基于大数据的大用户用电需求控制模型研究
2022-05-30李勇涛
彭 茁 王 翔 李勇涛
(国网合肥供电公司,安徽 合肥 230022)
业扩报装业务泛指从客户提交用电申请需求至实际成功用电的该段电力企业业务流程,其具体过程包括客户申请的确认、供电方案的确认、供电合同的确认以及最终的装表供电。该业务将电力企业与用户之间的供用电关系紧密连接。用户在最终的装表供电完成后,一般会经历一段时间的周期负荷调整过程,随着时间推移电量显著提升,直至用电维持在一个稳定的合理的区间。业扩报装业务具有以下方面的特性:一是具有确切的目的性,其目的是提供给到客户安全、稳定以及经济的用电服务。二是具有较强的时间紧迫性,供电公司需在最短时间内为客户提供送电服务,其对供电公司在业务流程和进度管理上要求颇高。三是具有多对一的响应关系,多个客户对接同一家供电公司的情况普遍存在。四是具有多部门协同合作性,该业务牵涉供电公司多个部门的多个业务,不同部门间的协作能力及部门沟通尤为重要。五是具有用电需求的复杂性,不同类型的用电客户存在不同的用电需求,及时满足多样的客户需求对供电公司提出了更高的要求。
在电改背景下,业扩报装业务既是提高供电服务水平的关键一环,也是拉升电网资产利用率的重要一步。多项电力因素影响着业扩报装需求的确定,设备容量等参数预留大多采用经验预估的方式,这既可能因为电网预留容量不足导致电力供应不能满足实际需求,也有可能因为预留容量过大使得电网设备利用率较低。故本文从两个方向开展大用户用电需求预测,实现精准量化大用户业扩报装需求,以更好提升客户用电满意度和电网设备利用率。(1)构建基于大数据的电力大用户业扩报装需求容量测算模型,通过数据模型量化报装需求。(2)从用电类别出发计算不同用电类别下的需要系数和同时系数,对大用户供电需求进行预测。
1 大用户级别业扩报装预测模型
大用户级别业扩报装需求控制模型研究包括以下方面:(1)确定和业务研究目标相关的影响特征。(2)确定研究的模型。(3)进行数据探索和特征工程。(4)构建需求控制模型,并验证模型结果。
1.1 影响特征表
采集某地区共计350 户专线大用户作为研究对象,搭建大用户业扩报装需求模型。基于业务特征,尽可能列举出对业扩报装有影响的所有因素,共计14 个特征。(1)用户信息:包括户名、户号、行业类别、人员数量、注册资金和区域。(2)用电信息:包括用电类别、供电电压等级和电源点个数。(3)电力数据:包括每日最大负荷、用电量和容量。(4)经济数据:包括行业GDP。
1.2 大数据模型处理方法
本文采用多种机器学习模型方法实现对大用户用电需求控制模型的研究,主要采用多元线性回归,k 近邻法和集成学习算法等回归模型实现对用电需求进行预测分析。


1.2.2 k 近邻回归模型:k 近邻回归模型是指利用该样本周围最接近的k 个样本的属性去预测该样本的值。一般采用平均值或者平均法来定义该样本的输出。同时样本的分布规律决定了k 值的选择方向,而k 值的选择也影响了模型的结果:一种是较小的k 值导致训练误差的降低和泛化误差的加大,另一种是较大的k 值导致训练误差的增大和泛化误差的降低。
1.2.3 集成学习回归模型:集成学习算法是一种将来自多个机器学习算法的预测值结合在一起的技术,比任何单独模型做出的预测更为准确。本文集成学习模型涉及Bagging和随机森林两类回归模型。
Bagging:Bagging 从Bootstrap 和Aggregating 两词结合而来,其算法逻辑是从训练集中通过有放回采样的方式获得不同的子训练集,在不同的子训练集上独立训练出多个不同的弱学习器,将多个弱学习器的结果进行一定的整合,以此作为最终的预测值。Bagging可以并行地训练多个不同的弱学习器,并行的特性可以提高模型的运算速度。回归问题的结果整合可采用均值方法。有放回采样的方式可自动实现将63%的样本作为训练集,而剩下的样本作为验证集。Bagging最明显的优势是可用来降低模型的方差。

图1 Bagging 方法示意图
随机森林:随机森林继承了Bagging 模型的基本思想,但对Bagging进行了两处改进:(1)其将决策树作为弱学习器,因为决策树是不稳定学习器,故适合进行Bagging操作。(2)同时对特征进行随机采样而形成特征子集,避免过拟合,以此增加各子决策树间的差异性。随机森林的优势体现在以下几点:一是对大规模数据集具有良好的性能;二是对高维特征具有较好的处理能力而无须进行降维操作;三是对于特征中的缺省值不敏感,具有较好的鲁棒性。回归问题的结果整合可采用均值方法。
1.3 数据探索和特征工程
1.3.1 相关性分析。变量间的相关性分析是将特征变量和目标变量间的线性关联进行直观体现,其计算的相关系数结果可作为特征工程中提取特征项目的依据。通过皮尔逊相关系数可直观查看变量间的关联,其衡量的是线性关系的强度和方向。假设有两个特征x和y,按照以下方式比较他们的每个元素,从而计算皮尔逊相关系数:

(2)哑变量通常是指人为虚设的变量,取值为0 和1,用来反映某个变量的不同属性特点。哑变量编码是将类别变量转换为哑变量,也就是将定性变量进行了量化处理。引入哑变量的目的即是为了评测定性变量对预测结果的影响。对人员数量进行有序编码,对电源点个数变量进行指定编码,对电压等级、行业类型和用电类别进行虚拟编码。
1.3.3 特征选择。特征选择是指在映射函数作用下直接将不重要的特征删除而抓住主要影响因子的过程。变量越少越有利于分析,对模型结果的可解释性越高。本文的特征选择方法是包装法,其算法逻辑是用递归特征消除法来达到筛选重要因子的目的。递归特征消除法是指在特征空间中抽取特征子集,在特征子集上构建相应模型,迭代该过程,遍历所有特征空间,通过模型结果来筛选表现最佳的特征子集。最终进入模型的特征有35 个,为’电源点个数’,’注册资金(人民币:万)’,’规模(人员数量)’,’用户达到最大负荷年数’,’用电量’,’行业GDP’,’容量’,’电压等级1’,’电压等级2’,’电压等级3’,’电压等级4’,’区域1’,’区域2’,’区域3’,’区域4’,’区域5’,’区域6’,’区域7’,’区域8’,’区域9’,’区域10’,’区域11’,’区域12’,’区域13’,’区域14’,’行业类型1’,’行业类型2’,’行业类型3’,’行业类型4’,’行业类型5’,’用电类别1’,’用电类别2’,’用电类别3’,’用电类别4’,’用电类别5’。模型依据交叉验证得分选择的特征如图3 所示。
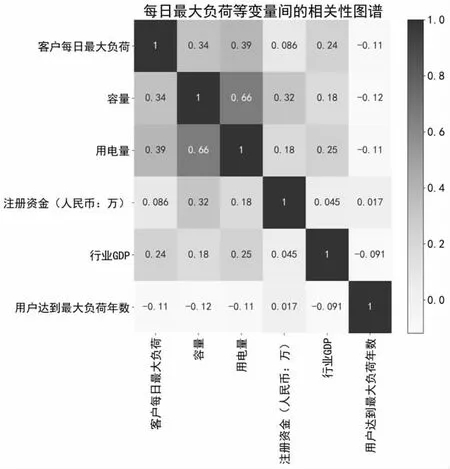
图2 每日最大负荷与容量、注册资金等的相关性图谱
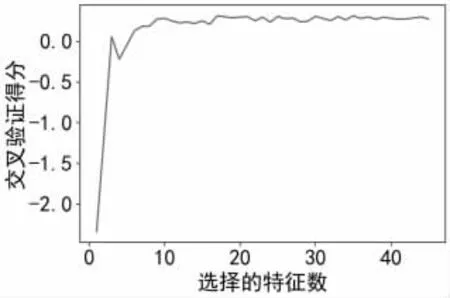
图3 模型选择的特征数图
1.4 模型构建
基于大用户电量历史需求、用电特征和行业特征等数据,使用特征工程、回归、决策树等机器学习方法,挖掘大用户电力需求,提取业扩报装大用户有效用电特征,将其作为模型输入特征,建立大用户业扩报装需求模型,量化输出大用户业扩报装容量需求。在对比多个模型精度后发现,多元线性回归的精度高于其他模型算法,但整体精度仍然不高。
1.4.1 多元线性回归模型:多元线性回归模型的预测精度,也就是R2达到0.712,也就是模型可以解释71.2%的变量。
1.4.2 k 近邻回归模型:选择k=20,模型的精度为0.564,预测效果一般。
1.4.3 集成学习回归模型:通过构建单个回归树、Bagging回归树和随机森林进行对比,发现集成算法会降低测试误差,Bagging和随机森林的测试误差基本一致,但是测试误差依然在0.88 左右。从随机森林的输入变量重要性来看,区域11 的用电量、容量以及用户达到最大负荷的年数等变量重要性高于其他变量,和特征选择的结果一致。

图4 回归树、Bagging 回归树和随机森林误差对比图
2 用电类别下供电需求预测
在基于大用户级别的报装预测的同时,可以通过用电类别下的需要系数和同时系数的计算来对不同的用电类别用户进行容量预测。算法逻辑为:一是依据用电性质将用户进行分类,获得不同用电类别下的历史最大负荷值,从而计算各用户不同的需要系数;二是用全行业历史最大负荷值和第一步中的用电类别下历史最大负荷值来计算全社会同时系数。需要系数和同时系数可用于电力大用户业扩报装负荷预测。
2.1 需要系数分析

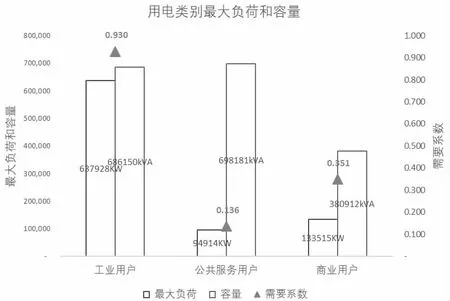
图5 用电类别下最大负荷、容量、需要系数图

2.2 全行业同时系数分析

2.3 供电需求预测

3 结论
本文通过两种方式给出了业扩报装容量的预测方向。一是构建了业扩报装容量的多种模型预测方法,特征选择后进行了多种模型结果尝试。后续可在收集的数据量级及数据获取的准确性上进行进一步扩展分析。二是通过用电类别集合下的需要系数和同时系数的计算,将用户集成到不同用电类别下进行对照预测,用计算获取的需要系数值和全社会的同时系数值来估计待预测区域的供电需求。
