基于BERT_DPCNN文本分类算法的垃圾邮件过滤系统
2022-05-30彭毅姜昕宇
彭毅 姜昕宇

摘要:近年来,研究表明垃圾邮件已经出现在私人邮箱中,严重扰乱了用户体验。这也已成为各大通信公司的优先研究事项。基于传统的机器学习算法垃圾邮件过滤模型已经得到了充分的研究。随着研究人员在自然语言处理方面的深入研究,深度学习算法及其构建的模型表现效果远强于传统机器学习模型。本文基于现有的各类分类模型进行了研究及比较,讨论了如何对垃圾邮件数据集进行识别,并建立了BERT_DPCNN模型,以改进对电子邮件这种具有独特特征文本的识别方法。本文使用DPCNN作为垃圾邮件分类器,使用BERT預训练模型得到的文本向量作为DPCNN模型的输入,以此加强模型的分类效果,有助于提取到更多的语义信息,以此避免出现深度神经网络梯度消失所带来的问题。根据模型的召回率、准确率和F1指数,BERT_DPCNN模型可以比其他模型更有效地识别垃圾邮件。此外,从实验数据中可以看出,一些涉及深度模型的特征提取方法,如本文中的BERT模型,比基于word2vec的特征提取方法具有更明显的优势。本文构建的BERT_DPCNN模型可以存储更多的语义环境信息,为文本分类提供更多的基础,并提取更深层次的文本特征。它是一个具有最佳整体性能的模型,对垃圾邮件过滤具有重要价值。
关键词:垃圾邮件;分类;BERT;DPCNN
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)22-0066-04
1 引言
电子邮件是一种通过电子方式提供信息交换的交流形式,用户可以在世界上任何地方以非常低的成本联系任何互联网用户。但是由于缺乏足够的监督,大量垃圾邮件的产生和大规模传播,垃圾邮件拦截软件的高速发展迫不及待[1]。因此本文基于最新的语言处理模型BERT提出更加高效的过滤方法。
文本分类是一项重要任务。抛开传统的机器学习算法K-近邻算法、决策树算法等来说,CNN最初是用于文本分类的神经网络模型[2],它是前馈网络,卷积层将每个小数据块转换为向量[3],并且可以并行处理。RNN虽具有循环的连接,但对并行处理不友好。Johnson[4]基于 RNN提出了 LSTM算法,解决了长文本序列中容易出现梯度消失的问题。Merrienboer[5]提出了 Gated Recur-rent Unit (GRU),它是一个简化的 LSTM,但是既保持了LSTM的效果,又节省了训练时间。虽然CNN和RNN都可以使用词序信息,但CNN因其简单性和并行性而更受欢迎,尤其是在训练集比较大时,与字符级CNN相比,词级CNN的层数更浅。虽然字符级CNN的优点是不需要处理大量不同的词,但词级CNN往往更有效。这证实了“单词”的知识可以产生更好的表示。Kalchbrenner[6]提出了一种称为Deep Pyramid CNN的模型,整个模型的计算被限制在小于卷积块范围的两倍。同时,其金字塔的独特结构也让模型能够发现文本中的长距离依赖,因此模型提取全局特征的能力得到了极大的提升。
因此,本文围绕垃圾邮件过滤问题,在NLP中通用的文本分类处理方法上提出了 BERT预训练与 DPCNN相连接来构造效果更高、结果更好的分类器。在词向量方面,以往的神经网络语言模型通常都使用word2vec生成词向量。word2vec由词义的分布式假设出发,最终得到一个look-up table,每一个单词被映射到一个唯一的稠密向量,因此也注定了它无法处理一词多义的问题。而 BERT使用的是 Transformer(中的编码器)作为特征抽取器,这种方法对上下文有很好的利用,不需要像 BiLSTM那样双向堆叠。配合 MLM这样的降噪目标在大规模语料库上进行训练,它的词表示更加动态(相对于word2vec) ,对于一词多义的问题理解上升了一个新高度。
随着深度学习以及迁移学习的发展,研究者开始更多地把深度学习模型应用到自然语言处理领域上去解决实际问题。通过大量查阅文献可以发现构造的模型除了在训练速度上大大缩短了时间,更在模型的准确率上有很大的提升,但是,随着垃圾邮件种类的层出不穷,应用于垃圾邮件的模型还有很大的创新空间。
2 模型构建
本节主要介绍BERT_DPCNN垃圾邮件过滤模型的设计构建。
2.1 模型介绍
首先,本报告中使用的BERT是在传统Transformer模型基础上的改进版本。它采用多头注意力机制,同时添加残差连接;扩展模型关注不同位置的能力,解决了随着网络加深而出现的梯度耗散问题。其次,本文创新提出了用BERT模型代替了DPCNN中的 region embedding,以抓捕更远距离的依赖关系,实现模型质的飞跃。
2.2 BERT框架
BERT模型的输入是一个单一的句子或句子对,每个词都是由相应的3个嵌入特征组成。这三个嵌入特征是:标记嵌入、片段嵌入和位置嵌入。词嵌入是指将一个句子划分为有限的共同子词单元;片段嵌入用于区分两个句子,如两个句子是否为上句和下句;位置嵌入是指将一个词的位置信息编码为一个向量。该模型用[CLS]标记分类模型,非分类模型可以省略;用[SEP]作为句子符号,断开输入语料的前后句子的联系。BERT模型将这3个嵌入式特征作为模型输入。
而它的网络架构使用的是多层 Transformer结构,其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效地解决了NLP中棘手的长期依赖问题。Transformer由6个Encoder和6个Decoder堆叠而成,它接收序列数据,同样输出处理后的序列数据。同时采用了多头注意力机制,相较于自注意力机制,它能为 attention 层提供了多个表示子空间,拓展了模型关注不同位置的能力。每个注意力头都分配一个Query、Key和 Value 权重矩阵;对于每个注意力头,计算其相应的关照程度向量,将得到的向量拼接之后乘以矩阵,就得到最终的注意力矩阵 Z;它的完整计算过程如图1所示:
与传统的自然语言词向量编码不同,BERT模型是一个预训练模型,它采用上下文敏感的句子级向量编码,可以更准确地量化词的含义和同一词在文本中的不同语境。同时,它还可以实现对长文中句子之间的关系进行编码。在使用BERT模型时,需要针对具体任务进行微调,以获得更好的性能。为了实现这一目标,BERT模型通过联合训练屏蔽式LM和下句预测任务,可以获得更全面的词向量表示;这可以更准确地描述输入文本的语义信息。当使用BERT时,不需要改变其核心架构,只需要添加一个新的层即可将BERT模型用于特定任务。
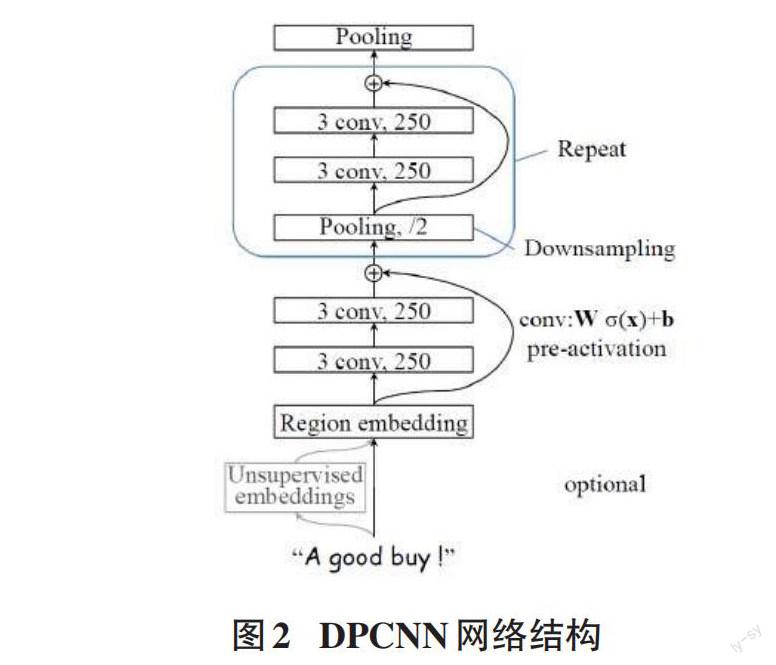
2.3 DPCNN 网络结构
在深度金字塔卷积神经网络中,其结构是卷积层和下采样层的交替;减少了神经网络内部的数据量和每层的计算量,并呈金字塔形状减少,这就是DPCNN得名的原因。DPCNN使用两层等长卷积来提高词汇嵌入表示的丰富性。在每次卷积之后,它将进行最大限度地池化,以此将序列的长度压缩到原始序列的一半;以便于它所能感知的文本段比之前更长。随着网络的深化,该模型可以在文本中发现更长距离的关联和全局语义信息。因此,DPCNN比使用短距离关联的浅层卷积神经网络有更高的准确性。其主要特点如下。
1) 含有一个region嵌入层,即含有多尺寸卷积滤波器的卷积层。具体操作是对文本区域进行卷积运算,得到区域文本的特征图作为嵌入向量。
2) 使用固定数量的特征图进行下采样,这样在进行池化操作时可以降低总的计算复杂性。
3) 等长卷积。这个特征可以压缩每个词组的上下文信息及其左右相邻词的上下文信息,使每个词组的含义更加丰富。DPCNN通过适当地使用双层等长卷积来提高词嵌入的语义丰富性。
4) 残差连接。在DPCNN中,具体的操作是将区域嵌入直接连接到每个区块上;也就是说,直接将区域嵌入连接到最终的池化层或输出层。这使得梯度可以忽略卷积层权重的影响,并将其直接传递给每个区块而没有损失,大大缓解了梯度耗散的问题。
传统的 DPCNN网络结构如图2所示:
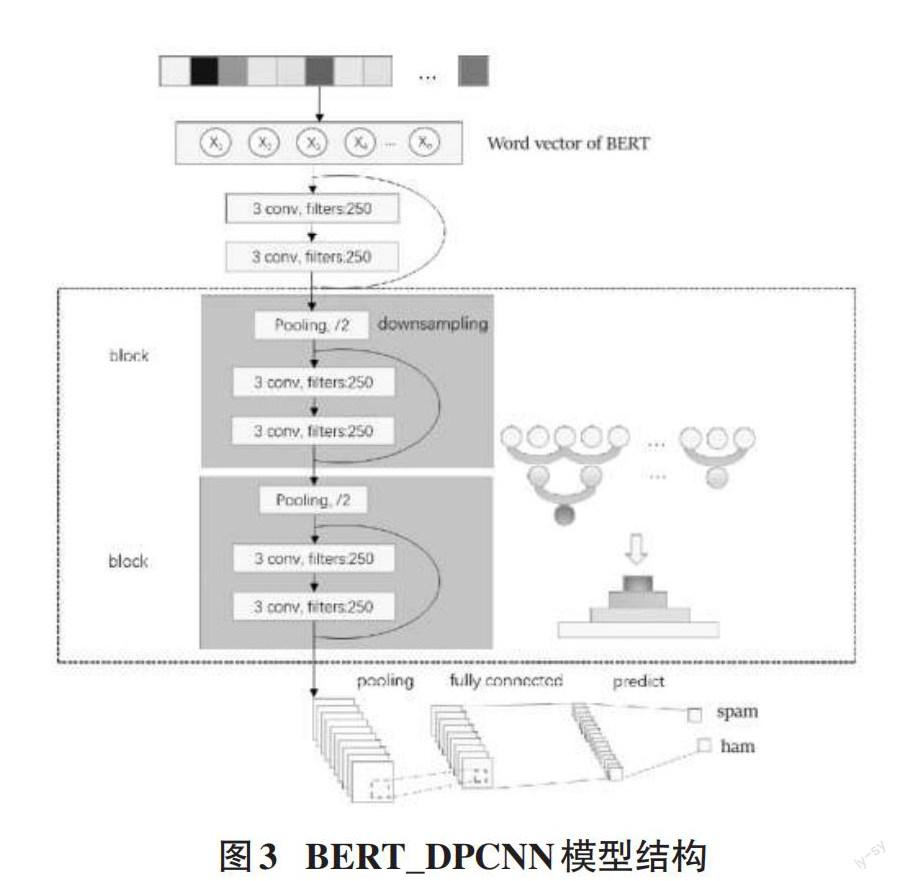
2.4 BERT_DPCNN模型
在DPCNN的实际应用中,一般使用region embedding作为模型的词向量;它是TextCNN的包含多尺寸卷积滤波器卷积层的卷积结果,其本质使用的也是N-gram,模型不能很好地理解语义。因此,本文选择了将DPCNN中的region embedding进行替换,正因为BERT使用了Transformer来提高模型效率以捕获更远距离的依赖,因而可以捕获真正双向的基于上下文的信息。本论文使用基于PyTorch框架的BERT base uncase模型。该模型有 12 个Transformer层、768个隐藏单元、12个self-attention Header和1.1亿个参数。
BERT的预训练模型使用维基百科等数据进行无监督学习(Unsupervised Learning) ,以此提高学习能力。模型BERT_DPCNN首先使用BERT将文本中的每个词在输入层转化为词向量,该过程由语义提取层中的Transformer编码器处理,然后对每个词向量进行拼接,得到向量矩阵X,公式如下:
X1:n= x1⊕x2⊕...⊕xn
卷积过程生成特征使用等长的卷积。h是卷积核W的大小,特征Ci可用以下公式表示:
Ci= f (W *Xi:i+h-1+ b)
上述公式中,f :非线性变换函数,它的过程是先进行矩阵乘法,得到结果后使用激活函数“Relu”来进行非线性变换,最后进行最大池化操作。经过以上步骤,模型获得了电子邮件的高级特征,最终通过连接全连接网络+Softmax层实现了对电子邮件的分类。本模型的结构如图3所示:
3 模型结果
3.1 模型表现
为了更好地观察训练过程以及优化模型参数,本文以100个batch来观察模型的拟合情况以及准确率,通过对训练集以及验证集的图形观察评估,确定了最终的模型效果,如图4所示,能达到准确率为99%的邮件过滤效果。
在整个训练过程中,通过跟踪训练集和验证集的accuracy、recall、F1等参数[7]来监控模型的学习进度。性能评估依照分类报告(见表1) 。从下面的分类报告可以清楚地看出,正常邮件中的召回指数证明99.79% 的邮件可以准确识别。此外,每个类别的F1分数非常相似。换句话说,本文提出的模型在大多数情况下几乎完美地对电子邮件进行了分类。
另一种方式是描述分类器在测试集上的表现。笔者使用的是混淆矩阵(如表2 所示) 或也称为误差矩阵[8],它能计算正确和不正确的预测。在每个类别中进行汇总和分布,这是混淆矩阵的主要特征。通常情况下,混淆矩阵代表分类模型在预测时的“混淆”程度。因此,它可以检查分类器的错误。
3.2 与其他先进模型的比较
众所周知,分类模型中使用的算法从早期的朴素贝叶斯、SVM、LR等经历了长时间的研究和讨论,再到当前的神经网络算法。神经网络模型包括TextCNN、BiLSTM、BiLSTM-Attention和BERT_DPCNN模型。其中BiLSTM是双向LSTM,包括前向LSTM和后向LSTM。
由于时间原因,本文无法构建所有算法的模型进行比较,因此参考了其他学者基于其他算法构建的模型的性能。该模型的性能可以通過该模型的准确率等各项指标进行比较来粗略判断,但是由于使用的数据集存在一定的差异,效果也略有不同。下面将介绍提出的垃圾邮件过滤算法的性能[9]。
该模型结合了基于自注意力的 ALBERT 和 Bi-LSTM 网络。同时他还对比了word2vec和bert词向量,一眼就能看出BERT的优秀表现,表3是其模型结果表。
綜上而言,BERT_DPCNN 模型的实验结果在上述各项指标上都取得了较好的效果,BERT_DPCNN的垃圾邮件过滤模型与传统的垃圾邮件过滤算法性能相比具有显著的优势。从理论上分析,特别是与word2vec特征提取方法相比,本文的垃圾邮件过滤模型可以在词向量环节提取到更多的语义环境信息,因此也可以提供更多的依据实现最大化的文本分类。通过训练结果的对比也可以显示出本文提出的模型具有明显优势,这也说明了本文所提出的基于BERT_DPCNN的垃圾邮件过滤模型值得扩展到实际的垃圾邮件过滤系统中。
4 总结
4.1 讨论与未来工作
尽管已经有很多优秀的垃圾邮件过滤算法,但在现实应用中,垃圾邮件的识别和分类方面还有诸多的问题需要解决。虽然本文提出BERT_DPCNN算法能根据垃圾邮件数据集的特点有效分类和过滤垃圾邮件。但也有一些不足:
1) 本文使用中等规模的数据集进行实验,数据集中正负样本的数量不是很均衡,会在一定程度上影响模型的训练和效果。未来应该考虑使用更真实的大数据集进行训练,实现精准过滤。
2) 本文的识别和分类对象主要以英文字符内容为主。与传统算法比较,在识别的有效性上有一定的提升;未来为了提升模型的准确率,降低分类错误的概率,可以增加邮件发件人、发送频率等信息综合考虑,进一步增强信息的维度。
此外,由于时间的限制,笔者不能探索所有的算法。因此,在未来的工作中,需要进行更多的实验,以与其他模型的性能进行比较。另外,笔者还发现也有一些新的训练前模型,如LXnet可以有更好的性能,这些都值得在未来研究和讨论。
4.2 结论
互联网信息时代的到来,人们身处异地就可以轻松地从用户终端获取信息,但是伴随着出现的恶意信息也给人们带来了巨大的困扰,诞生于这个互联网时代的电子邮件也是如此。一方面,人们可以不受地域限制地随时发送电子邮件进行交流。另一方面,各式各样的垃圾邮件也破坏了绿色健康的通信环境。由于垃圾邮件过滤模型的出现,使这个问题变得迎刃而解,垃圾邮件的识别和过滤将逐渐走向标准化。高效的垃圾邮件过滤系统可以帮助邮件服务提供商更准确地拦截一些骚扰用户、危害用户信息安全的邮件。然而,仍然清楚的是,即使对垃圾邮件识别进行了大量研究,仍然需要优化算法以不断提高用户满意度。主流的垃圾邮件识别方法主要有关键字过滤和后台人工审核,这带来了识别效率低、维护成本高、效率低等诸多问题。为了解决这个问题,本文创新性地提出了一种新的模型识别方法,并通过使用特定数据集来训练提出的模型来进行论证分析,证明该模型具有优秀的垃圾邮件识别效果。
综合全文,本文主要完成了以下研究工作:
1) 首先确定研究方向,查阅该方向的研究现状以及不足,正式提出课题进行可行性分析。通过对相关文献的研究调查,详细了解了电子邮件文本的特点以及垃圾邮件分类技术的现状问题,邮件文字杂乱、特征复杂、语言具有相当程度的独特性。同时,已有文章指出,对于邮件这种类型的文本信息,可以利用BERT模型的词向量来针对性地提取文本特征。
2) 随着迁移学习的发展,BERT模型逐渐流行起来,其在文本分类方面的优越性能也备受关注。因此,为了解决这个问题,本文创新性地提出了BERT_DPCNN垃圾邮件识别模型,在充分学习语义的基础上,通过对有效邮件数据集的训练,得到的模型能够准确有效地提取邮件的特征,并实现垃圾邮件的有效过滤。
3) 评估本文算法的性能。本文使用可信度极高的 kaggle 邮件数据集对模型进行训练和评估。最后的结果表明,本文提出的创新算法在accuracy、recall和F1等方面都表现出色。
参考文献:
[1] Goodman J,Yih W.Online discriminative Spam filter training[C]//. InProceedings of the 3rd conference on email and anti-spam (CEAS),2006.
[2] Konstas I,Keller F,Demberg V,et al.Convolutional Neural Networks for Sentence Classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, October 2014: 1746-1751.
[3] Sanghani G,Kotecha K.Incremental personalized E-mail Spam filter using novel TFDCR feature selection with dynamic feature update[J].Expert Systems With Applications,2019,115:287-299.
[4] Johnson R,Zhang T.Effective use of word order for text categorization with convolutional neural networks[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Denver,Colorado.Stroudsburg,PA,USA:Association for Computational Linguistics,2015: 103–112.
[5] Cho K,van Merrienboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[EB/OL].2014:arXiv:1406.1078.https://arxiv.org/abs/1406.1078.
[6] Kalchbrenner N,Grefenstette E,Blunsom P.A convolutional neural network for modelling sentences[EB/OL].2014:arXiv:1404.2188.https://arxiv.org/abs/1404.2188.
[7] ANGUITA D, GHIO A, RIDELLA S, et al. Kfold cross validation for error rate estimate in support vector machines [C]// DMIN 2009: Proceedings of the 2009 International Conference on Data Mining. Las Vegas: CSREA Press, 2009: 291-297.
[8] Vieira J P A,Moura R S.An analysis of convolutional neural networks for sentence classification[C]//2017 XLIII Latin American Computer Conference (CLEI).Cordoba,Argentina.IEEE,2017:1-5.
[9] VISA S, RAMSAY B, RALESCU A L, et al. Confusion matrix-based feature selection (2011). [C]//Proceedings of The 22nd Midwest Artificial Intelligence and Cognitive Science Conference 2011, Cincinnati, Ohio, USA. April 16–17, 2011:120–127.
【通聯编辑:唐一东】
