基于距离感知自上而下的多人三维姿态估计
2022-05-31林浩翔李万益邬依林黄用有林慕飞
林浩翔 李万益 邬依林 黄用有 林慕飞


摘要:人体姿态估计是计算机视觉领域的一个热门研究方向。人体姿态估计的技术发展已有一段时间,相关的方法已经提出比较多,这些方法基本都局限于单人的三维姿态处理。在大多场景下,三维运动形态呈现多人交互的情况,所以多人姿态估计的问题需要处理。随着深度学习的理论发展,该文提出基于距离感知自上而下深度学习,处理多人三维姿态估计的问题。
关键词:计算机视觉;多人三维姿态估计;深度学习
中图分类号:TP391.41 文献标识码:A
文章编号:1009-3044(2022)11-0077-02
1 引言
基于深度学习的三维单人姿态估计研究已经取得了一定的成果[1-5]。单人姿态估计方法适用的模型也比较多,其估计效果已经比较理想。单人估计的模型可以将角色模型融合到真实世界的视频和场景[6],可实现和场景的人物交互。但是在大多场景中,多人姿态交互的情况出现也有很多,比如集体舞蹈教学、多人体育竞技展示、多人动作交互三维重构等[7-9],多人三维姿态估计是常见并且需要处理的问题。该问题能否有效解决关系到三维姿态估计的核心技术能否有所突破。
在多人三维姿态估计中,人体肢体的相互遮挡、三维与二维图像的映射歧义以及模型建立与训练的问题比之前单人三维姿态估计要严重很多[10]。因此,为了较好实现多人三维运动形态估计,本文提出基于距离感知自上而下深度学习处理。该方法结合图像深度值计算,关键点检测进行估计,提出的方法不仅继承了传统单人三维姿态估计方法的优点,还具有多人检测并实时估计的特点,具有良好的稳定性。所提方法估计出的三维模型为常用的骨架模型[11],该模型可以转换成更高级的体型模型[12],对该高级模型的身高、体重、皮肤、肢体粗细等细节计算具有良好的促进作用。
本文提出的方法,首先检测二维图像的中心根节点,然后自上而下寻找其他肢体的节点,如腕部、脚踝位置的节点等,将这些关节点进行连接,组成一个人体二维骨架模型,接着计算中心根节点的深度值,确定相应三维模型的空间位置,最后通过神经网络估计出三维姿态。多人估计的实现依靠对二维图像人体个数的检测,还有对单幅图像多人肢体中心根节点和其他肢体关键点进行检测,以及神经网络在三维空间中估计的相应位置。本文进一步讨论所提方法并进行实验测试,测试分为单人三维姿态测试,体型模型转换测试以及多人三维姿态估计测试,测试结果显示所提算法具有较强的有效性、稳定性和准确性。
2 基于距离感知自上而下深度学习
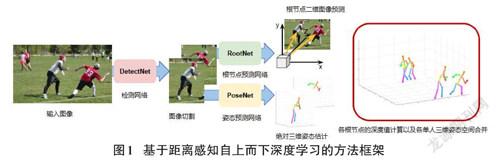
深度学习是最近几年提出的热点理论,其可以处理语音、图像,以及语言数据等,对大量的数据可以成功地构建复杂的映射关系,并且能成功地进行训练和预测。本文提出的方法以深度学习理论为基础,可以处理大量的人体姿态数据样本。由于多人动作交互的图像需要标注人体的肢体关键点,对关键点的三维空间位置进行预测,所以本文所提方法要计算图像的相关信息深度值,以此确定其关键点具体的三维空间位置。本文提出的方法基于文献[8],其方法框架如图1所示。
所提出方法是通过计算各个单人三维骨架模型的主要根节点位置以及其他关键节点(无空间位置信息) 的关键点整合到一个空间来实现。检测网络用于检测二维图像中的人体姿态在图像中的位置,以便能进行图片切割,得到相应的人体姿态二维图像,缩小二维图像的处理范围,如图2所示。得到人体姿态二维图像后,通过根节点网络预测二维图像中人体的根节点的位置,并对其深度值进行计算,如图3所示。然后通过二维图像的根节点计算其深度值,确定其在三维空间的位置,其具体方法如图4所示。用姿态预测网络预测非根节点的其他关键点(肢体关键点) ,得出绝对三维姿态和根节点的三维空间信息进行结合,输出三维空间中的单个三维姿态骨架模型。
3 实验与评价
本文提出的基于距离感知自上而下深度学习方法,不仅可以处理单人三维姿态估计,还可以处理多人三维姿态估计。下面对所提出方法进行实验测试。首先,进行单人的三维姿态估计进行测试,测试数据选用Human3.6M数据[6]进行测试,动作姿态选“吃东西”姿态片段,选取任意一帧进行展示,如图5所示。从图5中,发现所提方法估计的三维姿态与真实值很接近,该现象表明所提的方法估计单人三维姿态的准确度比较理想,不会出现左右相反的情况。
接下来,用所提出的方法对所估计的三维动作姿态进行体型模型转换测试,测试结果如图6所示。首先用所提方法进行二维动作姿态估计,得到二维图像的动作姿态,然后通过根节点预测网络、姿态预测网络以及深度值计算,得到骨架模型的根节点和其他肢体关键点组成相应的骨架三维模型,再通过体型计算得到相应的体型模型。从图6中发现,所得到的体型模型和相应的图像很匹配,说明所提出的方法估计的骨架模型对体型模型的计算有良好的辅助作用。
最后,在Human3.6M数据库[6]及其他数据库中选用不同的视频片段进行单人和多人的三维姿态估计测试,如图7所示。从实验测试可知,所提方法的性能较稳定,估计出的三维人体骨架模型投影到原图像后,与二维图像的人体肢体很匹配,并且估计的视觉效果比较理想,动作姿态展示准确。在多人姿态相互遮挡的情况下,所提的方法也能克服,得到比较理想的结果。图7的结果再次证明所提算法的有效性、稳定性和准确性。
4 结束语
基于距离感知自上而下深度学习的训练需要通过大量数据样本的收集来实现,这样才能构成较完美的根节点预测网络和姿态预测网络,最终实现较理想的实验效果。再者,经过实验测试,所提方法估计的骨架模型对体型模型的转换也起着较好的基础作用。随着社会的现代化发展,人体三维姿态估计作为计算机视觉领域的研究分支,其技术日益显得重要。该技術对集体舞蹈教学、多人体育竞技三维展示、多人动作交互三维重构等有良好的促进作用。
参考文献:
[1] Zhou XW,ZhuML,PavlakosG,etal.MonoCap:monocularhuman motion capture using a CNN coupled with a geometric prior[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,41(4):901-914.
[2] Hassanpour M,MalekH.Learning document image features with SqueezeNet convolutional neural network[J].International Journal of Engineering,2020,33(7):1201-1207.
[3] HosnyKM,KassemMA,Fouad M M.Classification of skin lesions into seven classes using transfer learning with AlexNet[J].Journal of Digital Imaging,2020,33(5):1325-1334.
[4] McNeely-WhiteD,Beveridge J R,DraperBA.Inception and ResNet features are (almost) equivalent[J].Cognitive Systems Research,2020,59:312-318.
[5] Wang JB,TanSJ,ZhenXT,etal.Deep 3D human pose estimation:a review[J].Computer Vision and Image Understanding,2021,210:103225.
[6] IonescuC,PapavaD,OlaruV,etal.Human3.6M:large scale datasets and predictive methods for 3D human sensing in natural environments[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(7):1325-1339.
[7] KamelA,LiuBW,LiP,etal.Aninvestigation of 3D human pose estimation for learning Tai chi:ahumanfactor perspective[J].International Journal of Human-Computer Interaction,2019,35(4/5):427-439.
[8] Moon G,ChangJY,LeeKM.Camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27 - November 2,2019,Seoul,Korea (South).IEEE,2019:10132-10141.
[9] Jianan Zhen, Qi Fang, Jiaming Sun, Wentao Liu, Wei Jiang, HujunBao, Xiaowei Zhou. SMAP: Single-Shot Multi-person Absolute 3D Pose Estimation[C]//Proceedings of the ECCV 2020, Glasgow, United kingdom, Springer Science and Business Media Deutschland GmbH,2020:550-566.
[10] BenzineA,LuvisonB,PhamQC,etal.Single-shot 3D multi-person pose estimation in complex images[J].Pattern Recognition,2021,112:107534.
[11] Li WY,ZengYQ,ZhangQ,etal.Humanmotion capture based on incremental dimension reduction and projection position optimization[J].Wireless Communications and Mobile Computing,2021,2021:5589100.
[12] BogoF,KanazawaA,LassnerC,etal.Keep it SMPL:automatic estimation of 3D human pose and shape from a single image[C]//Proceedings of the 21st ACM Conference on Computer and Communications Security, CCS 2014, Scottsdale, AZ, United states, Springer Verlag:2016: 561-578.
收稿日期:2021-12-20
基金項目:本课题由国家级大学生创新创业训练计划项目(No. 202114278009X),广州市基础与应用基础研究项目(No. 202002030232),广东省普通高校青年创新人才项目(No. 2019KQNCX095),广东省高等学校教学质量与教学改革工程项目(广东第二师范学院计算机实验教学示范中心, 2019年, No. 18),广东第二师范学院网络工程重点学科(No. ZD2017004) 资助
作者简介:林浩翔,男,本科生,研究方向为图像处理,深度学习;通信作者:李万益,男,博士,讲师,研究方向为图像理解、机器学习、深度学习。