普通话水平测试命题说话模块自动评分技术研究
2022-05-31申云飞刘嘉俊范智星早克热·卡德尔艾山·吾买尔
申云飞 刘嘉俊 范智星 早克热·卡德尔 艾山·吾买尔




摘要:命题说话是至今唯一采用人工方式评分的普通话水平测试考题,实现高精度命题说话评测技术有利于国家通用语言文字的推广普及。该文提出了基于回归模型的PSC命题说话模块评分模型,并在自建的PSC命题说话数据集上对比了基于不同回归模型的预测精度。实验结果表明,基于XGBoost的PSC命题说话模块评分模型在测试集上与综合专家评分的皮尔逊相关系数达到了0.860,相比线性回归模型提升了17.5%,与人工专家评分具有较高的相关度,具有一定的实用价值。
关键词:普通话水平测试考试;命题说话;发音自动评测;皮尔逊相关系数
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)11-0007-04
1 引言
普通话是我国的国家通用语言,全面加强国家通用语言文字教育,是坚持以人民为中心的发展思想的内在要求,是铸牢中华民族共同体意识的重要途径。人工智能(Artificial Intelligence, AI) 是引领现代教育革命的重要驱动力,这门技术已经被广泛应用于教育的各个环节,深刻地改变了过去的教、学、考的教育形式。国内外研究人员围绕教育领域的常规教学业务工作自动化,研发了写作评测技术、发音评测技术、自动化口语评测技术,在TOFEL、GRE、SAT等测试及我国普通话水平测试(Putonghua Shuiping Ceshi, PSC)、汉语水平考试(HSK) 、中国少数民族汉语水平等级考试(MHK) 等测试使用计算机辅助测试部分口语测试题,极大提高了自动化程度。命题说话题型属于文本无关口语评测技术,它测查应试人在无文字凭借的情况下说普通话的水平,重点测查语音标准程度、词汇语法规范程度和自然流畅程度。由于命题说话题型评测的复杂性,目前,在普通话水平测试中及各种公开的普通话学习软件及服务中,朗读题型大多已经实现了机器自动评分,但是命题说话部分仍然需要通过由专家人工评分的方式来取得较准确的评测结果。研究与人工专家打分结果具有较高相关度的普通话命题说话题型模块的自动评测技术,对普通话的推广具有重要的现实意义。
对命题说话题型的自动评测是自动口语评测(Automated Speech Scoring, ASS) 的一项子任务。目前国际上对命题说话自动评测的研究集中在英语上,并且取得了较好的进展。当前命题说话自动评测技术的主要难点是需要综合提取多种评分特征并进行融合,以实现更全面、更准确、与专家人工打分一致性更高的机器评分。命题说话自动评测的通常实现途径为通过自动语音识别(Automatic Speech Recognition, ASR) 识别待评测音频,随后基于待评测音频与语音识别结果进行发音错误检测(Mispronunciation Detection and Diagnosis, MDD) 、语法纠错(Grammar Error Correction, GEC) 、离题检测(Off-Topic Spoken Response Detection) 与流畅度评测等多项子评测,得到多维度的评分特征,最终通过评分模型得到整体性的评分结果。美国教育考试服务中心(Educational Testing Service, ETS)研发的托福口语自动评分系统SpeechRater就是基于大量人工设计的评分特征的英文命题说话自动评测系统[1]。许苏魁针对PSC命题说话题型的机器评测进行了详细的研究,基于DNN-HMM语音识别模型得到待评测语音的识别结果后验概率,利用RNNLM语言模型重打分与方言模型进行修正后作为主要机器打分特征,同时引入基于条件随机场(Conditional Random Field, CRF) 的语速特征提取模型、基于矢量空间模型(Vector Space Model, VSM) 的离题检测模型等辅助打分特征,利用线性回归模型作为机器评分的打分模型,最终获得了0.757的机器分与人工分的回归系数[2]。汤国春在研究针对汉语水平口语考试(HSKK) 的看图说话题自动评分模型时,通过对不同图片人工预设与其内容相关的关键词,随后通过计算关键词覆盖率作为主题相关特征,结合字数、重复字数与语法错误数这四个特征,构建了基于线性回归的评分模型[3]。以上研究均使用线性回归作为评分模型,李淇澳在研究开放式英语口语考试自动评测时,使用BP神经网络(也被称为多层感知机回归,MLP Regressor) 作为评分模型[4]。
综上,目前的命题说话等自由表述口语自动评分研究,主要使用线性回归或多层感知机回归等机器学习方法,构建基于单个模型的评分模型,尚未见到基于集成学习(Ensemble Learning) 方法的自动评分研究。目前,梯度提升回归树(Gradient Boosted Regression Tree, GBRT) 等集成学习类的机器学习方法由于优异的性能表现及良好的可解释性[5],在信用评级[6]、电网负荷[7]及房租预测[8]等多种多样的领域中得到了广泛的运用。本文在基于人工设计特征与回归模型的PSC命题说话模块的自动评测模型框架的基础上,在自建的PSC命题说话数据集上通过实验对比了采用线性回归、支持向量回归(Support Vector Regression, SVR) 、多层感知机回归、LightGBM和XGBoost等回归模型时的评分模型性能。实验结果显示该机器评分方法具有可行性,且基于XGBoost的PSC命题说话评分模型性能最好,得到的机器分与专家分间的相关系数达到了0.860,已经具有较高的相关度。
2 基于梯度提升方法的集成学习模型
2.1 集成学习与提升方法
集成学习是一种典型的模型独立学习方式,它通过一定的策略将多个模型进行集成,以多个模型进行综合决策的方式来提升模型预测的准确率。常用的集成学习策略包括装袋算法(Bagging) 与提升算法(Boosting) ,其中提升算法通过按顺序训练一系列基模型,每一个模型均针对前序模型的错误来调整训练样本的权重,从而不断提升模型性能[9]。梯度提升(Gradient Boosting) 是一类改进提升算法,它将提升算法的优化对象扩展到了一般的损失函数[10],得到了广泛的运用。以下介绍基于梯度提升方法的梯度提升回归树,以及它的改进实现LightGBM與XGBoost。
2.2 梯度提升回归树
梯度提升回归树是一类被广泛运用的机器学习算法,它基于提升树方法(Boosting Tree) 与梯度提升方法,也被称为梯度提升机(Gradient Boosting Machine, GBM) [11]。梯度提升回归树与梯度提升决策树(Gradient Boosted Decision Tree, GBDT) 的区别在于选取的基模型是回归树还是分类树。提升树方法是使用决策树作为基模型、使用加法模型对基模型进行线性组合的提升方法,它可以表示为:
对于回归问题,提升树方法在训练模型时通过前向分步算法进行迭代,即以损失函数作为优化目标,计算出当前回归树模型在训练集上的残差(Residual) 后,拟合残差得到下一个模型的参数。回归提升树模型常用的目标函数是平方损失函数,一般损失函数可能面临着残差计算困难的问题,梯度提升方法利用最速下降法,将损失函数的负梯度作為回归提升树的残差的近似值,从而将回归提升树扩展到使用任意连续可微的损失函数作为优化目标的场景,也就是梯度提升回归树。
在当今的大数据时代,机器学习任务中数据样本数量及特征维度快速增加,传统的梯度提升树算法在实际运用时面临着由于计算复杂度提升而不得不在准确度与执行效率中进行权衡[12]。针对这一现状,LightGBM与XGBoost这两种改进的梯度提升树框架应运而生,并得到了广泛的运用。
2.3 LightGBM
LightGBM是由微软公司研究院提出的改进梯度提升算法框架及相应的软件实现,它提供了高效易用的GBDT与GBRT模型实现[12]。针对大数据下GBDT与GBRT计算复杂度过高的问题,LightGBM提出了基于梯度的单边梯度采样(Gradient-based One-Side Sampling, GOSS) 与相斥特征打包(Exclusive Feature Bundling, EFB) 算法,在保证模型预测准确度的前提下大幅提升了GBDT与GBRT模型的训练速度。GOSS算法在训练阶段通过随机去掉梯度较小的样本实现训练数据的下采样。EFB算法将选择相斥特征的问题转化为图着色问题后,通过贪婪算法求解,这样就可以将相斥的特征进行打包以减少特征数量。此外,LightGBM选择使用基于直方图算法的决策树分裂点搜索方法,该算法在模型训练过程中将连续特征值通过分箱操作离散化,有效提升了模型训练速度[12-13]。
2.4 XGBoost
XGBoost是由华盛顿大学DMLC组(Distributed (Deep) Machine Learning Community) 提出的分布式梯度提升算法库软件,目标在于提供高效可扩展的GBDT与GBRT实现。为了对抗过拟合,XGBoost为目标函数添加了正则化惩罚以降低模型的复杂度,同时对特征进行下采样[11]。为了加快决策树模型分裂点的搜索,XGBoost提出了一种在构造目标函数时,使用损失函数的二阶泰勒展开进行近似的方法[14],同时它也支持与LightGBM相同的直方图算法①。在可用的基模型方面,XGBoost支持决策树与线性模型。
3 研究方法
3.1 命题说话评测系统设计
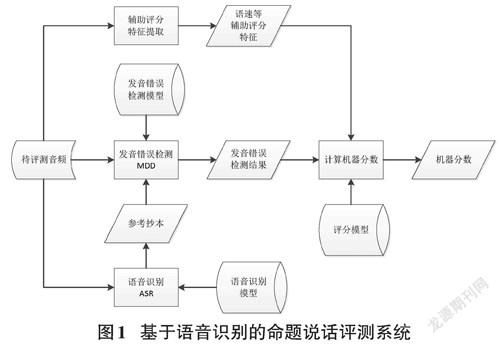
本文提出的命题说话评分模型及相应的评分环节是基于语音识别的PSC命题说话模块自动评测系统的一部分,该系统的结构如图1所示。该系统包含用于获得评测参考文本的语音识别子系统与在此基础上通过参考文本相关方法实现发音错误检测的发音错误检测子系统,通过按照一定的规则解析子系统的输出,即可获得命题说话评分模型的评分特征。在进行本文的研究时,语音识别子系统采用百度智能云提供的普通话语音识别公开接口服务②,而发音错误检测子系统采用云知声提供的普通话语音评测公开接口服务③。
3.2 基于回归模型的命题说话评分方法
本文所述的评分方法基于回归模型,使用人工设计的评分特征作为模型输入,模型的输出即为机器评分。由于PSC命题说话题的分数范围是[[0,40]],故超出这一范围的模型输出值将被相应地裁剪,确保最终得到的机器分数符合要求。于是本文所描述的命题说话评分模型可以表示为:
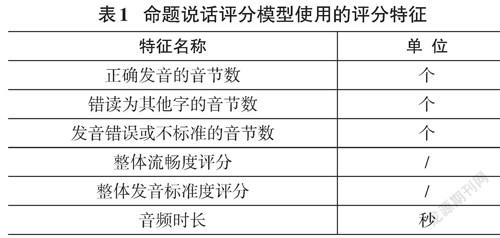
在选择评分特征时,我们参考PSC命题说话的评分规范,从流畅度、发音准确度等方面选取了一系列特征,这些评分在表1中给出。这些特征可以从待评测语音的元信息、发音错误检测子系统输出结果中计算得到。
3.3 模型超参数优化
对于GBRT等较为复杂的模型,超参数的设置会显著影响模型性能,所以需要通过超参数优化找到使该模型性能最佳的超参数组合,这一过程也被称为“调参”。本文使用的超参数搜索方法是网格搜索(Grid Search) ,它是通过尝试所有超参数的组合来寻址合适一组超参数配置的方法[9],利用Scikit-learn中提供的GridSearchCV功能即可便利地实现网格搜索。本文中使用的MLP回归、GBRT、LightGBM、XGBoost模型需要进行超参数优化。
4 实验与数据分析
4.1 数据集
本文实验在自建的PSC命题说话数据集上进行。该数据集包括400份普通话水平测试命题说话测试音频,数据来源为考场数据及组织大学生进行录音,录音环境为安静的室内,录音设备为台式电脑及头戴式耳麦。这400份数据来自124名说话人,囊括了PSC命题说话题型的全部30个话题,这些话题全部来自于PSC命题说话题库,从而确保与考试形式一致。原始数据集以7:3的比例随机划分为训练集与测试集,故训练集包括280份音频,测试集包括120份音频。该数据集由具有PSC评测员资格的普通话评测专家,在自建的Web打分系统上根据相应的评分规则进行评分。数据的人工标注内容包括整体评分以及发音标准度、流畅度、词汇语法规范度、是否离题等多个方面的打分细节,在进行本文所述的研究时只使用整体评分。为了确保数据标注的客观性,所有数据均由三名专家进行标注。在训练模型时及验证模型性能时,我们使用每份样本的三个专家评分的平均值作为该样本的真实分数,并将其称为所有专家综合评分。
本文使用皮尔逊相关系数(Pearson Correlation Coefficient, CC) 衡量专家评分间,以及专家评分与所有专家综合评分间的相关性。皮尔逊相关系数常被用于度量真实值与预测值间的相关程度。人工打分[Y]与机器打分[Y]间的相关系数的计算公式是:
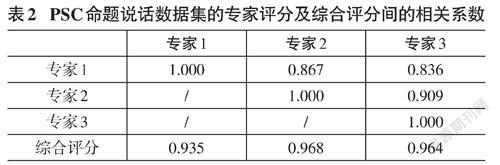
其中[μY]表示[Y]的均值。皮尔逊相关系数的取值范围是-1~1,值为1则两个变量完全正相关,值为0则二者完全不相关,值为-1则二者完全负相关。当被衡量的两组变量数据均已经被标准化时,皮尔逊相关系数与余弦相似度等价[15]。专家打分的相关系数见表2,根据表2中的数据可以得到三名专家的打分结果间的相关系数的均值为0.871,三名专家的打分结果与综合打分结果间的相关系数的均值为0.956。由于每位专家的评分与综合评分间的相关系数更高,故综合评分的可靠性更高,可以作为评价命题说话评测系统性能的对象。
4.2 實验设置
本文的实验在x86服务器上进行,操作系统为Ubuntu 20.04,GPU为NVIDIA Tesla V10016GB,代码运行环境为Python 3.8,使用的回归算法实现来自于Scikit-learn、LightGBM与XGboost库。实验中使用的回归模型包括Scikit-learn提供的线性回归、MLP回归、SVR、GBRT,以及由相应的库独立提供的LightGBM回归与XGBoost回归。本文将线性回归模型作为基线模型。对于性能会显著受超参数影响的MLP回归、GBRT、LightGBM、XGBoost模型,本文使用皮尔逊相关系数作为超参数优化的目标,在训练集上通过K-Fold交叉验证与超参数优化找到使模型性能最佳的超参数组合,随后使用该超参数组合在全部的训练集数据上训练模型,在测试集上验证模型最终性能。K-Fold的折数根据相关研究,通过对训练集样本的数量取自然对数[16],确定为6折。在模型配置方面,SVR模型使用RBF核,GBRT模型使用Huber Loss作为损失函数并限制最大深度为3,XGBoost模型使用与LightGBM类似的基于直方图算法的决策树分裂点搜索算法。进行实验时的全局随机种子为1234,从而确保实验结果可复现。
4.3 模型性能评估指标
为了衡量不同模型的性能,本文采用回归模型的通用评估方法及普通话口语自动评测领域常用的评测方法完成对模型的评估。本文使用评估指标包括均方误差(Mean Squared Error,MSE) 、判定系数(Coefficient of Determination,[R2]) 与皮尔逊相关系数。模型性能评估在测试集上进行,方法是将专家综合评分作为真实值,评分模型输出的机器分作为预测值,计算上述评估指标,通过比较评估指标的大小找到性能最佳的模型。以下介绍MSE与[R2]指标的计算方法。
1) MSE用于衡量预测值与真实值间的误差,整体误差越小则MSE的值越低。当数据集中有N个语音样本时,将它们的人工打分记为[Y],机器打分记为[Y],此时[Y=Y1,Y2,…,YN],[Y=Y1,Y2,…,YN],则向量[Y]与[Y]间的MSE可以通过以下公式计算:
2) [R2]用于衡量回归模型的解释力。人工打分[Y]与机器打分[Y]间的[R2]可以通过以下公式计算:
其中[μY=1Ni=1NYi],表示[Y]的均值。[R2]的取值范围为0~1,值越接近于1则回归模型对因变量中的变异有更强的解释能力。
4.4 实验结果与分析
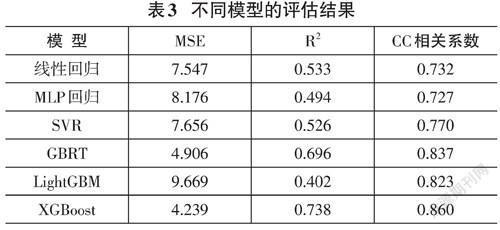
实验结果如表3所示,表中结果为不同模型在测试集上的性能。结果显示MLP回归的性能略低于作为基线的线性回归模型,原因是本文使用的数据集规模较小,导致神经网络不能充分发挥出其对非线性函数的拟合能力。GBRT、LightGBM、XGBoost这三种基于集成学习思想与梯度提升方法的模型的性能显著强于线性回归、MLP回归、SVR这些单体模型,在相关系数指标上相对于SVR获得了至少6.9%的相对提升,表明梯度提升方法可以有效改善PSC命题说话评分任务的最终性能。特别的,基于XGBoost的评分模型在MSE、[R2]、相关系数这三项指标上均取得了最佳的性能,在相关系数指标上,它相对于作为基线模型的线性回归获得了17.5%的相对提升,相对于原始版本的GBRT模型提升了2.7%。
5 结束语
本论文使用机器学习方法对命题说话开展了自动评分研究,使用正确发音的音节数、错读为其他字的音节数、发音错误或不标准的音节数、整体流畅度评分、整体发音标准度评分、音频时长等特征,针对PSC的命题说话模块的自动评分任务提出了基于XGBoost的评分模型。实验结果表明,本论文提出的模型的机器评分与专家评分之间的相关度较高,表明该方法具备较高的可实用性。
注释:
①https://xgboost.readthedocs.io/en/latest/treemethod.html.
②https://cloud.baidu.com/product/speech/asr.
③https://ai.unisound.com/sa-call-eval.
参考文献:
[1] Zechner K,Higgins D,Xi X.SpeechRater:A construct-driven approach to scoring spontaneous non-native speech[C].Proc.SLaTE,2007.
[2] 许苏魁.普通话自由表述口语评测关键技术的研究[D].合肥:中国科学技术大学,2016.
[3] 汤国春.对外汉语看图说话题自动评分模型的构建研究[D].南京:南京师范大学,2019.
[4] 李淇澳,文福安.基于神经网络的开放式口语评分系统研究[D].北京:北京邮电大学,2020.
[5] Fang W J,Zhou J,Li X L,et al.Unpack local model interpretation for GBDT[C]//Database Systems for Advanced Applications.Cham:Springer International Publishing,2018:764-775.
[6] 马晓君,沙靖岚,牛雪琪.基于LightGBM算法的P2P项目信用评级模型的设计及应用[J].数量经济技术经济研究,2018,35(5):144-160.
[7] 王华勇,杨超,唐华.基于LightGBM改进的GBDT短期负荷预测研究[J].自动化仪表,2018,39(9):76-78,82.
[8] 谢勇,项薇,季孟忠,等.基于Xgboost和LightGBM算法预测住房月租金的应用分析[J].计算机应用与软件,2019,36(9):151-155,191.
[9] 邱锡鹏.神经网络与深度学习[M].北京:机械工业出版社,2020.
[10] 李航.统计学习方法[M].2版.北京:清华大学出版社,2019.
[11] Chen T,Guestrin C.XGBoost:A Scalable Tree Boosting System[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,NY,USA:ACM,2016:785-794.
[12] Ke G,Meng Q,Finley T,et al.LightGBM:A Highly Efficient Gradient Boosting Decision Tree[C]//Guyon I,Luxburg U V,Bengio S,et al.Advances in Neural Information Processing Systems:卷 30.Curran Associates,Inc.,2017:3146-3154.
[13] Alsabti K,Ranka S,Singh V.CLOUDS:A decision tree classifier for large datasets[C]//Proceedings of the 4th knowledge discovery and data mining conference,1998,2(8).
[14] 陈振宇,刘金波,李晨,等.基于LSTM与XGBoost组合模型的超短期电力负荷预测[J].电网技术,2020,44(2):614-620.
[15] Berthold M R,Hoppner F.On Clustering Time Series Using Euclidean Distance and Pearson Correlation[J/OL].arXiv:1601.02213[cs,stat],2016[2021-12-16].http://arxiv.org/abs/1601.02213.
[16] Jung Y.Multiple predicting K-fold cross-validation for model selection[J].Journal of Nonparametric Statistics,2018,30(1):197-215.
收稿日期:2022-02-25
基金項目:北京信息科学与技术国家研究中心开放课题(项目编号:BNR2021KF02005) ;《多模态信息感知与智能处理创新团队》天山创新团队计划(项目编号:2020D14044)
作者简介:申云飞(1995—) ,男,江苏连云港人,助理,硕士,研究方向为语音识别、口语自动评测、机器学习系统;刘嘉俊(1998—) ,女,湖南祁阳人,硕士,研究方向为口语自动评测;范智星(1997—) ,男,辽宁大连人,硕士,研究方向为口语自动评测;早克热·卡德尔(1982—) ,女,新疆哈密人,实验师,硕士,研究方向为情感分析;艾山·吾买尔(1981—) ,男,新疆库车人,通信作者,教授,博士,研究领域为多模态自然语言处理。