瑞雷波频散曲线的深度学习反演方法
2022-06-02张志厚石泽玉马宁王虎乔中坤赵思为姚禹赵明浩叶志虎
张志厚, 石泽玉, 马宁*, 王虎, 乔中坤, 赵思为,姚禹, 赵明浩, 叶志虎
1 西南交通大学地球科学与环境工程学院, 成都 611756 2 西南交通大学,高速铁路线路工程教育部重点实验室, 成都 610031 3 浙江工业大学理学院,浙江省量子精密测量重点实验室, 杭州 310023 4 中铁二院成都地勘岩土工程有限责任公司, 成都 610000
0 引言
瑞雷波是纵横波在地面相互干涉形成并沿地表传播的一种地震面波,其具有能量强、衰减慢、信噪比高等优势,被广泛用于浅地表及中深部速度结构的调查(Miller et al., 1999; Du et al., 2019; Tang et al., 2019; Berg et al., 2020; Wang et al., 2021)等.诸多学者分别从瑞雷波场模拟(Xu et al., 2007; Zeng et al., 2011; 胡书凡等, 2021)、频散曲线提取(Hu et al., 2020; Xi et al., 2021; Dai et al., 2021; 易佳等, 2021)、频散曲线反演(Xia et al., 1999; 陈祥和孙进忠, 2006; Lu et al., 2007; Picozzi and Albarello, 2007; 于东凯等, 2018; Mi and Xia,2021; Poormirzaee and Fister, 2021)以及波形反演(Pan et al., 2019; Zhang and Alkhalifah, 2019)等方面进行研究,使得瑞雷波研究与应用得到了极大的发展.频散曲线反演是瑞雷波勘探的重要环节之一(Lu et al., 2007),也是获取近地表横波速度的关键步骤(Xia et al., 1999; 夏江海等, 2015).然而,同其他大多数地球物理反演优化问题类似,频散曲线反演具有高度的非线性、多参数及多极值等特点(于东凯等, 2018),一般线性反演方法效果取决于初始模型的选择和偏导数矩阵计算的准确性;非线性全局最优化算法如粒子群(Song et al., 2012; Poormirzaee,2016)、遗传(Picozzi and Albarello, 2007)、模拟退火(Pei et al., 2007; Lu et al., 2016)、布谷鸟搜索(Poormirzaee and Fister, 2021)以及多种全局优化方法改进或结合算法(Sun et al., 2017; Lei et al., 2019)等存在收敛速度慢、精度低等问题(于东凯等, 2018).
深度学习(Deep Learning, DL)是利用各类型的深层次神经网络模型来模拟人脑结构,该过程是信息的分布式存储和并行协同处理一个非线性系统的过程,尽管每个神经元或网络层的结构和功能非常简单,但其组合时却能完成复杂的非线性映射.深度学习在过去10年间为数据科学领域带来了一场革命,如在图像分割(Krizhevsky et al., 2012)、目标检测(Ren et al., 2017)、语音识别(Hinton et al., 2012)、机器翻译(Sutskever et al., 2014)、情感分类(Zhao et al., 2019)以及围棋游戏(Silver et al., 2016)等取得了突破性进展,使许多之前被认为无法实现的任务成为了可能(Bronstein et al., 2021).由于DL输入到输出的复杂映射关系难以明确解构,因此其属于典型“黑盒”方法.相比统计学上大量使用的“数据模型”,DL网络架构聚焦于寻找一种预测的算法,因此被称为“算法模型”(Diaconis and Mosteller, 1989),或称为一种“网络结构映射”,其本质是一个函数估计问题:在训练集上给定某些未知函数的输出,试图从某些假设函数类别中找到一个函数F,该函数可以很好地拟合训练数据,并可以预测出先前未见过的输入对应的输出(Bronstein et al., 2021).并且根据万能近似定理(Hornik et al., 1989),DL可以以理想的精度近似任意复杂非线性映射函数(LeCun et al., 2015),有助于解决地球物理正反演问题(Jin et al., 2017),以及DL与地球物理反演方法都具有类似的优化算法(Kim and Nakata, 2018).DL的显著优势也促使了诸多学者将其引入到地球物理领域中,无论是对原始数据进行预处理(Wang et al., 2019; Xu et al., 2020; 俞若水等, 2020; Dai et al., 2021; Guo, 2021;诸峰等,2022),还是对勘探成果的自动化解译(Wu et al., 2019; Xiong et al., 2018; Shi et al., 2019; 何易龙等,2022;张志厚等,2022),以及在地球物理“端到端”的反演中(Puzyrev, 2019; Liu et al., 2020; Li et al., 2020a,b; 张志厚等, 2021a,b)等都取得了较好效果.
DL除去利用已训练好的网络模型进行反演预测本身之外,其主要包括样本数据集的构建和网络结构的设计两大重要内容.
在数据集构建方面:DL样本数据主要来源于真实数据和人工合成数据.相关学者探索了基于精细化标注真实数据训练的语义分割模型(Bai et al., 2018),然而真实样本数据标注耗时、昂贵,且对人为错误敏感,并不能满足地球物理反演的需求;人工合成方法可以获取大量的样本数据,足量代表性数据可极大提高训练模型的泛化性能,如在DL的重磁反演(张志厚等, 2021a,b)、电磁反演(Puzyrev, 2019; Li et al., 2020b)、直流电阻率反演(Liu et al., 2020)、地震反演(Li et al., 2020a)中取得了较理想的成果,但以上内容缺乏样本数据集构建方法的系统性分析.
在网络结构精心设计方面:近10年来,以ImageNet为代表的大型、高质量数据集和不增长的计算资源(GPU)使我们能够设计各种被用于此类大型数据集的网络结构(Bronstein et al., 2021),如卷积神经网络(Convolutional Neural Networks,CNN)(Krizhevsky et al., 2012)、深度信念网络(Deep Belief Networks, DBN)(Hinton et al., 2006)、对抗神经网络(Generative Adversarial Nets, GAN)(Goodfellow et al., 2014)、长短时记忆网络(Long Short-term Memory Nets, LSTM)(Hochreiter and Schmidhuber, 1997)等.虽然很难理解以上每种网络结构之间存在的关系,但有学者提出了几何深度学习的概念(Bronstein et al., 2017),从而尝试将以上网络进行统一,并利用对称先验和尺度分离原理推导出当下较为典型的网络架构,如由平移对称推导出了CNN,由置换不变性导出的图神经网络(Graph Neural Networks, GNN)、DeepSets和Transformer网络,由时间扭曲不变形导出的LSTM,以及由规范对称性导出的计算机图形和视觉中使用的Intrinsic Mesh CNN等.瑞雷波不同频率相速度反映不同深度的横波速度,表明其具有一定的空间对应性,频散数据本质也是一种时间序列的变换,说明了瑞雷波频散数据同时具备空间对应性和时间序列性.而CNN可以通过卷积算子提取频散曲线的空间特征,LSTM用于频散序列数据的预测,且LSTM在处理梯度爆炸与消失问题方面相比其他网络结构具有更好的优势(Kong et al., 2019).
基于此,本文首先针对DL所依赖的样本数据集的足量多样属性,展开了浅地表速度结构所具备遍历性和有序性的讨论与分析,并由此提出了约束马尔科夫决策的样本数据构建方法;其次,基于不同网络结构的各自优势,针对瑞雷波频散曲线具备的空间性和序列性,提出了一种CNN衔接LSTM的DL网络结构(CNN-LSTM)用于瑞雷波频散曲线反演;最后,对本文所提方法进行理论数据和实测数据的检验,以此来证实文中方法的可行性、有效性和适用性.
1 反演样本数据集构建
近地表速度结构数据和速度结构一一对应的频散曲线数据组成了样本数据对.训练样本数据的多样性和足量性与DL方法所具备的泛化性能密切相关,其决定方法的实用性,然而采用单纯的遍历方法所构建的近地表速度结构模型一是计算成本高,二是不具有真实地下速度结构的典型性,三是造成部分大量样本数据的价值密度低,四是无法通过朴素的方式进行学习.因此,近地表速度结构模型的科学构建显现的尤为重要.
1.1 近地表速度结构遍历假说
“世上没有两片完全相同的树叶”,看似简单的自然现象,竟然可以引起人们对宇宙万物的深思.46亿年地球演化过程从没有简单的重复,物种的多样性,自然的多元性,都在随时随地证明自然系统的各态遍历属性,使得遍历假说也许是打开非线性科学的一把钥匙(杨文采, 2008).毫无疑问,近地表地层速度结构作为地球演化的表层系统也具有其内在遍历性.伴随着地球的演化过程,近地表速度结构的演化轨道也将力图遍历其相空间各种可能的体制和状态.
各态遍历假说阐述了一个“时间平均”与“空间平均”的等价关系,即在一个充分大空间内,同一区域不同时间上的各个可能状态遍历了同一时间不同区域的所有可能状态,反之亦然(Zhan, 1999).那么通过地球演化视角来看,同一区域近地表地层速度结构最终覆盖其全部的相空间,可以通过同一时间不同区域的速度结构状态来替代.因此,可以利用不同区域的速度结构来组成深度学习所需的样本数据集,遍历速度结构可用式(1)表达:
vk=random(vmin,vmax),k=1,2,3,…,n,
(1)
式中,vk表示第k层的速度,n表示一维层数,random为随机采样函数,vmin与vmax为随机采样空间的界限.
1.2 速度结构演化特征的有序性
自然系统在演化中还有力图保持自身特征形态的惯性(杨文采, 2008),使其随时空变化有序.如向日葵、松果籽、凤梨呈现出的斐波那契数列;斑马的皮毛、蝴蝶的纹理以及花朵的形状展现出规则的图案,都在随时随地验证自然的有序性.自然过程的惯性也是大自然的最佳选择,如河流演变是在流域内既定的地形、植被与地质等条件下,历经千万年的时空随机降水,通过地上地下的汇聚而形成的,其流动能耗最低.绵延的群山,地层的形变,岩石的自然裂缝,同一区域不同时间的近地表速度结构等也可以认为是大自然的惯性使然.对于近地表的层状速度结构,其惯性特点为速度随深度的增加而增大(图1e),这是由于地层随着深度的增加,其自重应力也随着增加,在力的作用下,其速度也将发生变化,可以用式(2)表述:
vk+1=vk+Δvk+1∝γkρkghk,
(2)
式中ρk、hk分别为第k层的密度与层厚,g为重力加速度,γk为大于零的系数.而不会出现随深度增加而减少(图1b).即便是针对不同岩性的情况也很少出现图1a所示的震荡速度结构,但极有可能出现图1c、d所示的速度结构,并且类似于图1e、f所示的速度结构较为普遍.
1.3 约束马尔科夫决策的速度模型
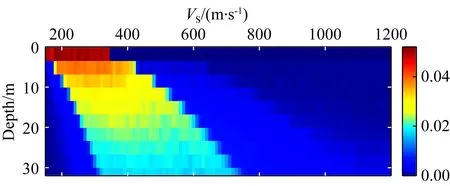
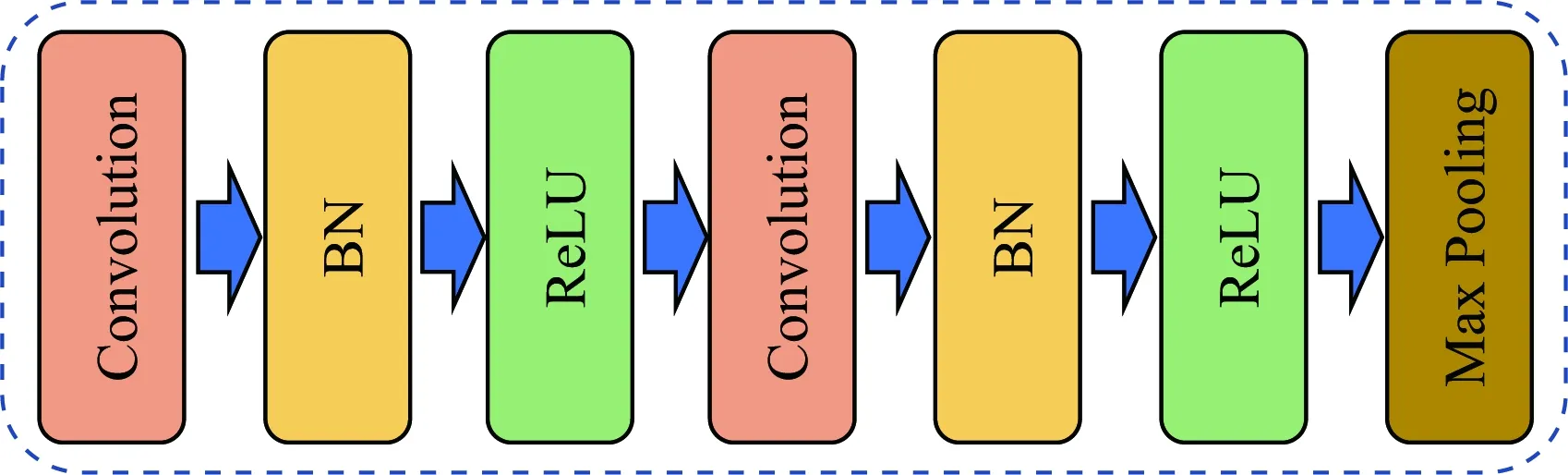
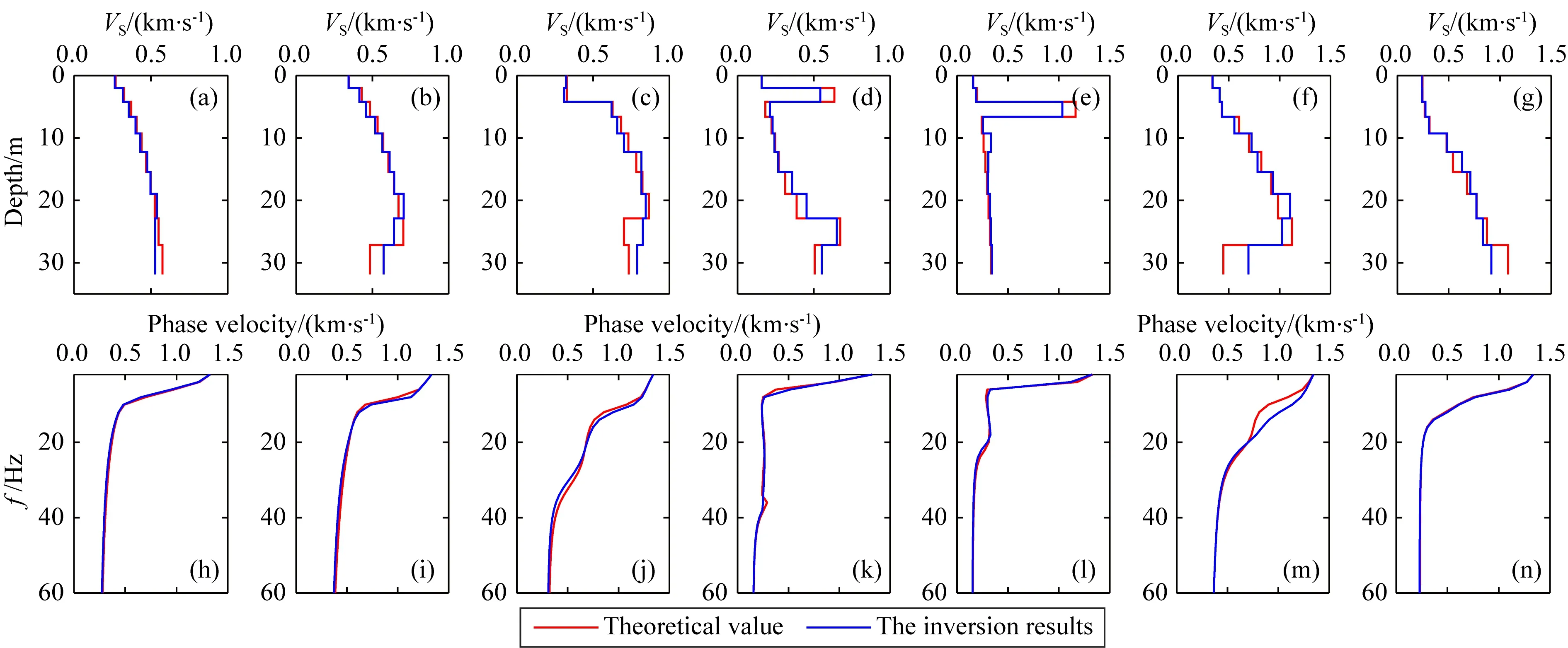
基于近地表速度结构的遍历性与有序性,文中将马尔科夫链引入到速度建模中.为了便于表述,将各层状模型速度随深度由浅到深的变化看成时间谱序列,每一层对应一个时间,每一层的速度对应该时间的状态.速度结构由浅到深建模过程视为一个随机过程{v(t),t∈T},其对随深度层增加的有限时序t1 P{v(tn)=vn|v(tn-1),…,v(t1)} =P{v(tn)=vn|v(tn-1)}. (3) 这种随深度增加而变化的速度结构特性称为速度层的马尔科夫过程无后效应,具有该性质的v(t)称为马尔科夫过程.{v(t),t∈T}为马尔科夫链(Markov Chain, MC),它表明当前地层的速度状态仅依赖于上一层速度,且下一层速度仅依赖于当前层的速度. 在条件概率P{v(tn)=j|v(tn-1)=i}中,v(tn)=j表示在tn时刻过程处于状态j,故条件概率P{v(tn)=j|v(tn-1)=i}表示过程在时刻tn-1处于状态i条件下,时刻tn过程变化到状态j的概率(Ching and Ng, 2006).它相当于随机移动质点在时刻tn-1的状态为i,经过一步随机移动变化到状态为j的概率,并记该条件下的概率为Pi,j: Pi,j=P{v(tn)=j|v(tn-1)=i}, (4) 图1 速度结构模型示意图Fig.1 Schematic diagram of the velocity structure model (5) 称为此过程的一步转移概率矩阵. 由于浅地表速度结构普遍具有底层速度大于上层速度(图1e、f所示)的特征,即下一层速度大于当前层速度为大概率事件.刘红帅等(2010)统计了不同地区8769个点的土层剪切波速度,结果表明随着深度增加,剪切波速呈近线性增大的关系.因此,本文速度结构建模的MC如图2所示,下层波速大于当前层波速并呈一定近线性增大为大概率事件,相比当前层波速下层波速显著增大以及减小或缓增为小概率事件. 图2 速度结构建模的马尔科夫链示意图Fig.2 Schematic diagram of Markov Chain for velocity 下面给出约束马尔科夫决策速度模型构建的基本步骤: 步骤1:本文将待正反演地层划分为10层,并令第一层的厚度h1=2 m,随后各层的厚度随深度的增加而递增,表达式为: hk+1=1.10×hk,k=1,2,3,…,9, (6) 步骤3:在约束速度范围内随机选择首层横波波速: (7) 方案一: 约束范围内随机选择第k+1层横波波速与第k层横波波速的近线性增加比: (8) (9) 方案二: 约束范围内随机选第k+1层的横波波速: (10) 其中,min(a,b)为取a和b的最小值函数. 方案三: 约束范围内随机选第k+1层的横波波速: (11) 其中,max(a,b)为取a和b的最大值函数. 步骤5:根据文献(Tang et al., 2020)计算各层近似纵波波速: (12) 并依据文献(Ikeda et al., 2017)计算各层的密度: (13) 其中,k=1,2,3,…,10,half. 速度模型频散曲线正演计算方法的选择是人工合成高效、准确性样本数据集的主要内容,其最终决定了DL反演方法的实用性.瑞雷波频散曲线的正演方法有Thomson-Haskell法(Haskell,1953)、δ矩阵法(Pestel and Leckie, 1963)、Schwab-Knopoff 法(Schwab and Knopoff, 1972)以及快速矢量传递法(凡友华等,2002)等.Thomson-Haskell法在高频段会出现数值溢出等问题;Schwab和Knopoff(1972)采用行列变换使频散函数公式更为简洁,获得了瑞雷波频散曲线快速正演算法;快速矢量传递算法(凡友华等,2002)解决了高频数值精度丢失等问题.Dunkin(1965)将系数传递矩阵方法应用于瑞雷波频散方程的推算过程,并克服了数值精度缺失等问题,且该算法在高频段计算稳定.考虑本文研究的正演频散曲线用于浅表层速度结构的反演,对应频散曲线的高频相速度,因此文中采用Dunkin(1965)方法计算瑞雷波频散曲线. 本文将速度模型和其对应的频散曲线组成样本数据对,通过约束MC构建大量的速度模型,从而获得本文监督学习所需的样本数据集,其中,τ等于0.8和0.9时分别创建了4万和10万个样本数据,总共包含14万个样本数据对.随机抽样了12组样本数据如图3所示,可以看出速度模型中包含速度层的正常递增、突然变大、突然变小、某一层变大或变小的情况.表明通过本文提出的约束MC决策过程可以构建具有一定代表性的样本数据集. 图3 抽样样本数据对(a) 横波速度模型; (b) 频散曲线.Fig.3 Randomly selected sampling data(a) Transversal wave velocity model; (b) Dispersion curve. 图4 速度概率密度图Fig.4 Velocity probability density map 图4为统计了14万个样本数据中各层速度区段(速度区段范围为10 m·s-1)的分布概率,可以发现:(1)概率密度较大的速度段整体呈现一带状分布区,整体上横波速度随深度的增加而近线性增大,说明这种情况下的速度结构占主体优势,符合速度结构自然“惯性”特点;(2)存在速度突然变大及突然变小的情况,其速度分布分别位于两个“浅蓝色”的带状区,符合近地表速度层的突变特点;(3)首层速度为一约束范围的随机取值,不存在突变情况.并且在约束范围内速度分布较为均一,说明利用“掷骰子”方法可以有效选取约束范围具有遍历属性的速度.综上所述,表明约束MC的样本数据集构建方法具有一定的有效性. 本文提出了一种名为CNN-LSTM的网络结构用于瑞雷波频散曲线的反演,其流程图如图5所示,该网络包含了输入(Input)、编码(Encoder)、解码(Decoder)及输出(Output)4个部分,其中编码部分包含了3个局部特征学习模块(Local Feature Learning Block, LFLB)和1个LSTM模块,解码部分是1个全连接层.该网络旨在从频散曲线中学习深层次特征,因此,每个LFLB模块的卷积层和池化层都是一维的.随着网络深度的增加,卷积核通道数分别为64、128、256;该网络结构的顶层为softmax分类器,用于近地表速度结构的分类. 图5 一维CNN-LSTM网络总体架构图LFLB为编码部分的局部特征学习模块,LSTM为编码阶段的全局学习模块,64、128和256表示卷积通道数;Dispersion Curves为频散曲线;Fully Connection为全连接;Shear Wave Velocity为剪切波速.Fig.5 One-dimensional CNN-LSTM network structureLFLB is the local feature learning module of the coding part, LSTM is the global feature learning module of the coding part, The number of convolution channels is 64, 128 and 256. 当一维向量表示的频散曲线输入到网络时,LFLB可以学习到局部特征.这些特征重构后,从最后一个LFLB模块输出再输入到LSTM层中,然后从这些输入的局部层次特征中学习全局信息的相关性.因此LSTM的输出包含了局部特征信息和全局信息的相关性.进而再将学习到的特征传递到全连接层,最后再输入到分类器中. 用LFLB来学习频散曲线的局部特征,每个LFLB模块包含了两个CNN层,两个批处理归一化层(Batch Normalization, BN),两个线性激活函数层(ReLU),一个最大池化层(Max Pooling),如图6所示.LFLB的核心是卷积和池化,其中卷积算子具有权值共享性和局部空间连通性(Shi et al., 2019),重点学习频散曲线与速度结构之间的非线性关系.BN层对每批卷积层激活结果进行归一化处理,可提高深层次网络的优良性和鲁棒性.池化层不仅可以抑制噪声提高模型的鲁棒性,同时还可以对数据进行降维,进一步提高计算速度.最大池化是常用的非线性函数,可将输入特征划分为不重叠区域,提取每一子区域的最大特征(Ciregan et al., 2012).ReLU进行非线性关系的激活,其主要优势是稀疏性,能够减少梯度消失的可能性,还具有非常好的收敛性能和较低的计算成本(张志厚等,2021a). 图6 局部特征学习模块框图Convolution为卷积算子,其大小为3,步长为1,跨度为1;BN为批处理归一化算子;ReLU为线性整流函数;Max Pooling为一维最大池化算子,其大小为3,步长为1.Fig.6 Block diagram of local feature learning moduleConvolution operator size is 3, step is 1, span is 1; BN is the batch normalization operator;ReLU is a linear rectification function; The size of one-dimensional maximal pooling operator is 3, step is 1. 局部特征学习可以根据不同的任务进行不同的组合,主要体现在卷积和池化的各种参数上.卷积层主要对局部特征进行提取,它会通过输入数据的长度与卷积内核进行卷积,然后通过计算核元素与输入元素之间的点积来生成特征映射.其中,一维卷积计算表达式为: (14) 式中,x(n)为输入信号,z(n)为输出结果,w(n)长度为l的一维卷积核,文中卷积核初始化采用随机方式. 然后将卷积特征输入到BN层,再输入到激活函数中.BN是一种数据的变换计算,其主要作用将特征的均值归一到0,将方差归一到1,这样有助于加快模型的收敛速度,减小“梯度弥散”.当归一化特征之后再输入到激活函数层后,输出特征可以表示为: (15) (16) 其中,E[x]与D[x]分别为x的均值和方差,ε是很小的正数,α是尺度因子,β是平移因子.ReLU(x)为线性激活函数,表达式为: ReLU(x)=max(x,0). (17) 上述卷积、批处理归一化和线性激活执行两次之后,再将特征输入到最大池化层.池化执行信息的非线性降采样功能,同时也可以增加网络结构的感受野. LSTM是一种循环神经网络体系结构,可以进行全局序列信息相关性学习(Hochreiter and Schmidhuber, 1997).因此它被叠加在LFLB上,从提取的局部特征序列中学习全局信息的依赖关系.LSTM有4个类型的网络组件,包含输入门、输出门、遗忘门和一个具有自循环连接单元(图7).LSTM单元在每个时间步长t处的更新用等式(18)—(24)来描述(Hochreiter and Schmidhuber, 1997): 图7 LSTM模块结构图黄色虚线框内为细胞状态更新(Ct);红色虚线框内为遗忘门(ft);蓝色虚线框内为输入门(it);绿色虚线框内为输出门(ot);σg为sigmoid函数,tanh是双曲正切函数;⊙是阿达玛积;⊕表示相加.Fig.7 LSTM module structureThe cell status update (Ct) is in the yellow dashed box; The forgotten door (ft) is in the red dashed box; The input door (it) is in the blue dashed box; The output door (ot) is in the green dashed box; σg is the sigmoid function; tanh is the hyperbolic tangent function; ⊙ is the Hadamard product; ⊕means addition. (18) it=σg(Wi[ht-1,xt]+bi), (19) ot=σg(Wo[ht-1,xt]+bo), (20) (21) (22) xt=ot⊙σgCt, (23) ht=ot⊙tanh (Ct), (24) 式中,Ct为LSTM当前细胞状态更新值,xt为输入值,ht为输出值,W为参数矩阵,b为偏置向量,ft、it和ot分别为遗忘门、输入门和输出门变量,σg为sigmoid函数,tanh是双曲正切函数,⊙是阿达玛积,⨁表示相加,[·,·]表示两个变量拼接. 将LSTM模块输出的特征再输入到全连接层,全连接层可以表示为: zl=bl+zl-1·wl, (25) 式中变量上标l和l-1分别对应输入和输出的特征指标. softmax是整个网络结构的速度分类器,它利用输入的特征进行预测,该速度分类器是logistic回归多分类问题的一种推广,表达式为: zi=∑jhjWji, (26) (27) 其中,zi为softmax分类器的输入,hj为倒数第二层的激活函数,Wji为倒数第二层与分类器连接的权重. 通过前文所述的方法共构建的样本数据为140000对.将样本数据包含了训练、测试以及验证数据,比例为18∶1∶1,即126000个数据作为训练,验证数据和测试数据各有7000个.训练轮数可以自由设定,图8所示为频散曲线深度学习网络的误差(轮数为100),可以看出,训练误差与验证误差的变化保持同步,模型训练良好,未出现过欠拟合. 图8 训练误差及验证误差Fig.8 Training loss and validation loss 为了测试本文所提方法的反演效果,将测试集中的7000组数据全部进行反演,共耗时5.267 s,平均每组数据反演耗时0.75 ms.从测试集中随机抽取了一些反演结果,如图9所示.从图中可以看出,CNN-LSTM反演方法无论是对正常地层递增的速度模型(图9a),还是速度异常夹层(图9d、e),以及速度突变层(图9b、c、f、g)都具有较好的反演效果,反演的横波速度值和理论模型基本一致.同时,理论速度模型的频散曲线与反演结果的频散曲线拟合度极高(图9h—n).为了进一步检验本文方法的稳定性,将图9所示的7组模型的频散曲线加入5%的随机噪声,然后获得其反演结果(图10),可以看出,反演结果能够完全反映出地下速度的变化趋势及其分层特性. 图9 测试集中抽取的理论值与反演结果对比(a)—(g) 分别为7组理论模型与反演结果对比图; (h)—(n) 分别为(a)—(g)理论模型与反演结果的频散曲线图. 图中红色与蓝色曲线分别代表理论值与反演结果.Fig.9 Comparison of theoretical values and inversion results of randomly selected data pairs(a)—(g) Correspond to 7 groups of theoretical models and inversion results respectively; (h)—(n) are the dispersion curves of (a)—(g) theoretical model and inversion results respectively. The red and blue curves in the figure represent the theoretical value and inversion result respectively. 图10 加噪声数据的反演结果与理论模型对比(a)—(g) 分别为7组加噪声数据反演结果与理论模型对比; (h)—(n) 分别为(a)—(g)理论模型与加噪声反演结果的频散曲线图. 图中红色与蓝色曲线分别代表理论值与反演结果.Fig.10 Comparison of inversion results and theoretical models for noise-contained data(a)—(g) Correspond to 7 groups of noise-contained data inversion results and theoretical models; (h)—(n) are the dispersion curves of (a)—(g) theoretical model and noise-contained data inversion results respectively. The red and blue curves in the figure represent the theoretical value and inversion result respectively. 为了客观评价反演效果,本文分别计算了理论数据反演结果与含噪数据反演结果的误差,如表1所示,无噪声情况下,反演速度模型的相对误差(Relative Error, RE)最大为0.09,频散曲线拟合的平均相对误差(Mean Relative Error, MRE)最大为0.056;含噪声情况下,反演速度模型的相对误差最大为0.15,频散曲线拟合的平均相对误差最大为0.089.可以看出,本文所提方法的计算精度高、鲁棒性强. 表1 反演结果的误差Table 1 Error of inversion results 总体而言,CNN-LSTM反演方法具有较高的精度与反演速度.另外,基于DL的反演方法,在抗噪能力上有一定的特点,并与训练轮数相关.训练轮数少,相应的反演精度相对低,但鲁棒性就越强,即网络的抗噪能力越强;训练轮数多,相应的反演精度就高,但鲁棒性会变弱,即DL泛化性能会降低.因此,如何平衡训练轮数与鲁棒性之间的关系是一个值得深思的问题. 为了进一步测试本文所提方法的效果,采用二维边坡模型(Mi et al., 2020)来检验方法的有效性.该模型简化为一个倾斜界面(图11a),在25 m处界面深度为9.2 m,界面与水平方向的夹角为10°,该模型可以看作是由从左至右的两层模型拼接而成,深度逐渐减小.首先采用多道面波分析(Multichannel Analysis of Surface Waves, MASW)数值计算方法(Mi et al., 2017)获得该模型不同采集剖面中点的瑞雷波频散速度(采用有限差分方法模拟13条合成多道记录,在有限差分法中,空间网格大小为0.2 m,时间步长为0.02 ms,震源是一个位于自由表面20 Hz的雷克子波,延迟60 ms,模拟剖面道间距1 m,剖面长度24 m,约为最大勘探深度的2倍,检波器道数为25,炮点位于剖面左侧,最小偏移距为30 m, 炮间距2 m,采用滚动采集模式).然后利用本文所提方法对所有频散曲线进行一维反演,随后通过空间插值方案(Miller et al., 1999)对倒置一维模型进行网格化,再合成相应的伪二维结果(图11b),可以看出反演结果与真实界面位置具有较好的对应性. 图11 二维模型及反演结果(a) 模型示意图(Mi et al., 2020); (b) 反演横波速度伪二维图.图中黑色虚线为界面位置.Fig.11 Two-dimensional model and inversion result(a) Illustration of a syntheticmodel (Mi et al., 2020); (b) Pseudo-two-dimensional VS Section of the inversion results, the dashed line in (b) represents the dipping interface. 将本文方法应用于同震偏移(2008年汶川MW7.9地震)勘探的瑞雷波数据中.同震偏移的确定对于理解断裂带力学机制具有重要的意义(Scholz, 2019; Wang et al., 2021).2008年汶川MW7.9地震发生在青藏高原东缘龙门山逆冲带;该断裂带主要由三条北东向逆冲断层组成,分别为茂县—汶川断裂、江油—灌县断裂和映秀—北川断裂. 作为发震断裂之一的江油—灌县断裂同震垂向位移量为1~2 m(Xu et al., 2009; Zhang et al., 2010).本文选择位于该断裂的白鹿镇同震地表破裂带开展了瑞雷波勘探,旨在探测浅表层第四纪堆积物的速度结构,为同震偏移的“局部吸收”效应提供科学佐证(Wang et al., 2021).瑞雷波频散曲线DL反演结果如图12所示(数据采集采用滚动模式,最小偏移距1 m,道间距2 m,共24道,炮间距2 m,震源为锤击震源,图12a中水平距离10 m处的单炮地震记录及对应频散曲线见附录中图A1).白鹿镇同震地表破裂带较好保存在原白鹿中学一带,该部位主要发育有两级阶地,阶地高差约4 m(图13,图14a).该处的同震破裂带走向约北东向,表现为逆冲型破裂,其中在T2阶地白鹿中学操场产生约1.8 m的垂向位错量(BLL2,图12a,图14a、b).而在操场北东方向的T1阶地白鹿河左岸一带,同震垂直位错量达到约2.5 m (BLL1,图12b,图14a、d),Ran等(2010)在该观测点以北测量一小路被同震垂向位错约2.4 m(图14a、c).因此,T1阶地的同震垂向位错量比T2阶地大39%.考虑到操场和白鹿河岸旁观测点之间的距离为185m(图13b),获得两个场地之间的同震垂向位错量变化率为3.8 m·km-1.此外,横跨T2阶地操场地表破裂的瑞雷波勘探剖面显示,第四系沉积物在断层上盘的视厚度为9.6 m (BLS2,图12a),这与白鹿中学操场观测点处开挖的大型探槽(图14a、e)揭示的第四系地层厚度具有一致性,表明瑞雷波的深度学习反演方法具有较好的可靠性.同时本文反演T1阶地观测点处在断层上盘的第四系沉积物视厚度为6.4m(BLS1,图12b),上述成果表明第四系松散地层可能在同震地表位错变形的局部化方面具有重要的作用,能够一定程度上吸收同震位错变形量(Wang et al., 2021). 图12 白鹿镇地表破裂的瑞雷波反演结果(a) T2垂直偏移约1.8 m,断层上盘显示第四系沉积厚度约9.6 m; (b) T1垂直偏移约2.5 m,断层上盘显示第四系沉积,厚度约6.4 m.Fig.12 Rayleigh wave inversion results of surface ruptures at Bailu(a) The second terrace was vertically offset by about 1.8 m and shows Quaternary deposits with an apparent thickness of about 9.6 m at the hanging wall of the fault; (b) The first terrace was vertically offset by about 2.5 m and shows Quaternary deposits with an apparent thickness of about 6.4 m at the hanging wall of the fault. 图13 白鹿镇地形(a) 高分辨率图像(谷歌地球); (b) 地形解释,红线表示2008年MW7.9汶川地震有关的地表破裂,蓝线和绿线分别表示瑞雷波剖面和地形调查剖面,“T”为阶地.Fig.13 Landform at Bailu(a) A high-resolution image (Google Earth); (b)Landform interpretation. Red lines denote surface ruptures associated with the 2008 MW7.9 Wenchuan earthquake. Blue and green short lines show Rayleigh wave profiles and landform survey profiles, respectively. “T” marks terrace. 图14 白鹿镇地表破裂带(a) 无人机拍摄的白鹿镇照片; (b) T2上两栋校舍之间的操场垂直偏移约1.8 m; (c) T1上的小路垂直偏移约2.4 m; (d) 白鹿河左岸T1面垂直偏移约2.5 m; (e) 在操场的地表破裂处挖掘了一条沟渠(Ran et al., 2019)研究表明次级阶地的地层单元主要为砂质黏土,含粒径为0.2~5 cm的小砾石.黄色虚线表示阶地和坡状沉积的边界,蓝线和绿线分别表示地震剖面的地形调查剖面,红线表示地表破裂与2008年有关MW7.9汶川地震,白色虚线表示与地震相关的突变断层;图片(b)、(c)、(e)分别摄于2010年、2008年和2009年.Fig.14 Surface fracture zone at Bailu(a) Photo ofBailu taken by drone; (b) The playground between two school buildings on the second terrace (T2) was vertically offset by about 1.8 m; (c) The small road on the first terrace (T1) was vertically offset by about 2.4 m; (d) Surface of T1 at the left bank of the Bailu River was vertically offset by about 2.5 m; (e) A trench was excavated across the surface rupture at the playground (Ran et al., 2019). The trench shows that the stratigraphic units of the second terrace mainly consist of sandy clay containing small gravels with diameters of 0.2~5 cm. Yellow dashed lines represent boundaries of terrace and sloperelated deposit. Blue and green short lines demote seismic profiles and landform survey profiles, respectively. “T” marks terrace. Red lines denote surface ruptures associated with the 2008 MW7.9 Wenchuan earthquake, and white dashed lines demote the coseismic fault scarps related to the earthquake. Photos (b)、(c)、(e) were taken in 2010, 2008, and 2009, respectively. 图A1 (a)单炮地震记录; (b)图(a)对应频散图 Fig.A1 (a) Single shot seismic record; (b) Dispersion curve corresponding to (a) 本文提出一种基于瑞雷波频散曲线的DL反演新方法.DL主要包含了两大重要的内容,一是样本数据,二是网络结构.在样本数据集构建方面:本文针对地球物理反演的近地表速度结构展开讨论,阐述了近地表速度结构的演化轨道也将力图遍历其相空间各种可能的体制和状态,具有其各态遍历性,以及其在演化中还有力图保持自身特征形态的有序性特征.基于速度结构的遍历性和有序性,本文提出了约束马尔科夫决策的近地表速度结构模型,随后对速度模型进行正演获得了具有代表性的样本数据对.随机抽样试验表明了约束MC的样本数据集构建方法具有一定的合理性.在网络结构搭建方面:本文提出了一种CNN-LSTM的混合网络结构,该网络结构包含了3个局部特征学习模块和1个长短时记忆层,局部特征学习模块主要包含了双卷积层和最大池化层,用于局部特征提取和层次关联学习,LSTM从学习到的局部特征中继续学习特征的长期依赖关系.这种混合网络结构能够结合CNN和LSTM各自优势,取长补短,最终对频散曲线的序列数据进行反演. 模型试验表明本文方法具有较高的计算精度和良好的鲁棒性,且计算效率极高,通常不到1 ms.以及将本文方法应用于同震偏移勘探的瑞雷波数据反演中,其结果与实地地震地质条件具有很好的一致性,表明本文反演方法具有较好的可信度. 本文DL的反演方法,在抗噪能力上有一定的特点,并与训练轮数相关.训练轮数少,相应的反演精度相对低,但鲁棒性就越强,同时也对应网络结构的泛化性能强;训练轮数多,相应的反演精度就高,但鲁棒性会变弱,即DL泛化性能会降低.因此,一方面如何平衡训练轮数与鲁棒性之间的关系是一个值得深思的问题;另一方面,如何进一步同时提高计算精度和网络的泛化性能,需要更深更合理的网络结构以及更加完备的样本数据集.然而,这势必会引起网络复杂度与计算量增加.因此,在随后的工作中,课题组将进一步对样本数据构建以及网络结构精修进行系统性的研究,以此更加符合真实地质情况的应用需求,从而使得频散曲线的深度学习反演方法更加普适化. 致谢感谢匿名审稿专家对论文提出的宝贵修改建议,感谢浙江大学宓彬彬副研究员提供的二维模型及对应的频散速度数据! 附录


1.4 速度模型构建的基本步骤
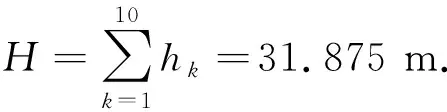






1.5 样本数据随机抽样实例

2 瑞雷波频散曲线反演方法
2.1 频散曲线反演网络总体结构

2.2 频散曲线局部特征学习模块(LFLB)


2.3 频散曲线全局特征学习模块

2.4 全连接模块及速度分类器
3 模型实验
3.1 模型训练

3.2 抽取测试数据反演结果


3.3 二维模型试验

4 实际资料应用




5 结论与讨论
