基于TF-IDF的贝叶斯模型的垃圾短信识别研究
2022-05-30刘晓蒙
刘晓蒙
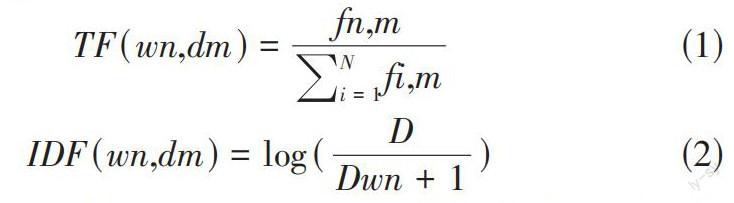
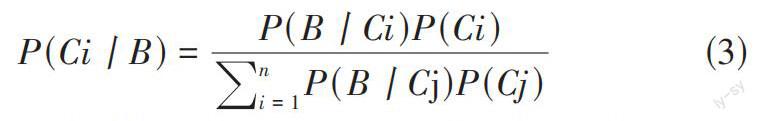

摘要:手机收到垃圾短信已经是一种常态,严重影响了人们的日常生活。结合TF-IDF模型规则,提出了一种基于TF-IDF的贝叶斯模型,特征向采用随机提取的方式,之后进行统一的归一化处理,提高样本的辨识度,以此作为训练集生成对应的模型,最后实现垃圾短信的过滤。最终的实验结果表明:在结合了TF-IDF的贝叶斯模型下,垃圾短信的分类精度更优于一般的贝叶斯模型。
关键词:垃圾短信;贝叶斯;TF-IDF;随机提取;分类
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)22-0064-02
1 引言
大数据时代的来临,智能手机的使用已经非常的普遍,而短信作为人们接收信息的重要来源之一,在大数据时代发挥着越来越重要的地位。但是由于短信内容的丰富性,垃圾短信的问题也渐渐产生并有了泛滥的趋势,这些垃圾短信不仅影响人们对于手机的使用,更重要的在于其带来的安全隐患,许多不法分子借机盗取用户的个人信息,侵害用户的安全隐私。所以对于如何有效地识别垃圾短信就具有重要的现实意义。对于垃圾短信的治理不仅需要有关部门的监管和措施,还可以同时使用数据分析的技术,在其根源消灭这些垃圾短信。
现今研究领域常用的识别短信的方式有基于黑白名单的方法,基于规则的方法和基于短信内容的方法。由于要识别的短信内容较多,因此本文选取基于短信内容的方法,其优点是避免了人工添加的关键词的低效率。
基于短信内容的方法,即文本分类技术是计算机应用于根据特定的分类系统或者标准自动分类文本。传统的文本分类算法有朴素贝叶斯、支持向量机等。本文选取朴素贝叶斯作为文本分类的算法是由于其计算速度快、效率高、应用广泛,同时其良好的稳定性和实现的简单、易于开发的特点能够有效地满足垃圾短信的过滤要求。
基于以上内容,本文提出一种结合TF-IDF的贝叶斯模型[1]。首先对大量的短信数据进行采样,保证垃圾短信和非垃圾短信的均匀分布,随后对短信的内容进行数据的预处理,包括数据清洗、文本去重、中文分词、停用词过滤,之后使用one-hot进行文本的向量表示,同时结合TF-IDF权重策略进行归一化处理,最后将特征向量输入贝叶斯分类器进行分类得到最后的结果。与未使用TF-IDF模型的贝叶斯模型相比,其准确率达到了93.72%、精确度达到88.61%、召回率达到96.44%,F1值为0.9602。实验证明了本文提出的模型的有效性。
2 模型构建
2.1 TF-IDF模型
TF-IDF作为咨询勘探和咨询检索中最常用的加权技术之一,其主要的作用是评估词组对一篇文章的重要性或者是对于一个语料库,其中的某篇文档的重要性[2]。词组的重要性与其出现的频次成正比的关系,与其在语料库中出现的频次成反比的关系。模型主要包含两个主要内容:词频(TF) 和逆词频(IDF) ,TF代表词组wn在文章dm中的出现频率,IDF则是代表类别的区分,公式如下:
[TF(wn,dm)=fn,mi=1Nfi,m] (1)
[IDF(wn,dm)=log(DDwn+1)] (2)
其中dm代表文章集D={d1,d2,d3...dm}当中的任意某篇,m是文章集的总数,dm代表词组的结合w={wn1,wn2,wn3,...,wN},N代表词组的总数,fn,m代表wn在文档dm中出现的次数。Xx代表文章dm中的所以词组的和,D为文章的总数,Dwn表示文章的数据,为了避免分母为零的情况,在分母的位置加1。
2.2 one-hot编码
one-hot编码(独热编码) 又称一位有效码,采用寄存器的形式对状态进行编码,每一个状态都有其对应的寄存器位,同时在任意时刻只有一个状态起效[3]。one-hot编码是常用的将非结构化数据转换成结构化数据的方式,对于一篇由多个词组组成的文章而言,one-hot编码将每个词组表示为一个有效的向量。例:
文本1:My dog ate my homework.
文本2:My cat ate the sandwich.
文本3:A dolphin ate the homework.
[a, ate, cat, dolphin, dog, homework, my, sandwich, the]
文本1:[0 1 0 0 1 1 1 0 0]
文本1:My dog ate my homework
文本2:[0 1 1 0 0 0 1 1 1]
文本2:My cat ate the sandwich
文本3:[1 1 0 1 0 1 0 0 1]
文本3:A dolphin ate the homework
one-hot編码虽然可以将非结构化的数据转换为结构化的数据,但是忽略了句子的词频信息。
2.3 朴素贝叶斯模型
贝叶斯定理作为概率论的基本原理,由18世纪英国数学家托马斯·贝叶斯提出,是对真实世界考虑的一种描述,即人们可以使用有限的经验对未来要发生的事情进行估计。其核心思想是:当不能准确地了解一个事物的本质时,可以借助与该事物相关的事件去估计概率,事件发生得越多则出现的概率越大[4]。贝叶斯定理由于其基于的统计的特性,使得贝叶斯定理在包括医学、灾害预测、文本分类、语音识别等领域使用广泛。
贝叶斯的数学表达通过先验概率和全概率去计算得到对应的后验概率:
[P(Ci丨B)=P(B丨Ci)P(Ci)i=1nP(B丨Cj)P(Cj)] (3)
其中B和C为随机的事件。P(Ci)与P(Cj)同为先验概率,根据先前的经验得到对应的概率。P(Ci|B)为后验概率,在已知B的条件之下,Ci对应的概率。
如何找到最大的条件概率arg maxP(c丨b),就是朴素贝叶斯的核心,即朴素贝叶斯分类公式:
[argmaxP(ci丨b)=argmaxP(b丨ci)P(ci)cinP(b丨ci)P(ci)] (4)
其中,c∈C、b∈B,通过先验概率计算得到对应的后验概率。
2.4 实验数据
本文使用的短信基数为80万条,由于垃圾短信的占比和非垃圾短信的占比差距较大,在筛选数据的时候,采用抽样的方式进行,保证最后数据中,垃圾短信的占比和非垃圾短信的占比各占50%,其中80%的数据作为样本训练,其余的作为样本的测试。
数据预处理和参数设置:
由上表可知,在原始数据中包含了很多无用的符号、空格,还有很多不标准的数据,导致了数据无法直接使用,首先要进行数据清洗,对原始数据进行处理,包括去除空格、文本去重、中文分词、去停用词。
2.5 评价指标
本文以准确率Precision,召回率Recall和F1作为模型性能的评价指标,公式如下:
[Precision=NrightNright+Nwrong] (5)
[Recall=TPTP+FN] (6)
[F1=2×Precison×RecallPrecison+Recall] (7)
其中Nright,Nwrong,TP,FN分别代表分类中的数量、错误的数量、非垃圾短信被判断成非垃圾短信的量和非垃圾短信被判断成垃圾短信的量[5]。
本文采用十字交叉法评估准确率。
3 实验步骤
数据准备:整理实验需要的相关数据,安装对应的实现软件,本文程序由python代码实现。
数据处理:采用随机抽样的方式对数据进行抽样处理,保证最后的正常短信的分布和垃圾短信的分布比例。同时对文本进行相关的处理。
模型建模:采用one-hot编码对文本数据进行建模,为了对比两种模型的准确性,一种采用one-hot编码,第二种采用one-hot与TF-IDF相结合的方式进行文本建模。之后采用贝叶斯公式对向量化的数据进行计算和分类。
结果展示与分析:采用可视化的方式对最后的实验结果进行展示和实验分析总结。
4 实验结果
本文设计了两组对比实验,分别使用了one-hot 高斯贝叶斯模型,one-hot结合TF-IDF的高斯贝叶斯模型。对两种模型根据不同的训练集进行实验的结果如下:
5 模型下对比分析
两种模型的准确率可以看出,在结合了TF-IDF的贝叶斯模型其准确率比没有使用TF-IDF的模型要有一定的提升。
通过上述实验,可以得到结论:在充分考虑了词频后,模型的精确度得到有效的提高,可以达到更好的分类效果。
6 结束语
本文将one-hot与TF-IDF模型相结合放入高斯贝叶斯模型中,设计出的结合TF-IDF 高斯贝叶斯模型,将其使用在垃圾分类领域,通过两组实验对比,验证了改模型具有良好的分类效果。
由于TF-IDF只是考虑了词与文档之间的关系,并沒有充分考虑到上下文当中词与词之间是否存在某种联系,所以在日后的工作中,优化TF-IDF的计算方法,使得改模型可以在以后的应用中发挥更佳的效果。
参考文献:
[1] 金小梅,毛本清.基于改进贝叶斯算法的垃圾短信过滤研究[J].科技与创新,2019(6):21-23.
[2] 王红,王雅琴,黄建国.基于文本分词朴素贝叶斯分类的图书采访机制探索[J].现代情报,2021,41(9):74-83.
[3] 雷朔,刘旭敏,徐维祥.基于词向量特征扩展的中文短文本分类研究[J].计算机应用与软件,2018,35(8):269-274.
[4] Kim Y,Jernite Y,Sontag D,et al.Character-aware neural language models[EB/OL].2015:arXiv:1508.06615.https://arxiv.org/abs/1508.06615
[5] 唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J].计算机科学,2016,43(6):214-217,269.
【通联编辑:王力】
