.93,因此接下来以最优相似度0.93为度量标准去识别测试集D3语料中的事件。测试集D3提前不进行事件语义标注而进行语句分句,用以模拟从未知文本中识别事件的过程。对待测事件文本进行分句的过程需要注意,由于提前并不清楚事件在文本中的位置和结构关系,无法通过一次性的分句确定其中的事件结构,事件本身也可以作为另一个事件的一部分,例如:在文本“台风利奇马登陆山东,使东营普降暴雨”中,“台风利奇马登陆山东”是一个事件,同时“台风利奇马登陆山东”作为一个事件实体也是“使东营普降暴雨”事件的施事者,因此,本文通过重复分句的方式确保识别尽可能多的事件。
对测试集D3进行重复分句操作得到分句结果S3={s1,s2,…,sn},再对分句结果进行句法特征提取得到测试集D3的句法特征集P3={,
在以“台风利奇马”为例的突发自然灾害事件中,通过人工标注的测试集D2,确定在该灾害网络舆情中,最优相似度为0.93,同时F1值达到了0.851;利用最优相似度成功从未经人工标注的测试集D3中识别出事件和非事件,实验结果的F1值达到了0.93;同时,为证明本文所提出基于句法特征的事件识别方法在训练集语料规模不大的情况下的优越性,将基于文本特征的事件识别方法作为对照组,采用相同的数据集和实验步骤,实验结果证明本文所提出的方法优于基于文本特征的识别方法。
面对突发自然灾害事件,社交媒体往往承担着信息交流平台的作用,其信息交流强度要远高于传统的新闻报刊,因此,社交媒体成为了折射网络舆情的传感器。快速高效地识别出社交媒体灾害网络舆情文本中所包含的事件,有助于政府管理部门及时发现网络中存在的谣言,帮助网络舆情研究人员厘清灾害网络舆情发展的来龙去脉。本文提出了一种基于句法特征的突发自然灾害网络舆情事件识别方法,为突发自然灾害网络舆情的进一步研究提供参考。同时,本研究也存在一定的局限性,本文所研究的事件识别方法在小规模数据集中能表现出较大的优势,但在大规模数据集中存在一定的劣势,因此当前研究方法适用于突发自然灾害网络舆情初期的事件识别,在后续研究中将考虑结合句法特征与传统的事件识别方法,使其能够在大规模数据集中展现出较大的优势。
参考文献
[1]新华社.应急管理部发布2019年一季度全国自然灾害情况[EB/OL].https://baijiahao.baidu.com/s?id=163014200439994 6578&wfr=spider&for=pc,2019-04-07.
[2]金占勇,田亚鹏,白莽.基于长短时记忆网络的突发灾害事件网络舆情情感识别研究[J].情报科学,2019,37(5):142-147,154.
[3]陈凌,宋衍欣.基于公众情绪上下文的LSTM情感分析研究——以台风“利奇马”为例[J].现代情报,2020,40(6):98-105.
[4]刘雯,高峰,洪凌子.基于情感分析的灾害网络舆情研究——以雅安地震为例[J].图书情报工作,2013,57(20):104-110.
[5]秦琴,汤书昆.突发自然灾害网络舆情风险监测指标体系研究[J/OL].电子科技大学学报:社会科学版:1-9[2020-06-14].https://doi.org/10.14071/j.1008-8105(2019)-3023.
[6]张宇,傅敏,羅加蓉.震灾网络舆情风险监测指标及其评估方法[J].重庆大学学报:社会科学版,2018,24(6):33-44.
[7]刘悦,杨桦.基于大数据的自然灾害事件网络舆情信息监测平台[J].灾害学,2018,33(4):13-17.
[8]张岩,李英冰,郑翔.基于微博数据的台风“山竹”舆情演化时空分析[J/OL].山东大学学报:工学版:1-9[2020-06-14].http://kns.cnki.net/kcms/detail/37.1391.T.20200221.1529.004.html.
[9]李纲,海岚,陈璟浩.突发自然灾害事件网络媒体报道的周期特征分析——以地震和台风灾害为例[J].信息资源管理学报,2015,5(3):18-24.
[10]王晰巍,文晴,赵丹,等.新媒体环境下自然灾害舆情传播路径及网络结构研究——以新浪微博“雅安地震”话题为例[J].情报杂志,2018,37(2):110-116.
[11]金占勇,田亚鹏,张洋.突发灾害事件网络舆情特征分析——以6·23盐城龙卷风事件为例[J].吉首大学学报:社会科学版,2018,39(S2):72-78.
[12]冯小东,李卓雅,史志慧.基于网络舆情热度的自然灾害影响评估分析[J].情报探索,2020,(1):16-22.
[13]Aguilar J,Beller C,McNamee P,et al.A Comparison of the Events and Relations Across Ace,Ere,Tac-kbp,and Framenet Annotation Standards[C]//Proceedings of the Second Workshop on EVENTS:Definition,Detection,Coreference,and Representation,2014:45-53.
[14]Doddington G R,Mitchell A,Przybocki M A,et al.The Automatic Content Extraction(ACE)Program-Tasks,Data,and Evaluation[C]//Lrec,2004,2:1.
[15]Petroni F,Raman N,Nugent T,et al.An Extensible Event Extraction System With Cross-Media Event Resolution[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.ACM,2018:626-635.
[16]Yang H,Chen Y,Liu K,et al.DCFEE:A Document-level Chinese Financial Event Extraction System based on Automatically Labeled Training Data[C]//Proceedings of ACL 2018,System Demonstrations,2018:50-55.684ED746-DECC-4521-AA5E-60CB09745A21
[17]刘振.基于网络科技信息的事件抽取研究[J].情报科学,2018,36(9):115-117,122.
[18]Huang L,Cassidy T,Feng X,et al.Liberal Event Extraction and Event Schema Induction[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers),2016:258-268.
[19]Zhou D,Zhang X,He Y.Event Extraction from Twitter Using Non-parametric Bayesian Mixture Model with Word Embeddings[C]//Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics:Volume 1,Long Papers,2017:808-817.
[20]Chen Z,Ji H.Language Specific Issue and Feature Exploration in Chinese Event Extraction[C]//Proceedings of Human Language Technologies:The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics,Companion Volume:Short Papers,2009:209-212.
[21]Zeng Y,Yang H,Feng Y,et al.A Convolution BiLSTM Neural Network Model for Chinese Event Extraction[M].Natural Language Understanding and Intelligent Applications.Springer,Cham,2016:275-287.
[22]Lafferty J,McCallum A,Pereira F C N.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proc of the 18th Intelligence Conference on Machine Learning.Francisco,CA,USA:Morgan Kaufmann Publishers Inc,2001:282-289.
[23]Lin H,Lu Y,Han X,et al.Nugget Proposal Networks for Chinese Event Detection[C]//Proc of the 56th ACL,Volume 1:Long Papers.Melbourne,Australia:ACL,2018:1565-1574.
[24]Li P,Zhou G,Zhu Q,et al.Employing Compositional Semantics and Discourse Consistency in Chinese Event Extraction[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:1006-1016.
[25]中國气象局.超强台风“利奇马”在浙江温岭市城南镇登陆[EB/OL].http://www.cma.gov.cn/2011xwzx/zdbk/jdbkxw/2019 08/t20190810_532548.html,2021-09-11.
[26]李纲,刘广兴,毛进,等.一种基于句法分析的情感标签抽取方法[J].图书情报工作,2014,58(14):12-20.
[27]王娟,曹树金,谢建国.基于短语句法结构和依存句法分析的情感评价单元抽取[J].情报理论与实践,2017,40(3):107-113.
[28]任彬,车万翔,刘挺.基于依存句法分析的社会媒体文本挖掘方法——以饮食习惯特色分析为例[J].中文信息学报,2014,28(6):208-215.
[29]霍珺,卢章平.基于空间句法分析的高校图书馆建筑空间可达性研究[J].图书情报工作,2017,61(6):53-60.
[30]俞琰,陈磊,姜金德,等.基于依存句法分析的中文专利候选术语选取研究[J].图书情报工作,2019,63(18):109-118.
(责任编辑:陈 媛)684ED746-DECC-4521-AA5E-60CB09745A21
