基于YOLOv5的微小型无人机实时探测方法
2022-06-04包文歧谢立强徐才华刘智荣
包文歧,谢立强,徐才华,刘智荣,朱 敏
(陆军工程大学 国防工程学院, 南京 210007)
1 引言
随着无线通信、飞行控制、惯性器件、智能视频分析等技术的快速发展,当前微小型无人机技术逐步成熟,并展示出了强大的功能,使其在公共安全、能源电力、农业植保等多种行业领域都得到了广泛应用。随着小型商用无人机的成本不断下降,购买无人机的爱好者数量连年攀升,根据中国民航局的官方公布数据显示,截至2020年底,我国实名登记无人机52.36万架,年飞行量达到159.4万小时,同比增速达27.5%。然而,随着微小型无人机在民用领域爆炸式增长,监管难度越来越大,其对公共安全构成了严重威胁,给城市安保带来了更大的挑战。例如,2021年4月3日,杭州萧山机场发生了因无人机黑飞导致多架航班空中盘旋、备降其他机场的案件,严重影响航空秩序,威胁机场安全。因此,通过技术手段构建无人机监测系统,对非法飞行的无人机进行精确探测与反制,对确保重要目标空域安全,保障社会安全稳定具有重要意义。
目前,国内外针对无人机探测的常用技术主要有雷达探测、声学探测、无线电探测、光电探测等。由于微小型无人机具有体积小,运动灵活的特点,传统的手段难以探测如此小的飞行器,更不能识别此类无人机。因此,微小型无人机的探测是一个亟待解决的难题。
近年来,随着深度学习技术的飞速发展,基于深度学习的目标检测算法是实现微小无人机探测个一种可行手段。基于深度学习的目标检测算法主要有一阶检测方法和二阶检测方法两类,一阶检测方法不需要单独寻找候选区域,因此速度较快,如SSD(single shot multibox detector)、YOLO(you only look once)等。二阶检测方法则将检测算法分两步进行,先要获取候选区域,再对其进行分类,精度上一般优于一阶方法,如R-CNN(region-based convolutional neural network)、Fast R-CNN等。在实际应用中需要对采集的无人机视频流进行实时探测,二阶算法难以满足实时性要求,而YOLO系列算法近年来更新迭代很快,在主流数据集的测试效果上要优于SSD算法。李秋珍等提出了2种基于SSD改进算法的实时无人机识别方法,但2种改进方法精度分别只有79%和83.75%,作者认为该算法识别速度基本满足实时性要求。马旗等人提出了基于优化YOLOv3的低空无人机检测识别方法,利用残差网络及多尺度融合的方式对原始的YOLOv3网络结构进行优化,在相同训练集下测试,mAP提升了8.29%,达到82.15%,检测速度为26 s,满足实时性要求。陶磊等人提出了基于YOLOv3的无人机识别与定位追踪方法,用YOLOv3输出视频中的无人机位置信息,再用PID算法调节摄像头角度实现无人机定位追踪,模型在测试集上能达到83.24%的准确率和88.15%的召回率,在配备有英伟达1060显卡的计算机上能达到20帧每秒的速度。YOLO算法无需对目标和背景进行复杂的人工建模,构建过程相对简单,泛化能力强,发展很快,且识别速度和识别准确性方面有一定的优势,已应用于多个场景,如疫情期间口罩佩戴检测、初期火灾探测,已成为目标检测的研究热点。目前YOLO算法已经更新到第五版本YOLOv5,其体积缩小到约原来的1/9,检测速度得到大幅提升,精度方面也有不错的表现。因此,本文提出采用第五版本的YOLO算法实现对微小型无人机的实时探测。首先,根据自行拍摄的无人机飞行时的照片构建数据集;其次,搭建深度学习环境,使用YOLOv5轻量化模型对数据集进行训练;最后,用训练得到的模型对视频或图片中的微小型无人机进行探测。
2 YOLO v5算法原理
YOLO算法最初是由Joseph Redmon等于2016年提出来的一种目标识别方法,其创新性在于把检测当作回归问题处理,只需一阶检测,用一个网络就可快速输出目标位置和种类,其最大的优势就是通过简洁的算法可以获得出色的识别效果。Redmon对算法进行改进依次推出了YOLOv2、YOLOv3两个版本。Alexey Bochkovskiy等人推出了YOLOv4版本。随着YOLO的不断更新迭代,其算法变得更快更精确,Glenn Jocher在2020年推出了最新版本的YOLOv5。YOLOv5版本是基于YOLOv4版本改进的,采用了PyTorch框架代替了YOLOv4版本的Darknet框架,网络部分未作修改,仅对参数进行调整优化,使得检测速度大幅提升,最快的检测速度达到了140FPS;同时,YOLOv5把权重文件的体积进行了缩小优化,只有YOLOv4的1/9左右。
YOLO v5算法检测可分为3步:首先统一调整图像的大小后进行分割,然后用卷积神经网络提取特征,最后通过非极大值抑制(non-maximum suppression,NMS)筛选重复预测的边框,输出最终的预测结果。算法先对所有图像进行尺寸调整后,将输入图像划分为×个格子,不同格子只负责其对应区域的物体识别,减少了重叠识别,大大减少了计算量。每个格子会预测其内部是否存在目标的位置中心坐标,若某个目标的中心位置落入其中某一个格子,那么该物体的识别就会由这个格子来负责。每个小格子将预测A个假定类别的概率和个边界框,每个边界框包含5个参数,分别为,,,和,其中(,)为预测边框的中心点坐标;(,)为预测边框的宽度和高度。反映边框中是否包含目标以及包含目标时预测目标位置的准确性,其由式(1)计算得到。
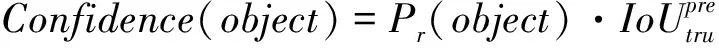
(1)
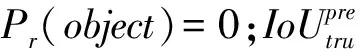
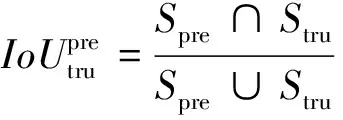
(2)
其中,为物体预测框(predicted bounding box)的面积,为物体真实框(ground truth box)的面积。
YOLOv5目标检测模型是基于卷积神经网络实现的,主要由输入端、Backbone、Neck、Prediction四部分组成,其结构如图1所示。输入端采用了Mosaic数据增强提升了小目标的检测效果,另外,采用自适应锚框计算的方法,不同的数据集都会有初始设定长宽的锚框,可以得到更大的交并比,提高大大提高了训练和预测的效率;Backbone部分为在不同图像细粒度上聚合并形成图像特征的卷积神经网络,主要有Focus结构和CSP结构。Neck部分是在Backbone和Prediction之间,是一系列混合和组合图像特征的网络层,将图像特征传递到Prediction部分。Prediction部分为最终检测部分,主要对图像特征进行预测,并生成边界框、预测目标种类。其采用了GIoU_loss(Generalized Intersection over Union)计算预测框(predicted bounding box)回归损失函数均值,Box值越小,预测框回归越准确; 采用了BCE Logits_loss计算目标检测损失函数均值,objectness值越小,目标检测越准确;采用二元交叉熵损失函数BCE_loss计算目标分类损失函数均值,classification值越小,目标分类越准确。以上3种损失函数公式分别如式(3)—式(5)所示:

(3)
其中,为2个框的最小闭包区域面积,为∪。
_=-,[,·log(,)+
(1-,)·log(1-(,))]
(4)
其中,为类别数目,为样本总数,是类目标的正例权重。
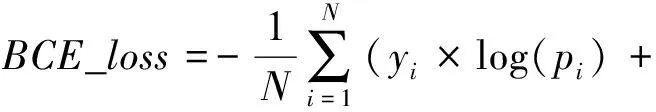
(1-)×log(1-))
(5)
其中,为样本总数,是第个样本的所属类别,是第个样本的预测概率值。
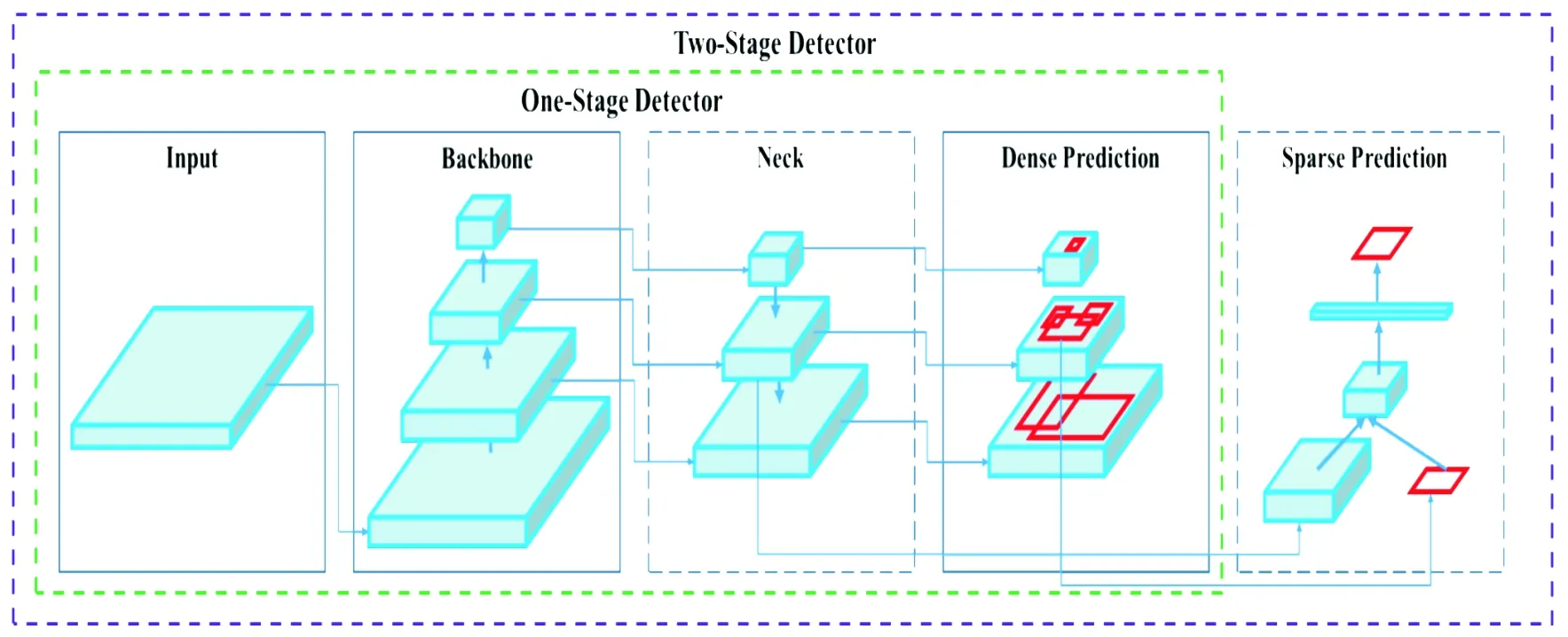
图1 YOLOv5神经网络结构图
3 探测实验
3.1 数据集的准备
目前,基于深度学习的微小型无人机探测方面研究较少,互联网上没有标准的数据集可供使用,因此需要自行采集数据构建所需数据集。
1) 数据采集。在不同天气、时间和背景对3款大疆无人机进行拍摄,其型号分别为Inspire2(尺寸为645 mm×650 mm×313 mm)、Mavic Air2(尺寸为183 mm×253 mm×77 mm)、Phantom4 pro(尺寸为330 mm×225 mm×405 mm),整理后得单台Inspire2图片60张、单台Mavic Air2图片64张、单台Phantom4 pro图片62张,2台及以上无人机图片24张。
2) 数据标注。YOLOv5模型训练前需对数据集进行标注,选用LabelImg标注软件对图片中的无人机进行人工逐一标注,完整框选出无人机边界并标注名称,如图2(a)所示。每一张图片标注完之后,将会自动生成一个相应的注释文档,包含物体名称编号,边界框的位置和大小等信息,如图2(b)所示。
3) 数据集构建。将图片和对应的标注文件上传到机器学习网站roboflow.com进行格式化,调整像素为640 px,并按照7∶2∶1的比例分别设置训练集、验证集和测试集。

图2 数据标注过程图
3.2 网络训练
网络训练是在专用深度学习服务器平台上进行的,平台的硬件配置和开发环境需求如表1所示。
实验过程为对微小型无人机数据集进行迁移学习训练,训练使用YOLOv5s的轻量化预训练模型yolo v5s.pt(通过COCO val2017数据库训练得到的轻量化检测模型)作为知识源进行迁移学习,修改目标种类参数nc(number of classes)为3,数据集配置文件data.yaml中设置好数据集路径,输入图像尺寸为640px,前向传播批处理大小设置为64,迭代次数设置为600。经过训练,得到基于微小型无人机数据集的目标检测模型,该模型可用于检测视频中每一帧图像中的无人机,并预测无人机的边界框、型号及相应的置信度。
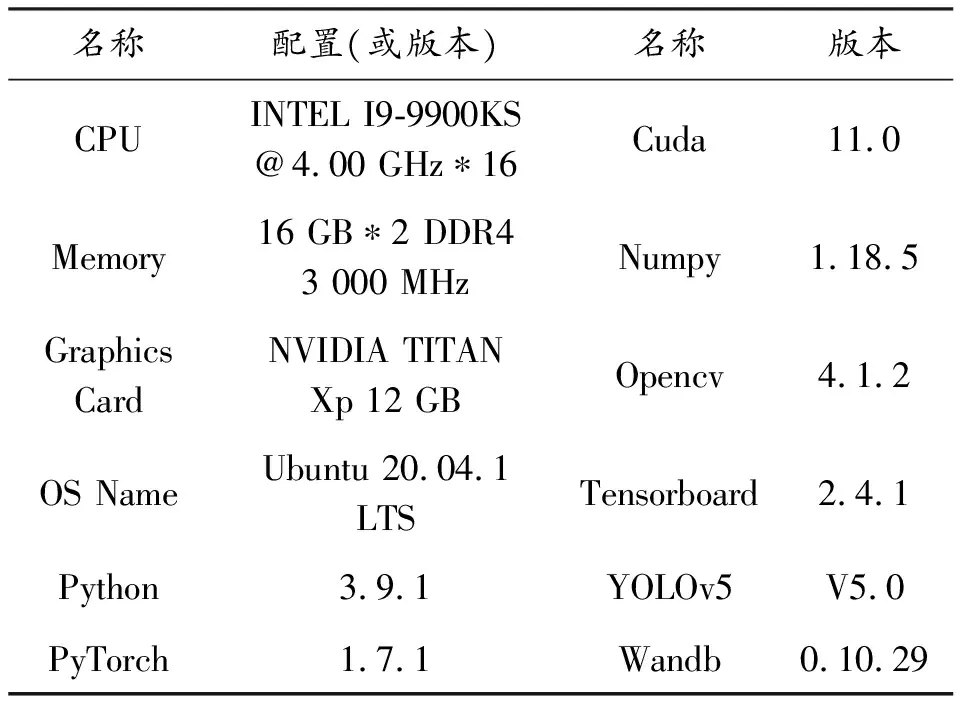
表1 硬件配置和开发环境需求表
使用Tensorboard可视化工具查看模型训练结果。图3(a)、(b)、(c)分别为训练过程中预测框回归损失函数均值、目标检测损失函数均值、分类损失函数均值随迭代次数的变化情况。可以看出,3种损失函数均值随迭代次数的增加快速下降,训练后期迭代到500次左右趋于稳定,最后趋于收敛。图4表示训练过程中精确率、召回率随迭代次数的变化情况,随着迭代次数增加,精确率和召回率快速上升后趋向于稳定。图5为当交并比阈值分别为0.5和0.5:0.95时平均精度均值(mean average precision,mAP)在逐步提升并趋于稳定。
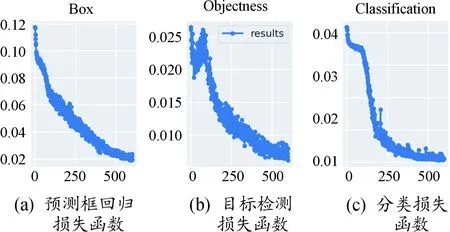
图3 3种损失函数随训练迭代次数变化图
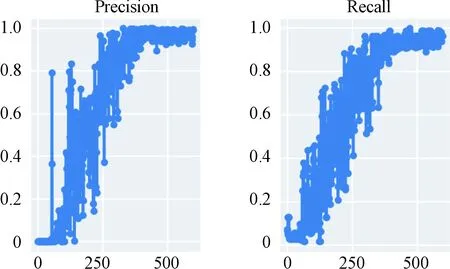
图4 精确率和召回率随训练迭代次数变化图
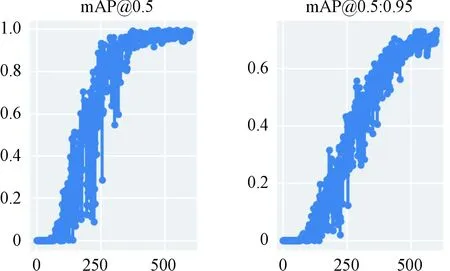
图5 阈值分别为0.5和0.5∶0.95时mAP随训练迭代次数变化图
图6为目标识别类别混淆矩阵元素图,图7为=0.5时的Precision-Recall曲线。
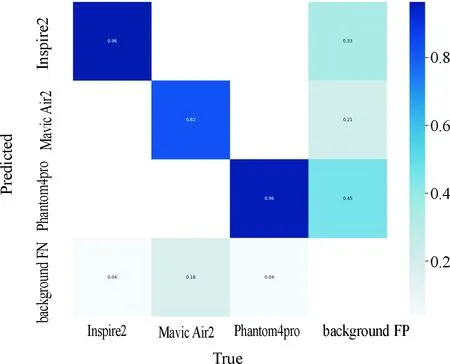
图6 类别分布混淆矩阵元素图
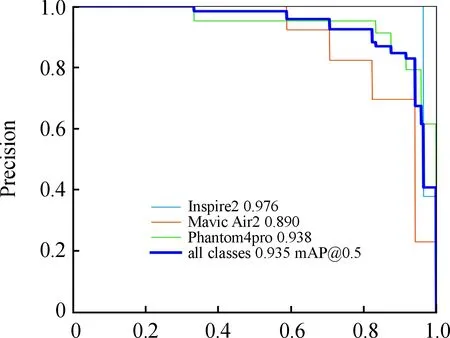
图7 Precision-Recall曲线
3.3 模型测试
网络训练结束后,把测试集中的图片输入训练好的网络模型进行识别目标的位置回归。只有同时满足≥0.5,无人机的种类识别正确这2个条件时,判定检测识别正确;否则为错误。选取精确率(Precision)、召回率(Recall)、平均精度均值作为评价指标,精确率表示在所有被检测为正的样本中实际为正样本的概率,其公式如(4)所示;召回率表示在实际为正的样本中被检测为正样本的概率,其公式如(5)所示;平均精度均值表示在所有检测类别上的平均精度的均值,比精确率和召回率更能反应模型的全局性能,其公式如(6)所示。(Ture Positive)为正样本被正确检测为正样本,(False Positive)为负样本被错误检测为正样本,(False Negative)为负样本被错误检测为正样本,为验证集个数。
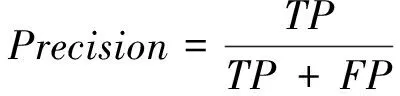
(4)
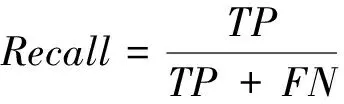
(5)
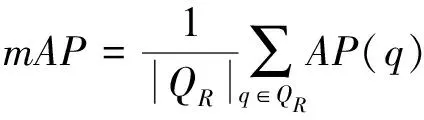
(6)
4 实验结果与分析
4.1 数据集测试结果分析
用测试集21张图片对训练模型进行测试,结果如表2所示,当交并比值为0.5时,训练得到的模型能够达到94.2%的精确率和82.8%的召回率,3种无人机识别的精度分别为:Inspire2为95.4%,Mavic Air2为92.1%,Phantom4 pro为95.2%,达到了较高的识别精度结果。测试集中部分检测结果如图8所示,在多种背景下均能够正确的检测出目标无人机,并准确识别出其型号类别。
在相同的服务器平台上,使用相同的数据集对YOLOv3和YOLOv5两种算法进行对比测试,结果如表3所示,使用YOLOv5模型进行测试时,达到93.5%,识别速度能达到141 FPS,精确率达到94.3%,YOLOv3模型的为81.5%,识别速度为59 FPS,精确率为83.2%。本实验的测试结果整体上也优于文献[10-11]采用YOLOv3算法的测试结果,更优于文献[9]采用的改进的SSD算法。
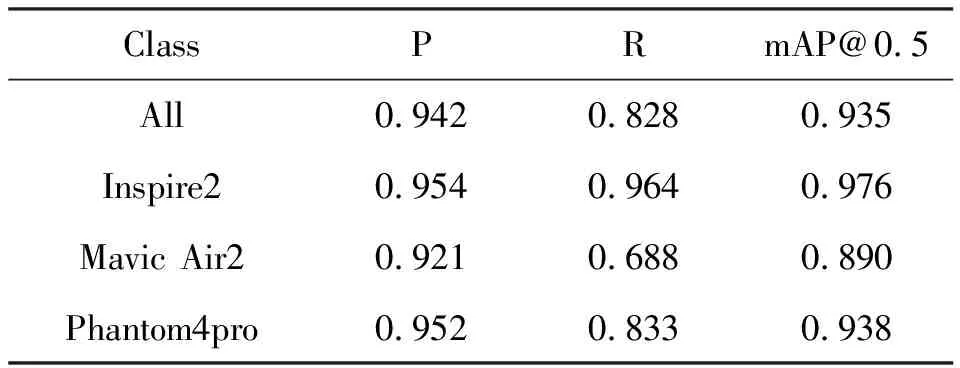
表2 YOLOv5模型的精确率、召回率和平均精度
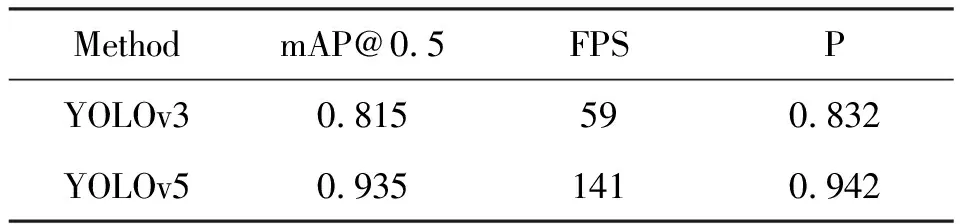
表3 2种模型的性能

图8 测试集中部分检测结果图
4.2 真实场景探测
为进一步验证基于YOLOv5对无人机的实时探测能力,本实验通过拍摄一段无人机视频,使用训练得到的模型对其进行探测。该视频中同时存在最多3种无人机的画面,视频分辨率为1 920*1 080,帧速率30 FPS。识别结果如图9所示,当较大无人机Inspire2在约45 m范围内,较小无人机Mavic Air2在约30 m范围内,该模型基本能检测出视频中的无人机目标,型号识别准确,同时置信度较高。每一帧图像的识别时间约为0.007 s,识别速率远大于源视频帧速率,具有较好的实时性。通过本文的实验可以验证YOLOv5算法在无人机实时探测应用上的技术优势。

图9 真实场景检测结果图
5 结论
使用迁移学习训练完的YOLOv5模型在测试集上能够达到94.2%的精确率、82.8%的召回率和93.5%的平均精度,此模型不仅能识别到微小型无人机,还能识别其具体型号,并标注其置信度。
在真实场景下,该方法能对光学监控设备的视频流进行实时探测识别,在配备NVIDIA GTX TITAN Xp 12 GB显卡的计算机上能达到142 FPS的速度,获得较为流畅的识别效果。
虽然本文提出的方法性能较好,但对于距离较远的微小型无人机,识别效果不佳。因为YOLO模型会对图片压缩处理,即当画面中无人机目标较远(或尺寸较小)时,压缩后无人机像素过小,无法提取有效特征,故难以识别。下一步考虑用增加尺度、网络检测分支等方式对YOLOv5算法进行修改,或者采取滑窗裁剪的方式增强小目标的探测能力。
