面向导游词的景区地理实体显著性排序方法
2022-06-02吴越,张翎,2*,龙毅,2
吴 越,张 翎,2*,龙 毅,2
(1.南京师范大学地理科学学院/虚拟地理环境教育部重点实验室,江苏 南京 210023;2.江苏省地理信息资源开发与利用协同创新中心,江苏 南京 210023)
0 引言
自然语言利用文字组合表述地理实体、要素及其相互联系[1],随着大数据时代的到来,基于自然语言的地理信息技术研究的重心逐渐从地理实体、位置等空间信息的提取[2,3]转向地理空间特征、语义特征的挖掘[4-6],而地理实体的重要性评价(即显著性排序)正是面向自然语言层次化空间认知研究[7]的重要内容之一。景区导游词是对特定景区的环境、景点与重要资源(自然与人文资源)进行系统描述的自然语言形式,除统计及信息特征[8-11],导游词还包含大量实体相关的地理空间特征。因此,从景区导游词出发,探讨景区地理实体的显著性程度及其排序,有助于进一步了解景区的资源分布、合理布局游览线路和实现层次化空间认知。
目前,实体排序方法相关研究主要关注两个问题:1)如何精确选择和提取相关实体特征。对于非结构化和半结构化文本地理空间特征的提取,核心在于如何从自然语言中有效识别地理实体并提取其空间关系,但多数研究[12-15]集中于建立提取框架及特征表示,用于区分显著性的地理实体特征,缺乏适用于实体排序的量化表达。2)如何建立合适的模型融合上述特征,并提升模型性能。通过关键词提取实体(词项)特征并训练相应的学习排序模型是常见的实体排序方法。例如:Mihalcea等考虑词项间的共现关系,基于Google的PageRank[16]提出对主题敏感的改进排序模型TextRank[17],Liu等通过衡量不同主题下词项重要性,提出基于词图主题的PageRank算法[18],两者着重分析了实体间特征、实体与文本主题的联系,但导游词中地理实体间特征不仅体现在文本的统计情况上,更突出表现在地理场景空间位置与结构的关系中。同时,传统实体排序方法[19-21]忽视了地理空间信息在地理实体显著性排序中的重要作用,导致特征提取缺乏针对性,丢失了排序模型的关键信息;且基于结构化知识库训练得到的模型通常无法处理非结构化或半结构化的地理空间特征,导致模型训练过拟合,泛化性能下降。
综上,地理实体显著性排序问题的难点在于如何通过学习器提升不同地理实体间的可区分性,而针对文本中非结构化或半结构化地理空间特征,很难获得预测精度较高的强学习算法[22]。Boosting方法通过集成排序性能高于随机预测的弱学习器,可生成更精确的集成排序模型[23],然后利用集成学习即可实现弱学习算法和强学习算法的转换[24]。鉴于此,本文将Boosting方法引入景区地理实体的显著性排序,研究兼顾文本信息与地理空间信息的实体特征提取方法,构建相应的弱学习器,并结合具体排序目标选取合适的损失函数,进而通过结合(combining)与剪枝(pruning)进行集成优化,以期实现面向导游词的地理实体显著性排序模型构建,最后以中文导游词文本为案例,对模型的可靠性和有效性进行实验与分析。
1 基于Boosting的景区地理实体显著性排序模型
面向导游词的地理实体显著性排序是将导游词中相对显著的景区地理实体尽可能排在边缘实体之前的过程,主要包含文本预处理、实体特征提取和排序模型构建3个部分(图1)。

图1 景区地理实体显著性排序方法流程Fig.1 Flowchart of geographic entity significance ranking for scenic spots
1.1 文本预处理
基于现有地理命名实体标注语料库及相关匹配规则,通过人工校正辅助提取景区地理实体,并将实体划分为显著程度较高的正例实体和显著程度较低的负例实体进行标注。
1.2 实体特征提取
在导游词文本中,景区地理实体通常以表示景点或重要资源的地名词项出现。在数量上,通常显著程度较高的地理实体(如参照物、核心景点等)在导游词中多次出现;在分布上,地名词项的集聚现象越明显,用以描述的篇幅越长,地理实体与文本的相关性也越高[25],显著程度也较高;此外,有些地理实体数量不多且分布较分散,但与其他实体因人文、历史相关的语义联系出现在同一篇章、段落或句子中,且共现次数越多,显著程度越高。上述特征仅反映了实体作为词项的统计与结构特征,没有考虑地理实体在现实世界中的空间位置及其延伸关系。
实体顺序关系与导游词文本序列的描述顺序基本一致,可被共现关系捕捉,而导游词通常缺乏对空间距离的具体刻画,无法建立实体群关系及结构的精确度量。导游词中的地理实体同属于一个旅游景区,在空间分布上具有连续性,因而地理实体间具有明确的空间拓扑关系,导游词对空间拓扑关系的描述反映了地理实体对的结构层次,暗含了景区空间结构上的显著性差异;同时,不同人使用不同语言表达方式所造成的模糊性程度也不同[26],导游对旅游景区内地物的介绍各有侧重,因而地理实体显著性越高,导游对其描述越全面、具体。导游词对地理实体自身特点的描述可以看作文本驱动的形态描述,“形”刻画了景区地理实体的空间尺度,“态”展现了实体当前的状态或态势,因此,形态描述的模糊性程度可以体现地理实体在语言刻画层面的显著程度。
综上,本文选择出现频率、聚集系数、共现关系、空间拓扑关系和模糊形态描述五方面特征刻画导游词中景区地理实体的显著性(表1)。

表1 景区地理实体显著性特征Table 1 Features of geographic entity significance for scenic spots



图2 颐和园空间拓扑关系示意Fig.2 Spatial topological relations of the Summer Palace
(1)
式中:TS(ei﹤﹤)为当前结点ei的父结点的权重;Bcount(ei)为当前结点ei的兄弟结点数量。

表2 形状描述、颜色描述、尺寸描述和方向描述的模糊性程度划分及得分区间Table 2 Ambiguity levels and scores of shape description,size description,color description,and direction description
VS(ei)=S(ei)+M(ei)+C(ei)+D(ei)
(2)
式中:S(ei)、M(ei)、C(ei)、D(ei)分别为各类形态描述的模糊性程度得分。
在特征提取阶段,景区地理实体显著性排序不同于一般文本的关键词提取,需重点考虑导游词文本中蕴含的空间拓扑关系和形态描述,并选取合适的结构与量化函数进行特征表示,综合地理实体在文本序列中的统计与结构特征,形成特征矩阵X。以综合文本信息的实体特征矩阵作为输入,正负例结果作为输出,从而构建排序模型的弱学习器。
1.3 排序模型构建
景区地理实体显著性排序问题可定义如下:对于任意给定的导游词文本d,自动对地理实体集合E(d)中的地理实体进行显著性排序,使正例实体集合P中地理实体尽可能地排在负例实体集合N中地理实体的前面,即将复杂的排序问题看作简单的二分类问题。为将分类问题还原为排序问题,本文提出一种基于Boosting的景区地理实体显著性排序(Geographic Entity Significance Ranking,GESR)模型。GESR模型借鉴了Boosting方法中Adaboost算法[30]的思想,通过每次只训练一个弱学习器不断优化模型,不仅可以得到高性能的集成模型H(X),还降低了优化问题的复杂度;对于每轮迭代学习,只训练一个弱学习器,并根据样本权重分布调整样本中不同实例的训练强度,最终对弱学习器进行集成以获得更好性能。串行集成方法可以对学习器进行合法性检查,但耗时长、效果差,本文采用降误差剪枝(reduced-error pruning)[31]获取独立学习器的子集,使用更小规模可得到更好的集成结果。首先依次选取使该轮集成验证误差最小的弱学习器加入集成,然后通过回填(backfitting)寻找可以降低集成验证误差的弱学习器替换已有学习器,直到集成中所有弱学习器均不能被替换为止(图3)。对于每个弱学习器,利用Logistic函数融合表1中5个特征,构建线性加权形式的排序函数,将损失函数定义为ROC曲线线下面积(Area Under Curve,AUC)的形式,并使用Sigmoid函数代替AUC公式中的指示函数,然后采用随机梯度下降法(Stochastic Gradient Descent,SGD)最小化损失函数,以求解每一个弱学习器的最优参数。此外,同一导游词文本中的不同地理实体之间存在一定程度的语义关联,虽然样本的权重分布针对训练集中不同的导游词文本,但必须对同一导游词中的所有地理实体进行一轮独立的训练。

图3 降误差剪枝流程Fig.3 Flowchart of reduced-error pruning
本文中地理实体及其所属的导游词文本不可分割,因此将原有对样本采用的重加权方法(re-weighting)改为重采样方法(re-sampling),样本的权重分布将决定某一轮中部分样本被训练的可能性,困难样本的权值更高,在下一轮弱学习器的训练中更有可能被采样。本文中X为地理实体的特征矩阵,Y为地理实体的排序结果,且可以被分为正例实体集合与负例实体集合,具体实验过程见算法1。
算法1 GESR模型算法
输入:
标注导游词文档集合DL={dl1(X1,Y1),dl2,…,dlm(Xm,Ym)}
训练的迭代次数T,采样比例r,学习率lr
输出:
(1)D1(dl)=1/m% 初始化样本的权重分布
(2)fort=1,…,T:
(3)DLt=S(DL,r,Dt(dl)) % 重采样


(6)ifEt>0.5: % 筛选弱学习器
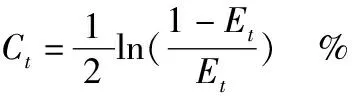


2 实验与分析
2.1 数据集
本文使用从互联网筛选的30篇中文导游词文本进行实验,包括颐和园、故宫、宝塔山等热门景区。考虑到不同景区类型、文本长度等因素对模型训练可能产生影响,数据集在筛选时主要从景区类型、文本长度和地理实体数量3个方面控制样本分布均衡:1)从资源景观的角度将样本划分为数量相近的两类,自然景观类样本包括黄山、九寨沟和玄武湖等景区,人文景观类样本包括夫子庙、颐和园和总统府等景区;2)不同长度的导游词文本对地理实体描述的粒度不一致,根据字数将样本划分为数量相近的两个区间,即500~1 000字的短文本和1 000~3 000 字的长文本;3)景区类型和文本长度相同的情况下,导游词文本中的景区地理实体数量相近。
由于根据得分对地理实体进行排序不利于验证排序模型的效果,无法反映单个地理实体在导游词文本中的显著性程度。本文参考Trani等[32]对实体的划分,根据地理实体在导游词文本中的显著程度,将地理实体划分为4个显著性等级(表3),并依据各等级的描述对数据集进行四分类标注,生成正例(等级为3、4)、负例(等级为1、2)的二分类标签。二分类数据适用于模型训练中损失函数构建,而四分类数据中明确的显著性程度划分有利于模型验证。

表3 地理实体显著性等级划分Table 3 Levels of significance of geographic entities
本文依据四分类和二分类的划分标准,对筛选后的30篇中文导游词文本进行人工标注,并将样本信息、序位、四分类和二分类标签按照一定的格式进行存储,图4为以颐和园导游词为例的数据集标注格式。

图4 数据集标注格式示意Fig.4 Schematic diagram of annotation format of dataset
2.2 排序模型评价指标
相比MRR(Mean Reciprocal Rank)等排序评价指标,AUC可以更精确、简便地计算出GESR模型对地理实体显著性排序的拟合优度值,AUC值越大,排序模型越有可能将正例样本置于负例样本前,即模型的有效性越好。本文使用AUC值和归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG)(式(3))[33]两个指标对模型排序结果进行评价。其中,AUC值可以直观展现模型对显著实体和边缘实体的区分度,NDCG则主要基于地理实体显著性程度和序位的正相关对排序效果进行综合评估。经过模型排序后,依据式(3)可以获得有序地理实体列表的折损累积增益DCG,并将人工标注的地理实体排序结果作为理想排序,计算得到IDCG。
(3)
式中:log2(1+i)为第i位地理实体按实际排序结果的位置折损;r(i)为实际情况下第i位地理实体的显著性等级;log2(1+j)为第j位地理实体按理想排序结果的位置折损;r(j)为理想情况下第j位地理实体的显著性等级。
2.3 特征消融实验
不同特征反映地理实体显著性的能力不同,本文分别移除表1各个特征,评价模型在缺少该特征情况下的性能(图5)。可以看出,缺少前3个统计与结构特征的情况下,模型性能表现平稳,缺少特征四、五时,NDCG和AUC值出现明显波动,模型性能皆存在明显下降,因此特征五(模糊形态描述特征)对于模型的影响最大,其次是特征四(空间拓扑关系特征),结果验证了地理空间特征在导游词地理实体显著性排序中的重要作用。

图5 不同特征对GESR模型的影响Fig.5 Influence of different features on the GESR model
2.4 敏感性分析
本文分别在训练过程中逐渐提高训练样本数量比例和集成中弱学习器数量,分析预测精度随两者的变化情况。如图6a所示,线性拟合的拟合优度较好,数据点围绕趋势线分布紧凑,预测精度与训练集数量比例呈显著正相关,说明GESR模型对数据量的增加十分敏感;由图6b可知,当学习器数量小于9时,随着学习器数量的增加,验证集的预测精度不断提高,而当学习器数量为10时,验证集的预测精度趋于平稳。因此,GESR模型在一定范围内对学习器数量较敏感,而后趋于平稳,且学习器的最佳数量约为9。

图6 训练集样本数量、学习器数量与验证集预测精度关系Fig.6 Relationships between number of training samples,number of learners and prediction accuracy of validation sets
2.5 基线对比分析
本文选取基于地理实体出现频率、聚集系数和实体共现关系的统计方法作为基线方法,与GESR模型进行性能对比(表4)。可以看出,基于实体共现关系统计方法的NDCG值相比另外两种基线方法更高,说明相比单独的实体频率统计,应用共现频率统计效果显著提升;GESR模型的AUC值最大,比基于实体共现关系的统计方法平均提升了14.6%,说明集成融合特征的弱学习器效果更好。

表4 GESR模型与其他基线方法的NDCG值和AUC值对比Table 4 Comparison of NDCG and AUC between the GESR model and other baseline methods
2.6 实例对比分析
游客在计划旅行时通常会利用互联网搜索并了解目的地的相关情况,知名度越高的景点客流量越大,关注度很大程度上反映了人群的偏向。2018年百度搜索在中国PC搜索各平台中流量份额最高[34],因此,本文选取网络获取的“颐和园”导游词,采用2011年1月1日至2020年1月1日的日均搜索量反映人群关注度,分析模型排序结果与人群关注度之间的差异性(表5)。从显著性排序趋势看,两个排序结果中的序位差相对较小,同一序位地理实体的显著性等级基本相同,排序结果的相似度较高,但排序模型中结构层次较高的地理实体(如昆明湖、万寿山)关注度排名有较大下滑,而一些结构层次较低的地理实体(如十七孔桥、铜牛)关注度有很大提升。结构层次的高低取决于现实世界中客观的空间拓扑关系,而人群关注度受到游客偏好、景区宣传和景点观赏性等多方面主观因素影响,例如,昆明湖在颐和园中属于大面积景观,近在眼前却容易被忽视,而铜牛、十七孔桥作为旅游网站的对外宣传景点易受大众关注。因此,人群的关注度很难反映地理实体的空间特征,更多体现了社会人文方面的受关注程度。对于描述特定地理场景的导游词文本,其地理空间方面特征的研究是不可或缺的,直接影响着景区场景的构建与还原,本文提出的模型正是在尝试弥补这种不足。

表5 关注度与GESR模型排序结果对比Table 5 Comparison of popular attention and results of the GESR model
3 结论
本文提出一种面向导游词的基于Boosting的景区地理实体显著性排序(GESR)模型,综合景区地理实体特有的地理空间特征构建目标排序函数,基于样本误差分布与随机梯度下降法迭代生成弱学习器,并通过加权平均法和降误差剪枝集成获得用于排序的强学习器。以30篇不同主题的导游词为样本进行模型的验证与分析,结论如下:1)与3种基线方法相比,GESR模型的NDCG达0.8841,AUC值达0.7579,排序性能明显优于基线方法;2)通过分别移除各特征,验证了地理空间特征在GESR模型中的重要作用;3)数据量与学习器数量的敏感性分析表明,训练数据量与模型性能呈现正相关,学习器的最佳数量约为9个;4)通过与搜索关注度进行实例对比分析,发现关注度缺乏对客观空间结构的表达作用,验证了本文方法对地理空间特征的反映能力。
尽管本文模型及实验取得了一定效果,但除拓扑关系外,空间关系包含的方位关系和距离关系仍存在可以深入挖掘的内容;此外,尽管地理实体的语义特征很难描述,但不容忽视,未来需要引入更多类似的空间特征与语义特征进行研究。
