基于组合预测法对云南省粮食产量的预测
2022-05-30陈婷怡王皓晔
陈婷怡 王皓晔
(电子科技大学成都学院,四川 成都 610000)
1 概述
粮安天下,农稳社稷。粮食安全对于国家经济发展、社会稳定起到重要的基础性作用[1]。而粮食生产是粮食安全的重要内容,虽然近年来我国粮食产量保持稳定增长,2021 年粮食总产量超过1.3 万亿斤,但当前国际形势变幻莫测,地缘政治冲突不断升级,我国的粮食安全也面临着诸多风险和挑战。云南省山区面积大,贫困问题较为突出,但在中国的“一带一路”倡议中,云南省凭借着毗邻南亚和东南亚的位置优势,又充分发挥着至关重要的桥梁和纽带作用[2]。因此,对云南省未来一段时间的粮食产量进行预测和分析,能够为粮食宏观调控提供重要依据,从而有利于促进边境地区经济发展。
目前学者们结合定性分析和定量分析在粮食安全评估和粮食产量预测方面进行了深入的研究。在评估粮食安全问题方面,李秀香和和聪贤(2020)从四个维度构建了粮食安全综合评估指标体系,分析发现我国粮食生产及供给存在结构性安全隐患[3]。丑洁明等(2022)研究了气候变化对粮食安全的风险影响[4]。针对粮食安全的评估,粮食产量通常是一个重要的指标。预测粮食产量的常见研究方法主要分为单一模型预测法和组合预测法,而建立单一预测模型相对简单,因此该方法的应用更加广泛,通常有时间序列模型[5]、支持向量机模型[6]等。在组合预测方法的研究中,孟国庆等(2019)指出灰色预测与神经网络的组合预测模型在一定程度上提升了预测精度[7]。樊超等(2019)构建了基于小波变换的GM(1,1)-ARIMA 组合模型,并证实分析了该模型具有良好的预测效果[8]。
综合来看,学者们在国家粮食安全评估和粮食产量预测方面做了非常有益的研究。在预测粮食产量的方法中,组合预测模型相对灵活,在一定程度上可以减小单一预测模型造成的误差。鉴于此,本文以云南省作为研究对象,将二次指数平滑模型、灰色GM(1,1)模型和支持向量回归模型进行组合优化,构建线性组合预测模型拟合2001-2017 年的数据,同时通过2018-2022 年的数据检验模型,最后对2021-2023 年云南粮食产量进行预测。
2 研究方法
2.1 二次指数平滑模型
二次指数平滑法是在一次指数平滑的基础之上发展而来的,其原理是将一次指数平滑值再次平滑,从而通过两次平滑处理所得到的数值来修匀时间序列的线性趋势,是一种适用于中短期预测的方法。其平滑公式为:
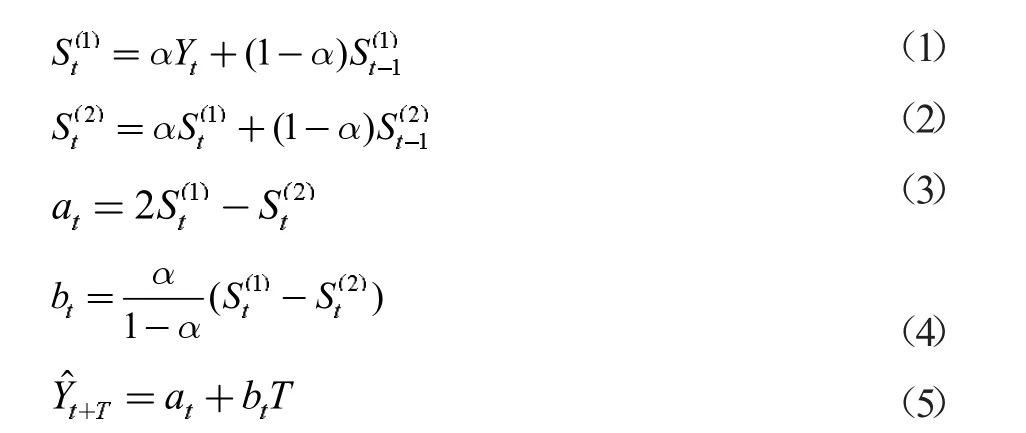

2.2 灰色GM(1,1)模型
由于粮食产量的样本数据具有少信息、不确定性等问题,而灰色GM(1,1)模型能较好地揭示少数据、少信息系统的演变规律,因此,本文将GM(1,1)模型纳入组合模型。

其中a 和b 为模型参数,通常情况下其估计值可以通过最小二乘法获得。
2.3 支持向量回归模型(SVR)
支持向量回归模型(SVR)是基于支持向量机(SVM)理论基础的一种回归算法。与传统回归模型不同,SVR对小样本、非线性的样本数据的拟合效果较好,这是由于SVR 以找到一个最接近所有样本点的平面为目标,从而使得该模型的泛化能力较好。模型公式如下:
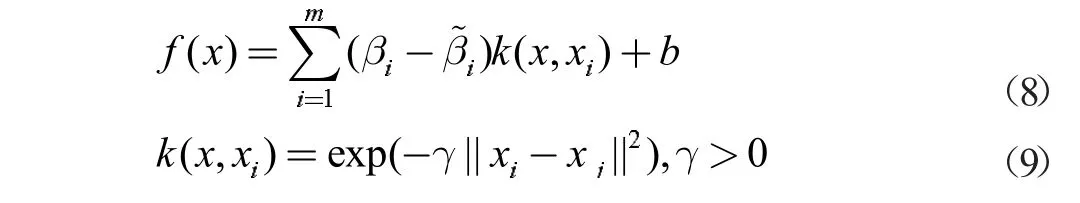
其中,k(x,xi)为核函数,γ、β 和b 均为参数,且βi-β^i≠0;xi为相应的样本点。
2.4 线性组合预测模型
组合模型是通过给予不同的单一预测模型相应的权重而形成的一种预测模型。组合预测模型在拟合数据方面更灵活,进而有助于提升预测精度。本文采用线性组合预测模型对三种单一模型进行权重分配,并求出权重系数,以此提高预测模型的可靠程度,其公式如下:

其中,y0t为t 时期的组合预测值;y1t,y2t,…,ynt分别为n 种不同模型在t 时期的预测值;W1,W2,…,Wn为相应的n 种组合权数[9]。
3 实证分析
3.1 数据选取及预处理
考虑到影响粮食产量到的因素众多,本文在建模时则采用小样本进行拟合,因此,选择云南省2001-2020 年的粮食产量数据作为研究对象,所有数据均来自国家统计局官方网站。Python 和SPSS 为本文数据处理过程中所使用的主要软件。云南省近20 年粮食产量的散点图如1所示。
从图1 中可以看出,云南省粮食产量从2001 年到2011 年间波动较大,这段时期内粮食主要由人工种植,受气温、降雨量等环境因素影响较大。2012 年到2017 年间,随着农业智能化的发展,粮食产量不断增加,呈现出稳步增长趋势。
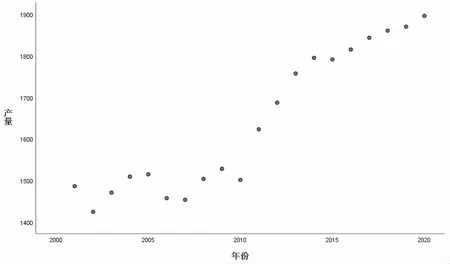
图1 云南省2001-2020 年粮食产量(单位:万吨)
3.2 基于线性组合模型的粮食产量预测
3.2.1 建立二次指数平滑模型
由于2008-2017 年间绝大部分样本数据呈现出线性趋势,因此,本文采用二次指数平滑法对其进行分析与预测。考虑到平滑常数α 的大小对预测结果的影响,本文计算了9 个平滑常数的均方误差(MSE),如表1 所示。
由表1 可知,当α=0.2 时,MSE 最小,以此建立二次指数平滑预测模型为:

表1 不同平滑常数的MSE 对比表

3.2.2 建立灰色GM(1,1)模型
灰色GM (1,1) 模型适用于极少样本预测,通常以6-15 个样本量为宜。因此,本文选择2011-2017 年的云南省粮食产量作为样本数据纳入该模型。拟合结果如图2 所示。从图2 中可以看出,通过这一模型拟合得到的2018-2020 年预测值与真实值大致是重叠的,则拟合效果较好。
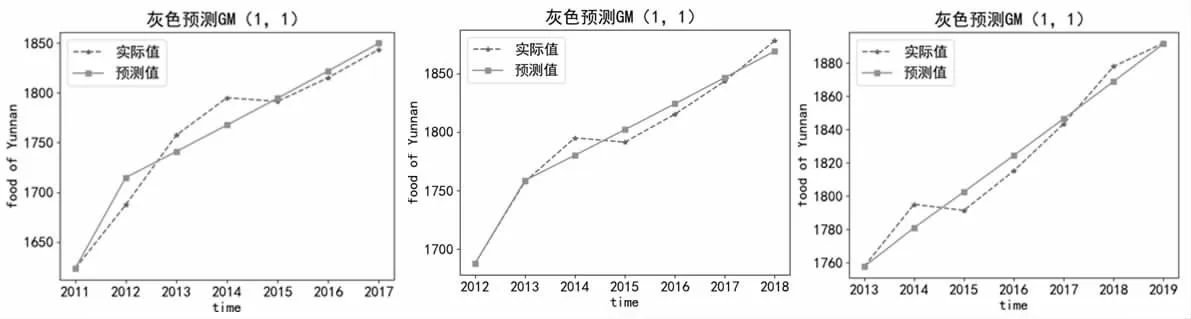
图2 灰色GM(1,1)模型的粮食产量拟合结果(单位:万吨)
3.2.3 建立支持向量回归模型(SVR)
考虑到支持向量回归模型(SVR)能够解决非线性的问题,本文将样本数据全部纳入模型。拟合结果如图3所示。从图3 中可以看出,云南省的粮食产量真实值大多分布在拟合平面的附近,拟合度较高。
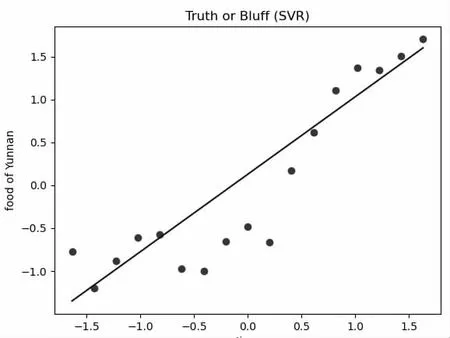
图3 支持向量回归模型(SVR)的拟合结果
3.2.4 建立线性组合预测模型
基于上述三种单一模型得到的预测值,本文进一步构建线性组合预测模型加以组合优化,权数由方差倒数法求得。权数结果如表2 所示。
将表2 中的权数代入得到线性组合预测模型为:
3.2.5 模型的评价及预测
在评价预测结果的可靠程度方面,采用平均相对误差作为评价指标是比较合理的,一般情况下平均相对误差值越小,表明模型精度越好。鉴于此,本文采用上述预测模型对2018-2020 年的粮食产量数据进行预测,并计算比较不同模型的平均相对误差,预测结果和平均相对误差如表3 和表4 所示。
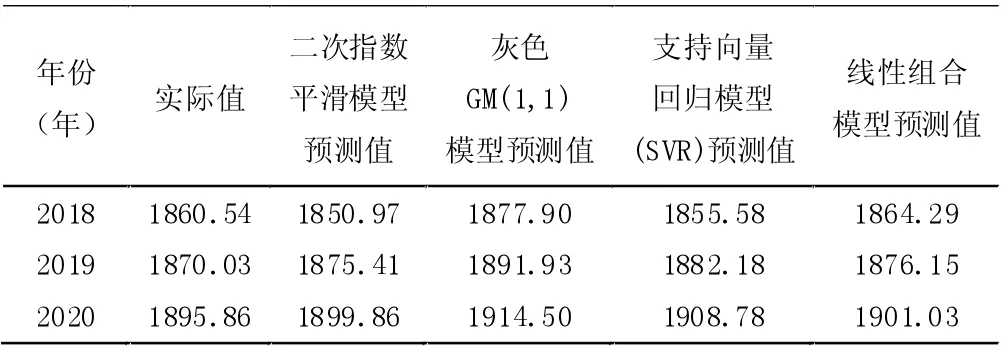
表3 云南省2018-2020 年粮食产量预测结果(单位:万吨)
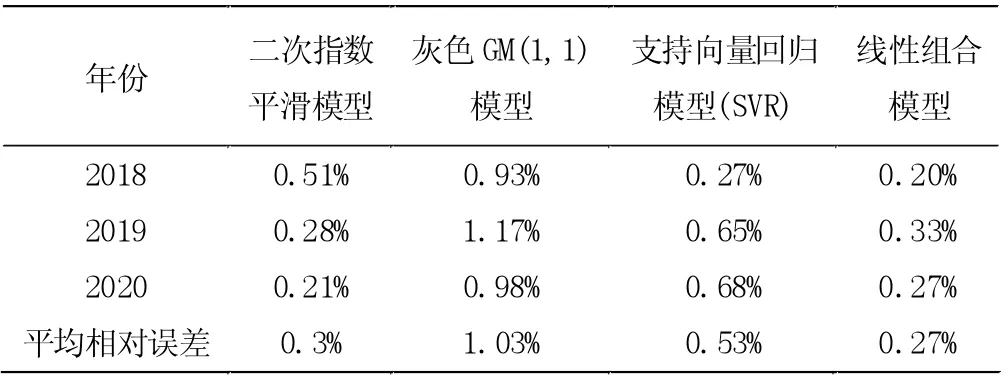
表4 各预测模型的预测误差与平均相对误差
由表4 可知,线性组合预测模型的平均相对误差最小,仅为0.27%;相较于其他三种模型,该模型的误差基本为0.3%左右,显然波动较小,即组合预测模型抵抗外部因素干扰的能力优于单一预测模型。鉴于此,本文采用线性组合预测模型对云南省未来三年的粮食产量进行预测,结果如表5 所示。
由表5 可知,2021-2023 年云南省的粮食产量分别为1928.86 万吨,1953.94 万吨,1978.92 万吨,呈现出稳步增长的趋势。

表5 云南省2021-2023 年粮食产量预测结果(单位 万吨)
4 结论
前文研究结果表明线性组合预测模型更灵活稳定,其平均相对误差仅0.27%,具有较高的预测精度。因此,采用线性组合预测模型预测云南省的粮食产量更接近客观实际,为云南省的粮食安全管理和农业政策制定提供了重要依据。从预测结果来看,云南省2021-2023 年粮食产量呈现出稳步增长的趋势,正常情况下,2023 年粮食产量将达到1978.92 万吨。但当前国际形势变幻莫测,不确定性风险持续上升,为进一步确保云南省粮食总产量稳定增长,应加大政策支持力度,落实好各种补贴政策,以政策调动农民生产积极性,同时,依托科技提高粮食质量和产量,以保障粮食安全,促进经济持续健康发展。
