基于改进GFCC特征参数的广播音频语种识别
2022-05-30邵玉斌杜庆治
邵玉斌, 陈 亮, 龙 华, 杜庆治
(昆明理工大学 信息工程与自动化学院, 昆明 650500)
在监听无线广播中, 亟待解决的问题是如何准确高效地识别其他电台语种, 从而及时将实时语音转入相应的翻译器进行翻译. 广播音频的构成复杂, 包括背景音乐、 噪声、 男女说话的不同等干扰因素, 更增加了语种识别(language identification, LID)的难度. 目前, 通常使用包括神经网络、 机器学习等方法提取与语种相关的特征进行学习建模, 从而提高语种识别的准确率.
如何去除不相关因素的干扰, 从一段语音信号中提取能描述语种特征的特征参数, 是语种识别的关键. 传统特征参数包括Mel频率倒谱系数(Mel-frequency cepstral coefficients, MFCC)[1]、 线性预测编码系数(linear prediction coefficient, LPC)、 线性预测倒谱系数(linear prediction cepstrum coefficient, LPCC)、 伽马频率倒谱系数(gamma frequency cepstral coefficients, GFCC)[2]等. 目前, 语种识别方法的研究主要集中在如何提取有效的底层声学特征, 输入到对应的模型或神经网络中进行训练, 得到语种识别模型. 语种分类模型有多种, 其中包括隐Markov模型、 高斯混合模型、 SVM分类器、 I-vector[3]等. 较常用的底层声学特征是伽马频率倒谱系数. GFCC参数使用Gammatone滤波器代替Mel滤波器, 更好地模拟了人体耳蜗频率特征, 再经过离散余弦变换, 去除同一帧的不同特征维度之间的相关性, 从而能更好地对特征参数进行建模, 达到较好的识别效果. Gammatone滤波器[4]在语音信号处理方面, 包括说话人识别、 语种识别、 语音情感识别[5]等方面应用广泛. 文献[6]提出了使用Gammatone滤波器滤波提取GFCC参数, 同时加上差分特征用于语种识别, 并使用GFCC参数提取移位差分倒谱(shifted delta cepstra, SDC)特征, 提高了语种识别的准确率; 文献[7]提出了用指数压缩代替对数压缩, 更好地模拟人耳的非线性特性, 提高了说话人识别的效果; 文献[8]提出了使用融合MFCC和GFCC的特征参数用于说话人识别, 再加上一阶差分和二阶差分, 取得了更好的说话人识别的识别准确率; 文献[9]提出了在GFCC的基础上, 加上多窗口估计、 均值减法、 方差去噪、 自回归移动平均滤波等, 增强了说话人识别的鲁棒性; 文献[10]提出了一种基于声道冲激响应频谱参数, 并融合Teager能量算子倒谱参数的融合特征作为语种识别方法; 文献[11]提出了将加权音素对数似然比(weighted phone log-likelihood ratio, WPLLR)应用于语种识别, 有效降低了语种识别的错误率. 在基于神经网络相关语种识别算法中, 文献[12]提出了一种基于Senone的深度神经网络语种识别算法; 文献[13]提出了LID-Senone统计特征, 比Senone特征能达到更好的语种识别效果. 基于深瓶颈特征(deep bottleneck feature, DBF)[14]的语种识别方法能有效抑制底层声学特征中的背景噪声、 说话人差异、 信道差异等影响, 从而有效提取与语种相关的特征, 提升识别效果. 在噪声环境下, 可采用语音去噪算法[15]对语音进行去噪后再进行语种识别. 针对广播音频, 传统算法提取语音语种特征时, 未能去除部分细节特征包括男女说话的不同、 电台广播频道的不同等的影响, 从而可能导致语种识别成为说话人识别或其他与语种无关的特征识别.
本文提出一种基于GFCC改进特征参数的语种识别方法. 首先对每帧语音进行归一化处理, 去除不同说话人音量大小的影响; 然后对分帧后的每帧语音信号进行快速Fourier变换(FFT), 先取平方再取对数, 得到对数能量谱. 对能量谱信号进行离散余弦变换(DCT), 将高维参数置0再进行逆离散余弦变换(IDCT)得到能量谱包络信号, 以去除部分与语种无关的细节特征. 再使用能量谱包络信号代替原来的能量谱信号通过Gammatone滤波器组进行滤波. 同时为提升GFCC参数的中高阶分量, 使其相邻值之间具有一定区分性, 在计算DCT倒谱后进行倒谱提升, 得到改进的GFCC特征参数. 最后使用隐Markov模型(hidden Markov model, HMM)语种识别系统进行仿真实验, 实验结果表明, 在广播音频语种识别中本文的改进GFCC特征优于传统GFCC特征及其衍生特征.
1 特征提取
首先对语音信号进行预处理, 得到分帧信号, 对每帧语音信号提取能量谱包络, 利用Gammatone滤波器组滤波, 然后进行DCT变换, 计算DCT倒谱信号, 再进行倒谱提升, 得到改进的GFCC特征参数. 改进的GFCC参数提取流程如图1所示. 由图1可见, 本文加入了求能量谱包络和倒谱提升两个模块. 在进行预处理后, 将语音信号提取对数能量谱包络代替原来的能量谱, 同时在求得DCT倒谱后进行倒谱提升.

图1 改进的GFCC参数提取流程Fig.1 Improved GFCC parameter extraction process
改进的GFCC参数提取过程如下:
步骤1) 预处理. 首先, 对语音信号进行预处理, 其中包括归一化、 预加重、 分帧、 加窗. 归一化的作用主要是去除不同语种语音的音量大小对语种识别的影响. 归一化方式采用能量归一化, 表达式为

(1)
其中x(n)为输入的一段语音序列,x1(n)为归一化后的语音序列.
其次, 对语音信号进行预加重.为提升高频分量, 需对语音信号进行预加重, 减小高频分量的损失, 用公式表示为
y(n)=x1(n)-ax1(n-1),
(2)
其中a通常取0.97,y(n)为预加重后的语音序列.
设分帧的帧长为l, 则帧移取帧长的1/2.根据语音的短时平稳特性, 本文语音分帧的帧长取1 024, 帧移取512.为减小语音信号每帧的边缘抖动等影响, 需对信号进行加窗处理.
步骤2) FFT变换. 对每帧信号进行FFT变换, 从时域变换到频域, 得到频域信号X(k).
步骤3) 取能量谱包络.通过FFT变换的频域信号X(k)取绝对值, 再取对数得到对数能量谱E(k), 表达式为
E(k)=20lg|X(k)|.
(3)

图2 能量谱包络提取流程Fig.2 Energy spectrum envelope extraction process
能量谱包络提取流程如图2所示.对得到的能量谱经过DCT变换, 将大部分信息集中到低维, 再将高维若干维参数置为0(高维参数不同维数置0会得到不同的识别效果), 最后经过IDCT变换, 得到能量谱包络信号. 语音分帧帧长为l, 所以得到的能量谱包络信号维数也是l.将能量谱包络后的信号记为E1(k).
一帧语音信号对数能量谱和能量谱包络如图3所示.由图3可见, 原始能量谱信号的波动起伏较大, 曲线较尖锐.取包络后, 去除了一些幅值较大或较小的点, 信号的曲线变得平滑, 且波动起伏较小.能量谱包络去除了一些细节信息, 例如男女说话的不同、 背景噪声谐波等, 反映了信号与语种相关的趋势.传统的GFCC参数提取未提取能量谱包络, 本文改进方法提取能量谱包络后再进行Gammatone滤波.
步骤4) Gammatone滤波器组滤波. Gammatone滤波器组由M个中心频率不同的滤波器组成, 每个Gammatone滤波器冲激响应为

(4)
其中:n为滤波器阶数, 一般取4;bi为第i个滤波器的带宽;fi为第i个滤波器的中心频率;φ为相位.
每帧语音信号取能量谱包络后, 使用Gammatone滤波器组进行滤波, 相当于对每帧的包络信号E1(k)与Gammatone滤波器的频域响应Gi(k)相乘并相加, 用公式表示为
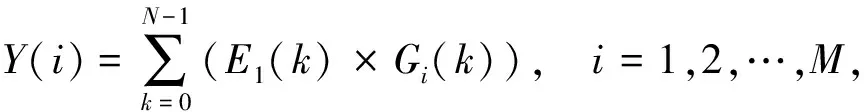
(5)
其中i表示第i个Gammatone滤波器,k表示频域信号的第k个值,N为信号长度,Y(i)为经过第i个滤波器滤波后的信号.
步骤5) DCT倒谱. 对经过Gammatone滤波器组滤波后的信号进行离散余弦变换, 得到GFCC参数, 表达式为

(6)
其中m表示第m维GFCC特征参数,i表示第i个滤波器,M为滤波器的个数, 也表示进行DCT变换后特征参数的维数. 进行DCT变换减小了同一帧信号中不同维度之间的相关性. 定义进行DCT变换后的参数为本文改进的GFCC算法1.
图4为从语料中某条语音提取的GFCC参数样本, 如取第25帧的GFCC参数, 不取能量谱包络与取能量谱包络的对比结果. 由图4可见, 取谱包络的GFCC参数与未取谱包络的GFCC参数曲线相比, 前几维无太大变化, 第5维后的GFCC参数曲线变平缓了, 在第10维后幅值几乎接近于零. 说明取包络后去掉了细节信息, 仅保留了与语种相关的信息.
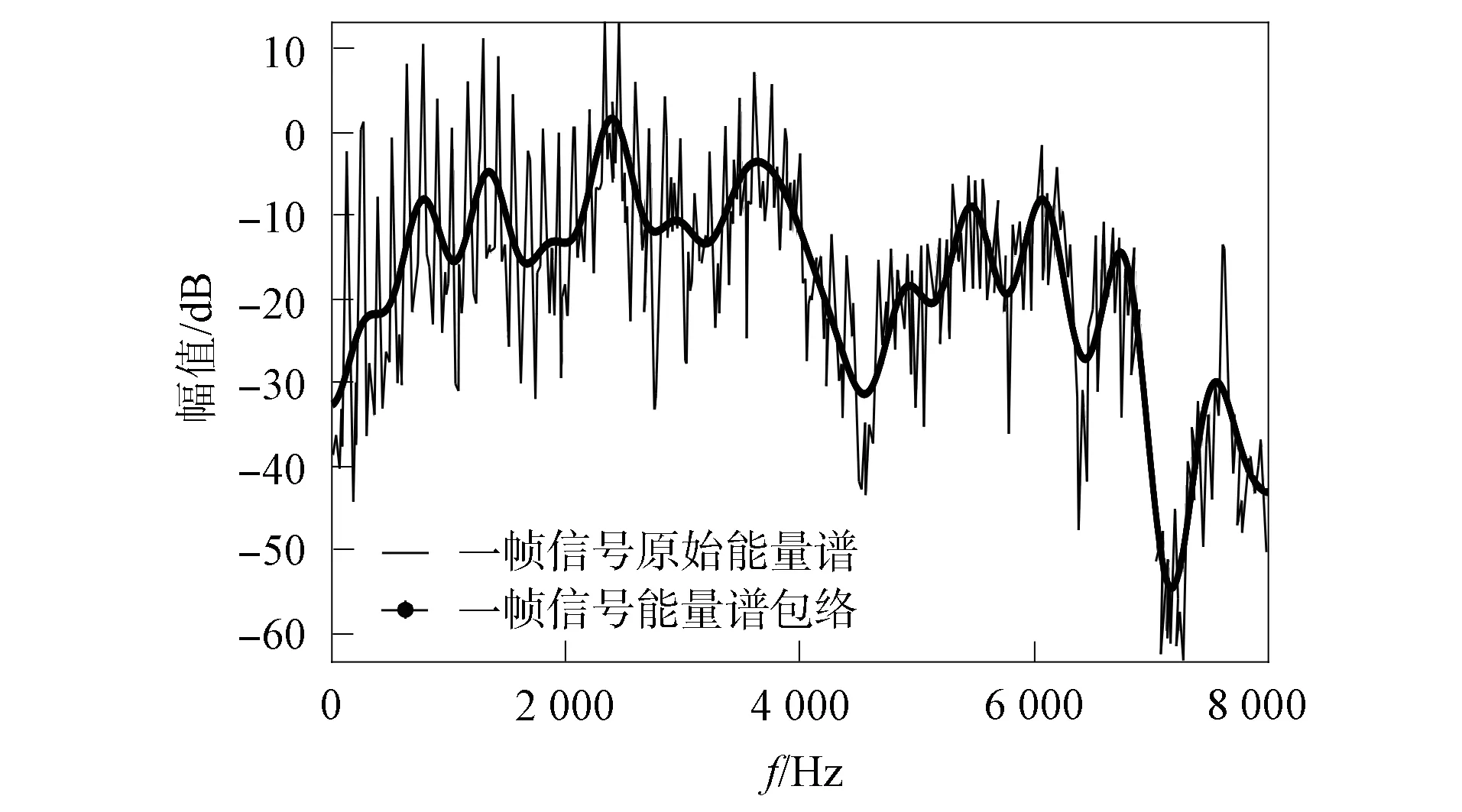
图3 一帧信号的原始能量谱和能量谱包络Fig.3 Original energy spectrum and energy spectrum envelope of a frame signal

图4 一帧GFCC参数不取包络与取包络的对比Fig.4 Comparison of GFCC parameters of a frame without envelope and envelope
步骤6) 倒谱提升. 对GFCC参数进行倒谱提升, 由于进行DCT变换求倒谱后, 低阶GFCC参数值较大, 因此采用倒谱提升以降低低阶GFCC参数值, 提升中高阶参数值, 使中高阶GFCC参数相邻值之间具有一定的区分性.
常用的倒谱提升函数为半升正弦函数, 表示为
w1(m)=0.5+0.5sin(πm/M),m=1,2,…,M.
(7)
本文采用倒谱提升函数
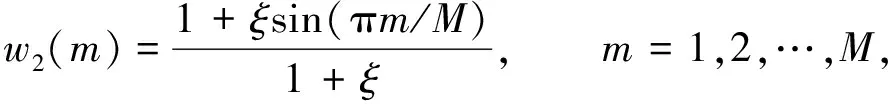
(8)
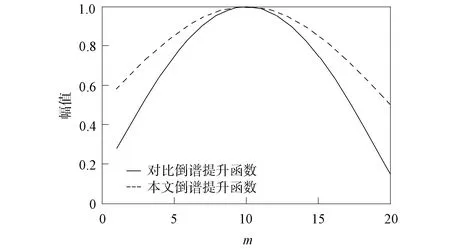
图5 两个倒谱提升函数对比曲线Fig.5 Comparison curves of two cepstrum lifting functions
对倒谱提升函数进行了归一化. 其中ξ为一个可变系数, 当ξ=1时等同于式(7).经过实验, 本文取ξ=6时, 效果最好.式(7)倒谱提升函数和式(8)中ξ=6时的倒谱提升函数0~20内的曲线如图5所示.由图5可见, 与式(7)相比, 本文的倒谱提升函数两端较低, 中间较高, 进行倒谱提升后更降低了GFCC参数低阶分量值, 提升了中高阶分量值. 倒谱提升函数与经过DCT变换后的信号相乘, 得到倒谱提升后的信号gfccen(m), 用公式表示为
gfccen(m)=gfcc(m)m×w2(m).
(9)
定义进行倒谱提升后的参数为本文改进的GFCC算法2.
2 语种识别
本文使用HMM作为语种识别的训练和识别模型. HMM模型作为一种常用的对语音信号进行建模的统计模型, 在语音信号处理领域, 包括语音分离、 语音增强、 说话人识别、 语种识别等方面都已得到广泛应用. 使用HMM模型对语音数据提取的特征参数进行建模, 保留了语音数据特征之间的前后关联性, 能更好地拟合同一语种的语音数据, 形成一个能区别于其他语种的模型. 对不同语种的语音数据特征参数进行训练建模, 分别拟合出与当前语种特征相类似的模型. 识别时, 将语音特征参数视为观测字符序列与模型进行匹配, 得到与观测字符序列对应的最佳状态序列, 从而达到语种识别的目的.
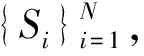

(10)
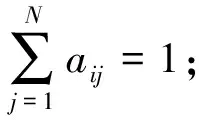
πi=P{S1=si},i=1,2,…,N,
(11)

本文的语种训练和识别流程如图6所示.首先, 对HMM模型进行初始化, 然后对训练集的不同语种语料提取改进的GFCC特征参数, 放入模型中进行训练. 通过Baum-Welch算法进行循环迭代, 重估3组模型参数{A,π,B}, 得到不同语种对应的识别模型. 其次, 对测试集提取改进的GFCC特征参数, 使用Viterbi算法, 将每条语音提取的特征参数与不同的语种识别模型进行匹配, 寻找匹配概率最大的状态序列, 即为识别得到的语种.
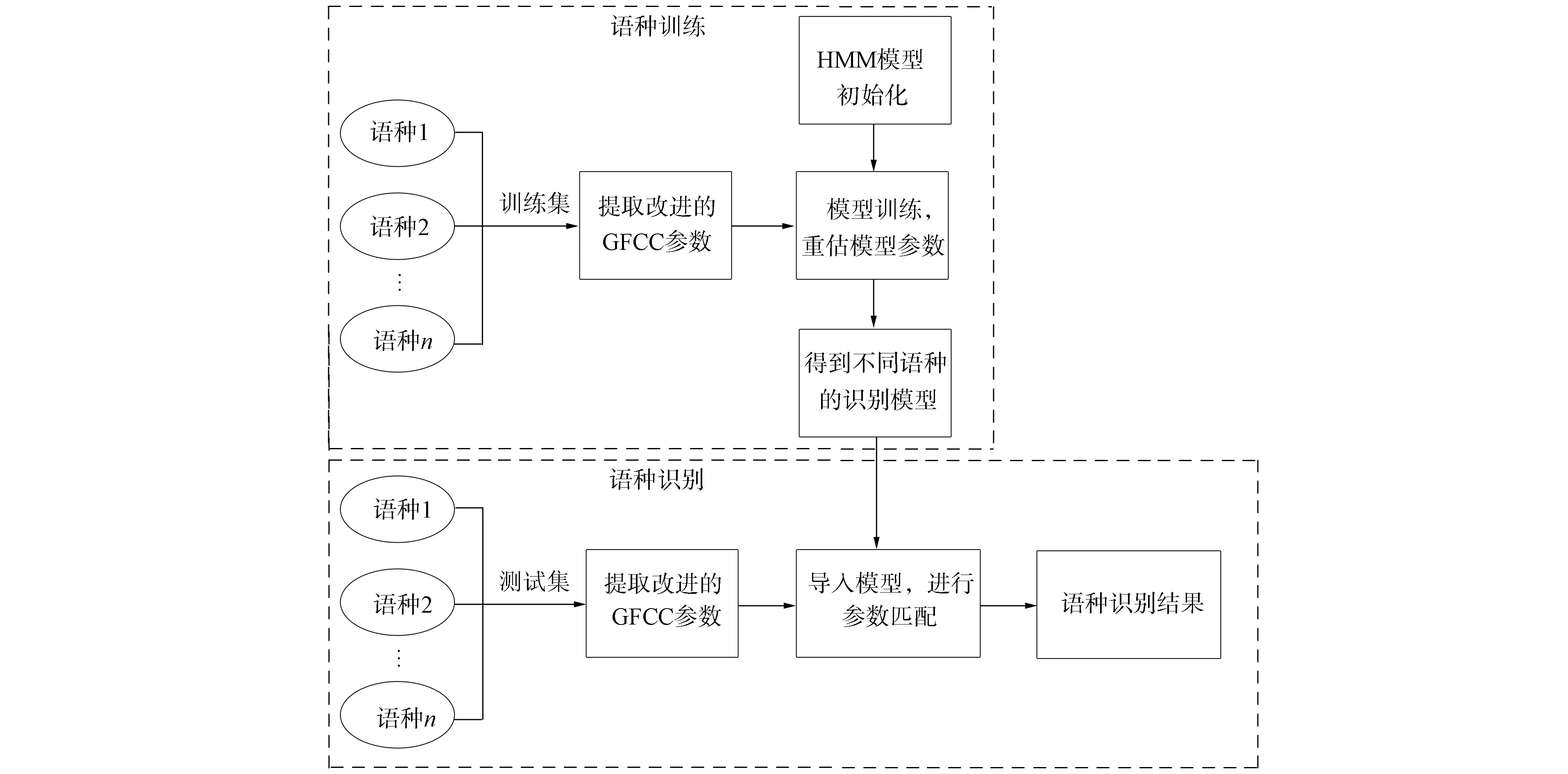
图6 语种训练和识别流程Fig.6 Flow chart of language training and identification
3 实验仿真及分析
3.1 实验语料
本文实验语料来自中国国际广播电台, 主要包括老挝语、 柬埔寨语、 缅甸语、 藏语、 维吾尔语、 越南语6种语言. 每个语种语料采自多个频道不同时间段的、 不同说话人的广播音频. 6种语种的语音数据采集好后通过人工剪辑的方式, 去掉较长的静音段、 音乐段以及背景音乐较强的语音段. 再通过音频转换软件转为单声道数据, 采样频率为16 kHz, 采样深度16位. 每个语种的广播音频中都含有一定的背景音乐, 且包括电台主持人说话语音、 本地人说话语音及采访语音等. 每个语种的语音都包含多个说话人, 包括男女混合, 每个语种的语料都被剪切成3 s的固定长度语音, 每条语音之间重叠1 s. 实验语料中, 每个语种训练集由3个频道的不同时间段采集的广播音频组成, 包含2 500条语音, 从中随机抽取2 000条语音进行训练. 测试集由不同于训练集的另外两个频道的不同时间段采集的广播音频组成, 包含500条语音.
3.2 实验设计
本文实验采用MATLAB2019a作为测试平台, 测试本文提出的改进GFCC算法1与算法2的有效性.
实验1测试本文改进的GFCC算法2在提取能量谱包络时, 对DCT变换后的1 024个参数64维、 128维、 192维后的值置为0的识别结果, 各特征命名及说明列于表1. 本文Gammatone滤波器个数取20个.

表1 各特征命名及说明
实验2提取本文改进的GFCC算法2的特征参数分别与传统的GFCC特征参数、 GFCC加上一阶差分和二阶差分(GFCC-Delta-Acceleration, GFCC-D-A)特征参数以及本文改进的GFCC算法1特征参数进行对比, 测试识别效果.
对语音信号提取特征参数, 使用HMM模型进行训练识别. 初始HMM模型的状态数和每个状态对应的混合模型成分数均设置为10, HMM模型训练时循环迭代20次.
3.3 实验结果与分析
实验1对每帧语音信号提取能量谱包络时对不同维度参数置0的改进的GFCC算法2特征参数, 使用HMM模型进行训练, 通过循环迭代, 得到每个语种对应的特征模型. 对测试语种语料提取同样的特征参数, 计算与语种模型对应的最佳状态序列, 得到语种识别结果. 采用每个语种语音识别正确的个数除以每个语种语音总个数得到的准确率作为评价指标.
取能量谱包络时, 对DCT变换后的高维参数不同维度参数置0, 会有不同的识别效果. 帧长为1 024, 所以得到的能量谱包络信号维数也是1 024. 测试本文改进的GFCC算法2在提取能量谱包络时, 对DCT变换后的1 024个参数64维、 128维、 192维后的值置为0的识别结果. 识别结果列于表2.

表2 能量谱包络不同维数置0语种识别准确率
由表2可见, 对192维后的参数置0识别效果最好, 达到86.4%, 对128维后的参数置0识别效果次之, 对64维后的参数置0识别效果最低, 但相对于最好效果, 平均识别准确率只降低了1.4%. 原始能量谱及不同维数置0能量谱包络如图7所示. 由图7可见, 取能量谱包络时对DCT变换后不同维数置0的包络图不同, 丢失的信息量也不同, 对64维后的参数置0丢失的信息量最多, 对192维后的参数置0丢失的信息量最少, 但相对于原始能量谱, 取包络都去掉了很大一部分细节信息, 反映了能量谱的大致走势. 相对于192维后参数置0的能量谱包络, 64维后参数置0的能量谱包络信息去掉过多, 可能将部分用于区分语种的信息丢失了, 从而降低了准确率.

图7 原始能量谱及不同维数置0能量谱包络Fig.7 Original energy spectrum and energy spectrum envelope with different dimensions set to 0
由实验1可知, 在取语音信号能量谱包络时对DCT变换后的参数192维后的参数置0效果最好, 所以实验2的能量谱包络均对192维后的参数置0.
实验2对每个语种的每帧语音信号提取文献[7]中的GFCC特征参数、 文献[6]中的GFCC-D-A特征参数以及本文改进的GFCC算法1特征参数、 改进GFCC算法2特征参数, 使用HMM模型进行训练识别. 识别结果列于表3.

表3 广播音频语种识别准确率
由表3可见, 本文改进的GFCC算法2对每个语种的识别准确率均较好, 平均识别准确率最高, 相比GFCC参数, 平均识别准确率提升了6%. 加上一阶差分和二阶差分的GFCC-D-A参数平均识别准确率比GFCC的识别准确率高1%, 比改进的GFCC算法2低5%. 本文改进的GFCC算法1相比于GFCC参数平均识别准确率提升了3.5%, 比本文改进的GFCC算法2低2.5%. 说明本文的倒谱提升方法也提升了语种识别的准确率. 因此, 本文改进的GFCC算法2相比传统的GFCC参数识别准确率有提升, 说明本文的改进算法有效.
综上所述, 本文在传统GFCC特征参数的基础上对GFCC参数提取过程进行了改进. 首先对语音信号进行归一化, 减小了不同说话人音量大小的影响. 然后对每帧语音信号进行FFT后, 取能量谱包络, 去掉细节特征, 通过Gammatone滤波器滤波后进行DCT变换得到改进的GFCC算法1特征参数, 再进行升正弦倒谱提升, 提升了GFCC参数的中高阶分量, 得到改进的GFCC算法2特征参数. 仿真实验结果表明, 本文改进GFCC算法1的特征参数相比于GFCC参数及加一阶差分和二阶差分的GFCC-D-A参数可达到更好的识别效果, 进行倒谱提升后的改进GFCC算法2的特征参数对识别准确率有进一步提升. 本文改进的GFCC算法2特征参数对6个语种可达86.4%的识别准确率, 识别效果最好, 说明本文改进的GFCC特征参数有效.
