一种1750A指令集仿真软核设计与验证
2022-06-01李士刚祝周荣
李士刚,祝周荣
(海装驻上海地区第六军事代表室,上海 201109)
0 引言
国产P1750A的研制成功并大量投入使用,规避了1750芯片完全依赖进口的风险,使得MIL-STD-1750A指令集已经成为我国星载弹载计算机常用指令集之一,它提供多种数据类型,包括16位、32位整数和32位、48位浮点数,以及直接寻址、间接寻址、立即寻址、短变址、长变址寻址等十三种寻址方式,指令类型有130种。
通常星载弹载计算机的结构是CPU+FPGA结合的方式来控制各个存储模块和IO模块,如看门狗电路、存储器控制功能(包括EDAC)、总线接口芯片控制电路等。CPU软件和FPGA产品都有程序的概念,都要进行专门的验证和测试,现有的测试方式通常是将CPU软件和FPGA产品分开测试,CPU软件在硬件平台上进行测试,而FPGA产品只能通过仿真器对CPU时序的读写IO时序和读写SRAM时序进行单一模拟,但是实际CPU时序会根据各种指令集产生不同时序和不同时序组合,因此现有测试方法仅能满足简单测试用例的实施,缺少通用性,时序产生的随意性和主观性较强,不能真正反映实际CPU时序的运行情况,从而导致FPGA内部设计隐患无法发现。因此需要有一种测试方法,既能实现实际意义上CPU时序的组合,又能进行某些安全性、强度、单粒子翻转等异常测试激励故障注入,从而实现软硬件联合仿真,并完全满足测试覆盖率要求。
本文提出一种CPU+FPGA的仿真模型搭建方法,设计了一种精简1750仿真软核,实现了基于1750A指令集架构微处理器仿真软核和FPGA软硬件联合仿真验证方法。该精简1750仿真软核能在执行星载弹载CPU程序的过程中,恰当产生该微处理器各引脚输出信号、并根据该微处理器各引脚输入信号(如中断等)激发程序正确执行相应的响应处理程序,实现真正意义上的软硬件联合仿真。
1 通用仿真模型搭建框架
该通用仿真模型参照硬件实际情况进行构建,同时还应建立PROM的仿真验证模型和CAN总线控制器的仿真验证模型,就像搭建一台单机一样,将FPGA和CPU仿真软核的各个信号按照硬件接口图或者原理图的连接方式进行连接,实现数字化的仿真验证平台,如图1所示。模拟整个硬件环境,主要验证整个软硬件系统包括FPGA产品和CPU软件的实现功能,相当于对装有正式CPU软件的单机进行测试,从而保证整个系统功能的正确性。验证人员需要将CPU软件转换为二进制执行代码,载入到PROM中运行。
测试内容不仅包括通常的应用功能,如接口模块的控制和应用层协议帧的验证。更重要的是还可以进行空间寄存器单粒子翻转、空间状态机单粒子翻转、中断信号异常等在硬件上无法 模拟的故障安全性验证等测试。此外,由于仿真模型可以记录下内总线的所有操作记录,因此可以对操作记录进行分析,并将该操作记录和PROM中的程序指令地址中的指令数据进行比对,从而可以得到目标码覆盖率结果。
利用该通用仿真模型进行软硬件协同仿真验证不仅可以进行RTL级仿真验证(前仿),还可以进行动态时序仿真验证(后仿),将不同温度和电压工况下的FPGA的电路延时放入仿真中进行执行运算,与真实系统更为接近,对各接口的时序测试更为精准。
如图1所示,基于1750A指令集软核的FPGA第三方验证通用激励模型包括起主动控制作用的MIL-STD-1750A指令集架构微处理器软核、提供系统时钟和复位电路等仿真输入模块、用于仲裁总线控制的CAN总线控制器仿真模块、系统正常信号监控仿真测试模块、存储数据的SRAM存储仿真模块和用于抗单粒子翻转EDAC仿真测试模块、中断滤波仿真测试模块、用于调试的RS422串口协议仿真测试模块和用于存放二进制码星载程序的PROM存储仿真。显而易见,精简1750仿真软核在该仿真激励模型中起了至关重要的作用,其功能包括:能够依据MIL-STD-1750A指令集架构规范完成指令功能,能够执行P1750A典型应用系统的工作流程,能够进行多种典型的故障注入和相应调试,能够进行内部寄存器和外部存储器的任意单粒子翻转场景设置,能够通过用户界面程序进行的配置和调试操作。
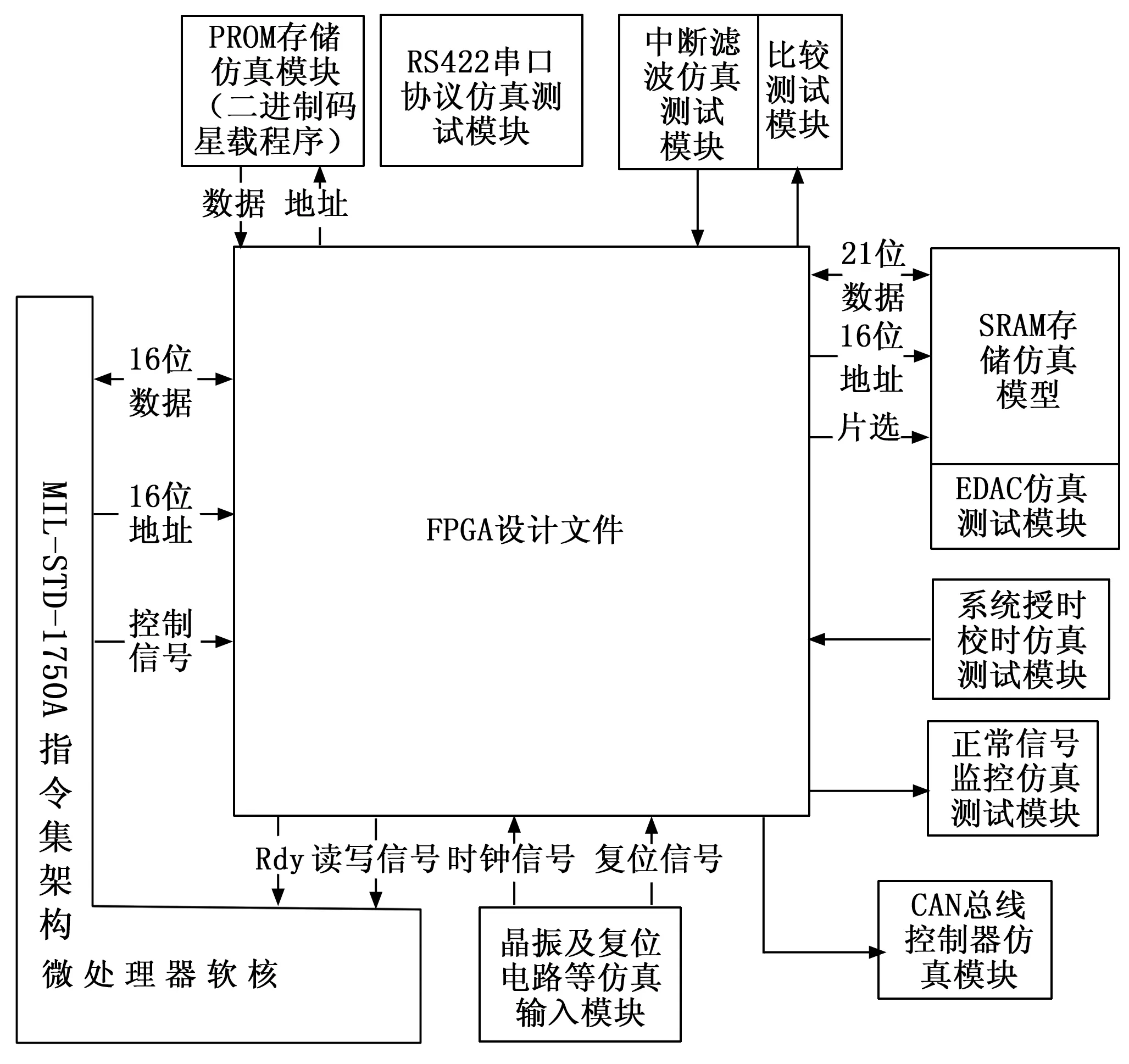
图1 基于1750A指令集软核的FPGA第三方验证通用激励模型
2 仿真软核内部体系结构
该仿真软核参照P1750A芯片,使用32位内总线结构,由3部分总线构成,如图2所示,连接一个24 bitx24 bit的乘法器(Multiplier)、一个32位的运算器(ALU)、一个32位移位网络(shift network)、一个多端口寄存器文件控制器(Registerfile)、一个状态记录模块(Flags)和一个地址计算单元(Address generator),此外,还内置了一个时序生成模块(Sequencer)、一个外围IO设备控制模块(IO control)和一个存放微指令代码的ROM(Microcode ROM)。其中,Sequencer内部主要是一个状态机,由系统晶振控制时钟产生处理器时序和控制信号。Microcode ROM是一个可存放1 408个64 bit字的小ROM,可用于存储初始程序、中断响应、总线响应、指令预取和自测试程序等。
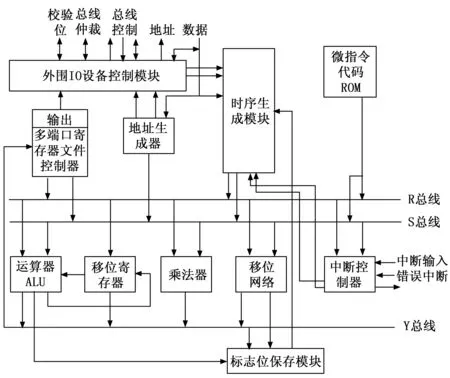
图2 精简1750A仿真软核的内部体系结构
3 关键技术及设计方法
3.1 中断处理设计
中断处理的完整流程如图3所示,其过程概括起来可分为锁存、检测、跳转和返回四大步骤。以下将逐一阐述各个步骤的具体流程。
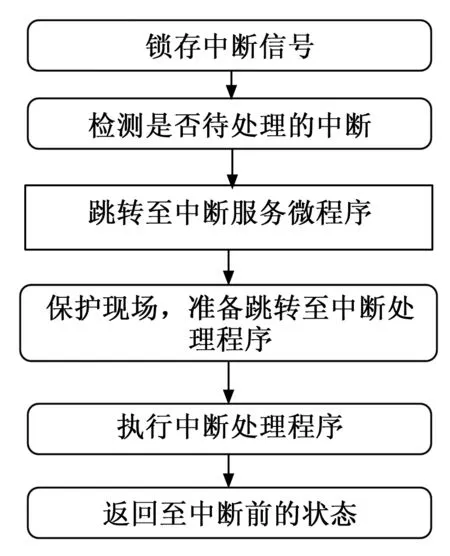
图3 中断处理过程
1)锁存:
在不同的时间节点将各个信号在锁存至中断悬挂寄存器或故障寄存器,具体实现如表1所述。

表1 锁存实现
2)检测:
检测中断的时间节点主要为每条指令执行结束后、下一条指令开始执行前。此时检测优先级判断逻辑给出的中断请求信号,若为有效则自动调转至中断处理服务微程序。由于1750A标准要求move等长指令在各个子周期间允许被打断,所以对此条指令须单独处理。不仅要在指令过程中检测中断的发生,还要在跳转时将返回地址修改至当前move指令的地址。
3)跳转:
跳转进行了表2两种情况处理方式设计。

表2 跳转方式
4)返回:
中断处理程序通常由LST指令返回。该指令会自动装载跳转前的处理器配置和状态,将IC指向跳转前的地址,并自动装载指令流水线。根据1750A标准的要求,LST执行失败会导致中断不能返回,进而继续执行下一条指令。CPU的默认行为与此相符,不需要特殊处理。
3.2 浮点运算单元
1750A指令集共定义了两种格式的浮点数:普通浮点数(32位双字)和扩展精度浮点数(48位三字),以及6种浮点数的操作类型,包括加减乘除以及和定点数的相互转换。浮点运算单元依据FPU指令集中规定的运算方法对浮点数进行计算和处理,图4描述了FPU运算逻辑的工作原理,送入FPU的操作数首先经过预规格化后根据不同的操作类型传送给对应的运算单元,由于加减法和乘除法对操作数的规格化要求不一致,故采用了独立的规格化模块。运算结果经规格化和舍入后输出。浮点数的比较运算与定点数不同,无需经过实际的减操作,而直接由逻辑引脚给出比较结果。若操作数不合法或不符合指定的运算规则,FPU模块会产生异常。这些异常大多由异常模块给出,而除数为零的异常由除法运算器给出。
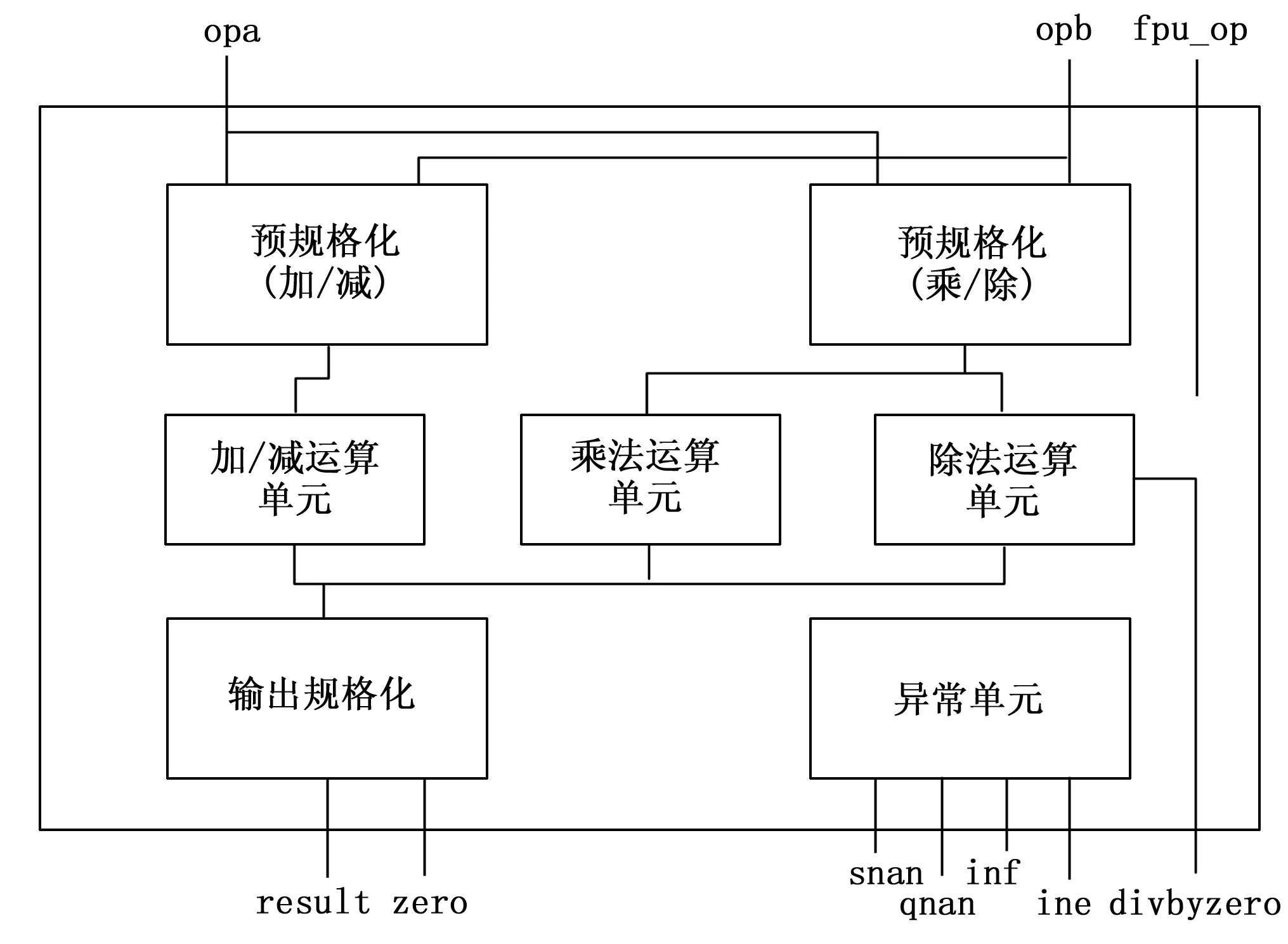
图4 浮点运算单元模块工作原理示意图
图4所述的浮点运算单元模块包括加减法、乘法和除法运算功能,且各自独立,不用的运算单元能够关闭通道,从而提高仿真验证效率。
3.3 故障注入机制设计
通过调研当前各型号的常见错误故障,实现如表3述类型的故障注入,进一步完善软核的功能。

表3 故障注入实现类型
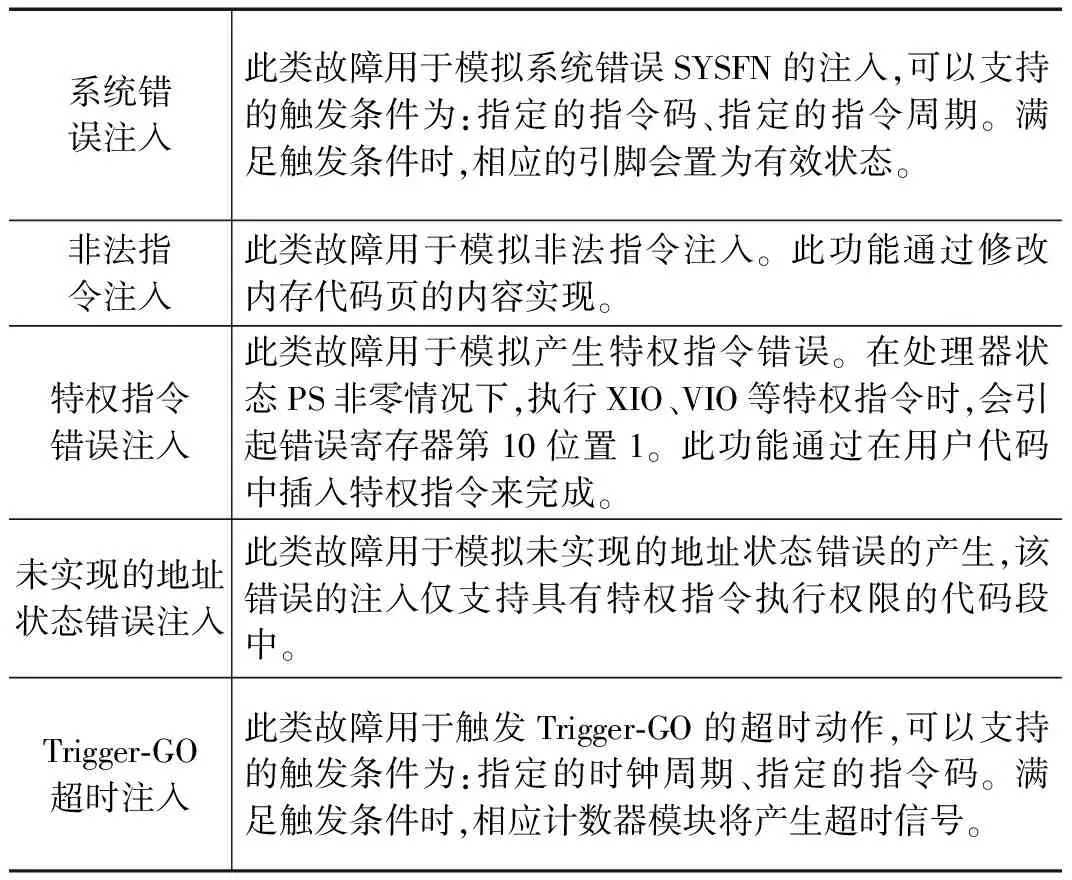
续表
在要进行故障注入的时刻点,先读取要注入故障的寄存器和信号线当前结果,然后通过写force强制语句强制寄存器和信号线为相反的结果,然后过1微秒后,释放强制,从而实现故障注入。
3.4 图形控制界面
为方便系统和用户之间进行交互和信息交换,以图形的方式提供一套软核控制机制,提供软核初始状态设置、故障注入、内存管理、调试断点设置、单步执行等功能,主要分为3个部分:顶层配置、内存管理和故障注入,如表4所述。

表4 图形控制界面设计部分
4 仿真验证和结果分析
4.1 仿真模型构建
项目组挑选了某卫星型号项目计算机CPU板FPGA和遥测采集FPGA进行仿真验证,目前主流的仿真验证方法一般分为2步:1)先是通过仿真器对CPU时序的读写IO时序和读写SRAM时序进行单一模拟先对计算机CPU板FPGA进行仿真验证,无法运行真正的CPU程序,而且故障注入方式单一,不能真正反映实际CPU时序的运行情况,不能体现实际外部RAM的运行情况,因此无法发现计算机CPU板FPGA内部设计较深层次隐患;2)观察计算机CPU板FPGA输出时序,由于CPU时序的读写IO时序和读写SRAM时序本身就是模拟的,具有不确定性,因此对遥测采集FPGA的输入激励就存在错误的可能性,从而造成遥测采集FPGA测试的不确定。此外,这种主流仿真方法只能进行FPGA产品的语句、分支和状态机覆盖率,对更为关注条件覆盖率和甚至是翻转覆盖率的测试无法达到测试要求。
利用该1750仿真软核搭建仿真激励模型将计算机CPU板FPGA和遥测采集FPGA联合起来能够很好的解决上述2个问题,既能实现实际意义上CPU时序组合的精准输出,还能联合构建2个FPGA同时进行仿真,从而实现系统级软硬件联合仿真,此外还能进行RAM运行情况测试、单粒子翻转等异常测试激励故障注入,实现正确的计算机CPU板FPGA和遥测采集FPGA仿真波形,最终满足各种代码测试覆盖率要求。激励模型顶层连线情况如图5所示。
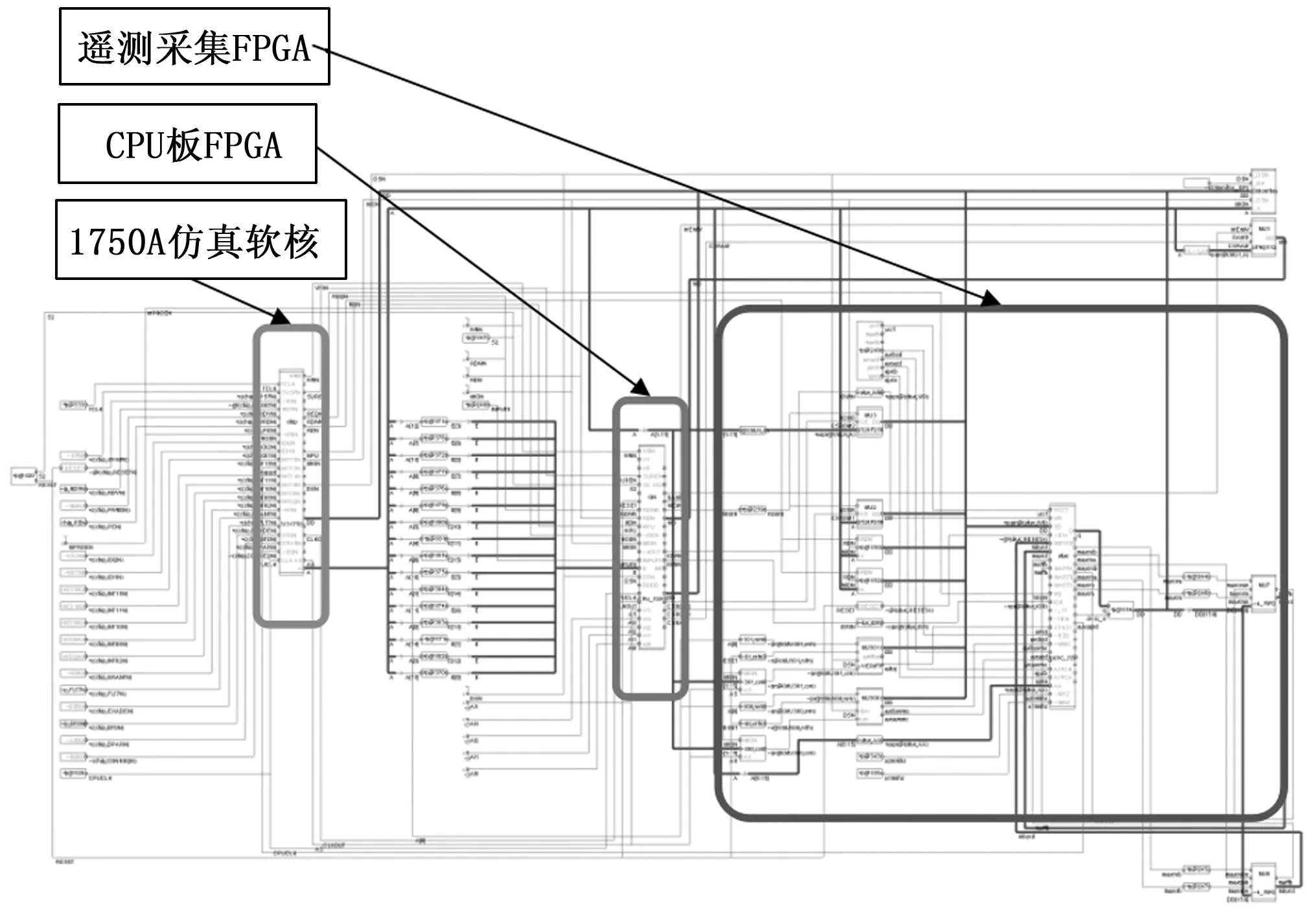
图5 1750A、CPU板FPGA和遥控遥测FPGA连线
如图5所示,该系统联合仿真模型主要由1750A仿真软核、CPU板FPGA和遥测采集FPGA三大模块组成。其中1750A仿真软核运行星载程序产生总线时序给CPU板FPGA。CPU板FPGA作为1750A仿真软核和遥测采集FPGA的桥梁,进行总线时序转换,此外,还完成图1中通用激励模型的功能。遥测采集FPGA实现该系统实际和外部硬件接口的遥控遥测指令控制。
激励模型构建完成后,执行了一段RAM翻转检查的程序。该段程序通过my_printf()函数调用XIO命令向0x0100端口写ASCII码,prints ()函数用于构造错误信息字符串,程序主函数调用my_printf()输出一个内容为“RAM TEST ”的字符串,标志着程序开始执行,然后将FIELD_BEGIN(0xD000)和FIELD_END(0xD05C)之间的一段RAM区域初始化为某个数值(0xF5A9),再将该区域内的值读出并与期望值比较,若发现不同,则调用my_printf()打印类似“<
4.2 RAM区域读写测试
启动图形界面,载入该测试文件程序编译后结果并执行,在执行一段时间后暂停软核,如图6所述。此时切换到Memory标签,如图7所述,可以看到,程序正处于第一个循环,即初始化RAM的阶段,此时0xD000至0xD05C之间的内存区域已经被正确初始化,而0xD05D至0xD0FF之间的区域还未进行初始化。
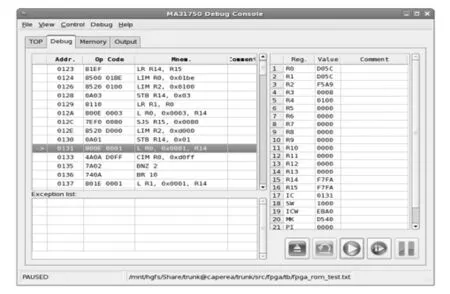
图6 测试文件程序编译暂停结果
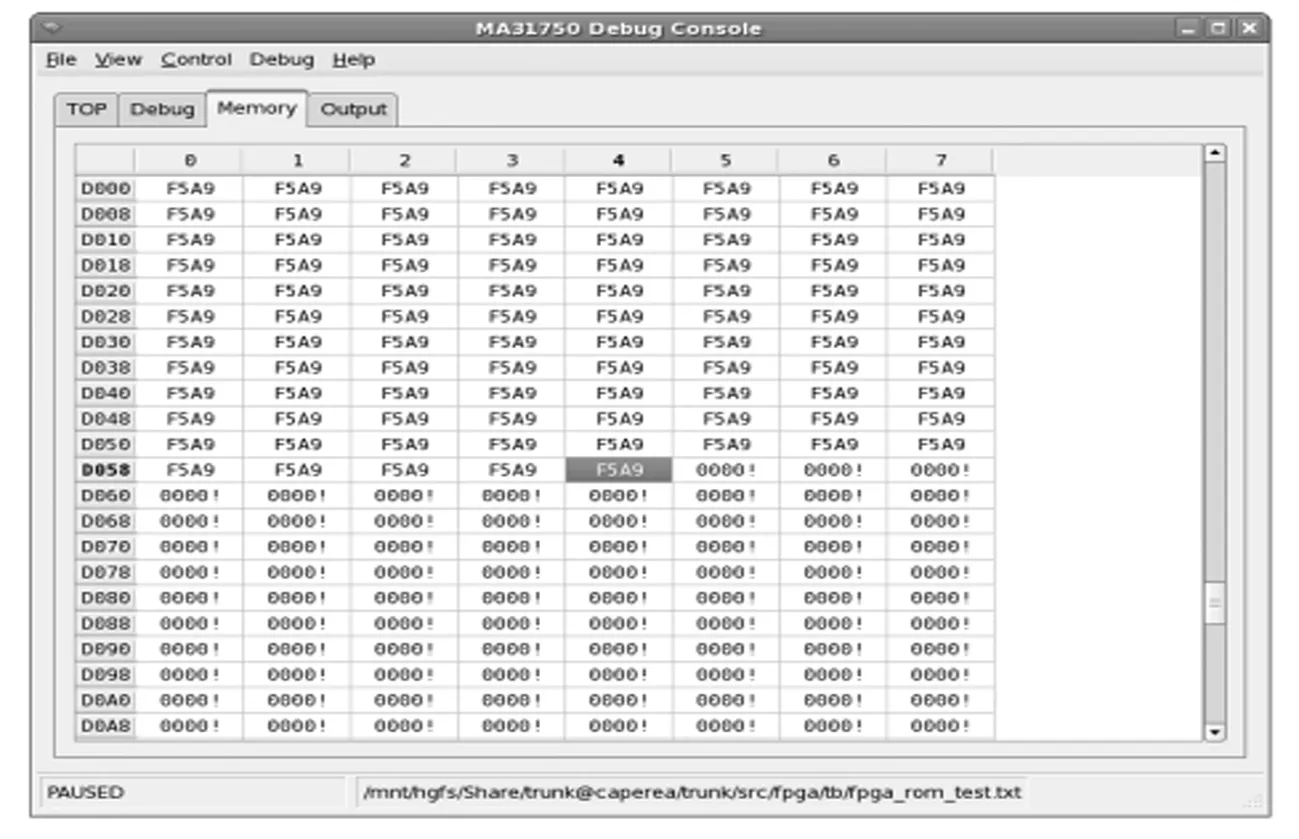
图7 RAM区域读写测试截图
4.3 单粒子翻转注入验证
分别对0xD040和0xD048两个单元做单粒子翻转注入。其中0xD040单元翻转4位,0xD048单元翻转1位,如图8左所示。单粒子翻转注入完后,切换到Debug标签并继续执行,直到整个测试程序执行完毕,重新切换到Memory标签中,检查刚才注入单粒子翻转的两个内存区域。如图8右所示,由于0xD048单元仅注入了一位翻转,此时被内存校验模块自动检测并更正;而0xD040单元,由于同时有4位发生翻转,超出了可修复的最大翻转位数,此单元并未得到修正。

图8 单粒子翻转测试截图
4.4 仿真验证波形分析
根据图5仿真激励模型,1750A仿真软核和CPU板FPGA之间的接口时序测试结果如图9所述,CPU板FPGA和遥控遥测FPGA之间的接口时序测试结果如图10所示。该仿真模型可以很方便进行模块间接口时序的测试。
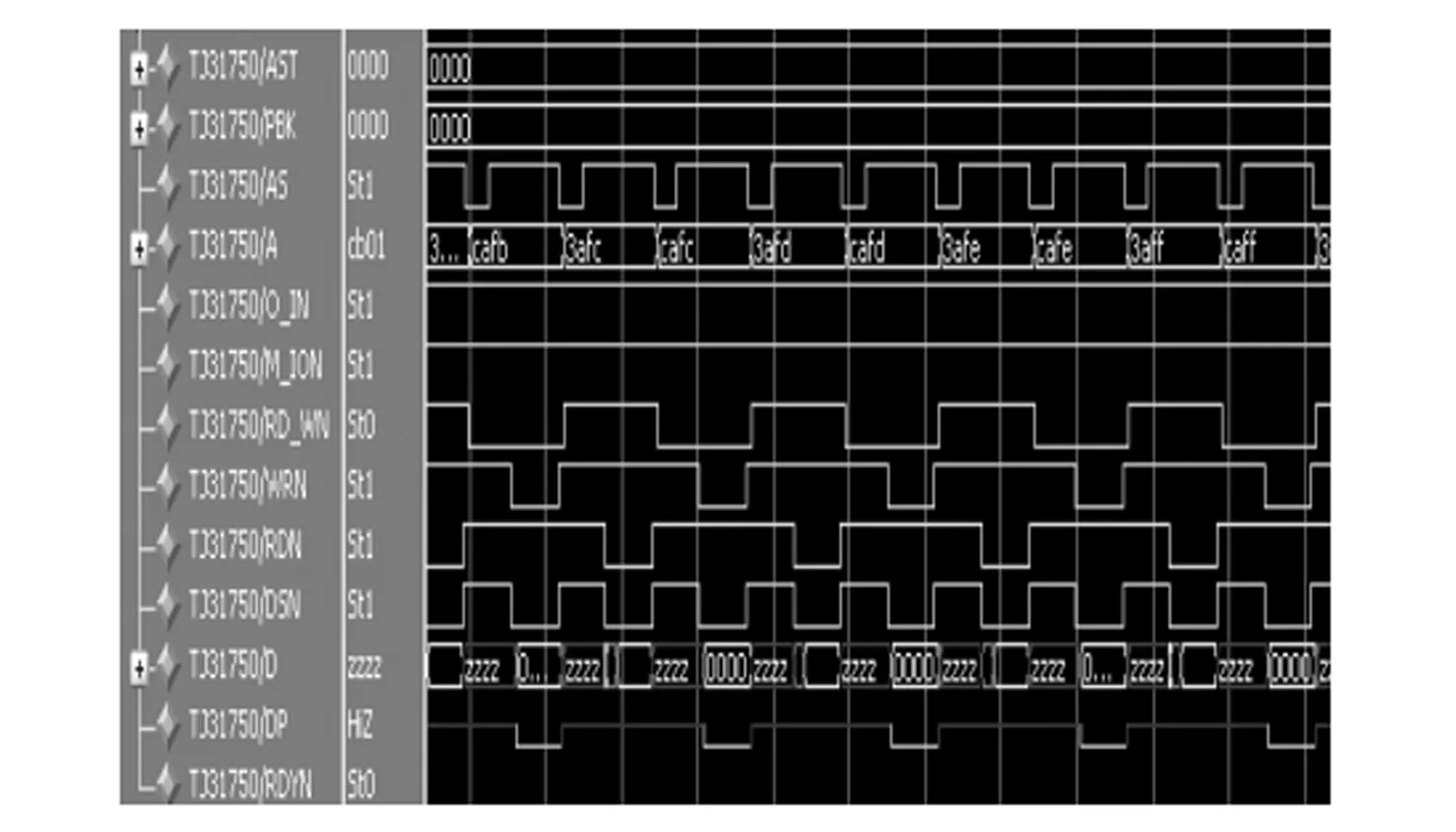
图9 1750和CPU板FPGA协同工作波形
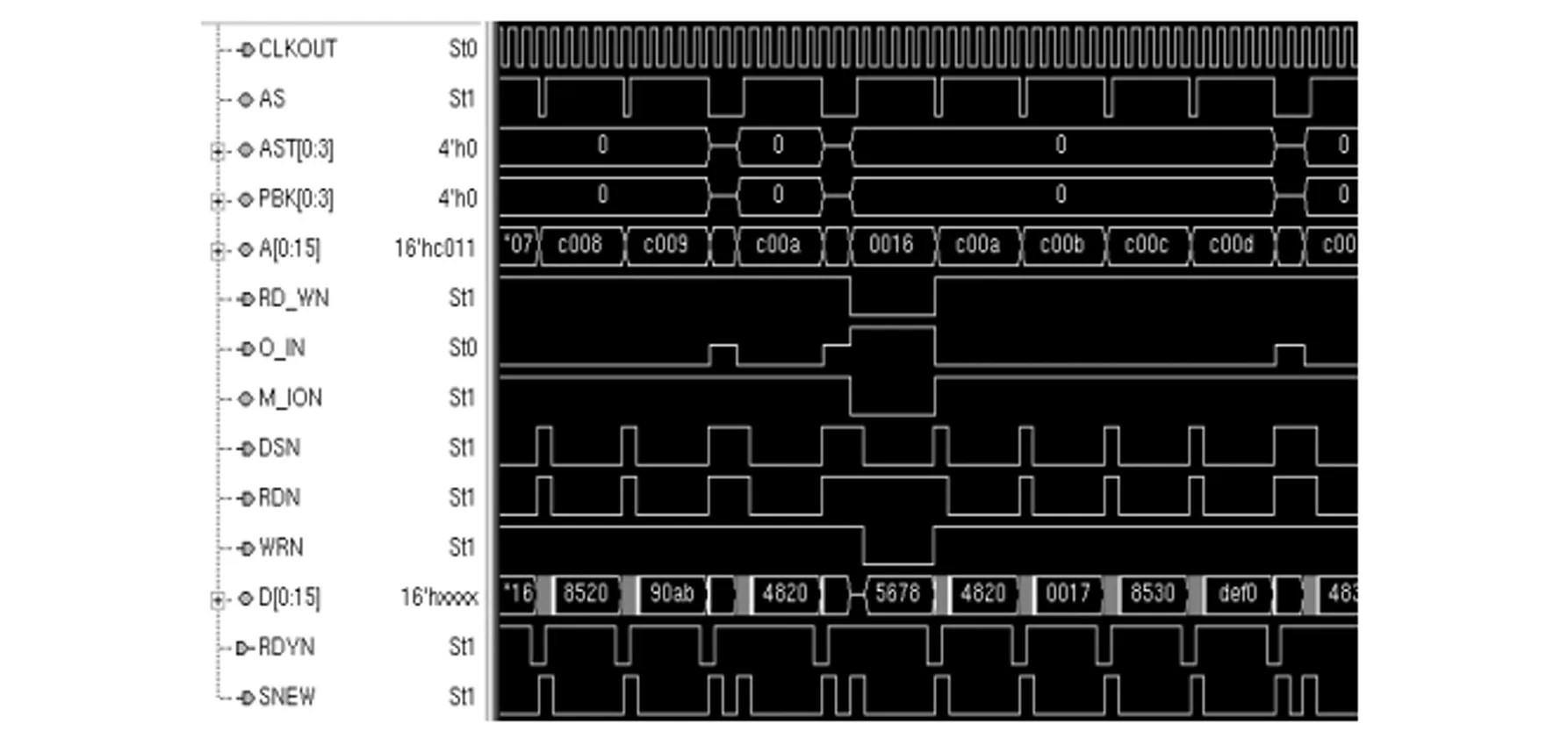
图10 CPU板FPGA和遥控遥测FPGA协同仿真波形
首先利用软核通过XIO指令向0x0015、0x0016和0x0017三个端口写入被测数据,并通过写0x0019端口告知遥控遥测写动作完毕。如图11所示,四次写操作分别引起了遥控遥测内部HA15、HA16、HA17和HA19依次产生4个低电平,对应时刻从数据线遥控遥测。SD可看到正在写入的数据。此后,软核进入等待循环,在该循环中等待遥控遥测将被测数据以串行方式写出。如图12,遥控遥测以ABCLK时钟上升沿为同步信号,输出测试用例所写入的值,图中四条纵向白线所隔开的3个波形段分别对应十六进制数1 234、5 678和90 AB的输出。测试结果与期望结果相符,该项测试成功。

图11 1750A操纵遥控遥测FPGA输出波形
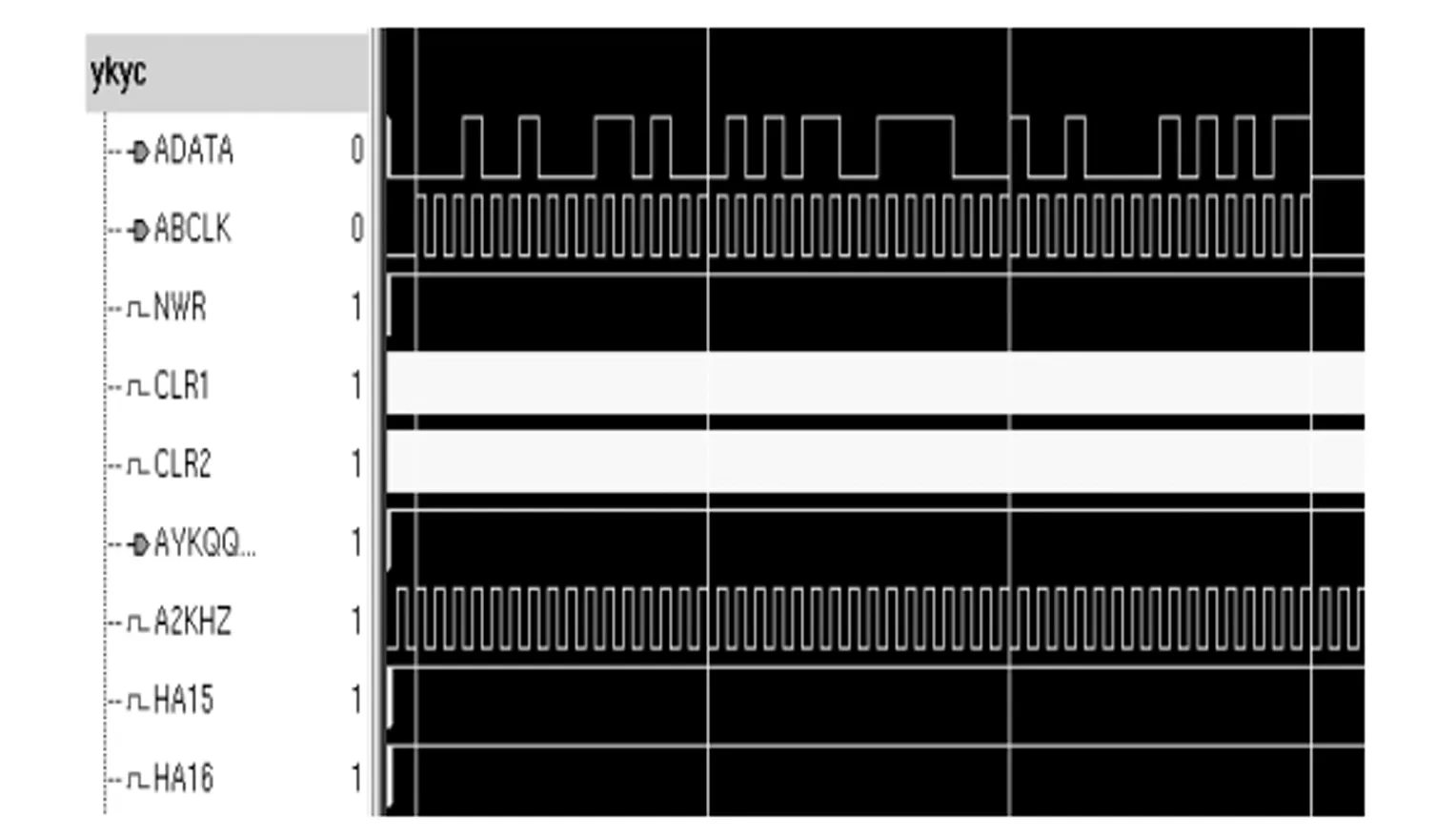
图12 遥控遥测FPGA输出波形
4.5 覆盖率统计
图13为仿真验证执行覆盖率总表,大部分功能模块和接口的验证覆盖率都达到了80%及以上,总覆盖率超过85%。其中Biu功能模块的覆盖率较低,原因是代码中有一部分采用了宏定义,而VCS仿真无法正确识别这些宏定义,因此在覆盖率总结中把其作为未覆盖到的部分。

图13 仿真验证执行覆盖率统计图
4.6 效果比对
从测试结果可以看出,通过使用该1750A软核,可以明显提高FPGA代码的条件覆盖率和翻转覆盖率。在该测试中,执行了FIFO读写,编/解码等测试,FPGA的翻转覆盖率由41%提高至87%。在测试效率提升方面,原为达到FPGA代码91%的测试覆盖率需人工操作4个工作日,利用该软核后,可在七个小时内完成,测试效率大大提高。
5 结束语
本文提出了一种CPU+FPGA的仿真模型搭建方法。首先从通用仿真模型搭建框架入手,介绍了精简1750仿真软核的作用和地位,接着在建立了精简1750仿真软核内部体系结构的基础上,对中断处理机制的实现、浮点运算单元设计方式、故障注入机制设计以及图形控制界面的实现等关键技术进行了阐述,最后搭建了较为完整的1750系列CPU+FPGA的仿真模型平台并在项目中应用。实验证明,利用该仿真模型平台,可极大提高1750系列CPU相关接口的FPGA产品的验证效率和可靠性。
