基于邻域核密度估计的高速铁路列车正晚点分布模型研究
2022-06-02徐辉章陈军华李崇楠张星臣
徐辉章,陈军华,李崇楠,张星臣,王 超
(北京交通大学 交通运输学院, 北京 100044)
列车正点运行是高速铁路(以下简称“高铁”)运输组织的核心要求之一,是铁路企业对旅客的承诺,兑现与否直接决定高铁运输服务质量。在实际运营中,受到人员、设备和环境等主客观随机因素的干扰,高速列车运行途中不可避免地会偏离运输计划,影响铁路客运服务可靠性和准时性。文献[1]规定“按图定时分早点或正点到达时,统计为正点;否则统计为晚点”。在不失严谨性的前提下,本文将列车实际到达时刻早于图定到达时刻记为列车到达早点,等于图定到达时刻记为列车到达正点,晚于图定到达时刻作记为列车到达晚点,正晚点研究在下文记为早晚点研究。掌握不同列车到达早晚点时长下对应的分布规律,并将之考虑在运行图编制过程中,是提升高铁运输服务质量的必要前提。列车运行实绩数据表明,在高铁实际运输生产过程中,列车早点到达的现象绝非偶然,甚至普遍多于正点和晚点,早点时长分布的研究应得到重视。实际上,某时段(或某列车)早点现象发生,表明该时段(或该列车)所对应的运输计划有足够的储备能力,在遇到特殊扰动时,可合理利用储备能力调整列车运行。一般情况下,可将列车早点状态视为储备能力未合理利用的表征[4]。早晚点研究有利于开展铁路站场运营管理和能力利用研究,有利于分析处理铁路运输管理模型中的延误信息,同时有利于设置车站仿真模型的输入输出。
在理论研究方面,文献[5]分析列车运行图结构,通过理论分析推导出运行图任意一点处晚点概率的计算公式,并给出运行图缓冲时间的合理分配方法。文献[6]通过理论推导,建立一个多项式函数来刻画铁路线路的累计晚点时长。在复杂运输场景方面,学者也利用仿真技术对早晚点时长分布进行了探索。文献[7]通过建立技术站仿真模型,根据预定义的列车到达晚点分布模型,随机产生晚点时间加载至列车图定到达时刻,得到复杂场景的晚点分布影响。文献[8]模拟日本铁路高密度开行情况下的连带晚点,提出一种加快恢复正点的方法。在数据驱动研究方面,学界应用铁路运行实绩数据进行了一系列研究。1996年文献[2]就已基于列车运行实绩数据,建立β分布模型刻画列车区间运行偏离的分布情况。文献[9-10]采集列车运行实绩数据,建立q-指数模型描述列车晚点分布,并应用超统计理论解释模型机理。文献[11]研究京沪高铁列车运行实绩数据,给出列车实际区间运行时长和停站时长的分布模型。文献[12]收集中国东北地区高铁的列车实绩数据,研究列车运行扰动源和列车晚点的统计特性,建立零截断负二项分布模型来刻画扰动源与晚点列车数量的关系。文献[13]以广州铁路局集团有限公司列车运行实绩数据为基础,分析7种致因下列车初始晚点的分布模型,发现对数高斯分布效果最优。文献[3]收集瑞典两个货车调车场的发车实绩数据,发现对数高斯分布模型可以合理描述货物列车发车时刻偏离的规律。既有研究多着眼于研究铁路晚点的时长分布,对列车偏离计划的两种状态(早点和晚点)同时进行的研究较少。
本文采集京沪高铁列车运行实绩数据,建立以邻域搜索算法获取带宽的核密度估计(KDE)模型探究数据的统计特性,发现不同车站的早晚点时长分布规律。为全面评价模型的拟合效果,将建立的邻域KDE模型与其他常见参数化模型及两种常见带宽选取方式下KDE模型进行拟合效果比较,获得车站列车到达早晚点分布的适宜模型。本文邻域KDE模型效果优于参数化模型分布效果,同时优于其他常用KDE模型。
1 模型与算法
基于实绩数据的既有研究大多需要一些较强的假设,即假定样本数据服从某一先验的参数化模型,缺乏足够的理论分析去证明这一假定的合理性,实绩早晚点数据往往数量庞大、结构复杂、涵盖丰富的信息,难以找到一个能够将实绩数据进行合理刻画的参数化分布模型。此外,调整和标定模型的参数也是一个极有挑战性的难题。而核密度估计(KDE)作为非参数估计模型,并不需要有关数据分布的先验基础知识,从数据本身特征出发建立模型,擅长对复杂系统内时间偏离等物理量的数据分布描述,在多个领域得到广泛应用,如能耗评价、列车牵引力概率分布、交通流速度分布等[14-16]。
然而,KDE模型的带宽取值往往基于经验公式,拟合的准确性难以保证,故本文在传统KDE模型的基础上提出一种邻域搜索算法,能够获得比传统经验公式更佳的带宽。本文构建的KDE-ND可用于描述高铁列车早晚点分布。
1.1 KDE
与传统的参数化模型不同,KDE模型不需要数据分布的先验知识,充分利用样本数据自身信息,采用平滑的核函数来拟合观测到的数据点,具有更优的拟合效果。因此,为真实反映高铁列车早晚点时长的概率分布,采用非参数估计方法中的KDE。它有两个要素:核函数K(·)与带宽h,在给定样本数据时,确定核函数与带宽就确定了KDE模型。KDE的表达式为
(1)
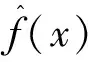
KDE有多种核函数供选择,高斯核函数因为数学性质优良、形式简单、使用方便的特点,为学界最为广泛使用,故采用高斯核函数建立模型。高斯核函数为
(2)
将式(2)代入式(1),得到高斯核函数的KDE模型为
(3)
式(3)中的带宽仍为未知参数,它反映了KDE曲线整体的几何形态,以及控制KDE密度函数的平滑程度。带宽越大,KDE曲线会更“矮胖”,函数峰值会更小,曲线也会更光滑;带宽越小,KDE曲线会更“高瘦”,函数峰值会更大,但曲线可能不太光滑。所以如果带宽过小,核函数叠加后的KDE曲线会过于陡峭;如果带宽过大,那么KDE曲线会过于平缓,掩盖了很多样本数据的信息。同时,带宽对KDE模型拟合的准确性有很大的影响,直接决定了KDE的拟合质量。因此,为KDE模型选择合适的带宽至关重要。
作为核密度估计的核心,众多学者相继提出了最优带宽的确定方法,如Silverman带宽选取法与最小二乘交叉验证(LSCV)带宽选取法。这些方法将带宽选择视为一个优化问题,得到的带宽值多为局部最优解,通常需要进行多次对比实验才能确定合适的值,故本文提出一种新的带宽选取方法,即基于邻域搜索算法(Neighborhood Descent,ND)来确定更优的带宽。这3类方法会得到3种不同的核密度估计模型,为方便分析,将这3种带宽选择方式下的分布模型简记为KDE-Silverman、KDE-LSCV和KDE-ND。
(1)Silverman带宽选取
Silverman带宽hS为[17]
(4)
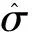
(2)LSCV带宽选取
LCSV带宽hLSCV为[18]
(5)
(6)
式中:j=1,2,…,n。
(3)ND带宽选取
Silverman方法根据固定公式选取带宽,可以快速得到较好的带宽值,但该带宽不是描述数据的最优带宽;LSCV方法通过计算交叉预测值的平均值求最优带宽,但该方法随样本量增大求解难度也逐渐增大。本文基于ND提出一种改进的带宽搜索算法——KDE-ND,通过巧妙地构建邻域集合实现快速寻优效果。该算法将LSCV方法求解的带宽作为初始解,基于LSCV方法求得的带宽hLSCV按不同的精度范围生成不同的邻域,算法伪代码如下:
输入: 基于LSCV方法求得的带宽hLSCV
输出: 基于邻域搜索方法求得的带宽hnd
1: 定义局部邻域集合N={h1,h2,…,hn},n=50
hi=hLSCV+random(-0.1,0.1),∀hi∈N
2: 初始解hb=hLSCV
3: repeat
4: Forl=1 tonDo
5://寻找邻域集中最优解h″ ofh′ inN
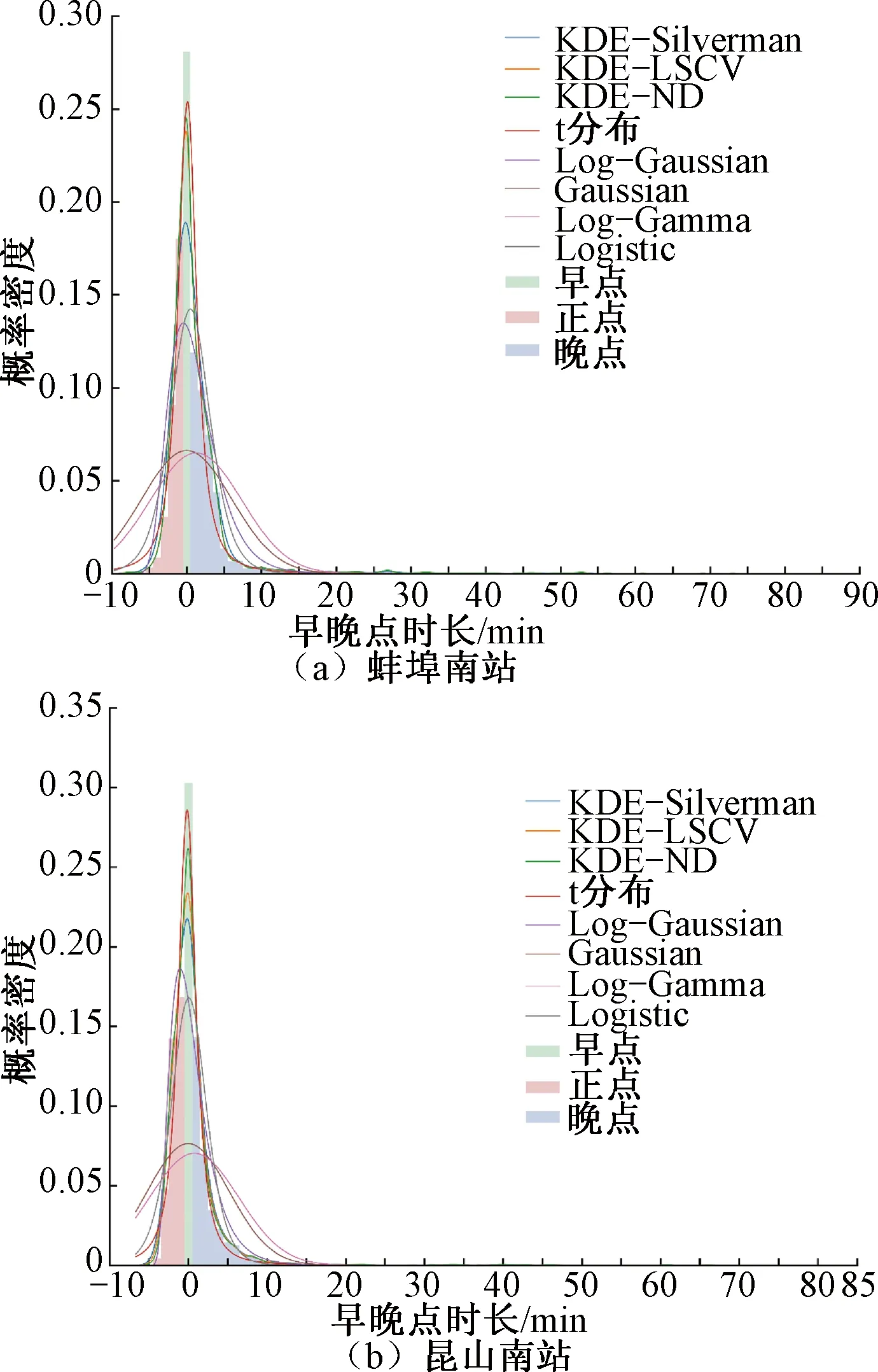
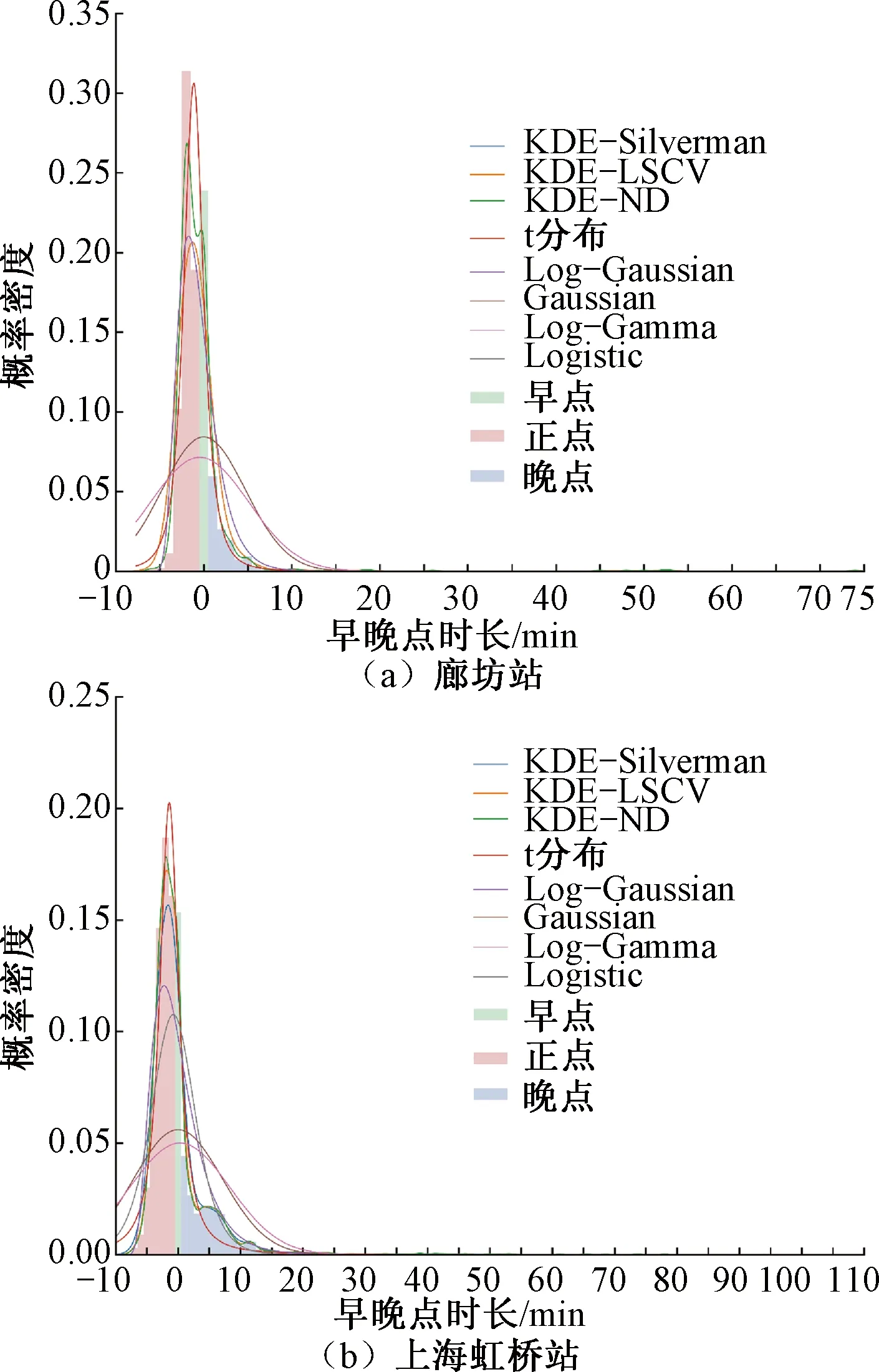
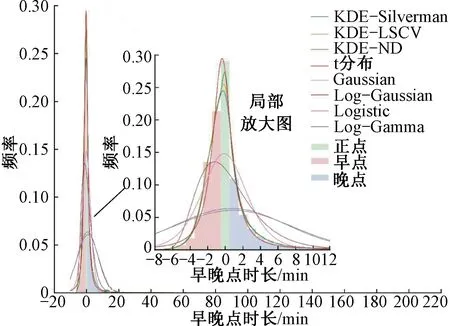
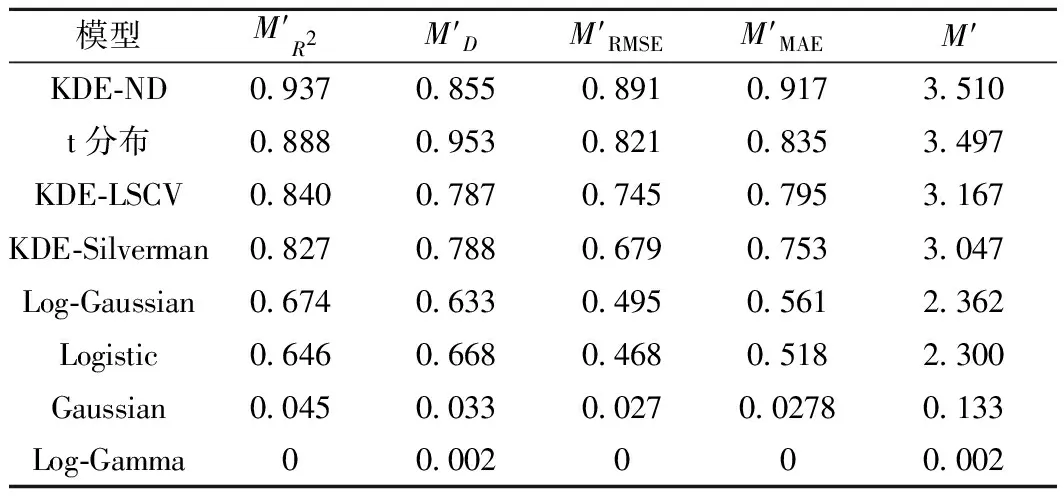
6: Ifg(h″) 7: Otherwisel=l+1 8: 输出hnd=h′ 其中,目标函数g(h)是平均积分平方误差,即 (7) 为与KDE模型拟合效果进行比较,采用如下几类常见的参数化分布模型,包括Logistic分布、高斯分布、对数高斯分布、t分布和对数伽马分布。采用极大似然估计方法来标定各分布模型的参数。各分布的概率密度函数见表1。由于此类分布模型大多要求定义域为正数,为贴合早晚点数据所需描述的正负数均存在的情况,本文增加了分布的位置参数和尺度参数进行修正。 对于模型的拟合效果进行评价可以采用MAE、RMSE等指标,不同的指标在量纲、数量级以及取值倾向(即有的指标是取值越小,拟合效果越好,有些指标则是越大越好)存在差异,对于同一模型可能会得到不同甚至相反的评价结果。为解决上述问题,基于几类单一指标,建立出一种综合评价指标,以全面评价不同模型的拟合效果。本文考虑的单一指标包括: 表1 参数化模型介绍 (1)Kolmogorov-Smirnov检验 Kolmogorov-Smirnov(K-S)检验可确定是否接受分布假设。在K-S检验中,虚无假设(H0)是指两个样本数据服从同一分布,或一个样本数据服从某一理论分布。为确定是否接受虚无假设,设检验统计量D,表示样本的经验累计分布函数(ECDF)和理论分布的累积分布函数(CDF)之间的最大差值,即 D=maxx|F(x)-G(x)| (8) 式中:F(x)为样本数据的ECDF;G(x)为理论分布的CDF。D的值越小,说明理论分布的拟合效果越好。 (2)均方根误差 均方根误差(RMSE)值PRMSE为 (9) (3)平均绝对误差 平均绝对误差(MAE)值PMAE为 (10) MAE的值越小,说明分布模型拟合效果越好。 (4)决定系数 决定系数R2为 (11) (5)综合评价指标 基于式(8)~式(11)的4项单一指标,建立一种综合指标。由于指标的量纲、数量级不一致,应当对单一指标进行预处理,本文采用归一化处理 (12) 式中:Mk′为归一化后的指标;Mk为原始指标;Mkmax、Mkmin分别为原始指标的最大、最小值。归一化后的指标的取值都介于0和1之间,且取值越高说明模型拟合效果越好。将归一化指标相加,定义综合指标M′。对于本文研究,该值越接近4,说明模型的拟合效果越好。 本文高铁列车运行实绩数据源自中国铁路客户服务中心12306网站。数据空间范围为京沪高铁沿线各站,时间范围为2020年某月1日至30日。实绩数据包含列车车次、列车到达车站、图定到达时刻、实际到达时刻等信息,数据以整分钟为单位。为进一步分析,获取的原始实绩数据需要进行数据预处理,包含筛选出在京沪高铁线路运行列车的数据(京沪本线车与跨线车数据),删除与实际情况相悖的错误数据等。 实绩数据以整分钟作为单位,原始数据条目总数为213 327,预处理结束后107 168。其中,由于3个车站信息不完全,不纳入样本集合,对京沪高铁其余20个车站进行描述和分析。 早晚点数据可通过实绩数据计算得到:由列车实际到达时刻与图定到达时刻作差计算出到达偏差量。当偏差量大于0时,表示列车到达晚点;当偏差量为0时,表示列车到达正点;当偏差量小于0时,表示列车到达早点。偏差量的绝对值可以反映各状态持续时长。 为研究实绩数据的统计特性,绘制描述性统计图,见图1。图1(a)为早晚点时长散点图,可以看到大部分观测点的时长值落入0的附近,说明高铁面临的早晚点大部分为小时长。部分分散较远的观测值晚点比例较大,分布较为松散,早点观测值分布密集,多集中在早点1~8 min。图1(b)将图1(a)中的早晚点散点图转换为频数分布直方图,由直方图的轮廓形态可以直观看出,京沪高铁全线整体的数据呈现偏态分布,但通过对各车站分布描述发现,不同车站分布存在明显差异,直接刻画京沪高铁全线数据分布难以描述所有车站的分布效果。 图1 早晚点时长描述性统计图 图2为车站早晚点比例分布图。由图2可知,京沪高铁两端的终到时刻早点到达频率普遍高于晚点,整个运输过程存在较好的赶点能力。不同车站正点频率基本持平,运输秩序较为稳定。晚点比例方面,不同车站差异不同,线路中间的车站具有更大的晚点比例。 图2 各车站早晚点比例分布 图3为京沪高铁各车站早晚点分布示意图,由图3可知,车站的早晚点分布情况存在较为明显的差异。从分布图形的峰值来看,大部分车站呈现单峰分布(如北京南站、沧州西站、德州东站等),但也有部分车站呈现双峰分布(如廊坊站、滁州站等)。单峰分布的峰值都是在横坐标为0即正点处取得,与高铁列车大部分准时正点到达的事实相符,而双峰分布中,除去正常的原点处取得峰值外,还可能在晚点状态下存在一个峰值,说明该类车站的列车会于某晚点时长下集中到达,应当采取适宜的晚点管理手段消解该峰值。从分布图形的尾部特征来看,靠近线路端点的始发终到站具有厚尾分布效应,而分布于线路中间的其他车站具有截断分布特征,分布图形的尾部不明显。图3中各个车站实绩分布情况的差异性说明,全线数据分布模型还不足以描述列车在各车站实绩到达情况,无法捕捉各个车站分布特点的差异性。因此需要对每一车站单独进行研究。另一方面,常规的参数化分布模型可能无法准确描述全线每一车站的情况,需要使用一种只依赖数据分布特点,无需先验知识的非参数化分布模型进行早晚点分布情况刻画。KDE作为一类应用广泛、理论完备的非参数化模型,尚未应用于铁路运输领域的早晚点分布刻画。因此,本文基于核密度估计模型,针对京沪高铁不同车站分别构建早晚点时长分布模型,并利用综合拟合优度指标评价各车站模型的拟合效果并与全线整体拟合效果作对比。 图3 各车站早晚点分布 将提出的模型算法应用于京沪高铁的实绩数据,并利用综合评价指标用以全面评价和比选模型。 京沪高铁部分车站在不同分布模型下的拟合结果见图4、图5。图4(a)和图4(b)是以蚌埠南站和昆山南站为例的单峰型分布,类似的车站还有北京南站、沧州西站、德州东站等,数据均服从正偏态分布。根据图4可以直观看出,KDE模型能够准确描述数据的分布,且在三类KDE模型中,KDE-ND的拟合效果更加突出。 图4 典型车站拟合结果分布图(单峰型分布) 图5(a)和图5(b)分别是以廊坊站和上海虹桥站为例的双峰型分布,类似的车站还有廊坊站、滁州站、定远站等。KDE-ND模型直接利用平滑的高斯核核函数拟合样本数据,可贴合双峰型分布的数据形态。而t分布等参数化模型在双峰型分布中难以匹配多个曲线的峰值。对比图5(a)和图5(b),也可看到数据的分布特点在不同车站有所不同,对于精细化客运需求的运营组织优化彰显必要。 图5 典型车站拟合结果分布图(双峰型分布) 京沪高铁全线实绩数据分布及拟合情况见图6。全线的分布呈现单峰右偏厚尾分布特征,对比图5与图3可知,无法保证全线分布能够与任一车站的分布完全匹配,甚至存在较为明显的差异。例如,滁州站呈双峰分布,与图5存在明显差异。另外,KDE系列模型和t分布描述全线分布效果较好(R2取值均在0.97以上),其余模型无法准确拟合峰值或尾部等特征,与实绩数据的情况差距较大。 图6 京沪高铁全线实绩数据分布及拟合 京沪高铁车站的KDE与参数化模型拟合优度的箱线图见图7。由图7可见,KDE-ND模型在PRMSE、R2和PMAE指标下均为最优,说明KDE-ND的拟合效果最优。除去KS外,t分布在3项指标下表现仅次于KDE-ND,说明参数化模型中t分布也具有较好的拟合效果。另外,针对不同的指标,模型之间的排序结果也有所不同,证明建立综合指标来全面评价模型拟合优度是有必要的。 图7 分布模型拟合优度箱线图 不同模型的拟合优度指标见表2,指标进行了归一化处理并依车站计算平均值后列入表中。从左开始第2到5列为单项拟合优度指标的取值,第6列为综合拟合优度指标的取值。KDE-ND具有最优的拟合效果,且优于另外两类KDE模型。其中,KDE-ND的综合指标取值为3.599(满分为4),而KDE-LSCV和KDE-Silverman的综合指标取值分别为3.167和3.047,均低于KDE-ND。另外两类KDE模型的综合指标优于t分布以外的分布模型,证明KDE模型普遍优于其他参数化模型。Log-Gamma和Gaussian分布的拟合优度取值情况很差,应当在实际应用中舍弃。 表2 分布模型归一化拟合优度指标和综合拟合优度指标 京沪高铁沿线各站的最优分布模型见图8。由图示可知,沿线大部分车站都适宜使用KDE-ND模型进行列车运行情况拟合,其次是少量车站适用于t分布模型进行早晚点分布描述。实绩数据呈近似对称单峰分布的车站适用于t分布刻画,而实绩数据呈双峰、厚尾、或者非对称复杂分布的车站则适用于KDE-ND模型。观察两类最优模型的车站在线路上的分布情况,发现最优模型为t分布的少量车站集中分布于线路的中间部分。 图8 京沪高铁沿线各站的最优分布模型 图9为京沪高铁沿线各站早晚点分布拟合与关键参数取值。根据图9,KDE-ND模型仅采用带宽bnd即可实现分布的描述,而t分布需要v、loc和scale 3个参数才能完全确定。说明KDE-ND模型更易于标定,在实际应用中的可扩展性更强。另一方面,t分布无法刻画廊坊站等带有双峰分布的实绩数据,并且很难捕捉线路端点车站厚尾效应的数据特性。此外,由于t分布为严格对称分布,所以不适用于早点晚点比例不均、分布不对称的情况。而KDE-ND模型因其强大的拟合能力可以很好地弥补t分布应用的局限性,刻画更加广泛和复杂的早晚点分布特征。在KDE-ND模型描述的车站中,带宽bnd取值范围为0.392~1.177,带宽变化范围较大。相邻车站的带宽取值可能比较接近,如定远站(0.436)和滁州站(0.430),也可能取值差距很大,如常州北站(1.211)和无锡东站(0.492)。除丹阳北站、沧州西站、枣庄站、常州北站与苏州北站带宽取值高于1,其余车站带宽取值均在0.5附近。观察发现,丹阳北站、沧州西站、枣庄站、常州北站与苏州北站列车到达早晚点分布形态均较为对称,核密度估计选取带宽时, 0.3~1.2附近带宽取值差别不够明显,但这类车站的列车到达早晚点数据可以通过t分布很好地拟合。对于其他存在单峰、多峰等情况的车站,t分布拟合效果则略显不足。 图9 京沪高铁沿线各站早晚点分布拟合与关键参数取值 针对高速铁路列车早晚点时长分布拟合问题,提出一种基于KDE-ND的概率分布模型。主要研究结论如下: (1)采用2020年某月京沪高铁列车运行实绩数据为数据源,对数据进行预处理和描述统计。统计结果显示,不同车站的数据分布有所差异。因此针对不同车站分别进行研究,考虑到既有研究鲜有对早点时长分布的考虑,或将早点和晚点割裂开来分别研究,为全面评价列车偏离计划运行的不同状态,本文构建同时包含早点与晚点到达信息的时长分布模型,从整体性、全面性的角度分析列车偏离计划运行不同状态的分布情况,可为仿真、车站到发线优化等研究提供支撑。 (2)提出KDE-ND来表达早晚点分布模型,引入两种经典带宽选择方法(Silverman和LSCV方法)的KDE模型及几种常见的参数化模型进行对比研究,数值试验的结果表明,3种KDE模型拟合效果优于参数化模型,同时本文提出的KDE-ND相比于其他KDE模型及参数化模型具有更好的拟合效果,可以高效地捕捉列车运行偏离的规律,当带宽取值在0.5附近时,模型可以取得较好的拟合效果。 (3)提出列车早晚点分析综合评价指标来全面考察各模型的拟合效果,该指标解决了具有差异性的不同单项指标下模型拟合效果排序不一致的问题,保证了评价指标的科学性,计算的综合评价指标可用于描述分布函数适配程度。 本文使用的数据类型主要为早晚点时长,由于晚点致因、客运量、天气、司机驾驶行为、调度调整策略等其他信息稀缺,早晚点分布规律与影响因素之间的关系需进一步探究。如果能够获取早晚点致因及更多高铁线路的早晚点数据,则可以建立高速铁路成网条件下考虑致因的早晚点时长分布模型,进一步加强模型的适用性,支撑早晚点预测模型的构建,为高铁运输组织的理论研究和工程实践提供帮助。 研究成果有助于理解高速铁路车站列车到达分布规律,为列车延误预测提供基础,同时为高速铁路运输实时管理研究提供借鉴;其次,可将研究得到的高铁列车早晚点分布模型用于列车运行仿真的参数标定和仿真输入输出,提高仿真质量,开展到发线分配优化策略研究;最后,由于列车早晚点分布会影响不同时段车站能力占用情况,研究成果有助于铁路运输能力利用优化,对于精细化高铁运营管理有指导意义和应用价值。1.2 参数化分布模型
1.3 综合评价指标

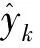

2 数据采集与整理



3 数值实验与分析
3.1 拟合结果
3.2 检验结果



4 结论
