基于MACNN的柴油机故障诊断方法研究
2022-05-30程建刚毕凤荣张立鹏汤代杰
程建刚, 毕凤荣, 张立鹏, 李 鑫, 杨 晓, 汤代杰
(1. 天津大学 内燃机燃烧学国家重点实验室,天津 300072;2. 天津内燃机研究所,天津 300072)
柴油机因具有热效率高、输出功率大、使用寿命长等优点,被广泛应用于工程机械、船舶、核电等领域。但是由于其机构复杂、工作环境恶劣等原因,导致其极易发生故障。因此,开展柴油机状态监测与故障诊断研究具有重要意义。
基于振动信号的故障诊断技术由于其测量简单、精度较高、不解体化等诸多优势成为了研究热点。传统基于振动信号处理的故障诊断技术通常需要人工参与提取特征,然后选用合适的机器学习算法用于分类。该方法主要存在以下两个问题:
第一,人工参与程度过高,导致识别结果不确定性高。在传统故障诊断过程中,需要人工参与提取特征。例如,Bi等[1]采用离散小波变换方法对爆震振动信号中的高频噪声进行分离,然后采用经验模态分解(empirical mode decomposition, EMD)[2]对降噪后的信号进行分解以后提取爆震特征,实现了汽油机爆震监测。但是该方法中的小波基函数、小波分解层数以及阈值等重要参数均需要人为选取,EMD算法由于采用递归结构存在模态混叠问题。这些因素均会对后续提取的特征质量有着重大影响,从而影响最终诊断结果。另外,模式识别算法的选择对识别结果同样有着重要影响。如文献[3]经过对比发现,采用核模糊C均值聚类算法(kernel fuzzy C means clustering, KFCM)、BP神经网络(back propagation neural network, BPNN)、深度置信网络(deep belief networks, DBN)三种方法对相同故障特征进行识别,得到的结果相差较大。
第二,人工特征对于不同故障类型的敏感程度差异较大,导致模型的泛化能力差。例如,Bi等[4]采用变分模态分解(variational mode decomposition, VMD)[5]算法对柴油机振动信号进行分解以后构建27维数据特征,然后采用遗传算法进行特征选择,结果表明,面对不同故障类型,经过特征选择得到的特征均不相同。由此可见,面对多类型故障诊断任务,传统故障诊断方法将难以胜任。综上,传统故障诊断方法中,人工特征提取过程以及模式识别算法的选取均对识别结果有着重要影响,导致该方法得到的结果不确定性较高。同时,由于人工特征对于故障类型有着较强指向性,导致传统故障诊断方法泛化性能较差。因此,不少学者将注意力转到基于深度学习的端到端故障诊断方法研究。
基于深度学习的端到端故障诊断方法中期望以原始时域数据作为系统输入,通过模型自学习的方式完成特征提取并分类,尽可能减少人工参与诊断过程。其中,以卷积神经网络(convolutional neural networks, CNN)和循环神经网络(recurrent neural networks, RNN)在端到端故障诊断方向的应用最多。CNN有强大的特征提取能力,其采用局部连接、权值共享等策略带来运算速度的极大提升。虽然CNN对图片类型的二维数据格式处理具有巨大优势,但是面对故障诊断领域的一维时域数据,CNN并未考虑序列信息,导致其应用效果有限,当前CNN在故障诊断领域的应用主要包括:①使用CNN作为人工特征的分类工具。例如,Lu等[6]提取时域和频域特征,采用CNN进行训练分类,经采用滚动轴承故障数据验证后表明,与支持向量机算法相比,该方法具有更好的诊断效果。但是该方法仅仅将CNN作为一个分类器使用,其特征提取过程依旧依靠专家经验知识进行,导致最终模型诊断效果受人工特征质量影响较大。②沿用卷积神经网络用于处理图像的网络结构,将故障振动数据处理为二维输入格式,进一步采用CNN进行分类识别。例如:Wang等[7]采用短时傅里叶变换(short-time fourier transform, STFT)将一维振动信号转换为时频域图像,作为CNN的输入,完成了电机的故障诊断;Xia等[8]将一维时间序列信号采用逐行堆叠的方式处理为二维输入矩阵,然后采用CNN实现了滚动轴承和齿轮箱的故障诊断。上述方法实现过程较为繁琐,其中时频图转换过程中会存在信息丢失的风险,将一维数据强行堆叠处理为二维矩阵的方法需要根据原始数据长度的变化调整矩阵尺寸,对不同长度数据自适应性较差。利用RNN对于序列数据的处理优势,不少学者将其用于实现端到端故障诊断。例如:庄雨璇[9]采用长短期记忆网络(long short-term memory networks, LSTM)实现了轴承故障端到端诊断;张立鹏等[10]通过在双向门控循环单元(bidirectional gated recurrent unit, BiGRU)中引入注意力机制实现了机械故障端到端诊断。另外,值得借鉴的一个例子是:Zhou等[11]采用CNN和LSTM的联合网络,完成了文本分类任务。总的来说,RNN及其变体在端到端故障诊断中取得了较好的应用效果,但是由于RNN在计算过程中以时间点为单位逐个输入,无法并行计算,导致其运算时间过长,限制了其在故障诊断领域的应用。
因此,为解决传统故障诊断方法识别结果不确定性较高、泛化性能差的问题,同时避免RNN运算时间过长的缺陷,论文将以CNN为主体,通过对卷积输出结果进行重组的方式最大化保留序列信息,同时引入注意力机制,加强模型对于关键信息的提取,最终设计了一套端到端的柴油机故障诊断系统,其以原始时域振动信号数据作为输入,通过对历史数据进行学习便可建立输入-输出映射关系。
1 基本原理
1.1 卷积神经网络
卷积神经网络是在计算机视觉领域应用最广泛的深度学习算法,其基本组成主要有输入层、卷积层、池化层、全连接层和输出层。卷积层和池化层交替堆叠出现,分别实现特征提取和特征降维功能[12]。
卷积层采用多个卷积核与输入数据的局部区域进行卷积运算,每个卷积核在卷积过程中共享一组权值。卷积的具体过程如式(1)所示
(1)

激活函数可以加强模型的非线性表达能力,本文模型采用ReLU函数[13],其表达式如式(2)所示
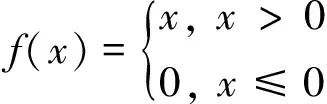
(2)
为了进一步降低模型过拟合风险,减少模型处理的数据量,常在卷积层后使用池化层进行降采样。通常有平均池化和最大池化两种方式。为充分提取振动信号中冲击信息特征,滤除部分噪声,本文采用最大池化操作,表达式如式(3)所示
(3)

1.2 批量归一化算法
Ioffe等[14]于2015年提出了批量归一化算法(batch normalization, BN)。该算法作用于各网络层之间,通过改变网络层间数据分布,达到加速网络训练收敛速度,避免梯度消失的目的。
在训练过程中,批量归一化算法流程如下所示:对于某个网络层间输入某个大小的批量数据X={x1,x2,…,xn},xi∈,其均值和方差分别如式(4)和式(5)所示
(4)
(5)
对于每一批数据做归一化处理,如式(6)所示
(6)
式中,ε为一个很小的常数值,该参数是为了保证除数不为0。
经过式(6)以后,网络层间各批次输入数据从各层间学习到的特征分布均被统一修改,为了不丢失网络层提取到的数据特征,批量归一化算法引入了位移参数β和拉伸参数γ,将输入数据按照式(7)和式(8)进行变换。
(7)
Y={y1,y2,…,yn},yi∈
(8)
式中:β和γ通过梯度下降算法在训练过程中被不断迭代更新;Y为该层的输出数据。
在测试过程中,将采用网络训练过程中所有批次数据的均值作为测试阶段均值u′,用每个批次的标准差σ的无偏估计作为测试阶段的标准差σ′。
2 MACNN介绍
CNN具有强大的特征提取能力,其通过局部连接、权值共享等策略大大加快了运行速度。本文将以CNN为主体,引入多种注意力机制,搭建一套基于多重注意力卷积神经网络(multiple attention convolutional neural networks, MACNN)的端到端柴油机故障诊断系统,如图1所示。
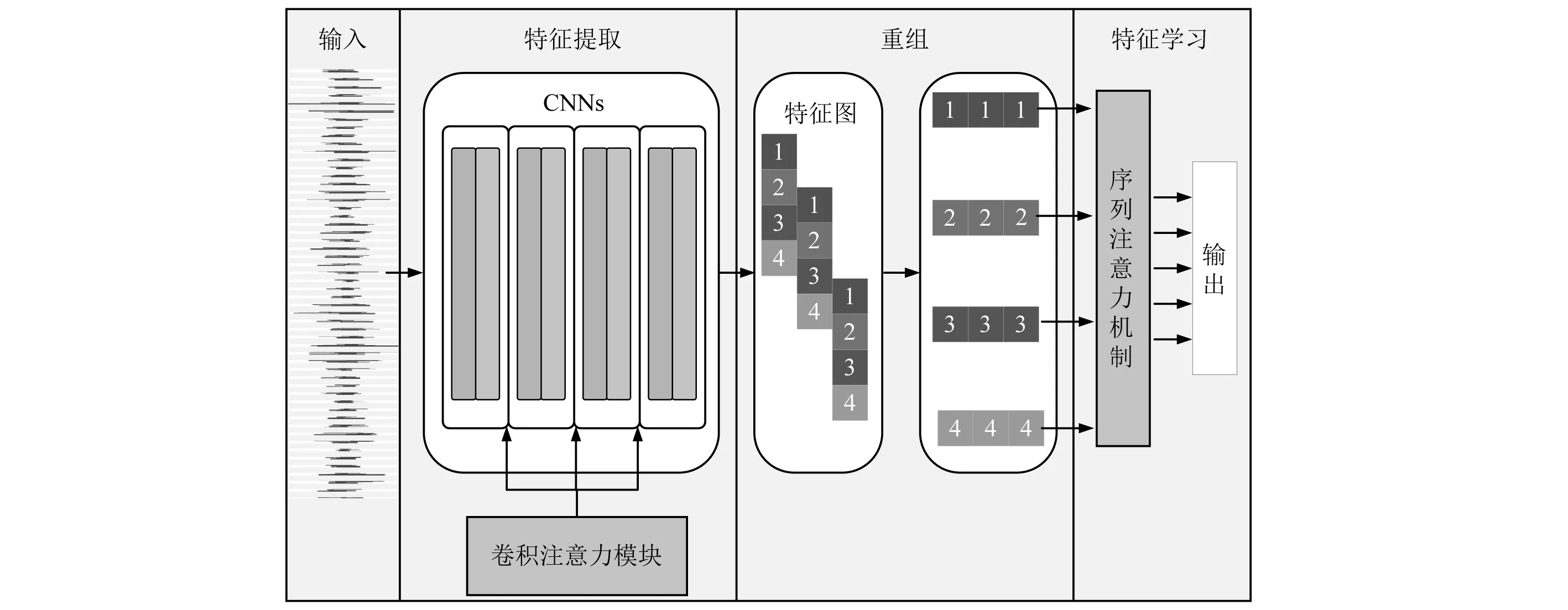
图1 MACNN结构Fig.1 The architecture of MACNN
2.1 特征提取
MACNN中采用多层CNN结合卷积注意力模块(convolutional block attention module, CBAM)[15]从原始时域数据中提取特征。CNN由4层卷积层组成。第1个卷积层使用16个较大卷积核(5×1)来提取大尺度特征,接下来3层卷积层,采用32个小卷积核(3×1)来提取深层的特征。在每个卷积层之后,使用最大池化层进行下采样。针对多层网络训练困难的问题,在各卷积层之间增加了一个批量归一化层,进一步提高训练的收敛速度和模型的泛化能力。
为进一步加强模型的提取特征能力,将在CNN中引入CBAM,CBAM包括通道注意模块和空间注意模块,如图2所示。

图2 CBAM结构Fig.2 The architecture of CBAM
(9)

特征图2如式(10)所示
P′=MC(P)⊗P
(10)
式中, ⊗为元素相乘运算。
空间注意力MS(·)用于提取特征图上各空间区域之间的联系,其表达式如式(11)所示
(11)

最后,通过式(12)计算得到特征图3。
P″=MS(P′)⊗P′
(12)
2.2 重 组
针对卷积输出的多维特征图,在经典CNN中,主要将其展平为一维向量以后输入全连接层完成分类。针对序列学习任务,该方式并未考虑输出特征的序列信息,导致其对于序列信息的利用率低。因此,本文将通过重组的方式对CNN中多维卷积输出特征图进行处理。具体原理如图3所示,重组结果为X′。X′的表达式如式(13)所示
X′ ={x1,_,x2,_,…,xm,_},xm,_∈1×d
(13)
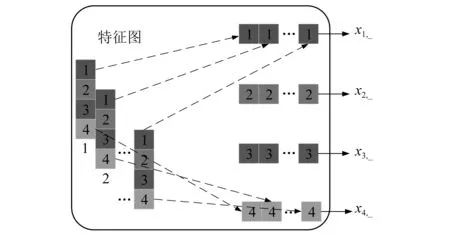
图3 重组示意图Fig.3 Reorganization diagram
2.3 特征学习
为加强序列数据学习效率,不少学者在模型中引入了注意力机制。例如:Vaswani等[16]采用层层叠加的自注意力机制来学习文本表示,提出了著名的Transformer模型; Zhou等[17]在双向LSTM的隐藏状态输出向量中引入注意力来提取关键信息,完成了关系分类任务。MACNN将引用2016年 Zhou等研究中的注意力机制直接学习重组后的深层序列特征,为便于与卷积注意力模块区分,文中将其命名为序列注意力机制。其学习过程如下所示,首先计算注意力权值,计算过程如式(14)所示
S=softmax{αT[tanh(X′)]}
(14)
式中:α为可学习参数,在训练开始时采用随机初始化方式给定初始值,之后通过梯度下降算法进行不断调整;S为序列注意力层从重组后的序列特征X′中学习得到的权值,权值越大代表携带的信息对于分类决定越重要。
最后,结果由注意力权值与序列特征相乘得到,如式(15)所示
y=X′ST
(15)
式中,y为输出结果。
3 实例分析
3.1 柴油机故障模拟试验
柴油机故障模拟试验在一台某型直列6缸柴油机上进行,该柴油机的性能参数如表1所示。

表1 柴油机主要参数Tab.1 Main parameters of diesel engine
试验采集柴油机的缸盖振动加速度信号,传感器布置在1~6缸的缸盖上,试验柴油机台架示意图以及传感器的布置位置,如图4所示。

图4 试验用柴油机以及传感器布置Fig.4 The experimental diesel engine and the location of the sensors
试验主要模拟了气门间隙异常故障(1缸)、喷油轨压异常以及供油量不足三种故障类型,并且对每一类故障发生的不同程度进行了模拟。总共包括8类故障状态,对应样本标签为0~7,详细介绍如表2所示。试验共包括700 r/min,1 300 r/min,1 600 r/min,2 000 r/min和2 300 r/min 5个转速工况,采样频率设置为25.6 kHz。
选取2 000 r/min工况,1缸缸盖位置处振动信号数据用于验证本文模型。当采样频率为25.6 kHz,转速为2 000 r/min时,柴油机工作一个周期采集1 536个数据点,为确保单个样本中包含一个完整周期的信息,设置样本长度为1 600。为了增加训练数据量,对于训练数据,在原始时域数据序列上采用重叠率为25%的方式截取,对于测试数据采用无重叠方式截取,以便更好地模拟真实应用场景。最后,得到每类故障状态包含520个训练样本和120个测试样本。

表2 模拟故障表Tab.2 Simulated failure table
3.2 训练测试分析
按照3.1节所述方法划分数据集,将时域振动信号直接输入模型,以交损失熵为目标函数,采用Adam优化算法[18]训练每一层网络参数。每批次输入256个样本进行训练,采用如式(16)所示的指数衰减学习率控制学习速率。模型建立在基于Python的PyTorch深度学习库中,采用单个NVIDIA GeForce RTX3080GPU进行训练。模型训练过程如图5所示。
LR=lr·decay_rate(epoch/decay_steps)
(16)
式中:lr=0.01;decay_rate=0.9;epoch为训练次数;decay_steps=40。
图5中,训练300次以后,模型收敛,此时训练准确率达到100%,测试准确率达到97.88%。模型测试在CPU上进行,硬件环境为Intel i7-10700F@2.90 GHz,记录MACNN模型测试100个样本所用时间为0.35 s。测试结果表明,无论从识别准确率还是运算速度上看,MACNN模型都可以很好地实现端到端的故障诊断。

图5 模型训练过程Fig.5 The training process of the model
为探究BN算法对MACNN模型训练收敛速度以及模型最终训练效果的影响。现将不添加BN算法的MACNN模型(命名为MACNN-noBN)中输入相同数据,超参数设置与MACNN模型相同,在上述硬件环境下进行训练和测试,MACNN-noBN训练过程如图6所示。同时,统计MACNN与MACNN-noBN的测试准确率以及测试100个样本用时对比,如表3所示。

图6 模型训练过程Fig.6 The training process of the model

表3 各模型对比Tab.3 Comparison of different model
由图6中可以发现,相比MACNN-noBN与MACNN模型训练过程,主要有3个不同点:
(1) 不添加BN算法的MACNN-noBN模型训练收敛速度明显变慢。MACNN经过300次训练以后,模型便收敛,但是MACNN-noBN经过900次训练调整以后,模型才收敛。可见,批量归一化算法的引入加快了模型收敛速度,提升了模型训练效率。
(2) 不添加BN算法的MACNN-noBN模型收敛以后,训练准确率为99.62%,测试准确率仅有87.29%,远低于MACNN模型97.88%的测试准确率。因此,BN算法的引入提升了模型的识别准确率。
(3) 从图6中可以看出,最终测试损失曲线有轻微上扬的趋势,而训练损失曲线随着训练过程的进行不断调整降低。因此,可以判定不添加BN算法的MACNN-noBN模型出现了轻微的过拟合现象。但是,MACNN模型中却并未产生该问题。因此,BN算法的引入增强了网络的泛化性能,避免模型训练过程中出现的过拟合问题。
进一步地,为证明MACNN中CBAM引入的有效性,将图2中MACNN模型的CBAM移除,得到的不含CBAM的MACNN模型(命名为ACNN)。采用与上述相同的硬件环境进行训练和测试,将ACNN测试准确率和测试100个样本用时与MACNN结果对比,见表3。
由表3对比可以发现,添加卷积注意力机制以后,MACNN模型的测试准确率提升3.93%,达到97.88%。其测试100个样本用时为0.35 s。作为参考,当柴油机转速为2 000 r/min时,柴油机工作100个周期用时6 s。由此可见,CBAM引入以后带来的测试100个样本用时增加0.2 s的结果是可以接受的。同时,MACNN模型测试100个样本用时为0.35 s的运算速度为实现柴油机在线故障诊断奠定了良好的基础。
为体现CBAM在特征提取过程中发挥的作用以及各个网络层在整个模式识别过程中所起作用,将采用t-SNE对ACNN和MACNN各个网络层输出结果进行降维可视化分析。具体地,将各个网络层数据维度降为二维,分别以t-SNE1和t-SNE2命名。可视化结果如表4所示。表4中,层数0~5分别表示原始输入数据、第1层卷积层、第2层卷积层、第3层卷积层、第4层卷积层以及序列注意力层输出结果。
从表4的纵向看,随着网络层数的加深,ACNN和MACNN各层数据聚类特征均随着网层数的增加变得愈加明显。从表4的横向看,经过第1层卷积层学习以后,引入了CBAM的MACNN中故障标签为1的供油量25%类故障聚集到了中心,但是ACNN中该类数据却较为分散。MACNN的第2层卷积层输出结果中各类数据逐渐呈圆环状分布,与ACNN相比,其聚类效果更佳,各类数据呈圆环状分布情况差异在第2、第3层卷积层输出数据中体现得更加明显。从MACNN中第4层卷积层输出结果中可以发现,除了标签分别为0,1,6的3类数据以圆环状聚集在一起,无法明显区分以外,其余5类故障类型均能较为清晰地区分。而ACNN中各类数据均无法进行较为清晰地区分。最后,经过序列注意力层学习以后可以发现,MACNN和ACNN中8类数据的聚类状态均较为明显,具体地,ACNN中各类数据呈长条状聚集,而MACNN中各类数据呈椭圆状聚集,同类数据点之间距离更短,更有利于分类。可视化结果表明,CBAM引入以后,加强了模型对于关键信息的提取,提高了模型的学习能力。这主要得益于CBAM通过自学习的方式对输入信号诸如脉冲信号特征等重要信息分配更大的注意力权值以给予重点关注,对信号中低频噪声等无关信息分配更小的注意力权值以忽略其带来的干扰。最终结果表明,MACNN模型可以很好地从原始时域振动数据中通过自适应学习完成特征提取和分类任务,实现了柴油机故障端到端的诊断。

表4 可视化结果分析Tab.4 Analysis of visualization results
4 对比验证
为进一步评价本文提出的MACNN的性能,将分别采用多种方法对本文建立8类故障数据集进行诊断对比,主要包括传统基于信号处理的故障诊断方法和采用端到端的故障诊断方法,传统基于信号处理的故障诊断方法具体为:
方法1VMD+KFCM——采用VMD算法,通过观察选择合适分解层数对原始时域振动信号进行分解,计算VMD分解结果各分量的最大奇异值,选取最大的3个奇异值构建3维特征,最后采用KFCM进行分类;
方法2EEMD+KFCM——采用EEMD算法,通过不断调试选择合适白噪声幅值系数和集合平均次数对原始时域信号进行分解,计算各分量与原始信号相关系数,选取相关度最高的前3个分量计算最大奇异值,构建3维特征空间,最后采用KFCM进行分类;
方法3VMD+DBN——采用VMD算法,通过观察选择合适分解层数对原始信号进行分解,然后提取最大的3个奇异值、峭度值、香农熵、均方根值、时域能量、四阶累积量和多尺度熵,构建21维特征,然后进一步利用遗传算法进行特征选择,最终得到8维特征,最后采用DBN分别对构建的8维特征以及方法1构建的3维特征进行分类,具体地,DBN采用2层受限玻尔兹曼机堆叠而成,各层神经元数量均为200。
由于传统故障诊断方法需要过多人工参与,流程过于繁琐,计算用时远大于本文所提出的MACNN。因此,这里将不再对传统故障诊断方法的计算用时进行对比,仅统计上述所有方法识别准确率,如表5所示。
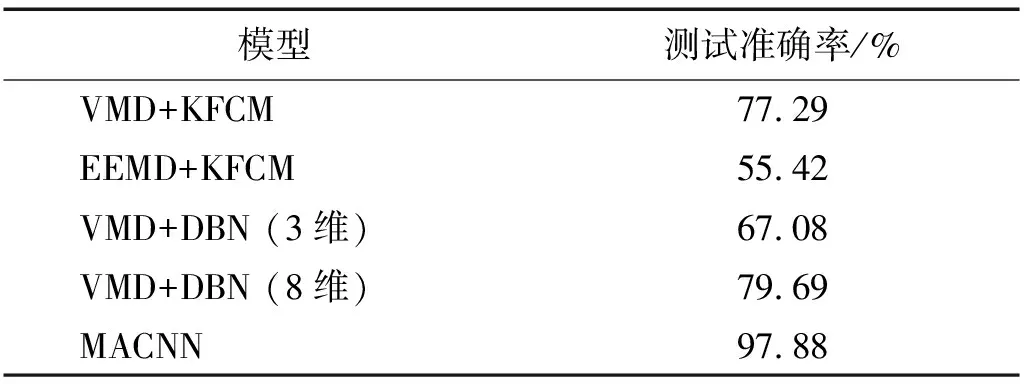
表5 与传统方法对比Tab.5 Compare with traditional methods
表5中,采用EEMD分解算法提取特征,KFCM用于分类得到的识别准确率低于60%。VMD提取相同的特征,利用KFCM进行分类能够得到77.29%的识别准确率,体现出VMD信号分解算法的优越性。针对VMD算法分解提取的3维特征和经过特征选择以后的8维特征,采用DBN进行识别,分别获得了67.08%和79.69%的识别准确率,进一步体现出DBN对于高维特征数据的表征能力。
综上,传统基于信号处理的故障诊断方法中,主要包括人工特征提取和模式识别两个部分。其中,人工特征提取方法和模式识别方法均对最终结果有着至关重要的影响,导致传统基于信号处理故障诊断方法的识别结果受人工干扰程度大,不确定性高,最终识别准确率偏低。而本文提出的端到端故障诊断方法,直接从历史运行数据中通过自学习方式建立映射关系,很好地避免了传统基于信号处理的故障诊断方法中不确定性因素带来的影响。
论文选取基于端到端故障诊断方法,主要如表6所示。特别地,LSTM和双向长短期记忆网络(bidirectional long short-term memory networks, BiLSTM)将输入样本划分为200个数据块作为输入;CNN-LSTM和CNN-BiLSTM采用2层卷积,LSTM和BiLSTM均为3层;CNN由4层卷积层和池化层交叉堆叠的方式构成,与MACNN模型类似,第一层卷积核尺寸为5×1,随后3层卷积核尺寸为3×1。各模型的测试准确率和测试100个样本用时对比,见表6。

表6 与端到端方法对比Tab.6 Comparison with end-to-end methods
如表6所示,庄雨璇采用LSTM中的方法仅能达到61.04%的识别准确率,BiLSTM能够达到88.32%的识别准确率。采用2015年Zhou等研究中CNN和LSTM的联合网络,仅能达到55.20%的识别准确率,进一步采用CNN-BiLSTM网络能达到80.42%的识别准确率。结果表明,采用BiLSTM同时考虑输入位置前和输入位置后的信息能够达到更好的效果。采用张立鹏等研究中BiGRU和注意力BiGRU分别能达到92.59%和95.82%的识别准确率。上述以RNN的变体为主体的方法均能够实现端到端的故障诊断。其中,张立鹏等研究中注意力BiGRU能够达到的最高识别准确率为95.82%。但是,由于RNN网络存在着无法并行计算的缺陷,导致其在本文的CPU环境中测试100个样本用时为8.46 s。作为参考,当柴油机工作转速为2 000 r/min时,运行100个周期用时6 s(<8.46 s),进一步考虑到实际硬件环境,上述算法运行时间会进一步加长。因此,为将该算法应用于实践,还需要首先解决其计算速度问题。另外,CNN模型能够达到90.18%的测试准确率,体现了CNN强大的数据挖掘以及特征表示能力,但是由于其并未充分考虑数据的序列信息,导致其最终的测试准确率低于MACNN。但是CNN测试100个样本用时仅为0.14 s,这也充分体现了CNN可以并行计算,采用权值共享和局部连接等策略带来的运算速度的巨大提升。最终结果表明,本文提出的MACNN,通过采用重组的方式解决了CNN对于序列信息利用率低的问题,同时通过引入注意力机制进一步加强了模型对于关键信息的提取能力,最终能够达到最高的测试准确率为97.88%,测试100个样本用时仅需0.35 s,为实现在线故障诊断奠定了良好基础。
5 结 论
为解决传统故障诊断方法人工参与程度过高,为识别结果带来诸多不确定性的问题,本文采用CNN引入多种注意力机制建立端到端的诊断模型——MACNN,该方法可以通过对大量数据进行自学习后提取特征并分类,实现了柴油机故障端到端的诊断。
