基于速率修正PSO 和核基ELM 的云数据库恶意行为识别方法
2022-06-02李玉玲朱咏梅刘东红顾振飞
李玉玲 ,朱咏梅 ,刘东红 ,顾振飞
(1.上海电子信息职业技术学院电子技术与工程学院,上海 201411;2.南京信息职业技术学院网络与通信学院,江苏 南京 210023)
云数据库[1]是一种经过优化被部署到云计算环境中的数据库,可以实现按需付费、按需扩展、高可用性以及存储整合等优势。相对于用户自建数据库,云数据库具有更经济、更专业、更高效、更可靠的特点。随着云计算技术的成熟,云数据库也在各行各业中得到了广泛的应用并发挥着不可替代的作用。尽管如此,从传统数据库往云数据库的转换仍然面临着一些挑战,其中最为关键的就是如何保证云数据库的安全性[2,3]。目前针对云数据库的恶意行为攻击尤其突出,一些大型企业的云数据库几乎每天都会面对大量的服务器干预、网络渗透以及SQL 注入等各类恶意行为攻击。事实上,许多企业已经将恶意行为视为他们日常业务运营的最大威胁。在云数据库逐渐取代传统数据库的大趋势下,如何避免恶意行为的攻击以及降低攻击风险是相关行业以及学者必须解决的当务之急。
目前主要有两类恶意行为检测方案。第一种是基于特征的恶意行为检测[4,5],这种方案维护一个已知攻击的特征数据库,通过特征数据库去匹配已知的恶意行为攻击。Lu 等人[21]提出了一种Poster架构,对网络链接、服务延迟、吞吐量等流量特征设定恶意攻击的判别阈值,通过比较实时监测数据和判别阈值确定是否发生了恶意攻击行为。何亨等人[22]将数据包IP 头部和TCP 头部作为特征数据,根据预先设定的规则,当其中特定额度特征数据超过阈值时就报告相应的异常行为。文献[25]基于贝叶斯算法自适应地推理出僵尸网络生命周期事件之间的因果关系,从而计算每个主机的感染可能性。
第二种是基于异常的入侵检测系统[6,7],这种方案通过观察正常的流量数据并学习其规律,一旦检测到不符合正常规律的流量数据后,就认为存在恶意行为。Damian 等人[23]提出了基于人工神经网络的入侵检测系统,特征生成器从细粒度数据流中提取流量统计信息并进行处理形成流量特征,传输至分类器,由分类器检测数据平面中的恶意活动,控制器监控特征生成器和分类器的操作,并对流量分类的结果进行可视化。文献[24]构建了基于深度神经网络模型的入侵检测系统,该模型中使用NSLKDD 数据集进行训练,并通过在SDN 中获得的网络链接时间长度、网络协议类型、从源地址到目的地址的数据字节数、从目的地址到源地址的数据字节数、两秒内同一主机的连接数、两秒内同一服务的连接数这6 个基本特征来进行SDN 异常流量检测。此外他们还将门控循环单元(Gated Recurrent Unit,GRU)提升网络的长短期记忆。
以上两种方案均是基于某种既定规则去实现恶意行为检测的,尽管方案具备一定的有效性[8,9],但是检测过程的计算复杂度较高且依赖于规则的人工维护[10]。对于常见恶意行为攻击之外的新型攻击手段,现有的检测方案缺乏较好的应对策略。因此我们需要针对云数据库设计一种更为泛用的恶意行为检测模型来保障其安全性[11]。
(1)本文工作
针对以上问题,本文提出一种基于改进粒子群优化与核极限学习机的恶意行为检测方法(KE-VP)。该方法的核心是对粒子群优化算法进行了改进,然后通过与核极限学习机相结合,从而实现一种基于机器学习的恶意行为攻击检测。通过实验分析,我们发现KE-VP 与现有方案相比具备更好的检测精度和检测效率。
(2)相关工作
文献[12]提出了一种基于投票极限学习机的异常行为检测方案,试图通过神经网络模型来执行DDoS 攻击的检测。方案在NSL-KDD 数据集上达到了99.18%的检测精度,在ISCX 数据集上达到了92.11%的检测精度。文献[13]将泰勒序列与象群优化算法相结合,然后通过一个模糊分类器来实现规则的学习。文献[14]提出了一种AI 驱动的多层防护策略模型,包含数据采集器、交换器、域控制器、NFV 虚拟化设施以及智能控制器共5 层架构。通过NS3.26 模拟的IP 嗅探、主机劫持、重载流量表、DDoS、控制层饱和等攻击的测试,该模型能够很好地识别出大多数攻击。文献[15]提出了一种基于支持向量机的权限管理算法来对用户的行为进行分类。
1 恶意行为检测
为了提升云数据库的接入安全性,本文提出了一种称为KE-VP 的异常行为检测方案。对于用户而言,对云数据库的相关操作都是通过从客户端发起的操作请求去执行的,而操作请求中是有可能包含一些恶意行为的,这是由于:(1)操作请求是由恶意用户发起的;(2)操作请求在传输过程中遭到了某种攻击。因此当客户端向云数据库发起操作请求后,云数据库需要对收到的操作请求进行必要的检测。
本方案首先通过数据集来训练KE-VP,然后利用训练好的模型来检测实际操作请求是否为某种恶意行为攻击。具体的执行流程包括:(1)预处理;(2)特征抽取;(3)特征降维;(4)特征转换与标准化;(5)检测。下面对这几个步骤进行介绍。
1.1 预处理
为了防止测试集信息泄露,我们在预处理之前,将原始的数据集划分为训练集和测试集。原始的训练集包含大量的重复且非必要的数据,这些数据构成了原始数据集当中的噪声。因此需要通过去重、填充等操作去除原始数据集当中的噪声,防止噪声对异常行为检测模型的训练造成影响。
1.2 特征提取
在预处理工作的基础上,我们从数据集当中总共提取出47 种数据特征,主要包括:流量特征、内容特征、基础特征、生成特征以及时间特征等。以上特征最终用于对行为进行分类。在本文所阐述的工作中,我们根据公开数据集UNSW-NB15[16]对原始数据集进行了特征提取。表1 展示了UNSW-NB15 中各个特征的数据类型、特征码号以及特征总数等。
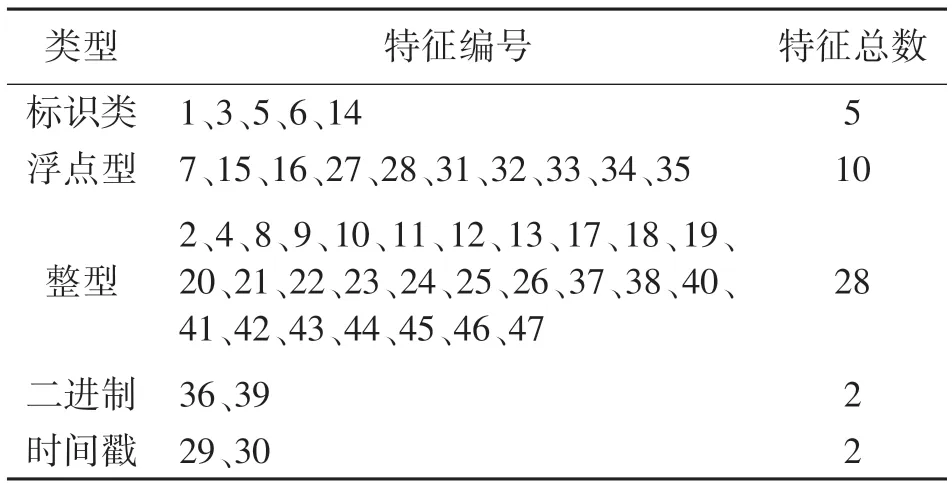
表1 UNSW-NB15 数据特征的类型、编号及总数
1.3 特征降维
特征降维是一种降低数据噪声、消除共线性问题的重要手段。通过特征降维,模型能够更好地识别出异常行为。在本文工作中,我们采用了线性判别分析算法(Linear Discriminant Analysis,LDA)来实现降维。LDA[17]原先是一种分类模型,不过该算法生成的投影向量具备良好的降维能力。
1.4 特征转换
通常情况下,数据集特征包括标识类特征和数值类特征。为便于后面的模型训练,我们需要将所有的标识类数据转换为数值类数据。UNSW-NB15数据集中包含协议类型、服务类型以及状态数据等表示类数据,我们按照图1 所示将其逐一转换为数值类数据。
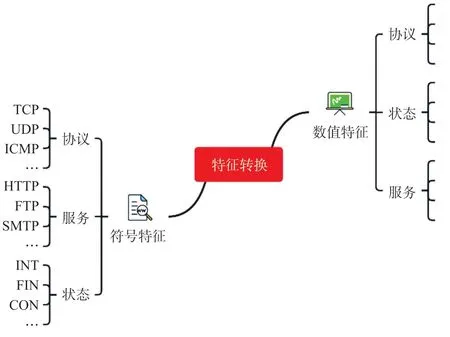
图1 UNSW-NB15 数据集符号特征的特征转换
经过特征转换后,我们对数据进行Min-Max 标准化处理。这一步操作的目的是为了保证所有特征在同一个尺度下,消除不同特征在统计意义下的偏差,进而提高模型训练的效率。Min-Max 标准化的公式如下所示:

式中:X为特征,xi为特征的任意样本,min(X)为特征X能取到的最小值,max(X)特征X能取到的最大值。在特征转换过程中,我们保留了训练集所有特征的最大值和最小值。在测试阶段,我们将利用训练集所有特征的最大值和最小值对测试集进行特征转换。这样的做法可以有效避免测试集信息泄露问题的发生。
1.5 识别
在完成以上所有的数据处理工作之后,我们利用处理好的数据去训练K-ELM by V-PSO(KE-VP)框架,用于云数据库上的恶意行为识别。框架主要分为检测和分类两个阶段。在检测阶段,算法将用户行为区分为正常行为和恶意行为;在分类阶段,算法将恶意行为分类为具体的攻击手段。
下一节将详细说明KE-VP 模型的构造方法。
2 模型构造
2.1 核函数优化极限学习机
极限学习机(Extreme Learning Machine,ELM)[18-19]是一类基于前馈神经网络(Feedforward Neural Network,FNN)构建的机器学习方法。极限学习机随机选取输入层权重和隐藏层偏置,输出层权重通过最小化由训练误差项和输出层权重范数的正则项构成的损失函数,依据Moore-Penrose 广义逆矩阵理论计算解析求出。即使随机生成隐藏层节点,ELM 仍保持FFN 的通用逼近能力。目前极限学习机的理论和应用已被广泛研究,从学习效率的角度来看,极限学习机具有训练参数少、学习速度快、泛化能力强的优点。
为方便后续的推导,我们首先给出单层前向传播神经网络的数学模型表示:
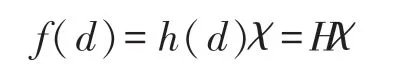
式中:d为输入样本,h(d)或H为隐藏层的映射矩阵,χ为隐藏层到输出层之间的权重。
对于ELM 而言,χ通过以下公式计算得出:

式中:Y为惩罚系数。因此ELM 的数学模型可以表示为下式:
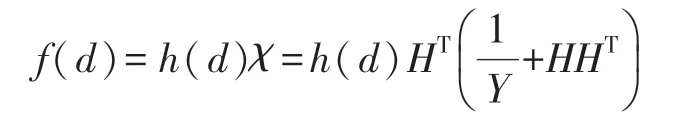
为了实现更快的收敛速度,我们在ELM 基础上部署了一个核函数,构成了一种核基极限学习机(Kernel-based Extreme Learning Machine,K-ELM)。原先ELM 中的特征映射矩阵h(d)被一个核函数K(p,q)替代。K-ELM 数学模型表示为下式:

式中:ΔKELM=HHT为核矩阵,K(p,q)=exp(-γp-q2)为一个高斯核函数。
在以上数学模型中,γ为核函数的带宽参数,它控制着模型输入从低维空间到高维空间的映射。Y为惩罚系数,它负责掌控模型复杂度与模型拟合误差之间的平衡。由此可见参数(γ,Y)的优化是模型训练的关键步骤,因此K-ELM 的性能好坏很大程度上取决于这两个参数的选取。但是较少的参数使得K-ELM 具有更好的泛化性能以及更快的收敛速度。除此之外,K-ELM 通过非线性映射来处理低维数据,从而克服了ELM 模型的线性不可分问题。
2.2 改进粒子群算法
粒子群优化(Particle Swarm Optimization,PSO)[20]是一种演化计算方法。PSO 算法最初是为了图形化地模拟鸟群优美而不可预测的运动,通过对群体行为的观察来发现群体中信息共享的演化优势。相比绝大多数优化算法,PSO 算法具有易于实现、参数少易调试的优势。然而,PSO 算法存在粒子运动更新速度慢,模拟随机搜索效果差的问题。为此我们考虑对粒子速率进行适时的修正,保证算法能够快速收敛到全局最优点。
为方便算法描述,我们首先在表2 中列出相关的符号和说明:

表2 符号以及定义
基于传统PSO 算法,我们提出了一种速率修正的PSO 算法(Velocity-corrected PSO,V-PSO),算法的具体步骤如下:
(1)初始化所有粒子的速度vi(t)和位置si(t);
(2)计算每个粒子i的初始适应度f(si(t));
(3)对每个粒子i,设置其最佳位置pbest,i=si(t);
(4)设置全局最佳位置gbest=min(pbest,i);
(5)对每个粒子i,按照以下的式子更新其速度:
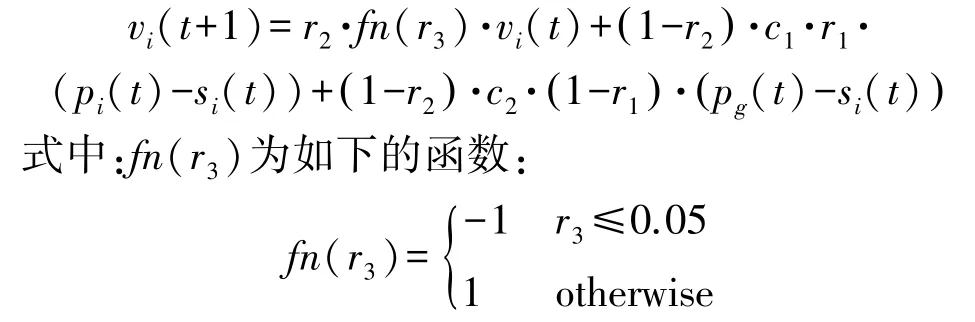
(6)对每个粒子i,按照以下的式子更新其位置:

(7)对每个粒子i,比较其当前位置si(t+1)和最佳位置pbest,i的适应度,如果当前位置si(t+1)的适应度较好,则将更新其最佳位置pbest,i为当前位置si(t+1);同时比较其当前位置si(t+1)和全局最佳位置gbest的适应度,如果当前位置si(t+1)的适应度较好,则重新设置gbest的索引为当前的粒子索引;
(8)重复步骤5-7,直至达到既定的迭代次数。
以上步骤形成的算法伪代码如下所示:
算法 V-PSO

相比PSO 算法,步骤5 当中的式子实现了一种更为细致的粒子速度更新方法。其中参数r1不足以呈现全局最优解,故而利用参数r2来控制局部最优与全局最优的平衡,同时利用函数fn(r3)用来限制粒子的随机运动。这种启发式机制相比经典的粒子群算法,在避免局部收敛方面拥有更好的性能。
3 实验分析
通过以上的算法优化,我们设计了K-ELM by V-PSO(KE-VP)框架,用于云数据库上的恶意行为识别。框架主要分为检测和分类两个阶段。在检测阶段,算法将用户行为区分为正常行为和恶意行为;在分类阶段,算法将恶意行为分类为具体的攻击手段。
框架基于Java 实现,在实验阶段我们将KE-VP与其他现有方法进行了对比,并分析了主要的性能指标。本节首先介绍我们所使用的数据集,然后给出详细的实验结果分析。
3.1 数据集
本方法在实验环节使用了UNSW-NB15 数据集,该数据集由新南威尔士大学堪培拉校区的网络靶场实验室基于IXIA 公司提供的PerfectStorm 系列工具进行收集并创建的,它包含了常规的网络流量以及各类攻击的异常流量。UNSW-NB15 攻击包含了540 044条数据,每条数据都包含了49 种特征,其中包括常规的网络流量以及其他9 种攻击行为(Fuzzers、Backdoors、Analysis、Dos、Generic、Shellcode、Exploits、Worm 以及Reconnaissance)。在本实验当中,我们使用了UNSW-NB15 提供的包含了175 341条数据的训练集,以及包含82 332 条数据的测试集。
3.2 KE-VP 性能分析
我们首先在UNSW-NB15 数据集上进行检测测试,对KE-VP、K-ELM 以及人工神经网络三种模型在区分正常网络行为和异常网络行为方面的性能进行了测试。如表3 所示,我们记录了K-ELM、ANN以及KE-VP 算法在检测任务中取得的Precision、Accuracy、Recall、False-Positive-Rate (FPR)、F1-Score、训练时间等性能指标。
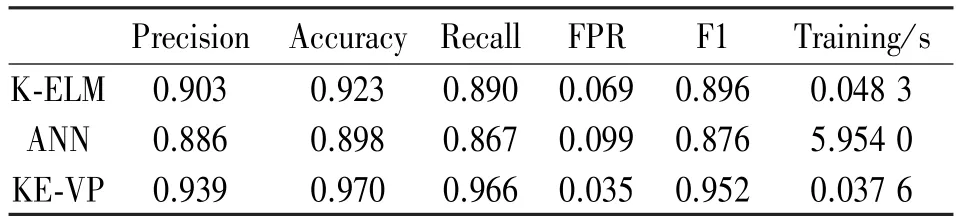
表3 行为检测性能比较
从表3 当中可以看出,相比K-ELM 以及ANN算法,本文提出的KE-VP 算法取得了最高的F1-score(0.952),同时取得了最低的FPR(0.035)。此外在模型训练时间上,KE-VP 相比K-ELM 缩短了近25%且远低于ANN 所需要的训练时间。
在分类阶段,我们剔除了正常行为的样本数据,仅保留恶意行为并对基于KE-VP 算法的分类性能进行了测试。该阶段的训练数据集包括5 000 条恶意行为数据,测试集包括1 000 条恶意行为数据。如表4 所示,我们记录了KE-VP 在分类任务中针对不同攻击手段(包括 Analysis、Backdoor、Dos、Exploits、Fuzzers、Generic、Reconn、Shellcode、Worms)所取得的Precision、Accuracy、Recall、FPR 以及F1-socore 等性能指标。
从表4 可以看出在F1-score 指标上,后门攻击(Backdoor)的分类性能表现稍稍逊于对其他攻击手段的分类性能。但是在整体上,KE-VP 面对各类攻击的分类均表现出了较好的性能。
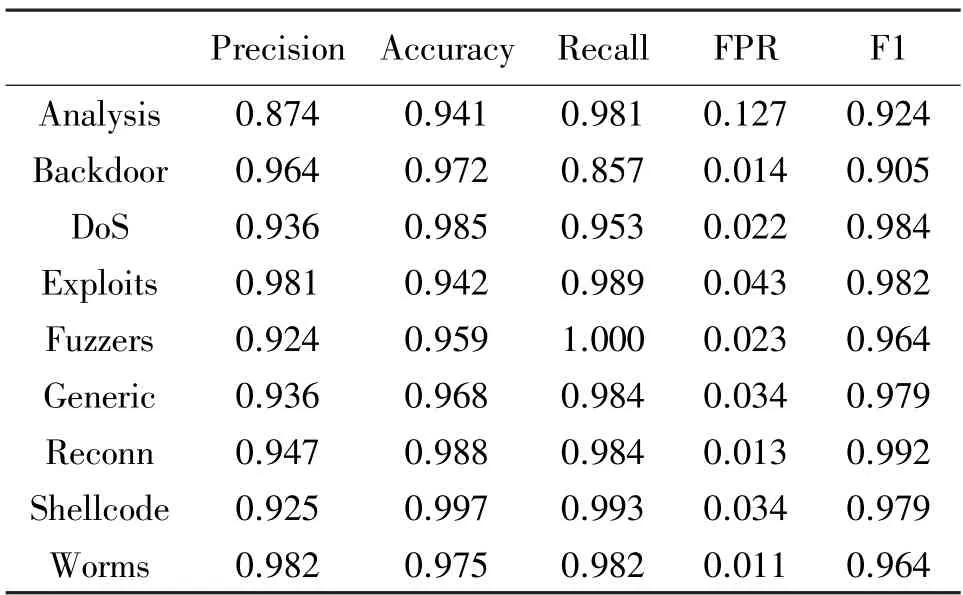
表4 KE-VP 针对不同恶意行为的分类性能
4 结束语
本文首先提出了一种核基极限学习机,通过一个核函数提升极限学习机的收敛速度。其次对粒子群优化算法的粒子速率迭代方法进行修正,提出了一种速率修正的粒子群优化算法。利用速率修正的粒子群优化去训练核基极限学习机,将其应用到云数据库上的网络流量分析,最终实现恶意行为的快速准确识别。经过实验分析,该方法与现有方案相比具备更好的识别精度和模型训练效率。未来将在模型的泛化能力上进行更多的改进。
