基于Java多线程的智能图片爬虫系统的研究与实现
2022-05-30黄子纯蔡敏
黄子纯 蔡敏


摘要:针对在传统的爬虫系统中,按照一定规则自动抓取相关信息时,通常包含大量的无效信息这一问题,提出了一种基于Java多线程的智能图片爬虫系统。该系统以爬取图片为例,利用HttpClient、JSoup、WebMagic框架以及线程池技术,实现了在传统爬虫系统基础上增加图片筛选模块,可以智能爬取有效图片,并且自动过滤重复图片,进一步优化了基于Java多线程的传统爬虫系统。
关键词:网络爬虫;多线程;HttpClient;JSoup;WebMagic
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)22-0055-03
1 引言
随着人工智能领域的不断发展,诞生了许多分支研究。不管是语音处理,图像识别,还是自然语言处理,都面临着需要大量数据集的问题,人工收集数据需花费大量的时间与精力。解决这一问题的技术就是爬虫技术,因此爬虫技术也成为获取数据集的重要工具。
对于传统的爬虫来说,爬取得到的数据集并不能保证正确性与完整性,以爬取图片为例,爬取到的图片一方面会得到重复图片。另一方面,既不能保证得到的图片格式是正确的(比如png或gif格式会直接转为jpg格式) ,也不能保证爬取得到的图片是完整的(比如下载的图片只显示一半) ,因此传统的爬虫系统在爬取数据之后,反而需要消耗大量时间筛选有效数据,造成资源浪费,在大数据环境下,数据爬虫的有效性也是非常的重要,因此本文以爬取图片为例,利用HttpClient、JSoup、WebMagic框架以及线程池技术,实现了智能爬取有效图片,在爬虫阶段,实现自动过滤重复图片,有效提高了图片的正确性。
2 爬虫相关技术
2.1 爬虫技术介绍
爬虫技术的出现有效简化了人工收集数据的烦琐流程,其主要作用是在互联网的众多页面中,通过特定的程序,按照一定的规则遍历网页信息,爬取所需的信息,并将爬取得到的信息数据进行存储,爬虫技术具有网页采集,网页分析以及数据存储三个模块,其特点包括以下几部分:
分布式——可以在分布式环境中跨多台计算机同步进行。
高质量——爬虫技术获取得到的页面普遍质量较高[1]。
实时性——对于随时更新的页面,例如,新闻、更新小说等,能保持爬取得到的数据具有实时性[2]。
可扩展性——爬虫程序的可扩展性能够适应不同数据格式以及不同协议[3]。
在进行大数据分析或者进行数据挖掘的时候,需要有数据源进行分析。爬虫技术的诞生,满足了对日益增加大量数据源的需求,爬虫技术自动抓取数据内容,爬取得到数据集,再进行更深层次的数据分析、图片识别、语音识别等人工智能领域方面的研究,获取更多有价值的信息。
2.2 HttpClient技术介绍
HttpClient是Java网络爬虫的核心技术之一,网络爬虫是通过程序自动爬取网络上的资源,而互联网的访问网页协议使用的都是http协议,http协议主要规则是针对文本、声音、图像等之间信息交换的面向事务的应用层协议[4]。HttpClient在面向http协议编程时,极大降低了编程的复杂度,并且其支持最新的协议版本。
2.3 JSoup技术介绍
JSoup是一款功能较大的第三方开源HTML解析器,能够通过对网页中的文本标签的属性,针对不同格式的文本内容进行解析。通过JSoup提供的一套API,能够非常方便地对所需数据进行解析和操作[5]。JSoup一方面在浏览器中找到相应源码后,能够针对HTML中的URL,文件或字符串找到对应标签并进行解析,另一方面能够通过不同选择器来抓取所需数据,其功能的强大在于,只需在浏览器中查找源代码,找到所需内容对应的标签,便能够对任意格式的文本图片进行解析。
2.4 WebMagic框架介绍
WebMagic框架包括核心和扩展两部分,将其代码模块化是WebMagic框架的主要目标。其中,核心部分(WebMagic-Core)实现了代码的模块化,扩展部分(WebMagic-Extension)则提供了注解模式、内置常用组件等一系列功能,更便于网页爬虫实现。
WebMagic包含了 Downloader、PageProcessor、Scheduler、Pipeline 四大组件[6],由Spider把这四大组件组织起来,使其可以互相交互,流程化地执行相关操作。其中,Downloader表示爬虫生命周期中的下载、PageProcessor表示爬虫生命周期中的处理、Scheduler表示爬虫生命周期中的管理和Pipeline表示爬虫生命周期的持久化功能,而Spider是一个大的容器,也是WebMagic逻辑的核心。
2.5 线程池技术介绍
线程池技术广泛应用于解决线程消耗资源问题,在执行具体任务的过程中将其添加到线程池中,相当于对所有任务进行统一管理,当线程创建完成之后,线程池中的任务会自动启动。多个线程能够同时抓取数据,可以实现程序多任务执行。随着多核处理器在现代计算机设备中的流行,在软件中使用多线程程序的频率也随之增加,多线程技术可有效提高程序运行效率,但是多线程的模式需要不停地建立与摧毁线程,虽然同生成进程相比,创建线程的时间已经很短了,当这个操作被大量执行,依然会造成很多时间资源的浪费[7]。而线程池主要目标就是对线程资源进行统一管理,线程池的优点是节约了线程的创建和销毁所占用的时间[8]。
3 智能图片爬虫系统介绍
3.1 智能图片爬虫系统功能架构
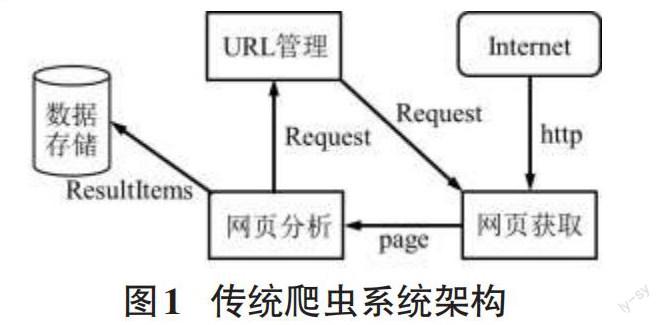
传统的爬虫系统使用WebMagic框架,其主要功能模块为网页获取模块,该模块主要获取得到具体网页;网页分析模块,该模块主要功能为解析具体网页内容;数据存储模块,该模块将爬取得到的数据进行存储。其中,传统爬虫系统中的网页获取与网页分析可以为一个模块组,且该模块组为实现功能主要模塊,该模块组内含网页获取、网页分析、URL管理三大模块。如图1所示。
图1中架构显示,用户提交http请求,在得到响应后,从Internet上获得网页上的 URL,这一过程中,获取得到的可能是HTML、JSON或者其他文本格式的内容。接着进行使用JSoup对page解析,并且不断地从当前页面上抽取新的URL放入到URL管理模块中,其中,网页分析模块会对当前网页的URL进行保存,而Request就是对URL地址的一层封装,发出一个Request请求也就对应一个URL地址。通过网页分析后得到的Resultltems相当于一个集合,爬取得到的数据放在Resultltems中,最后对其进行数据存储。本文在传统爬虫系统的基础上增加了一个筛选图片功能模块,如图2所示。
智能图片爬虫系统的功能模块包括网页获取与分析模块,该模块组内含网页获取、网页分析、URL管理、图片筛选以及数据存储五大模块。
3.2 智能图片爬虫系统功能模块介绍
1) 网页获取。传统网络爬虫的基本原理是,HttpClient创建对象相当于创建浏览器,传统爬虫系统通过http请求,发送给指定页面,得到响应后,便可对网页进行分析,并完成相应的数据爬取。
2) 网页分析。网页分析模块将存储在HTML框架中的文本一一解析,从具体标签中爬取有效信息,常用的方法包括通过字符串处理工具和使用正则表达式提取文本数据。但是这些方法都会带来很大的开发成本,所以本文使用一款专门解析HTML页面的技术JSoup实现网页内容提取。
3) URL管理。在数据进行解析的过程中,会出现两种情况,一种是在当前页面已经拿到所需数据,则可直接进行图片筛选,反之,需再次请求新的URL,本模块将抽取得到的URL进行统一管理,保存完成后可直接进行解析。
4) 图片筛选。图片筛选模块的基本流程如图3所示:
图片筛选模块对两张图片进行像素比对,在获取得到图片的像素个数大小后,使用循环的方式,对两张图片的像素进行一一对比,在循环过程中,一旦比较确认两个像素点不同,则退出循环,计算相似度。
5) 数据存储。爬虫得到数据集后需存储数据,一种方式可以将数据集存储到本地文件,另一种方式将数据集保存到数据库。爬取少量数据则可选择保存到本地文件这一方式,大量数据一般选择保存到数据库。数据库可以选择使用MySQL数据库,这是一个开源的数据库。MYSQL数据库体积小、灵活性强、速度快,这保证了爬虫的效率。
3.3 智能图片爬虫系统实现
智能图片爬虫系统具体实现是创建HttpClient对象,对目标网页发出请求,得到响应后则开始解析网页内容,解析过程中会将URL进行统一管理,抽取到URL管理模块,当前响应内容存在所需图片时,便可抓取图片对图片进行筛选,筛选完成后存入数据库中,当前响应内容不存在所需图片时,可通过URL管理模块抓取得到所需图片。具体实现如下所示:
1) 网页获取模块实现
传统的网络爬虫使用HttpClient创建对象,通过设置URL直接获取访问地址并解析,核心代码如下:
//使用Httpclient发起请求,获取响应
CloseableHttpResponse response = httpClient.execute(httpPost);
//解析响应
if (response.getStatusLine().getstatusCode() == 200){
string content = EntityUtils.toString(response.getEntity(),"utf8");
}
HttpClient每次创建对象相当于创建一个浏览器,同样销毁对象相当于关闭浏览器,可以看出每次请求都要创建 HttpClient,会有频繁创建和销毁的问题,因此本文使用连接池来避免出现频繁创建和销毁问题,核心代码如下:
//创建连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
//使用连接池管理器发起请求
doGet(cm);
//从连接池中获取Httpclient对象
CloseableHttpClient httpClient = HttpClients.custom() . setConnectionManager(cm).build();
2) 网页分析模块实现
获取到访问地址之后并不是我们真正需要的数据集,还需对其进行解析,核心代码如下:
//解析HTML标签
Document doc = Jsoup.parse(new File(“访问路径”),“utf-8”);
//获取所有图片
Elements element = doc.body().getElementsByClass("具体元素").select("li");
3) URL管理实现
URL管理模块保存的是页面中抓取到的超链接地址,网页分析模块会自动请求该页面并分析获取信息。本智能图片爬取系统以爬取“图片之家”为例,按照实际页面结构获取URL。核心代码实现如下:
//获取图片链接
page.addTargetRequests(page.getHtml().css(“具体标签”).link().all());
4) 筛选图片模块实现
使用注解单一属性定义两张图片,预先分析得到的图片定义为预期图片,后分析得到的圖片定义为实际图片,之后对这两张图片进行对比,核心代码如下:
//像素比较
if(imageInput == imageoutput){
for (int j = 0;j if (imagefileInput.getElem(j) != imagefileOutPut.getElem(j)) { imageG++; }} }else { flagF=(imageInput+imageoutput)/2; } //计算相似度 double similarity=1-(double)( imageG *2)/( imageInput+imageoutput); 5) 数据存储实现 目前已经实现将筛选得到的图片保存在内存,还需将图片保存到数据库中。在WebMagic框架中用于抽取结果进行保存会使用pipeline 做一个输出,但其没有保存到数据库的输出,而考虑到这一问题后,设计了pipeline 的接口,接口中只有一个方法,只需要实现这个方法就能实现数据库存储,核心代码如下: //图片到数据库中 this.jobJnfoService.save(jobInfo); 4 結束语 本文基于Java语言开发,在eclipse IDE 2021.3版本基础上通过实现Java多线程智能图片爬虫程序,可以表明通过增加筛选图片模块能够减少图片的重复性,并且能够提高其有效性。但本文所设计的系统还需进一步完善,比如在进行图片筛选时,存在智能图片爬虫系统所消耗的时间和占用系统资源较大的问题。此外,目前许多网站都会对网络爬虫做一定的限制,请求访问网页的程序当线程和进程数量过多时会被禁止,没有实现代理机制,所以智能图片爬取系统效率的提升在实际环境中还有较大优化空间。 参考文献: [1] Yu L X,Li Y L,Zeng Q T,et al.Summary of web crawler technology research[J].Journal of Physics:Conference Series,2020,1449(1):012036. [2] Pavai G,Geetha T V.Improving the freshness of the search engines by a probabilistic approach based incremental crawler[J].Information Systems Frontiers,2017,19(5):1013-1028. [3] Deka G C.NoSQL web crawler application[J]. Advances in Computers, 2018,109:77-100. [4] 李尚林,陈宫,雷勇.基于Java的网络爬虫系统研究与设计[J].新型工业化,2021,11(4):74-77,80. [5] 熊艳秋,严碧波.基于jsoup爬取图书网页信息的网络爬虫技术[J].电脑与信息技术,2019,27(4):61-63. [6] 孙德华.基于RPA的财务工作辅助系统的设计与实现[D].南京:南京邮电大学,2021. [7] 赵静文,付岩,吴艳霞,等.多线程数据竞争检测技术研究综述[J].计算机科学,2022,49(6):89-98. [8] 王林.基于Linux的高并发网络聊天系统设计[J].智能计算机与应用,2020,10(7):176-179. 【通联编辑:谢媛媛】
