基于改进YoloV4网络的虹膜定位算法
2022-05-30杨亚男朱晓冬刘元宁
杨亚男, 朱晓冬, 刘元宁, 朱 琳, 董 霖
(吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012;吉林大学 计算机科学与技术学院, 长春 130012)
0 引 言
与指纹、 面部等生物特征相比, 虹膜具有高度唯一性、 稳定性和非侵犯性[1], 因而虹膜识别技术应用广泛. 虹膜识别系统包括虹膜图像采集、 虹膜图像质量评价、 虹膜内外圆定位、 归一化以及特征提取和匹配[2]. 虹膜定位是虹膜识别中的重要环节, 定位的不准确将引入光斑、 睫毛等干扰信息或导致虹膜纹理信息丢失, 直接影响特征识别效果以及特征匹配正确率[3].
经典的虹膜定位算法有Daugman[4]法和Wildes[5]法. Daugman通过积分微分算子确定虹膜的内外圆, 但易受图像边缘干扰; Wildes利用Hough变换和投票机制搜索内外圆, 但该算法对噪声敏感. 为准确定位虹膜, Yu等[6]提出了基于小范围搜索确定瞳孔的大致位置, 利用Daugman圆模板和Hough变换精定位内外圆; 刘帅等[7]通过Hough变换和卷积操作对虹膜进行粗定位, 再利用分块搜索进行精定位; 孙正等[8]先利用投影法和灰度直方图定位瞳孔, 再利用扇环灰度定位虹膜外边界. 这些传统定位算法均只适用于干扰较少的虹膜图像, 不能处理光斑、 睫毛眼睑等导致的灰度梯度值变化过程中的局部最值情况.
卷积神经网络在目标检测领域取得了较好的成果, 主要有One-stage和Two-stage两种思路. Two-stage基于目标候选框的思想, 先生成一系列样本候选框, 再通过卷积神经网络进行样本分类, 如滕童等[9]提出了一种基于级联神经网络的多任务虹膜快速定位方法, 但该方法多次运行检测和分类流程使得检测速度较慢; 张海珊等[10]提出了一种两级质量评价与虹膜定位的级联型方法, 先利用HOG-SVM分类模型和BP神经网络对虹膜进行粗定位, 再利用圆拟合法对虹膜进行精定位, HOG(histogram of oriented gradient)特征会丢弃大部分的判别信息, 同时, 评价指标过多会误删除部分可进行虹膜识别的图像, 导致浪费虹膜数据. One-stage基于回归的思想, 通过主干网络提取图像特征信息直接回归物体的边界框, 速度较快, 如Yolo系列. YoloV4[11]在网络结构和训练技巧上较YoloV3[12]都有所改进, 检测速度更快, 准确率也更高. YoloV4通过一系列的卷积操作进行特征提取, 导致模型参数量较大. 轻量级网络MobileNetV3[13]将标准卷积操作分解为深度卷积和点卷积, 在精度不减的情况下极大减少了参数量和计算量.
针对上述算法的局限性以及神经网络在计算机视觉中的优势, 本文提出一种基于MobileNetV3和YoloV4相结合并进行一系列细化步骤的虹膜定位算法, 包括K-means++聚类算法[14]生成先验框, 增强数据集适应性; 改进网络结构, 使其更适用于虹膜定位任务; 改进非极大值抑制, 使用快速soft-DIoU-NMS算法, 提高模型检测率; 修改损失函数, 使用Focal Loss[15]作为类别损失函数; 使用灰度差值对不合格虹膜图像进行精定位. 实验结果表明, 该算法提高了虹膜定位准确率和定位速度, 能准确定位受光斑、 睫毛眼睑等干扰的虹膜图像, 增强了虹膜定位的鲁棒性, 识别效果稳定. 算法流程原理如图1所示.

图1 基于改进YoloV4网络的虹膜定位算法流程Fig.1 Flow chart of iris location algorithm based on improved YoloV4 network
1 虹膜内外圆粗定位
为更好地降低睫毛眼睑、 光斑等背景干扰, 更快速、 有效地提取瞳孔和虹膜的关键信息, 本文采用改进YoloV4网络对虹膜内外圆进行粗定位, 用MobileNetV3结构提取主干特征, 用YoloV4检测网络结构进行网络结构的预测, 在两个不同维度上完成虹膜内外圆定位. 本文方法的整体网络结构如图2所示. 用K-means++聚类算法生成与数据集虹膜和瞳孔尺寸相匹配的先验框, 用Focal Loss作为类别损失函数, 用快速soft-DIoU-NMS算法进行预测框的筛选.

图2 Mobile_YoloV4整体网络结构Fig.2 Overall network structure of Mobile_YoloV4
1.1 主干特征提取网络
为适应数据集中虹膜和瞳孔的尺寸, 去除原始YoloV4网络中小目标预测尺度, 保留适合较大的虹膜和尺寸中等的瞳孔检测两个尺度. MobileNetV3通过使用SE(squeeze-and-excitation)注意力机制、 激活函数H-swish使其具有优秀的特征提取效果, 将标准卷积分解成深度卷积和点卷积的核心思想是大幅度减少参数量和计算量[16]. MobileNetV3由若干个Bneck结构连接而成, Bneck结构如图3所示, 由1×1卷积升维、 深度可分离卷积、 逆残差结构、 SE块、 1×1卷积降维几部分组成. 其中NL表示非线性激活函数, Dwise表示深度卷积, 1×1卷积表示点卷积. H-swish激活函数可简化swish函数的计算成本, 并最大程度完成swish函数的功能, 表达式为

(1)
其中x表示当前层的输入, ReLU6为ReLU6激活函数.

图3 Bneck结构Fig.3 Bneck structure
考虑到网络输入尺寸对模型检测速度和精度的影响, 将数据集中的图片尺寸统一为480×480. 特征提取网络结构列于表1, 由1个卷积层和13个Bneck结构组成, 分别在卷积层和第2,4,7,11个Bneck处下采样为240×240,120×120,60×60,30×30,15×15. 其中Conv表示标准卷积, Bneck表示Bneck结构,n×n表示卷积核大小, 升维通道数表示每个Bneck结构中第一层1×1卷积升维通道数, SE表示当前Bneck结构是否使用SE注意力机制, HS表示H-swish函数, RE表示ReLU函数. 将第10个Bneck输出特征图30×30和第13个Bneck输出特征图15×15作为两个分支输入到检测网络中.

表1 主干特征提取网络结构
1.2 检测网络
由于对输入网络的图片进行了统一尺寸预处理, 因此本文检测网络部分去除Yolov4中的空间金字塔池化(spatial pyramid pooling, SPP)结构, 检测网络结构如图2所示. 经过主干特征提取网络进行初步特征提取, 得到两个有效特征图30×30和15×15, 分别对这两个特征图进行1×1卷积操作调整通道数. 先将15×15特征图进行步长为2的上采样, 再与尺寸相同的特征图30×30进行相接得到低层次特征图. 对相接后的特征图进行1×1-3×3-1×1结构的卷积操作后, 一部分进行下采样与15×15特征图相接后再次经过1×1-3×3-1×1结构的卷积操作. 其中1×1卷积核用于调整通道数, 3×3卷积核用于提取特征, 多个卷积核交错达到目的. 下采样直接使用池化操作, 3×3卷积均使用深度可分离卷积, 以进一步减少计算量和参数量. 此时, 这两个特征图已经包含了丰富的上下文信息, 分别在这两个维度上预测边界框.
1.3 先验框
YoloV4先验框是在VOC数据集的标注上进行聚类得到的. 在虹膜数据集中, 虹膜和瞳孔大小差异变化较小, 不适合直接使用原始模型的先验框. 故本文基于虹膜数据集进行K-means++聚类[14,17]生成6组先验框, 算法步骤如下:
1) 提取数据集中所有的GT-Box(ground-truth box)坐标, 获得n组GT-Box的宽高数据作为样本;
2) 从n组宽高数据集中随机选择一个样本作为初始聚类中心Anchor-Box;
3) 计算每个GT-Box到最近Anchor-Box的IoU值;
4) 选取一个样本作为新的聚类中心, IoU值较大的点被选择为聚类中心的概率较大;
5) 重复步骤3)和步骤4), 直到得到预设的6组先验框.
1.4 损失函数
整个网络训练过程中的损失由位置损失、 置信度损失和类别损失三部分组成[18-19]. 由于虹膜数据集中存在正负样本数据不均衡, 负样本比例过高的问题, 因此本文使用Focal Loss[15]作为类别损失函数, 可降低大量简单负样本在训练中所占权重. Focal Loss公式如下:
FL(pt)=-α(1-pt)γlog(pt),
(2)
其中α为用于调解正负样本比例的权值,γ是用于降低简单样本损失值的权值,pt表示模型的预测得分.本文取α=0.25,γ=2.
1.5 快速soft-DIoU-NMS算法
在虹膜定位过程中, 由于瞳孔在虹膜内部, 因此同时预测虹膜和瞳孔时, 使用传统非极大值抑制(non maximum supression, NMS)算法存在一个最高分数的预测框将其他置信度稍低但表示另一物体的预测框删除的情形, 导致漏检. DIoU-NMS算法[11]将DIoU(distance-IoU)作为非极大值抑制的准则, 不仅考虑两个预测框之间的重叠区域, 还考虑中心点距离. soft-NMS算法[20]对非最大预测框的预测得分进行高斯指数衰减而非彻底筛除. 考虑到数据集中的每张图片仅存在一个瞳孔类别和虹膜类别, 因此本文在结合soft-NMS和DIoU-NMS算法的基础上, 先去除部分冗余框, 将剩余预测框在获得新的得分后按预测类别排列, 分别选出两个类别中的最大得分预测框, 即为网络的预测结果. 算法步骤如下:
1) 设置置信度阈值Conf_thres, 取出当前图片中得分高于该阈值的预测框, 并根据置信度降序排列;
2) 选取置信度最高的预测框Max_detection添加到输出列表, 并将其从预测框列表中删除;
3) 计算Max_detection与预测框列表中所有框的DIoU值, 将获得的DIoU值取高斯指数后与原始得分相乘得到新的得分并重新排列, 得到新的预测框列表;
4) 根据预测框中的类别信息将预测框按类别排列, 得到瞳孔预测框列表和虹膜预测框列表;
5) 分别选出瞳孔预测框列表和虹膜预测框列表中得分最高的预测框, 即为网络预测结果.
2 虹膜内外圆精定位
由虹膜的结构可知, 虹膜中心与瞳孔中心不是同一点, 但这两个中心存在一定的耦合关系[21], 可以以虹膜内圆定位信息为基础对虹膜外圆精定位. 因此, 先精定位虹膜内圆, 再精定位虹膜外圆. 为减少无意义的计算量, 只对网络输出预测框与其真实框交并比小于IoU阈值的图像进行精定位. 首先判断网络输出预测框和对应真实框的交并比与IoU阈值的关系, 若小于阈值, 则进行精定位; 否则, 为定位的最终结果. 虹膜内圆精定位和虹膜外圆精定位的流程分别如图4和图5所示. 以JLU4.0数据集中的图像为例, 内圆和外圆的IoU阈值均设置为0.90.

图4 虹膜内圆精定位流程Fig.4 Flow chart of precise positioning of iris inner circle

图5 虹膜外圆精定位流程Fig.5 Flow chart of fine positioning of iris outer circle
2.1 虹膜内圆精定位


(3)

(4)

(5)
其中

(6)

(7)
图7为网络预测结果.由图7可见, 图像的瞳孔圆心为(304.00,141.50), 半径为38.75; 左、 右、 下3个检测区域的灰度均值依次为152.82,255.00,132.75.左侧和下侧检测区域无需移动, 右侧检测区域需向左移动.检测区域移动后如图8所示.此时, 3个检测区域灰度均值依次为152.82,140.52,132.75; 3个检测区域中心坐标依次为(265.25,141.50),(336.75,141.50),(304.00,180.25).根据上述公式, 调整后的圆心为(301.00,144.50), 半径为35.88.调整后的虹膜内圆如图9所示.

图6 二值化图像上的检测区域Fig.6 Detection region on binarization image

图7 网络预测结果Fig.7 Network prediction result

图8 二值化图像移动后的检测区域Fig.8 Detection region of binarization image after movement

图9 虹膜内圆精定位Fig.9 Fine positioning of iris inner circle
2.2 虹膜外圆精定位
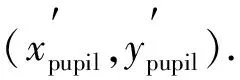


图10 调整圆心前后的虹膜外圆Fig.10 Outer circle of iris before and after center adjustment
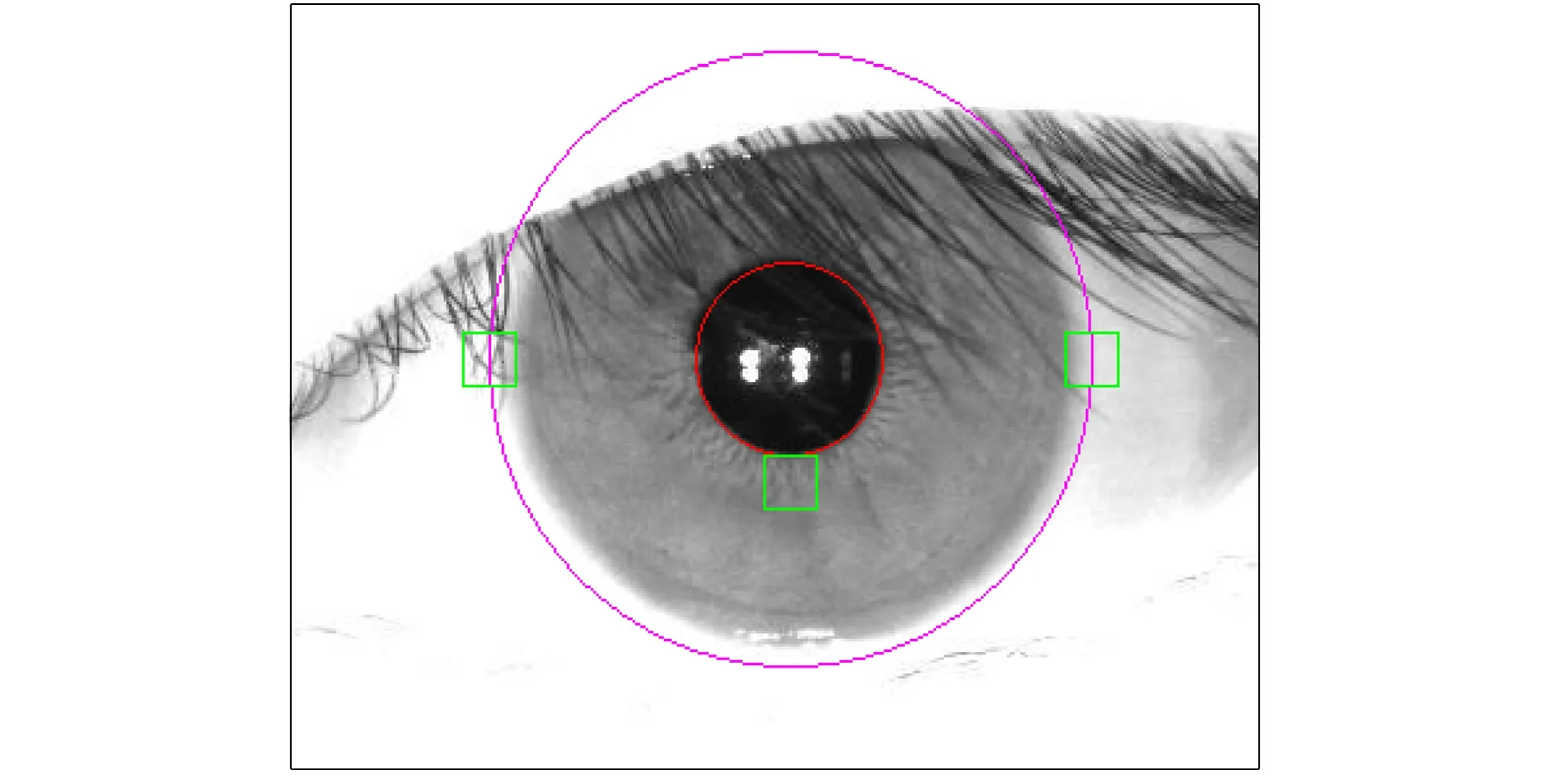
图11 模板区域和检测区域Fig.11 Template region and detection regions
图11中图像的虹膜圆心为(301.00,144.50), 半径为115.00; 左、 右两个检测区域灰度均值与模板区域灰度均值的比值依次为1.67和1.64, 左侧检测区域需向右移动, 右侧检测区域需向左移动.检测区域移动后如图12所示.此时, 两个检测区域灰度均值与模板区域灰度均值的比值依次为1.35和1.44; 两个检测区域中心坐标依次为(196.00,144.50)和(411.00,144.50).调整后的圆心为(303.50,144.50), 半径为107.50.调整后的虹膜外圆如图13所示.

图12 移动后的检测区域Fig.12 Detection regions after movement

图13 虹膜外圆精定位Fig.13 Fine positioning of outer circle of iris
3 实验与分析
3.1 数据集和参数设置
本文数据集由吉林大学自主采集的虹膜库JLU4.0,JLU6.0和中科院虹膜库CASIA-IrisV4-Interval组成, 其中选取JLU4.0数据库中40个类别, 每类别选取100张图像, 共4 000张图像; 选取JLU6.0数据库中20个类别, 每类别选取80张图像, 共1 600张图像; 选取CASIA-IrisV4-Interval数据库中60个类别, 每类别选取10张图像, 共600张图像. 其中包括睫毛较重、 贴近边缘等类型图像. 对每个样本进行人工标记虹膜内外圆, 并对每个数据集按照4∶1的比例划分训练集和测试集.
JLU4.0和JLU6.0数据库中数据尺寸为640×480, CASIA-IrisV4-Interval数据库中数据尺寸为320×280, 本文网络输入尺寸为480×480, 因此在输入网络前需对3个数据集分别进行预处理. JLU4.0和JLU6.0数据库中数据以长边为基础裁剪得到480×480的图像, CASIA-IrisV4-Interval数据库中数据对长边和短边做填充操作得到480×480的图像.
Bneck结构中一个主要的参数是扩张系数t, 本文设置两次下采样之间使用同一个扩张系数, 为确定一组最优的t, 选择几组不同的扩张系数进行实验, 实验结果列于表2.

表2 Bneck结构中扩张系数t的设置

图14 虹膜区域归一增强过程Fig.14 Normalized enhancement process of iris region
选择F1值[22]为评价指标, 对精确率和召回率进行调和平均, 该值越大表示模型的输出越好. 平均精度均值(mean average precision, mAP)[22]是衡量多类别目标检测的指标.F1值(iris)表示虹膜外圆F1值,F1值(pupil)表示虹膜内圆F1值. 由表2可见, 参数设置为t={1,3,3,6,6}时,F1值(iris)最高, 参数设置为t={1,2,2,2,6}时,F1值(pupil)最高, 且平均精度均值最高. 综合考虑, 将t={1,2,2,2,6}应用于本文模型中.
实验使用Intel Core i7-8550处理器, 内存为12 GB, NVIDIA GeForce MX150显卡, Window10操作系统的PC机, 模型框架为pytorch1.2.0, 编程语言为python 3.6. 训练模型的超参数设置如下: 训练批次大小Batch_size=2, 模型训练次数Epoch=100, 初始学习率为0.001, 优化算法选用Adam算法. 本文将Daugman[4]的微积分圆模板法、 Wildes[5]的Hough圆定位法、 文献[7]的分块搜索法、 文献[8]的单位扇环灰度法、 文献[9]的级联神经网络多任务虹膜快速定位方法、 YoloV3[12]、 YoloV4[11]、 不改变YoloV4的主干结构模型作为对比方法.
3.2 评价指标
本文选择目标检测常用的mAP和虹膜识别系统中常用的正确识别率(correct recognition rate, CRR)、 等错率(equal error rate, EER)和ROC曲线[23]作为评价指标. ROC曲线是表示错误拒绝率(false reject rate, FRR)和错误接收率(false accept rate, FAR)关系的曲线. 在同一阈值下, 二值呈反比关系, ROC曲线越接近坐标轴, 系统性能越好. FAR和FRR相等时的值为EER.
3.3 虹膜图像特征表达与匹配
在进行虹膜图像归一化时, 本文的对比实验均使用Daugman[4]提出的橡皮圈模型将环形虹膜展开成512×64矩形, 并进行图像增强, 截取左上角纹理最强的部分256×32区域作为虹膜识别区域; 使用水平移位, 消除虹膜旋转[24]. 该过程如图14所示. 使用二维Gabor滤波[25]提取虹膜的纹理特征, 通过对比样本间的欧氏距离[26]判断虹膜类别.
3.4 实验结果分析
根据不同IoU阈值下平均定位准确率、 内外圆平均定位时间以及CRR,EER和ROC曲线对不同算法进行比较. 在吉林大学JLU4.0,JLU6.0数据库和中科院CASIA-IrisV4-Interval数据库中的实验结果分别列于表3~表8, ROC曲线分别如图15~图17所示.

表3 JLU4.0数据库中不同IoU阈值下不同算法的平均定位准确率和平均定位时间

表4 JLU6.0数据库中不同IoU阈值下不同算法的平均定位准确率和平均定位时间

表5 CASIA-IrisV4-Internal数据库中不同IoU阈值下不同算法的平均定位准确率和平均定位时间

表6 JLU4.0数据库实验结果
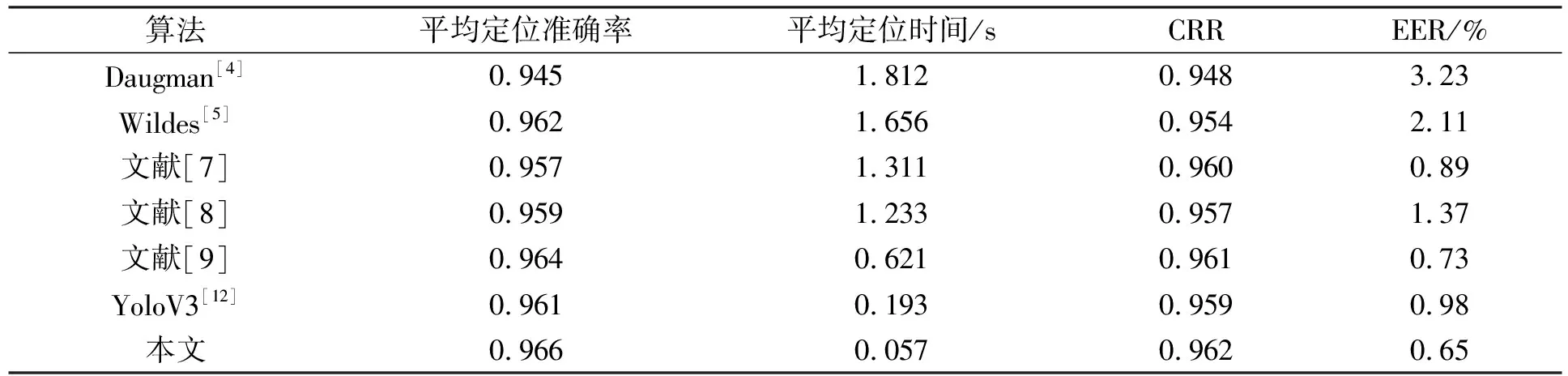
表7 JLU6.0数据库实验结果

表8 CASIA-IrisV4-Interval数据库实验结果

图15 JLU4.0数据库实验结果ROC曲线Fig.15 ROC curves of experimental results of JLU4.0 database
表3~表5对原始YoloV4网络、 不改变YoloV4主干部分和本文算法进行了比较, 其中不改变YoloV4主干部分是指除主干部分外其余部分均与本文算法相同. 由表3~表5可见, 当IoU阈值较小时, 本文方法平均定位准确率存在略小于YoloV4模型和不改变YoloV4主干部分的网络模型的情形, 这是由于原始YoloV4主干特征提取网络结构复杂且网络参数较多, 能更好地适应复杂环境下的目标检测. 随着IoU阈值的增大, 由于在网络预测基础上增加精定位, 不改进YoloV4主干部分的网络模型和本文算法的平均定位准确率高于YoloV4模型. 本文将主干部分网络替换为改进后的MobileNetV3模型, 平均定位准确率较替换前的网络模型有所提升, 内外圆平均定位时间较替换前大幅度减少. 说明本文使用的改进Mobile_YoloV4模型和灰度差值精定位不合格虹膜图像的思想对定位速度和定位准确率的提升具有关键作用.

图16 JLU6.0数据库实验结果ROC曲线Fig.16 ROC curves of experimental results of JLU6.0 database

图17 CASIA-IrisV4-Interval数据库实验结果ROC曲线Fig.17 ROC curves of experimental results of CASIA-IrisV4-Interval database
表6~表8和图15~图17对Daugman[4]算法、 Wildes[5]算法、 文献[7]、 文献[8]、 文献[9]、 YoloV3算法和本文算法进行了比较. Daugman[4]利用圆检测算子检测内外圆, Wildes[5]利用Hough变换和投票机制搜索内外圆, 这两种方法都是在全局范围内定位内外圆. 文献[7]的分块搜索法虽然在局部范围内进行边缘定位, 但在粗定位时采用先内圆后外圆的方法, 过程非常耗时. 文献[8]采用投影法、 灰度直方图和扇环灰度值分别定位内圆和外圆, 同样导致定位时间较长. 同时, 上述算法在遇到光斑、 睫毛眼睑等干扰或图像边缘噪声等问题时, 定位效果并不理想, 从而导致识别效果不稳定. 文献[9]采用先生成候选框再进行细粒度物体检测的思想分两阶段同时定位内外圆, 有效解决了正负样本不均衡的问题, 准确率较高, 识别效果较稳定, 但两阶段的检测任务使得检测速度较慢, 不能满足虹膜系统实时性的要求. YoloV3[12]直接在网络中提取特征预测物体分类和位置, 虽然定位时间约为0.2 s, 但相比两阶段的算法, 随着识别标准的升高准确率会逐步下降, 同样导致识别效果不稳定. 本文首先将Focal Loss作为损失函数, 解决了正负样本不均衡的问题, 同时引入改进的MobileNetV3作为主干特征提取网络, 使用快速soft-DIoU-NMS算法去除冗余框, 后续对不合格的图像再次进行精定位, 使定位时间大幅度下降, 并提升了定位准确率, 能准确定位受睫毛、 光斑等干扰的图像, 增强了虹膜定位的鲁棒性, ROC曲线较其他算法更接近于坐标轴, 识别效果更稳定.
综上所述, 本文提出了一种基于改进YoloV4网络的虹膜定位算法. 首先, 利用改进Mobile_YoloV4网络模型在两个维度对虹膜内外圆进行粗定位, 同时, 使用K-means++聚类算法生成先验框, 引入Focal Loss函数作为类别损失函数解决正负样本不平衡问题, 改进非极大值抑制为快速soft-DIoU-NMS算法去除预测过程中的冗余框, 提高算法检测率; 其次, 挑选出小于内外圆IoU阈值的虹膜图像; 最后, 利用二值化图像对小于IoU阈值的内圆进行精定位, 利用虹膜和巩膜的灰度差值对小于IoU阈值的外圆进行精定位. 实验结果表明, 相比于传统算法, 本文方法通过利用神经网络可以同时定位内外圆且能准确定位出受干扰的图像; 相比于Two-stage算法和Yolo系列算法, 本文方法通过改进损失函数和非极大值抑制、 引入MobileNetV3、 改进网络结构以及筛选不合格虹膜进行精定位, 提高了虹膜定位准确率, 缩短了定位时间, 提高了定位速度, 识别效果稳定.
