基于改进的PCA-RBFNN过程变量软测量建模及应用
2022-06-02朱荷蕾高慧敏
朱荷蕾,高慧敏
(嘉兴学院 信息科学与工程学院,浙江 嘉兴 314001)
0 引言
工业生产体系中多采用集散控制和现场总线技术,特别是自动化流水线生产系统,工艺生产过程的控制完全由现场数据进行驱动。然而,一旦现场传感器出现数据故障,则会引起生产系统暂停或中止,不但可能引发安全事故,而且后续生产恢复的工作量也极其繁重,严重影响生产进度。本文针对生产过程中存在的不易测量或者需要多重测量的关键工艺参数,提出一种软测量建模方法,以实现过程变量的在线软测量及实时监控,提高现场生产过程的安全性、稳定性。
软测量就是通过选择与被估计变量相关的一系列可测变量,构造以可测变量为输入、被估计变量为输出的数学模型。目前,该方法的研究主要集中在混合建模[1-2],一方面通过主成分分析(Principal Component Analysis,PCA)、偏最小二乘法(Partial Least Square,PLS)等回归分析技术解决模型输入变量优化选择问题;另一方面利用神经网络、模糊数学、统计学习等人工智能理论在非线性拟合方面的优势提高模型预测精度。例如:ZHAO等[3]提出了自适应加权最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)的软测量模型,实现了催化重整生产过程中芳烃产量的在线预测;SUN等[4]提出PCA-PSO-LSSVM模型对造纸废水厌氧处理系统中水质的化学需氧量(Chemical Oxygen Demand,COD)进行在线软测量;WEI[5]结合主成分分析和径向基(Radial Basis Function,RBF)神经网络模型对台风期间水库流域的降水量进行定量预报;ZHANG等[6]提出了基于SVM和遗传神经网络(Genetic Algorithm Neural Network,GA-NN)的预测模型,实现了油水两相流中水分含量的软测量。
但上述方法在对过程变量进行回归分析时存在一些缺陷,例如文献[3]中主成分分析(PCA)筛选出的综合变量过少导致系统特性丢失,降低了预测模型的泛化能力;文献[4-5]将经主成分分析后的主元变量作为神经网络的输入,导致模型预测精度不高。同时,这些方法多侧重于某一应用领域,研究重点在模型结构改进和权值优化上,造成模型本身比较复杂,增加了实际工程中的应用难度。本文提出一种改进的PCA-RBFNN软测量建模方法,根据过程变量集合的PCA相关性分析,筛选出最能体现系统运行特性的过程变量子集作为RBF神经网络的输入,解决了直接利用主成分变量建模时模型泛化能力弱、解释性不足的问题。同时在RBFNN的构建过程中采用梯度下降法优化网络参数,提高模型精度。该方法能够在减少现场数据采集量的同时实现过程变量的在线预测,满足现场过程控制的要求。
1 改进的PCA-RBFNN模型
1.1 模型结构
改进的PCA-RBFNN模型主要由PCA变量筛选和RBF神经网络两部分组合而成,如图1所示。首先对样本空间数据进行主成分分析,找出最能体现系统运行特性的原始过程变量作为网络的新输入;然后利用梯度下降法对RBF网络参数进行训练和优化,直到满足精度要求。

1.2 PCA变量筛选
在改进的PCA-RBFNN模型中,设过程变量的运行数据构成样本空间为矩阵X(I×J),其中I为样本数,J为过程变量个数,则矩阵X的主成分分析结果[7-8]为:
X=(x1,x1,…xJ)=FAT,A=(α1,α2,…,αJ),F=(F1,F2,…,FJ);S=diag{λ1,λ2,…,λJ},λ1≥λ2≥…≥λJ。
(1)
式中:xk=(x1k,x2k,…,xJk)T,k=1,2,…,J,为第k个过程变量样本向量;αk=(a1k,a2k,…,aJk)T为矩阵X经主成分分析后第k个特征向量;Fk为主成分向量;λk=Var(Fk)为主成分向量Fk在第k个特征向量方向上提取的特征值;S为J个特征值按照从大到小排列构成的对角矩阵。主成分分析后可得到J个主成分,每个主成分包含的变异信息量是递减的,则第k个主成分的贡献率Ck以及前p个主成分的累计贡献率CCp分别为:
(2)
本文采用主成分分析变量筛选方法直接从原始过程变量集合中选择过程变量子集合,以较少的数据量获得理想的建模效果,其筛选流程如图2所示。

首先对过程变量集合的样本数据进行第一次主成分分析,在特征值序列中找到最小特征值λmin,若其贡献率ρλmin小于设定值ρ0,则说明其主成分对总体的贡献量最小,在特征值λmin对应的特征向量αmin中找出所占权数最大的分量,该分量对应的过程变量xd即为需要删除的变量,因为过程变量xd在贡献量最小的主成分中起最主要的作用。在样本空间中删除过程变量xd的样本数据,然后对保留下来的样本空间数据重新进行主成分分析,若找到的最小特征值λmin贡献率仍然小于设定值ρ0,则继续删除对应的过程变量,更新样本空间后重新进行主成分分析,直到最小特征值λmin贡献率大于设定值ρ0,则输出样本空间中最终保留的过程变量集合,该集合中的过程变量具有对原变量系统最佳的解释能力。通过主成分分析筛选变量法找到了软测量建模中与被估计变量最相关的过程变量子集合,不但减小了建模工作量,而且保证了模型的可靠性和稳定性。
1.3 RBF神经网络参数
模型中RBF神经网络采用3层前馈网络[9-10],其多输入单输出结构如图3所示。第一层为输入层,有M个信号源输入节点;第二层为隐含层,有H个隐节点;第三层是输出层,有1个输出节点。

经PCA变量筛选后所保留下来的过程变量的历史数据作为训练样本集,设样本数为Q,则RBF神经网络的输入和输出关系可用线性回归模型[12]表示为:
(3)
写为矩阵形式,即:
d=Θw+e。
(4)
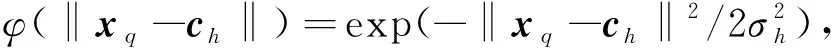
RBF神经网络设计重点在于对网络参数的求解[11-12],主要包括隐含层节点的数据中心ch、基函数的扩展系数σh和隐含层到输出层的连接权值wh。 采用监督学习算法对网络进行训练[13],并通过梯度下降法对参数进行优化。设定目标函数为
(5)
由式(4)和式(5),第i个样本输入的模型误差为:
(6)
目标函数E在ch、σh及wh方向上的梯度为ch、σh及wh,有
(7)
(8)
(9)
为使目标函数最小化,各参数的修正量与其负梯度成正比,即:
Δch=-ηch; Δσh=-ησh; Δwh=-ηwh。
(10)
其中η为参数修正的学习率。在RBF神经网络参数训练优化过程中,对于每个输入样本xi,可根据式(10)中的修正量对网络参数进行调整,使目标函数取得最小值。在参数优化前需要对参数进行初始化,具体方法为:
(1)对训练样本集进行k-means聚类得到H个聚类,将这些聚类中心作为隐含层节点的数据中心。
(2)基函数的扩展系数为:
(11)
式中cmax为数据中心的最大距离。
(3)隐含层到输出层的连接权值可以用最小均方误差法[14]直接计算得到,公式为:
w=Θ+d,Θ+=(ΘTΘ)-1ΘT。
(12)
式中Θ+是回归向量矩阵的伪逆。
2 模型验证及性能分析
2.1 应用实例
图4是纺织原料生产中某工艺过程示意图,为典型的间歇生产过程,其过程变量为压力P1、P2、P3、P4,温度T1、T2,液位L1、L2、L3,对应各个传感器的属性及数据测量范围如表1所示。


表1 过程变量传感器属性及数据范围
液位L1为浮标式液位传感器,安装于反应室底部,工作条件比较恶劣,常有短暂数据不准或缺失问题,故选为被估计变量,利用本文所提出的改进PCA-RBFNN建模方法,建立该变量的软测量模型,如图5所示。
2.2 数据预处理和过程变量筛选
在历史数据库中选取1个批次的全部数据作为建模样本,采样点数量为250,记为矩阵X(250×9),为消除变量量纲及数值大小的影响,需要对X进行标准化处理[15-16],分别采用Min-Max标准化和Z-score标准化。


(13)
(14)
式(13)中:xj、x′j分别为第j个过程变量的原始值和标准化后的值;xmax、xmin分别为原始值中的最大值和最小值。Min-Max标准化方法用于RBF神经网络输入数据的预处理,其将原始值映射到[-1,1]范围内。
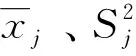
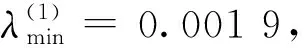
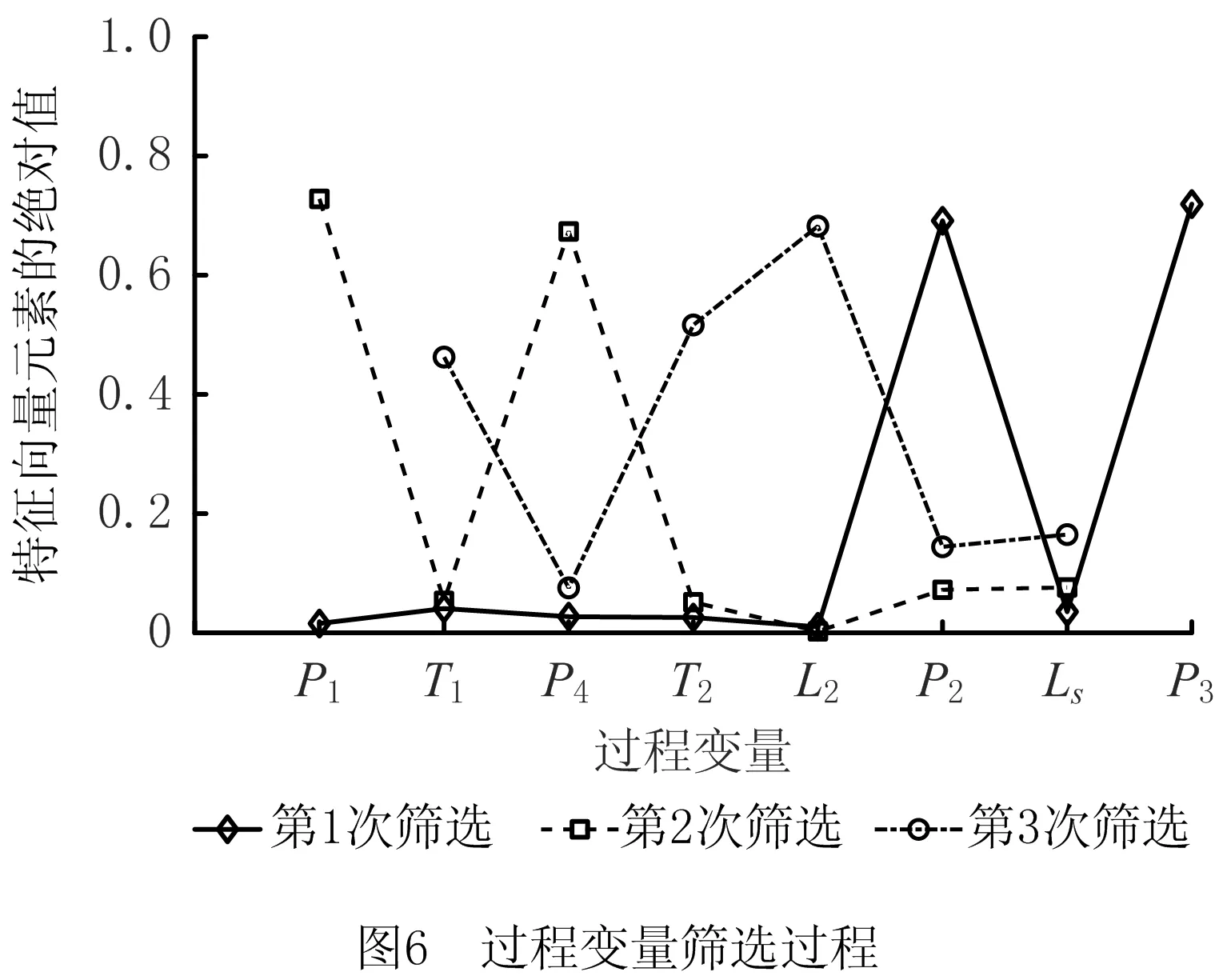
2.3 改进PCA-RBFNN模型的构建及输出性能
将筛选出的过程变量子集作为改进PCA-RBFNN软测量模型RBF网络的输入,被估计变量L1(反应室液位)作为RBF网络的输出,则过程变量子集的样本数据Xin(250×5)、被估计变量L1的样本数据Y(250×1)组成了RBF神经网络的训练样本集。RBF网络参数设置如下:模型误差目标E为1.0e-05;隐含层节点数量为250;学习效率η为0.1。网络训练时,首先采用K-means聚类和最小均方误差法初始化数据中心、扩展系数和连接权值,然后按照梯度下降法不断优化网络参数,直到网络收敛且输出误差满足预先设定的误差目标为止。
选取残差(δ)、相对误差(RE)、平均相对误差(MRE)、误差平方和(ESS)、均方根误差(RMSE)、相关系数(CC)和效率系数(CE)7个指标定量描述模型的输出性能,如下:
(15)


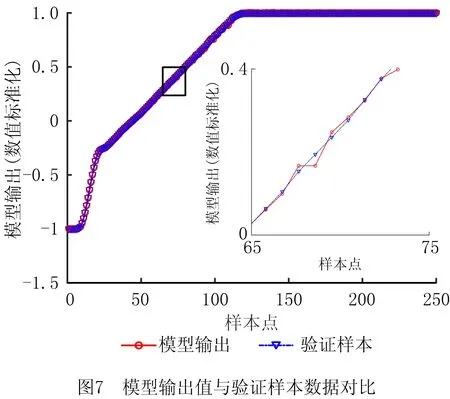
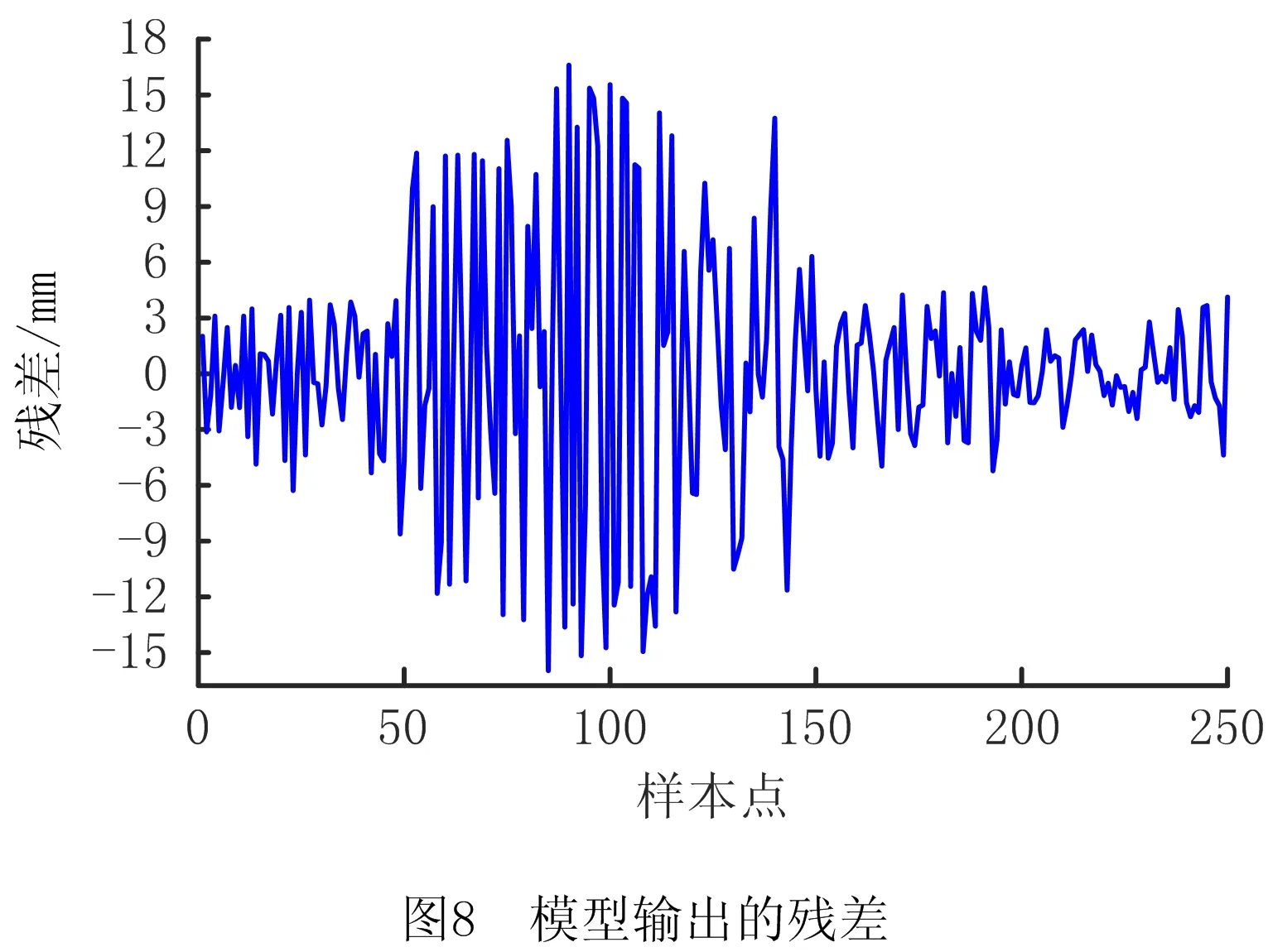
由表2可知,随着网络误差目标的提高,网络训练迭代次数不断增加,模型输出的误差平方和、均方根误差均不断减小。当误差目标分别为1.0e-05和1.0e-06时,网络训练次数需要增加2倍,而输出误差减小并不明显,因此考虑到训练时间和计算量等因素,选取合适的误差目标为1.0e-05。

表2 不同网络精度目标下模型的输出性能对比
2.4 改进前后PCA-RBFNN模型的性能对比
为对比改进前后两种模型,本文构建了改进前的PCA-RBFNN模型,通过对8个原始过程变量进行主成分分析,按照累计贡献率超过85%的原则,选取两个主成分变量PC1和PC2作为RBF神经网络的输入进行建模。

(16)
式中,PC1、PC2两个主成分变量为8个原始过程变量的线性组合。建模样本数据、验证样本以及模型参数设置与2.3节中改进模型相同。
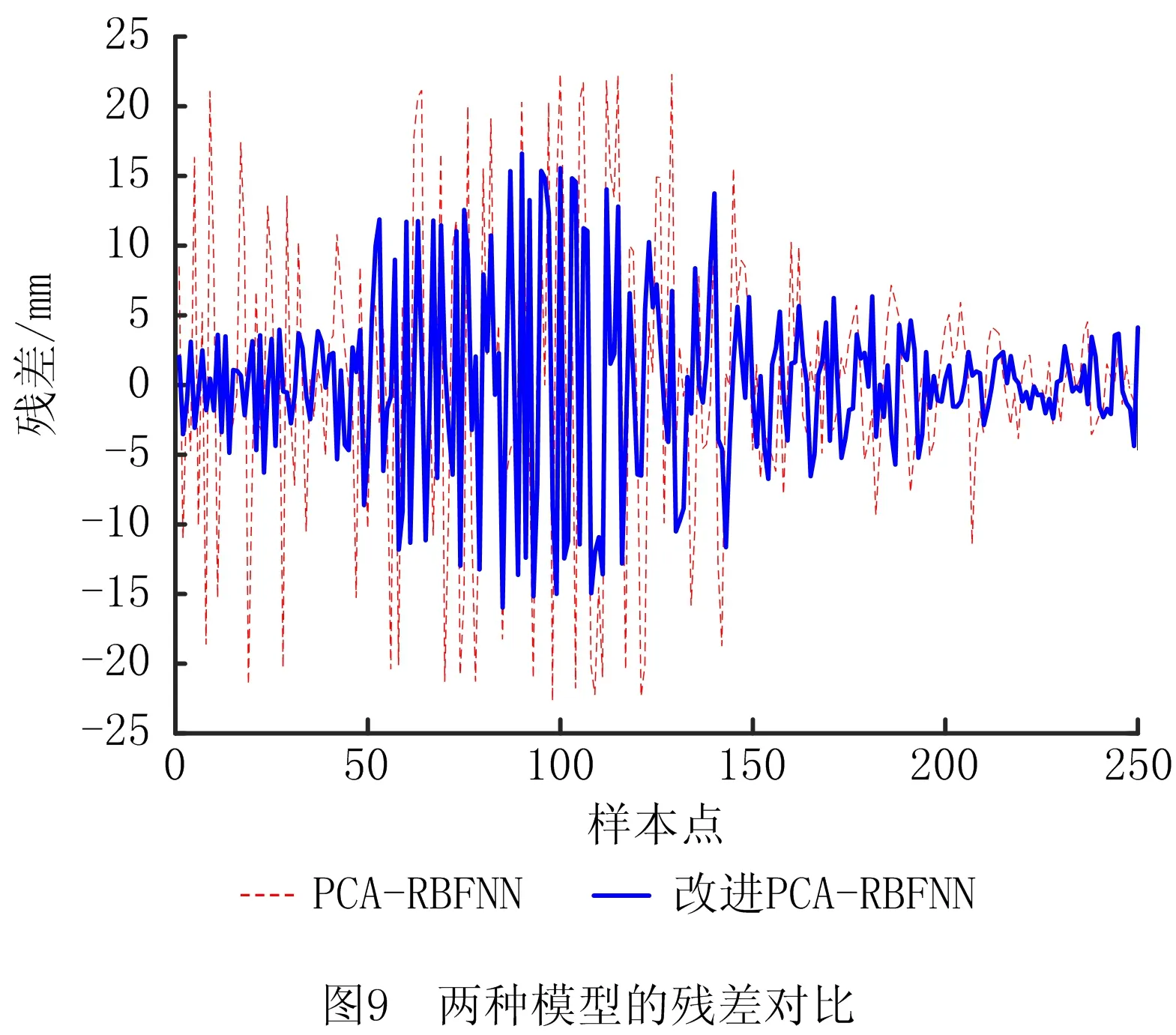
如图9所示为两个模型的残差对比,改进前模型的残差分布在[-21 mm,21 mm]范围内,而改进后模型的残差范围减小为[-11 mm,11 mm],说明改进模型的预测输出与测量值拟合得更好,模型预测精度得到提高。
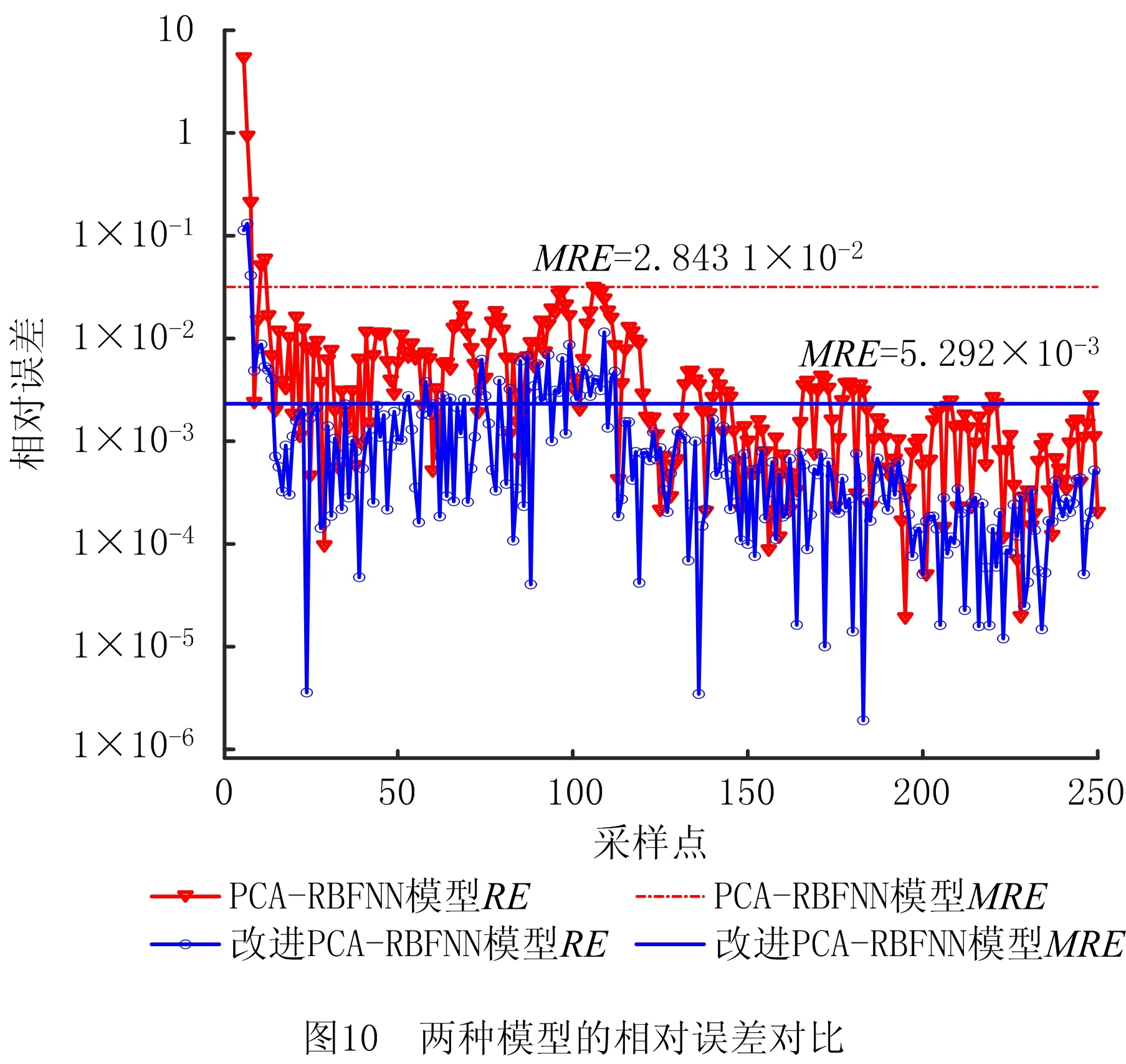
如图10所示为两个模型的相对误差对比,为便于说明,图中纵坐标采用对数形式,可以看出在开始几个采样点位置处两个模型均存在较大的相对误差,沿着采样点轴向方向,相对误差呈逐渐减小的趋势。两个模型的平均相对误差分别为2.843 1e-2、5.292e-3,改进模型的相对误差在总体分布上明显小于改进前模型。
由表3可知,改进模型的误差平方和、均方根误差相比改进前模型均降低了一个数量级,进一步说明改进模型的预测输出在整体上较改进前有了很大的提高。同时,改进模型的相关系数和效率系数也有所提高,说明模型的预测性能得到提升。

表3 两种模型的性能指标对比
改进前,模型虽然使用了8个过程变量数据,但实际的模型输入是主成分分析后的2个主成分变量,导致建模时输入节点数量过少,损失了一部分系统运行信息,造成模型精度不高、泛化能力不强。而改进模型使用5个原始过程变量数据作为模型输入,在保证模型精度的同时减少了建模运算量。在实际应用中改进模型可以以较少的现场数据采集量实现关键参数的精确预测。
3 结束语
本文针对生产过程中关键过程变量的预测提出了改进PCA-RBFNN软测量建模方法,通过对过程变量集进行主成分分析筛选确定出对系统运行特性具有最佳解释能力的过程变量子集,降低了建模输入维数和模型运算量,同时采用梯度下降法训练和校正RBF神经网络,并分析和对比改进前后两种模型的输出性能。通过实例建模及模型输出性能对比,表明改进模型能够在减少现场数据采集量的同时实现过程变量的精确在线预测,具有较好的泛化能力和输出精度。
在后续的研究中,将针对主成分分析时所使用的生产过程数据进行数据归一化预处理,以改善PCA变量筛选时的计算精度和效率,从而提高模型整体的输出性能。
