基于决策树的代码异味优先级评估
2022-06-01郭迪吴海涛
郭迪 吴海涛


摘 要: 基于以开发人员驱动的代码异味优先级排序方法,结合优化决策树算法建立模型,对代码异味的重构优先级进行面向开发人员的排名,并在实证研究中评估了该模型,以模型可解释性方法对特征的重要性进行评估,给出了相关影响较高的特征.结果表明,该模型的F1值为89%,分别较基线值和最新研究成果高出25%和5%.
关键词: 代码异味; 决策树; 特征选择; 软件可维护性
中图分类号: TP 311 文献标志码: A 文章编号: 1000-5137(2022)02-0210-07
GUO Di, WU Haitao
(College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 201418, China)
Based on the prioritization method of developer-driven code smell, combining with the optimization decision tree algorithm, a model was built to rank the refactoring priority of code smell for developers, which was evaluated in the empirical study. The importance of features was evaluated by the interpretive methods and features with high correlation impact were provided. The experimental results showed that the F1 value of the model was 89%, which was 25% and 5% better than the benchmark value and the latest research result, respectively.
code smell; decision tree; feature selection; software maintainability
0 引言
隨着软件系统的演进,开发人员需要持续地修改代码以适应新的需求和变化的业务场景.因此,在开发过程中会引入技术债务,即因软件代码问题导致软件质量的下降,而代码异味是一种典型的、可量化的技术债务.代码异味与程序可理解性、可维护性、可测试性的降低以及维护工作量和额外成本的增加有关联,对代码异味的人工分析也耗时且费力.因此,研究人员提出使用自动化机制,帮助开发人员识别和消除代码异味,从而提升代码质量.
FONTANA等提出了从软件指标中衍生的代码异味严重性度量方法,根据度量值对代码异味的优先级进行识别,但该方法过于依赖于主观经验,导致工具之间的一致性较低且不符合开发人员的偏好,对于代码异味检测的实践贡献仍然有限.MARINESCU提出了开发人员驱动的代码异味优先级方法,根据开发人员提到的重要因素提取特征,用于对代码异味进行优先级排序,与文献[7]相比,排序性能得到了提升,但该方法仅使用了最通用的特征选择方法和机器学习模型实现排序功能,且没有阐明选择这些方法的具体理由,其模型的性能仍有待提升.本文作者基于上述文献的数据集,提出了一种改进的模型,通过阈值筛选出合适的特征,避免了特征筛选中的局部最优问题;另外,通过引入决策树模型,提升预测优先级的准确率,并采用信息增益方法计算特征的重要性,分析每个特征对每种代码异味优先级预测的贡献.
1 构建方法与建立模型
决策树()原理
LightGBM是一个梯度boosting框架,使用基于学习算法的决策树,解决了对每一个特征都要扫描所有的样本点来选择最好切分点的问题,是分布式且高效的.LightGBM主要具有以下特点:1) 能减少分割增益的计算量,通过将直方图相减计算,进一步减少所占内存的空间以及并行学习的通信代价;2) 制定决策树生长策略,最优分割类别的特征值;3) 优化并行学习的LightGBM算法的两个主要步骤:
① 基于梯度的单边采样 (GOSS),仅对样本进行采样来计算梯度,其伪代码如图1所示.
② 互斥特征捆绑(EFB),将某些特征捆绑,降低特征的维度,寻找最佳切分点,减少成本的消耗,其主要伪代码如图2所示.
模型建立
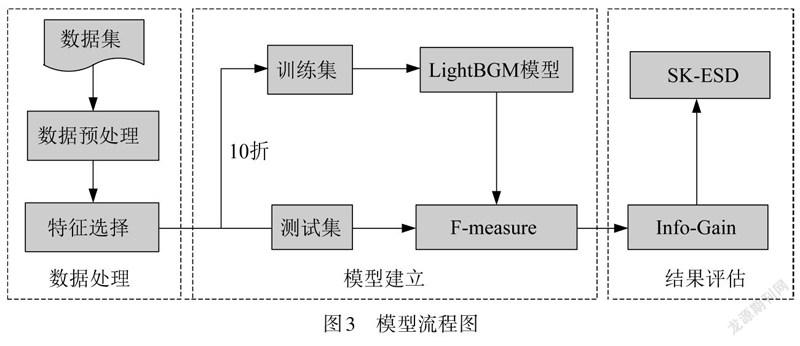
模型流程如图3所示.数据处理包括:1) 数据预处理,对选取的软件指标进行人工数据筛选,剔除空白指标数据,删除冗余数据,将数据归一化;2) 特征选择,本研究采用spearman对软件指标间的相关系数()进行相关性分析,spearman对原始变量的分布不作要求,属于非参数统计方法,所选取的特征更符合数据集本身的要求.
通过对比各种分类器,选择优化后的LightGBM作为最佳分类器模型.为了训练模型,采用了10折交叉验证策略,将数据集随机划分为大小相等的10份,对数据集分层抽样,每一折具有相同比例的临界等级.将2份数据用作测试集,其余用于训练模型.该过程重复10次,每次将数据集重新划分成训练集和测试集.
通过计算精度、召回率和F-measure评估实验模型的性能.使用信息增益算法和Scott-Knot结果大小差异(SK-ESD)測试计算和评估软件指标带来的熵变化,其中Scott-Knott检验是一种统计度量,用于比较和区分模型性能,使用层次聚类方法对评估指标进行分组,以便分析评估指标对开发人员感知代码异味严重性评估的准确性.
2 仿真实验
代码异味
选取4种代码异味进行研究:
1) 上帝类(God Class).上帝类会影响不遵循单一职责原则的类,造成代码内聚性变差且难以维护,上帝类通常会造成软件缺陷,提高维护成本.
2) 复杂类(Complex Class).高度复杂的类会提高开发人员理解并优化代码的难度,开发人员通常需要识别这种异味,并评估其重要性.
3) 意大利面条代码(Spaghetti Code).意大利面条代码通常表现为混乱的代码控制结构,且没有正确使用面向对象编程原则的编程风格,会影响开发人员对源代码的理解.
4) 霰弹式修改(Shotgun Surgery).当开发人员对一个类进行修改时,必须同时在大量不同的类中做相应修改,导致相关类出现缺陷的概率大幅提高.
PECORELLI等证明了这4种异味在真实的系统中广泛分布;GRANO等证实了这4种异味对软件系统的可维护性、可理解性和可测试性会产生负面影响;PALOMBA等提出开发人员不仅能准确分析这4种代码异味,而且能感知它们的严重性.
软件指标
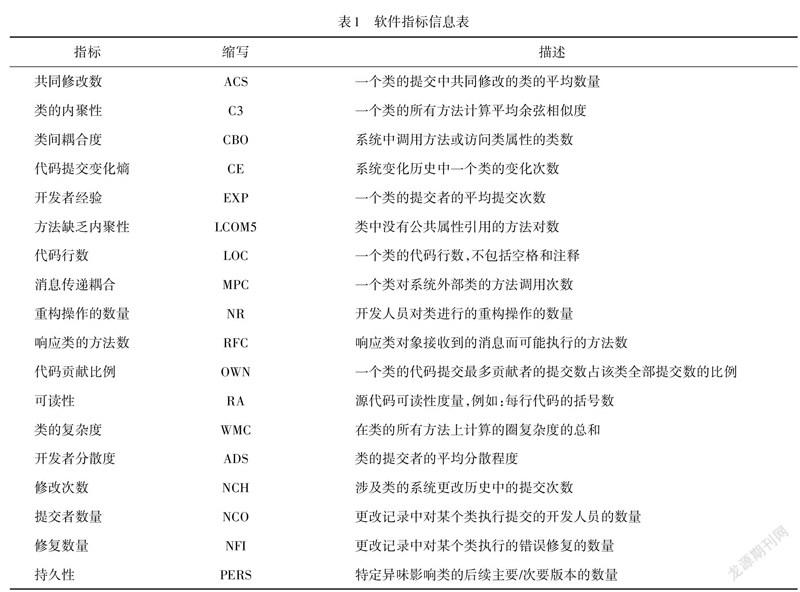
参考文献[19]选取一组涵盖不同角度下的类结构和可维护性特征的指标,如表1所示.
数据集
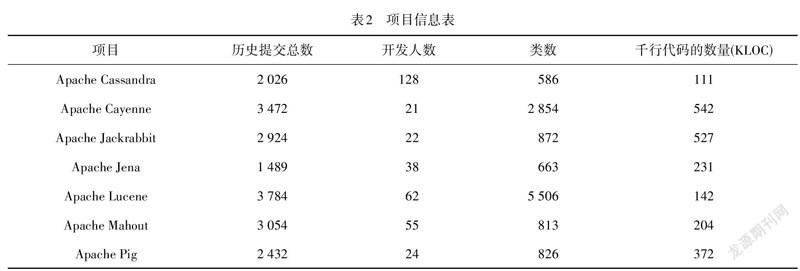
代码异味是随着时间变化的一组特征,所以项目需满足数据集完整性、连贯性的要求,选取Apache社区的7个开源项目进行实验(表2).考虑类数超过500,更改历史至少5年,至少提交1 000次,并且贡献者数量高于20人的项目,筛选出341个上帝类、349个复杂类、313 个意大利面条代码和329个霰弹式修改,共1 332条数据.
实验结果分析
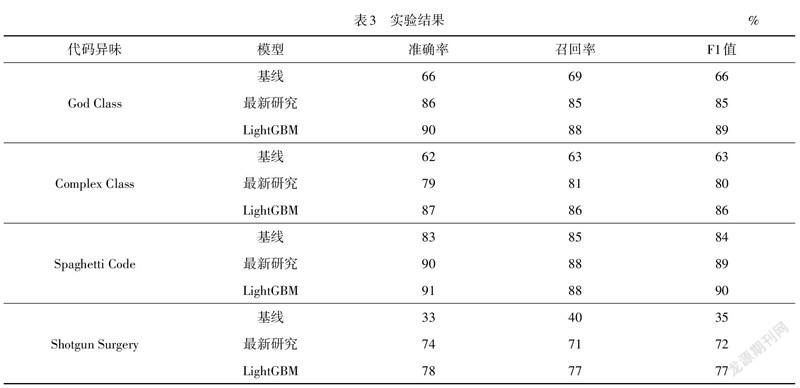
通过对数据集的训练和测试,得到的实验结果对比如表3所示.结果表明,所建立模型的F1值为77%~90%,高于对比文献[19]中的模型,其中对God Class,Complex Class及Shotgun Surgery的分类结果,F1值分别高出4%,6%及5%.
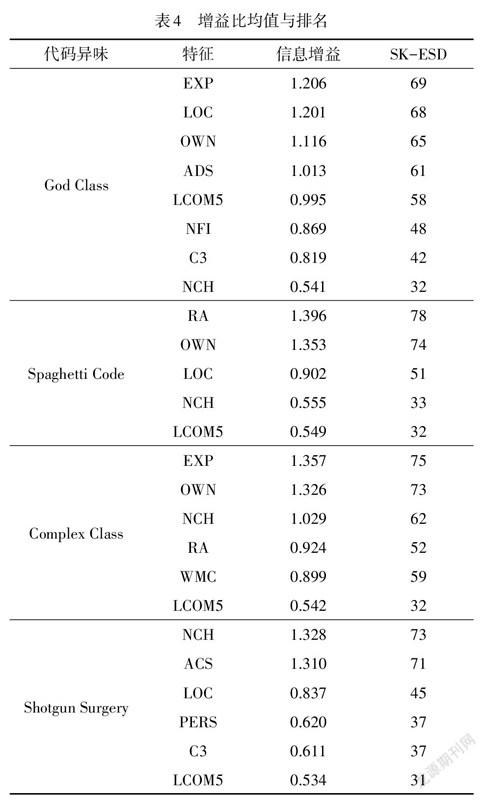
通过特征可解释性工具,计算出每个特征的重要性,实验结果如表4所示.通过信息增益算法,计算出每个特征对模型结果提供的增益值,利用Scott-Knott结果大小差异校验进行评估打分,并对打分进行排序.本研究给出信息增益值大于0.5的结果.
影响代码异味God Class的因素是由多种指标混合而成,不能仅仅通过某种单一指标进行描述.模型主要依赖EXP,LOC,OWN及ADS,同时LCOM5,C3以及NFI对其也有影响.
对于Complex Class,模型最为依赖的指标为EXP,OWN和NCH,此外其他指标对分类模型也有一定影响,如RA,表明在优先考虑Complex Class时,开发人员认为可读性很重要.其他影响因素包括WMC和LCOM5,证实了代码异味的检测涉及代码结构方面的因素.
在分析Spaghetti Code时,发现没有代码结构因素对分类产生主要影响.RA是开发人员优先考虑Spaghetti Code的首要因素,因此,开发人员在遇到遭受这种异味的实例时,优先考虑语义上是否连贯.OWN和 LOC为次要因素,NCH和LCOM5的影响可以忽略不计.
Shotgun Surgery,NCH和ACS被证明是重要的指标.此外,PERS也被证明会影响分类的情况,证实了开发人员会根据单次代码提交共同修改涉及类的数量,即Shotgun Surgery的强度, 评估Shotgun Surgery的严重程度.此外,C3和LCOM5也会有一定程度的影响,但与其他类型指标的贡献相比,影响程度较低.
3 结 论
基于面向开发人员的代码异味优先级排序方法,利用特征选择方法选择自变量,应用LightGBM机器学习算法,对描述代码异味的关键性特征进行分类,用于预测开发人员对1 332个代码异味实例标注的严重程度.通过实验表明,对于4种代码异味的分类,所设计模型的F1值为77%~90%,与基线模型相比,平均高出25%.本研究后续的工作包括:1) 增加数据集数量,优化数据集处理方法;2) 替换其他模型,论述模型的对比与优化情况;3) 更换其他开发语言应用,验证本研究结论.
参考文献:
[1] BROWN N, CAI Y F, GUO Y P, et al. Managing technical debt in software⁃reliant systems [C]// Proceedings of the FSE/SDP Workshop on Future of Software Engineering Research. Santa Fe: ACM,2010:47-52.
[2] SHULL F, FALESSI D, SEAMAN C, et al. Technical Debt: Showing the Way for Better Transfer of Empirical Results [M]// Perspectives on the Future of Software Engineering. Berlin: Springer,2013.
[3] ABBES M, KHOMH F, GUEHENEUC Y G, et al. An empirical study of the impact of two antipatterns, blob and spaghetti code, on program comprehension [C]// 15th European Conference on Software Maintenance and Reengineering. Oldenburg: IEEE,2011:181-190.
[4] PALOMBA F, BAVOTA G, PENTA M D, et al. On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation [C]// 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE). Gothenburg: IEEE,2017:1-34.
[5] GRANO G, PALOMBA F, GALL H C. Lightweight assessment of test?case effectiveness using source⁃code⁃quality indicators [J]. IEEE Transactions on Software Engineering,2019,47(4):758-774.
[6] SJØBERG D I K, YAMASHITA A, ANDA B C D, et al. Quantifying the effect of code smells on maintenance effort [J]. IEEE Transactions on Software Engineering,2012,39(8):1144-1156.
[7] FONTANA F A, ZANONI M. Code smell severity classification using machine learning techniques [J]. Knowledge⁃Based Systems,2017,128:43-58.
[8] MARINESCU R. Assessing technical debt by identifying design flaws in software systems [J]. IBM Journal of Research and Development,2012,56(5):1-13.
[9] AL⁃ANI A, DERICHE M. Feature selection using a mutual information based measure [C]// Proceeding of the 16th IEEE International Conference on Pattern Recognition. Quebec: IEEE,2002:82-85.
[10] KE G L, MENG Q, FINLEY T, et al. Lightgbm: a highly efficient gradient boosting decision tree [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach: ACM,2017:3149-3157.
[11] BAEZA⁃YATES R, RIBEIRO⁃NETO B, MILLS D, et al. Modern Information Retrieval [M]. New York: ACM,1999.
[12] SCOTT A J, KNOTT M. A cluster analysis method for grouping means in the analysis of variance [J]. Biometrics,1974,30(3):507-512.
[13] BUDD T A. An Introduction to Object?Oriented Programming [M]. Boston: Addison⁃Wesley Publishing,2001.
[14] FOWLER M, BECK K. Refactoring: Improving the Design of Existing Code [M]. Boston: Addison⁃Wesley Publishing, 1999.
[15] KHOMH F, PENTA M D, GUÉHÉNEUC Y, et al. An exploratory study of the impact of antipatterns on class change-and fault⁃proneness [J]. Empirical Software Engineering,2012,17(3):243-275.
[16] SOH Z, YAMASHITA A, KHOMH F, et al. Do code smells impact the effort of different maintenance programming activities?[C]// IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering. Osaka: IEEE,2016:393-402.
[17] BROWN W H, MALVEAU R C, MCCORMICK H W, et al. Antipatterns: Refactoring Software, Architectures, and Projects in Crisis [M]. New York: John Wiley & Sons,1998.
[18] PALOMBA F, BAVOTA G, PENTA M D, et al. Do they really smell bad? A study on developers’ perception of bad code smells [C]// Software Maintenance and Evolution. Victoria: IEEE,2014:101-110.
[19] PECORELLI F, KHOMH F, LUCIA A D. Developer⁃driven code smell prioritization [C]// Proceedings of the 17th International Conference on Mining Software Repositories. New York: ACM,2020.
[20] HUANG Z J, CHEN J H, GAO J H. Quantifying anemia and bloodshot of layers in Web applications from the perspective of code smell [J]. Acta Electronica Sinica,2020,48(4):772-780.
[21] TUFANO M, PALOMBA F, BAVOTA G, et al. When and why your code starts to smell bad (and whether the smells go away) [J]. IEEE Transactions on Software Engineering,2017,43(11):1063-1088.
[22] TAIBI D, JANES A, LENARDUZZI V. How developers perceive smells in source code: a replicated study [J]. Information and Software Technology,2017,92:223-235.
(责任编辑:包震宇,冯珍珍)
