基于Soft-Masked BERT的新闻文本纠错研究
2022-05-30史健婷吴林皓张英涛
史健婷,吴林皓,张英涛,常 亮
(1.黑龙江科技大学,黑龙江 哈尔滨 150022;2.哈尔滨工业大学,黑龙江 哈尔滨 150000)
1 研究背景
当今的时代是一个信息爆炸的时代,在社交网络、智能互联设备等的共同推动作用下,网络数据以指数倍增长。据不完全统计,2014年,互联网用户达24亿。2016年,用户量增长到34亿,2017年用户量达37亿。截至2019年6月,已有超过44亿互联网用户。在短短五年内,互联网用户增加了83%,每个用户每时每刻都在产生大量的数据,互联网个体用户已然成为独立的数字信息生产者,而在数据流通过程中,电子文本信息占据了相当大的比重,社交评论、即时通讯、电子读物、网站专栏、电子出版等内容共同组成了体量庞大的文本模块。
在互联网时代的新闻宣传领域,每天都会产生大量的文本稿件,对文本初稿的校对是一项体量巨大的工作,仅仅依靠人工进行校正成本极高,效率低下。中文错別字侦测技术可以应用在教育及出版等许多领域。相比于英文纠错过程,中文纠错技术更具有挑战性,包含语法错误、拼写错误、搭配错误、语境错误等多种情况。虽然近期许多研究提出了一些能提高效能的模型,但这些模型却存在误报率偏高的缺点[1]。因此,寻找一种全新的方法来对新闻初稿进行自动校正具有十分重要的现实意义。通过计算机对新闻初稿进行审阅可以极大地提高校稿效率,大大减少人力成本与时间成本,如果进一步利用特定新闻领域语料集的深度学习模型,完成个性化定制,那么在该领域的纠错过程中可以取得更好的效果。
2 研究方法
早在2003年,骆卫华等人就提出中文文本自动校对的研究还处在摸索阶段。其方法多为字、词级别上的统计方法和基于规则的短语结构文法,其团队发现中文文本自动校对的研究集中在词级和句法查错两方面,其中语义级查错仍是薄弱环节[2];Vaswani A等人[3]在研究中提到BERT使用了Transformer作为算法的主要框架,通过双向Transformer结构使得网络能更加彻底地捕捉到语句中的双向关系,从而将上下文语境联系起来,使模型在质量上更优越,更具可并行性,同时需要更少的训练时间(如图1所示)。
Wilson L Taylor[4]研究了Mask Language Model(MLM)和Next Sentence Prediction(NSP)的多任务训练目标,隔离实验表明NSP对于提取句间关系是有效的;Gu S等人[5]使用Seq2seq模型对中文文本进行校正,将文本校正器视为一个序列学习问题,利用偏解码的方法来提高模型的双语评估替代研究分数;Gehring J等人[6]就基于卷积神经网络的序列到序列(convolution sequence to sequence,ConvS2S)模型进行了讨论,通过递归神经网络将输入序列映射成可变长度的输出序列,所有元素的计算可以在训练期间完全并行化,以更好地利用GPU硬件;Wang H等人[7]将语法错误纠正(GEC)视为一个序列到序列的任务,使用Bert的Pre-train模型对汉语语法进行纠正,证明了基于BERT的预训练模型在中国GEC任务中的有效性。Google AI团队凭借强大的算力训练超大规模的数据,使BERT的效果达到全新高度,用户通过使用开源的BERT模型,可以将其作为Word2Vec的转换矩阵并应用到个人下游任务中。BERT的应用证明层数较深的模型可以显著提高NLP任务中的准确率,且该模型可以通过无标记数据集中预训练得到。
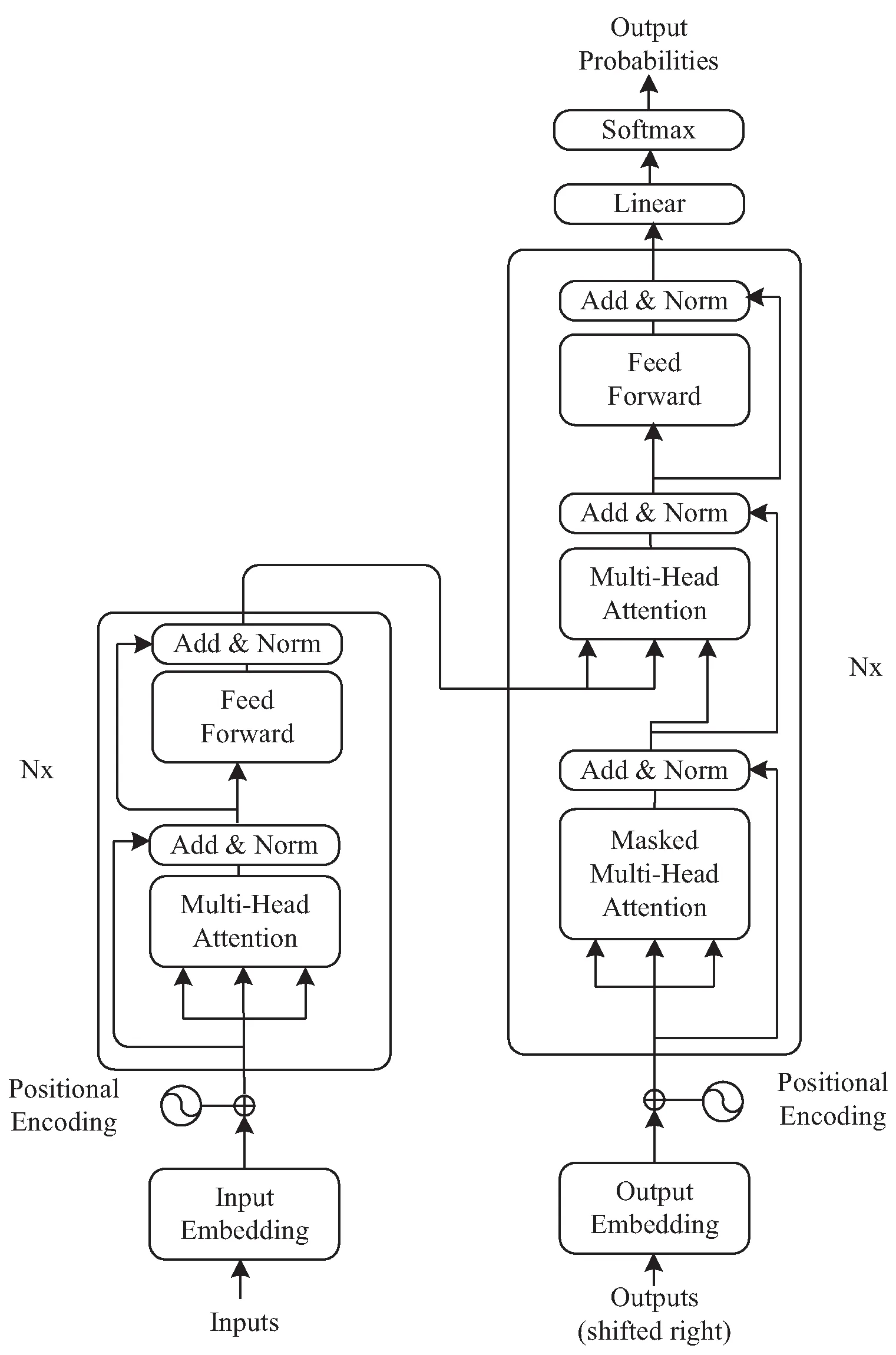
图1 Transformer原理图
目前出现了大量使用BERT来在NLP各个领域进行直接应用的工作,方法都很简单直接,效果总体而言比较好,比如问答系统、搜索与信息检索、对话系统、文本抽取、数据增强、文本分类、序列标注等等[8]。与RNN不同,BERT计算当前词汇特征并不需要依赖前文计算数据,不需要受时序问题的制约,而是同时利用上下文信息运算,通过矩阵的模式快速获取每句话的token特征。Tan M等人为解决正式文件编写过程中拼写错误造成的字符串错误比例过高的问题,提出了一种基于BERT结构转换的字符语音BERT模型,通过使用BiLSTM网络检测错误字符的位置,然后将错误位置的拼音先验知识加入到BERT网络中,从而实现端到端的拼写错误检测和纠正[9];Cao Y等人基于BERT模型、双向长期短期记忆(BiLSTM)和条件随机字段(CRF)设计并实现了具有得分功能门的错误诊断器(BSGED)模型,该模型用较少的先验特征获得了较好的结果,大大减少了特征工程的工作量,同时保留了特征项之间的偏序关系,大大减少了模型训练参数的数量[10];Wu S H等人通过使用条件随机场(CRF)和BERT模型深度学习方法的组合在NLPTEA-2020 CGED共享任务中的中文语法错误诊断系统评估中取得了更好的效果[11-12]。
传统的统计机器学习方法通过维护一个中文语料词库和一个词语编辑距离库,利用注音机制对文本进行读音纠错并根据词库中的词汇及频率进行替换[13]。然而,传统统计机器学习方法需要维护和更新容量巨大的词库,并且要通过不断对词库进行人工扩充来解决未登录词的问题,人力成本高,维护成本高,同时仅仅根据拼音机制进行检错纠错准确率较低,会出现相当一部分文本无法识别和纠正的情况。N-gram模型将文本里面的内容以字节为单位生成大小为N的滑动窗口,形成了长度为N的字节片段序列,通过统计gram的出现频度,按设定的阈值进行过滤,生成关键gram的向量特征空间,每种gram代表一个特征向量维度。其包含当前词以及当前词之前的N-1个词所提供的全部信息,从而对一个句子中的各个词进行约束,但是无法解决远距离词问题以及数据稀疏问题;基于卷积的seq2seq模型通过引入Stacking conv来捕捉长距离的信息,通过编解码的方法来提高模型的双语评估替代研究分数,采用了更合理的令牌方案,增强了纠错机制的鲁棒性,但是BLEU的指标会随着句子长度的增长而逐渐降低。
Google的BERT模型使用大量未标记语料集进行无监督预训练,之后再使用标记数据进行微调,进而从给定句子的各个位置的候选列表中预测可能性最大的字符进行纠正替换,因此BERT模型自身具有了一定程度的获取语言、理解知识的特性[14]。在特征提取器的使用过程中,Transformer仅仅使用了self-attention机制,并没有选择使用RNN与CNN,同时结合使用残差连接来解决梯度消失问题,使其方便构建更深层的网络结构,即BERT通过构建更多层深度Transformer来大幅提高模型性能。通过添加前馈网络来提高模型的非线性能力,同时利用多头注意力机制从更多角度全面提取信息。利用BERT模型从候选词列表中选择字符对句子的各位置错别字进行纠正,因此成为了界业的常用方法之一,但由于BERT初始模型是通过Mask掩码语言建模对语料进行预训练,使得BERT缺乏足够的能力去检测句子的每个位置是否都有误差,进而使得仅使用BERT模型的中文纠错Baseline过于粗暴,很容易造成高误判率。
基于上述情况,文中使用一种全新的中文文本纠错模型理论:Soft-Masked BERT,该模型将中文文本的检错过程与纠错过程分离,纠正网络的输入来自于检测网络输出。文中旨在Soft-Masked BERT基础上进行改进应用,使用“哈尔滨工业大学新闻网”新闻稿件中10 000条文本序列(HIT News Site)作为初始语料进行训练,以对该新闻网的相关稿件进行中文文本校对。
3 Soft-Masked Bert算法
Soft-Masked模型主体分为两部分:检错网络与纠错网络,两个网络之间通过Soft-Masked技术连接成一个整体,错误检测网络(Detection Network)的输出信息即为BERT校正网络(Correction Network)的输入信息(如图2所示)。其中Detection Network是一个双向的GRU(Gate Recurrent Unit)网络,即双向的门控循环单元,功能是预测字符在各个位置上发生错误的概率,Correction Network是基于BERT的校正网络,对检错成功的位置上的字符进行纠正与替换。
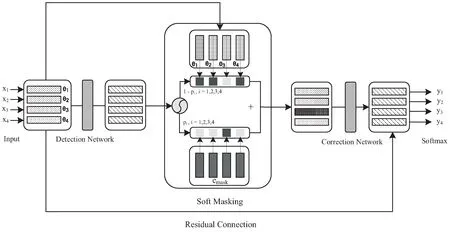
图2 Soft-Masked网络结构
GRU常用来解决传统RNN网络在反向传播期间出现的梯度消失问题,从而避免短期记忆现象的出现(如图3所示)[15]。GRU利用门(Gate)的内部机制来调节单元之间传输的信息流,判断何种数据需要保留,何种数据需要舍弃,从而将较早时间步中的相关信息传递到较晚时间步的长序列中进行预测。GRU利用隐藏态传递消息,核心结构是重置门(Reset Gate)和更新门(Update Gate),Reset Gate决定对过去信息的遗忘部分,Update Gate决定当前时间步里需要舍弃哪些信息以及需要添加哪些信息。
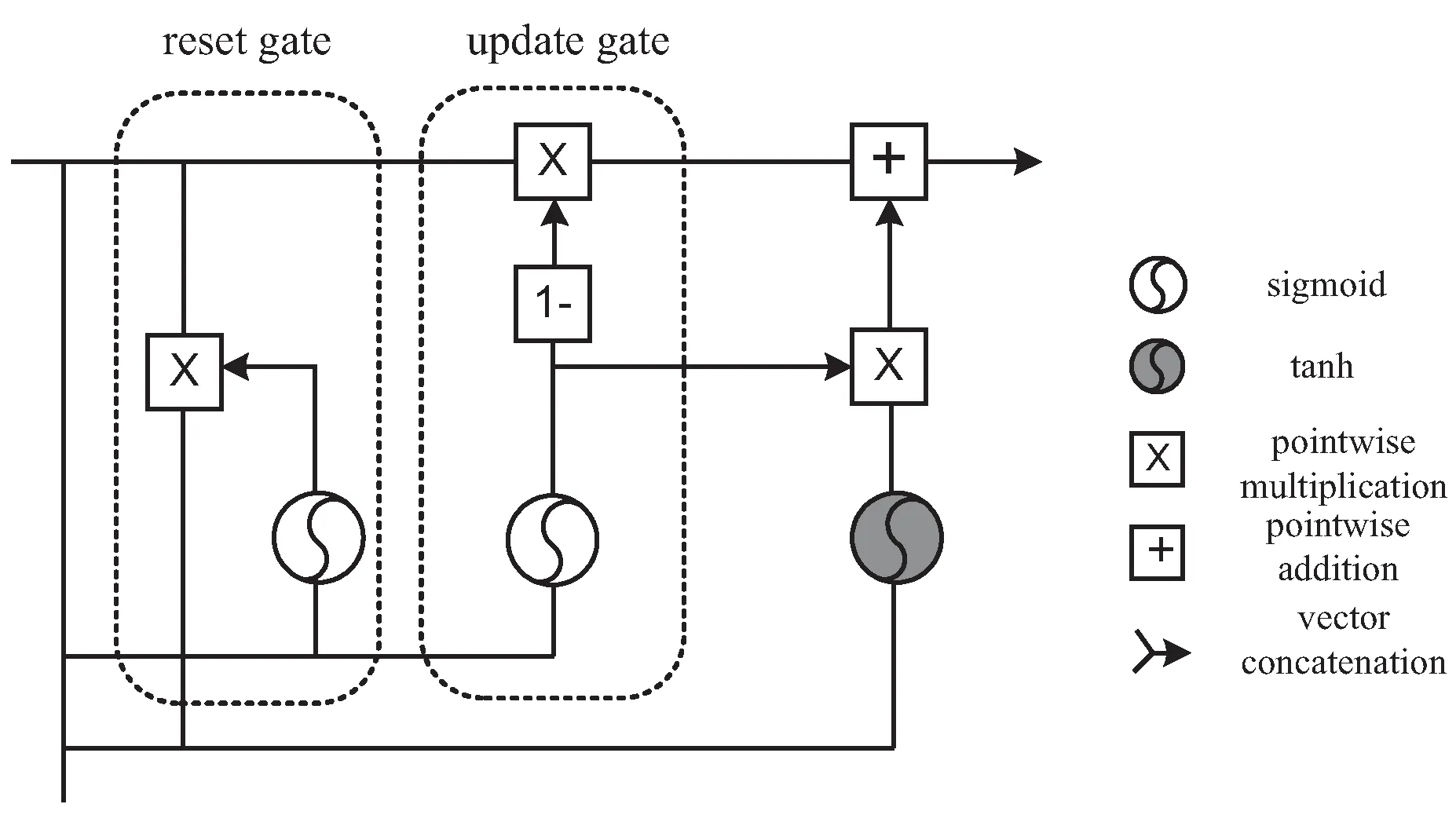
图3 GRU结构
对于检测网络中的双向GRU网络序列的每个字符,错误概率的定义为:
(1)
其隐藏状态被定义为:
(2)
(3)
(4)
将前后两个部分的embedding进行相加形成e-mask机制,经以下公式:
(5)

对于纠错网络序列的每个字符,纠错概率定义为:
(6)
在错误检测和错误纠正过程中对应两个目标驱动函数:
(7)
(8)
将两个目标驱动函数线性结合即得到总体学习目标:
(9)
参数pi即当前位置字符是错别字的概率,利用该概率值pi对该位置的字符嵌入进行Soft-Masked处理,pi越接近1,该字被认为是错别字的可能性就越大,反之pi的值越接近0,此时完成了Soft-Masked模型中的检错部分。
4 数据处理与实验设置
4.1 实验数据介绍
网络输入的初始语料对于模型的应用领域与最终效果极为重要,文中使用的语料来自于“哈尔滨工业大学新闻网”公开新闻稿,涉及的内容板块包括 “学校要闻”、“综合新闻”、“媒体看工大”、“哈工大报”四个部分。
通过对该网站的四个板块原始的文本内容进行抓取,形成自建的公开小型数据集(HIT News Site)作为原始语料,通过使用jieba分词库与hit_stopwords停用词表将原始语料进行词语词频的分词处理,形成可用于深度网络训练的词典。再将原始语料以标点符号为间断分成短句形式,将无关信息删除后统一规整,形成10 000个文本序列作为深度网络训练的真实输入语料。
使用自建数据集可以实现语料集的定制化,与通用公开数据集相比有独特的优势,可以相对精确地检测模型在特定领域的性能表现,如在Hit News Site数据集中的特定词“哈工大”、“刘永坦院士”、“永瑞基金”等,可以视为检错和纠错过程中独特标志词。
4.2 数据集预处理
Soft-Masked Bert的模型需要将初始语料处理为“完全对齐语料”,即通过“错字-正字”的映射阵列来检测纠错的可靠性,同时,在对文本进行纠正测试时需要联系上下文文本信息环境,因此模型整体对训练语料的预处理程度依赖很大。
文中对初始语料进行“掩盖”处理,将总文本集划分成为训练集与测试集,生成“错字-正字”的映射对,用于实验结果的测试。其中错误序列的生成过程包括对文本语句中的字级进行替改、删除、增添的随机造错,以模拟现实文本纠错过程中可能出现的各种情况。在预训练过程中,通过维护一个包括随机同音字、生僻字以及随机字符的“混淆表”文本文件,配合随机数算法用以生成“错字-正字”映射中的“错字”部分(如图4所示)。

图4 “错字-正字”映射
由图4可知,在替改方法中将正字“馆”字替改成了错字“蟀”,在删除方法中将“开放”中的“开”字删掉,在增添方法中在句尾添加了生僻字“紘”,以此方法来随机生成所有测试集(如图5所示)。

图5 测试集
最终在总文本的预处理过程中生915个“错字-正字”文本对作为测试集阵列,用于模型训练完成后的测试使用,充分保证了实验的随机性与可靠性,避免数据泄露现象出现干扰实验结果。
4.3 实验设置
实验中将MLM学习率(MLMLearningRate)设为1e-4,Batchsize设为16,输入句长设为512,掩盖率(MaskRate)设为0.15,测试文本句经过embedding之后的隐藏层维度为768,自注意力头尺寸设为12,中位尺寸为3 072,经过Bert的embedding机制将原始文本转化为“token_embedding+position_embedding+segment_embedding”的词向量,此时向量的维度是(16,512,768),将该向量输入到Detection Network的双向GRU中,得到新维度(16,512,1 536),在网络连接部分接入全接连层(1 536,768)将维度恢复为初始的(16,512,768),在训练中连续进行16个Epoch,得到最终的训练模型。
4.4 实验结果与分析
在训练过程中采用16次迭代训练(EP0—EP15),得到训练过程中的纠错率与损失率Mask Loss,以迭代次数epoches为横轴,以训练时损失率Train_mask loss为纵轴,绘制出训练过程Loss收敛曲线(如图6所示)。

图6 Mask Loss曲线
由曲线可知,随着迭代训练的进行,数据拟合度不断提高,各参数变化趋于稳定,损失值逐渐走低,最终稳定在0.19,模型训练效果较为理想。
与之前的研究工作相似,文中采用了准确度(Accuracy)、精确度(Precision)、召回率(Recall)以及F1-Score(F1分数)4个数值作为评价指标,来评估文中模型的纠错性能。
在使用Bert模型进行对比实验时,微调过程保留默认超参数,保持学习率为2e-5,输出对比结果(如表1所示)。
结合表1的对比数据可以看出,完全不进行微调的BERT-Pretrain(BERT预训练)过于泛化,无法适应精确领域中的特定学习任务,缺乏足够的有监督数据,故其纠错性能非常差,在实际工作中几乎无法正常使用;BERT进行微调后的BERT-Finetune由于其自身有大规模无标记语料的预训练作为基础,因此具有一定的语言理解能力,在准确率上可以达到70.5%;经对比,Soft-Masked模型在HIT News Site数据集上的整体性能表现优于BERT-Finetune,准确率提高0.6个百分点,精确率提高1.3个百分点,召回率提高1.5个百分点,F1分数提高1.4个百分点,效果良好。

表1 模型表现对比 %
与此同时,在研究中也发现了一些影响进一步提升实验准确率的因素。文中模型的纠错部分使用的是一个基于BERT的序列多分类标记模型,相较于RNN与LSTM,BERT可以一次性读取整体文本序列,提取多个层次的文本信息,更加全面地诠释文本语义,通过注意力机制,并行计算每个位置相对另一个位置的权重,如果计算资源充足,训练速度会比LSTM快许多,同时由于使用海量无监督数据进行预训练,模型效果更优,但是由于BERT预训练模型本身规模较大,参数极多,在训练集体量较小的时候,容易发生过拟合,影响实验进程与最终准确率。BERT的部分mask字符,在下游的Finetune任务可能并不会再次出现,使得前后文本失去平衡,信息不匹配。尤其是针对两个及以上连续单字组成的词汇,随机mask掩盖会割裂连续字之间的相关性,致使模型难以学习到词的语义信息。对于文本中的词汇,BERT会将其分成词片,在随机mask的过程中,如果被mask的词片处于文本中间位置,会使该词汇失去与上下文的语义同步,导致最终的预测与上下文失去关联,偶然性加大。在NLP的纠错领域中,现有技术已经可以解决大部分的文本拼写错误,但是对于部分需要常识背景(world-knowledge)的文本纠错问题,例如同音异义词问题(如图7所示)时效果会不尽人意,必须利用一定程度的背景知识,模拟真人对该类问题进行推理和分析,这也正是当前NLP纠错研究中的难点。
在某些强调实时性的纠错场景中,对模型的硬件以及实效性都要求较高,需要对纠错的时延有较为严格的限制,容易导致规模庞大的字典库以及结构过于复杂的精密模型无法广泛适用。另外,文中模型的语料集局限于完全对齐文本,这给模型的推广使用带来了不便。Zheng L等人近来提出了一种可以同时处理对齐文本和不对齐文本的校正框架[16],可以更好地启发下一步研究。使用文中模型得到的纠错结果如图8所示。

图7 同音异义词

图8 纠错结果
5 结束语
文中使用了BERT模型的改进模型Soft-Masked BERT对中文文本进行纠错检测,将原本的单向纠错过程分成了检测网络和校正网络两部分双向执行,对稿件文本中可能出错的字符进行Soft屏蔽,将检测网络的输出作为基于BERT的校正网络的新的输入,从而对可能存在错误的字符进行定位与校正。文中以“哈尔滨工业大学新闻网”(HIT News Site)的文稿作为数据集,最终的纠错准确率达到71.1%,相比BERT-Finetune模型提高0.6个百分点,效果良好。但是,Soft-Masked BERT模型的语料集必须是完全对齐文本,需要通过使用“错字-正字”序列来检测性能,在特定阈值下可能会出现只能定位无法纠正的问题。在未来的研究中,将Soft-Masked BERT与现实应用联系起来,仍是一个值得探索的课题。
