基于迁移学习的多场景垃圾图像分类方法
2022-05-30杜永萍常燕青韩红桂
彭 治,刘 杨,杜永萍,常燕青,韩红桂
(1.北京工业大学 信息学部,北京 100124;2.江苏省固体废弃物处理环保装备工程技术研究中心,江苏 常州 213000)
0 引 言
随着日常生活中产生的垃圾不断增加,对垃圾进行分类管理是实现垃圾资源回收利用,同时达到垃圾减量的重要途径。传统的垃圾分类依靠人工手动进行,需要耗费大量的人力物力,分类效率低。图像识别是实现智能化垃圾分类的重要方法,基于神经网络模型的图像识别与分类技术具有准确度高、泛化性能好等优点。
近年来在图像识别领域,深度学习网络应用较广,并在数据充足时有稳定的表现。目前,将图像识别技术应用于垃圾分类中也受到了学者广泛的关注与研究[1]。对于规模较小的数据集,深度神经网络模型在训练过程中容易产生过拟合的现象,而通过数据增强的方法可增加训练样本,有效缓解过拟合的问题[2-3]。此外,提高模型的泛化能力是深度神经网络模型最困难的挑战之一[3]。对于模型,不仅要求它对训练数据集有很好的拟合,同时也希望它可以在测试数据集上有很好的性能。数据增强可以实现数据更复杂的表征,让模型更好地学习迁移数据集上的数据分布[4-5]。目前,在图像分类模型中都普遍应用了数据增强技术,Krizhevsky等人提出的AlexNet[6]中,应用数据增强增加ImageNet数据集样本从而避免神经网络训练过程中产生过拟合。G. Huang等人提出的DenseNet[7]中,对CIFAR数据集采用标准的数据增强方案(镜像/移位)提高模型的泛化能力。
随着传统神经网络模型的深度不断增加,训练过程中会出现梯度消失、梯度爆炸、模型过拟合等问题[8]。通过正则化的方法对大量数据进行训练可以有效地解决过拟合问题,在一定程度上缓解浅层网络的梯度消失/梯度爆炸问题,更快地训练稳定的网络[9-10]。如果网络层数继续简单增加,会出现网络退化,上百层的传统神经网络将难以训练。He等人[11]通过引入恒等映射,实现跳层连接,缓解了深度网络的退化问题,深度残差网络(deep residual networks,ResNet)逐渐成为了图像分类的核心技术。Inception[12-13]使用3个不同大小的滤波器对输入执行卷积操作,所有子层的输出最后会被级联,并传送至下一个Inception模块,实现了特征的复用,提高了特征张量宽度以及对特征的囊括性[13],也减缓了加深神经网络模型引起的梯度消失/梯度爆炸问题。
ResNeXt[14]是ResNet和Inception的结合体,不同于Inception v4[13]的是,ResNeXt不需要人工设计复杂的Inception结构细节,而是每个分支都采用相同的拓扑结构。ResNeXt的本质是分组卷积[15],通过变量基数来控制分组的数量。传统的模型通过加深或加宽网络来提高性能,但是随着超参数的增加,网络设计的难度和计算开销也会增加,而ResNeXt模型在不增加参数复杂度的前提下可以有效提高准确率,同时减少了超参数的数量。Lin等人[16]提出一种新的基于ResNeXt弱监督模型的染色体簇类型识别方法,识别准确率、灵敏度以及特异性都达到了较高的效果。
迁移学习是运用已有的知识对不同但相关领域问题进行求解的一种机器学习方法[17]。深度学习模型能够从海量数据中学习高级特征,但数据依赖是一个严重问题。与传统的机器学习方法相比,深度学习模型需要大规模数据来学习数据间的潜在关联[18]。在某些领域由于数据采集和标注费用高昂,构建大规模的高质量标注数据集非常困难。迁移学习放宽了训练数据必须与测试数据独立同分布的假设,因此利用迁移学习可以有效缓解训练数据不足的问题。例如,胡等人[19]提出了动态采样与迁移学习结合的疾病预测模型,在规模较大的多类别疾病数据集上训练预测模型,然后迁移到样本不足的疾病预测模型中,从而缓解数据不足的问题。迁移学习把训练好的模型(预训练模型)迁移到新的模型来进行训练[20-21],将已经学到的模型参数通过某种方式分享给新模型从而加快并优化模型的学习效率,而不需要对目标域内的新模型从零开始训练,显著地降低了对目标域内训练数据需求[22]。
该文将基于深度学习的图像识别技术应用于垃圾智能分类任务,采用ResNeXt模型提取有效特征,对于训练数据规模有限的问题,在利用数据增强技术扩大训练集规模的同时,进一步通过迁移学习的策略提升模型性能,实现垃圾图像的智能分类。
1 基于迁移学习的垃圾图像分类模型
该文提出了一种基于迁移学习技术的深度神经网络垃圾分类模型,ResNeXt网络在图像分类中具有高效性,采用该网络进行可回收垃圾图像的识别分类,模型结构如图1所示。在大规模数据集ImageNet上进行模型训练,并将其迁移到垃圾图像数据集,实现可回收物的准确识别分类。
为了进一步提升模型的分类准确率,对采集到的垃圾图像采用如下的方式进行数据增强,包括比例缩放、水平/垂直翻转、图像随机裁剪等不同的数据增强技术,获得丰富的训练样本用于模型训练,提升模型的鲁棒性和泛化能力。
(1)利用transforms.Resize()函数重新设置大小,统一输入图像大小;
(2)利用transforms.RandomCrop(size)函数对输入的图像进行随机裁剪,设置裁剪的大小(size)为300,将输入的图随机裁剪为300*300的图像;
(3)利用transforms.RandomVerticalFlip()和transforms.RandomHorizontalFlip()函数对随机裁剪后的图像分别依照默认的概率进行垂直翻转和水平翻转;
(4)利用transforms.RandomRotation()函数对翻转后的图像进行随机旋转一定角度;
(5)利用transforms.Normalize()和transforms.ToTensor()函数对旋转变换后的图像进行归一化,使模型训练时,梯度对每张图片的作用都是平均的。
经过数据预处理实现数据增强后,将图像输入模型进行训练,训练集更加丰富,使模型具有较好的泛化能力。
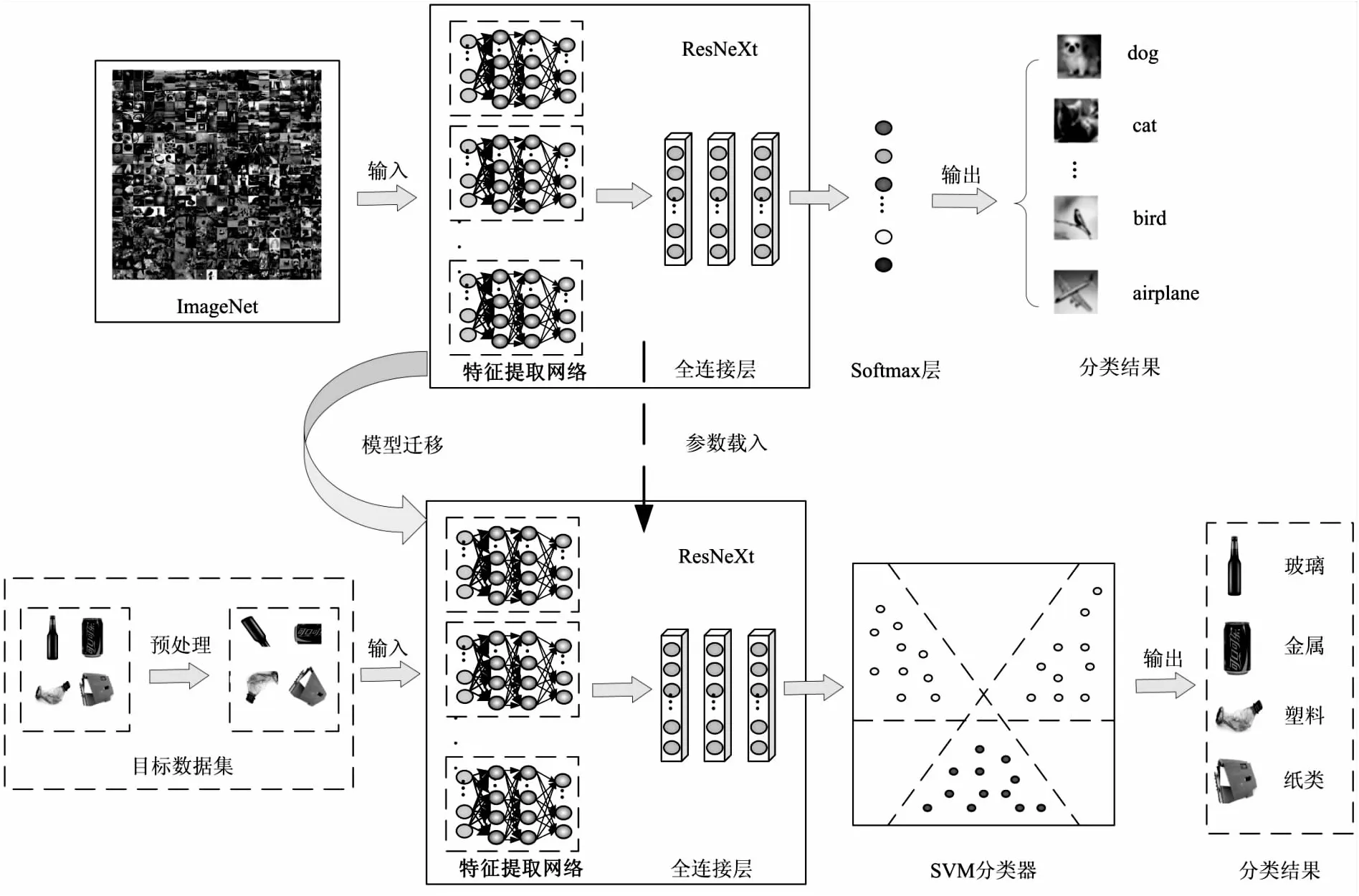
图1 基于迁移学习技术的垃圾图像分类模型
2 基于残差网络的特征提取与分类
2.1 特征提取网络
在分类模型中,采用残差网络ResNet和Inception的结合体,即ResNeXt,实现特征提取。在大规模图像分类数据集ImageNet上进行预训练得到ResNeXt的网络结构和参数。

ResNeXt利用聚合变换的思想,采用一个更通用的函数代替初等变换(wixi),它本身也可以是一个网络,聚合转换可以表示为:
(1)
其中,Ti(x)可以是任意函数,类似于一个简单的神经元,Ti将x投影到一个(可选的低维)嵌入表示中,然后进行转换。
在公式(1)中,C是要聚合的转换集的数量,称为基数。虽然宽度的维度与简单变换(内积)的数量有关,但基数的维数控制着更复杂的变换的数量。实验表明,基数是一个基本的维度,比宽度和深度的维度更有效。
最后,公式(1)中的聚合转换用作残差函数,得到最终的形式,如公式(2):
(2)
其中,y为输出。
ResNeXt采用同构多分支的结构,使模型有更少的超参数;同时引入基数,基数增加可提高模型分类效果,比传统的加深或加宽网络模型有更好的性能。在模型迁移过程中调参过程更简单并具有更强的鲁棒性。
2.2 SVM分类器实现图像分类
传统的卷积神经网络分类模型提取图像特征后,通常采用softmax分类层进行分类,该文使用SVM代替softmax分类层。
支持向量机属于线性分类器,它将一系列的输入数据映射到类别上,通过寻找超平面实现对样本的分类。支持向量机的预测输出是f(x)=Wx+b。该文采用多类SVM损失函数作为目标函数:

(3)
(4)
其中,yi表示真实的类别,syi表示在真实类别上的评分,sj表示预测错误的评分。
对于一个样本,模型预测的结果是一个评分,通过优化损失函数,分类器函数拟合这些样本,使大部分样本输出满足f(x)>0。若图像恰好落在分类超平面,其评分等于0,离超平面越远,评分的绝对值也就越大,箭头方向指向评分的正增长方向,表示正确的分类结果。
3 实验结果与分析
针对垃圾图像数据中存在的单一背景与复杂背景两种不同场景,分别进行了实验。在单一背景中,每张垃圾图像只有一个目标物体;在复杂背景中,每张垃圾图像中有多个物体,包含复杂的背景干扰。该文同时针对厨余垃圾中是否混有杂质(如:可回收物)的问题,利用图像分类技术进行检测。
3.1 实验环境
模型训练与测试均是在Pytorch的深度学习框架下完成的。实验平台为Ubuntu系统、Nvidia GTX1080 Ti GPU,12 GB显存和CUDA 11.1。模型的训练与测试均通过GPU加速。
3.2 数据集
(1)单一背景数据。
在单一背景图像数据的实验中所用到的垃圾图像数据是在kaggle和华为云等平台进行采集,从中筛选出玻璃、金属、塑料、纸类4类可回收垃圾图像进行识别。
(2)复杂背景数据。
在复杂背景实验中所用到的垃圾图像数据是通过人工采集到的垃圾图像,包括纯厨余垃圾和非纯厨余垃圾2类图像数据。
采集到的4类单一背景的可回收垃圾图像样本共9 620张,2类复杂背景图像样本共4 681张,图像数据分类统计如表1所示。

表1 单一背景和复杂背景图像数据分类统计
3.3 评价指标
采用准确率(Accuracy)来对测试结果进行评价。
Accuracy=(TP+TN)/(TP+FP+FN+TN)
(5)
其中,TP(true positives)为正确地划分为正例的个数,即实际为正例且被分类器划分为正例的样本数;FP(false positives)为被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的样本数;FN(false negatives)为被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的样本数;TN(true negatives)为被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的样本数。
3.4 实验结果与分析
将数据集按7∶3分割为训练集和测试集,并将测试集随机均分为三组进行测试,同时采用ResNet101模型(基础的残差网络模型)进行对比实验。在训练过程中,设置超参Epoch为100,训练数据集100次,在每次训练的图像输入阶段,将所选图像进行数据增强处理,提升训练数据量的同时增强模型鲁棒性。初始化学习率为0.001,每10次迭代进行一次验证评价。
单一背景下的图像数据在训练过程中损失和准确率变化如图2所示。损失值在前700次迭代下降较快。在2 000次迭代训练后,损失趋近于0,训练准确率趋于稳定。
复杂背景下的图像数据在训练中的损失和准确率变化如图3所示,损失值在前1 000次迭代下降较快。在2 500次迭代训练后,损失趋近于0,训练准确率趋于稳定。
单一背景图像数据测试集的实验结果如表2所示。
单一背景下,经过实验结果验证,基于ResNeXt101模型方法的准确率都稳定在93%以上,在纸类回收物模型平均最高准确率达到98.15%,而ResNet101模型的准确率相对较低。这表明ResNeXt通过变量基数来控制分组的数量,在不增加参数复杂度的前提下可以有效提高准确率。
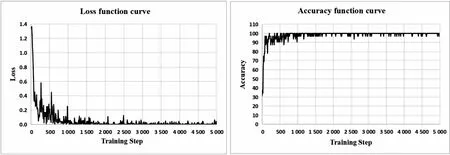
(a)损失(Loss) (b)准确率(Accuracy)图2 单一背景图像训练集损失值和准确率
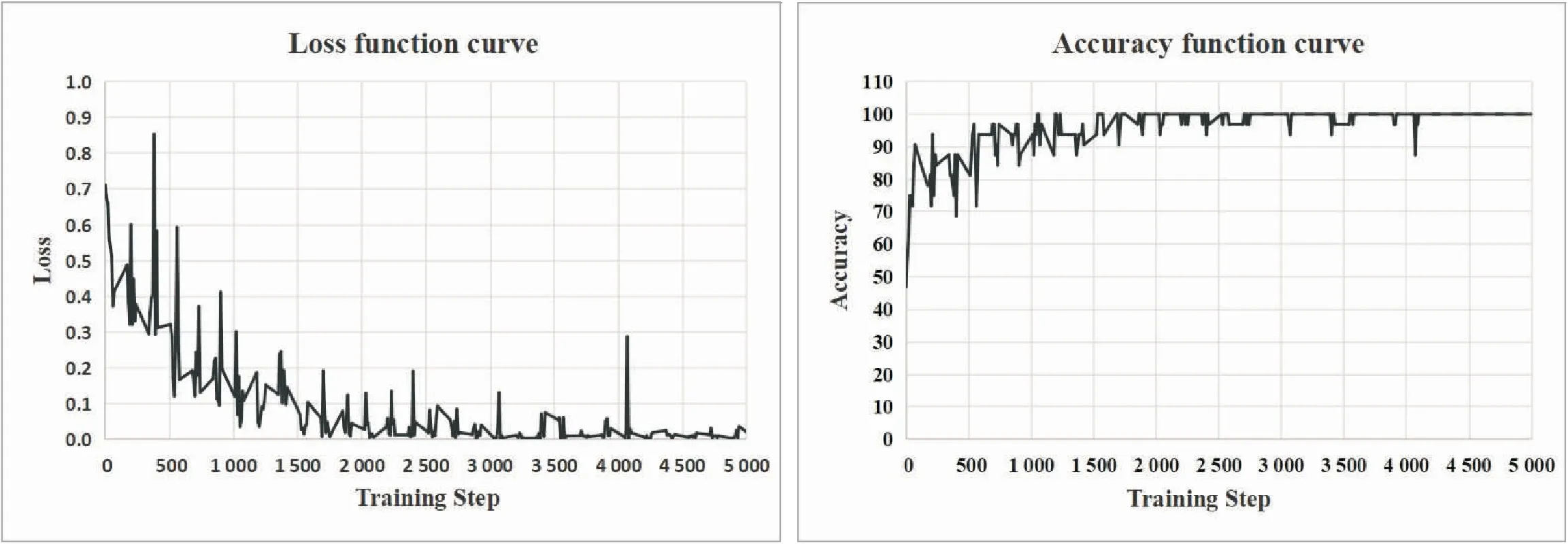
(a)损失(Loss) (b)准确率(Accuracy)

表2 单一背景图像测试集准确率(Accuracy)
复杂背景图像测试集测试的结果如表3所示。

表3 复杂背景图像测试集准确率(Accuracy)
复杂背景下,经过实验结果验证,基于ResNeXt101模型方法的准确率稳定在86%以上,总分类准确率为87.42%。模型能够在复杂背景下有效地检测厨余垃圾中是否包含杂质。
基于ResNeXt101模型方法得出的混淆矩阵如图4(a)、(b)所示,分别表示单一背景与复杂背景的不同场景分类结果,纵坐标表示图像的真实标签,横坐标表示模型的预测标签,矩阵对角线上的值代表模型分类正确的结果,其余数值分别代表每个类别的分类误差。
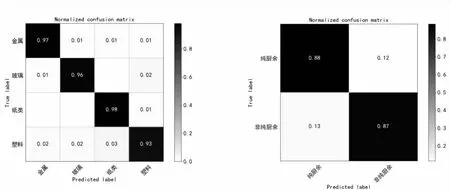
(a)单一背景(flat) (b)复杂背景(complex)图4 模型混淆矩阵
图4(a)中可以发现纸类图像数据分类准确率最高,达到了98%,而塑料类的图像数据分类误差相对较大,这是由于塑料类的图像数据种类较多且复杂,该类数据准确率相对较低,这也将是下一阶段需要重点解决的问题。图4(b)中模型对纯厨余垃圾分类准确率较高,在非纯厨余垃圾分类错误样例中发现包含的杂质复杂多样,且部分杂质体积较小,颜色与厨余垃圾相似,例如餐巾纸、塑料袋等,这也是图像分类技术面临的重点难点问题。
对比分类结果可以发现,在单一背景图像数据下,模型的分类准确率更高,同时损失值和准确率的变化能更快收敛并且能稳定地维持最优结果。在复杂背景下,图像分类模型对小目标物体的特征提取能力较低,存在干扰特征,影响模型的学习效果,具有更大的挑战性。
4 结束语
面向单一背景和复杂背景两种不同场景下的垃圾图像数据,利用迁移学习的策略进行模型训练与学习,实现了在缺乏大规模标注数据的可回收物图像准确分类和厨余垃圾杂质检测,在单一背景下模型分类准确率高达96.19%,验证了迁移模型的有效性。在复杂背景下,模型的分类准确率可以达到87.42%,这表明模型对于复杂背景中的杂质有较好的特征提取能力,以及对图像的背景与前景有较好的区分能力。其中,模型对体积较小存在干扰特征的杂质检测性能相对较低,对于图像分类模型具有挑战性,也将是下一阶段需要重点解决的问题。同时,该文通过数据增强的方法降低了图像成像要求,进一步提高了模型的鲁棒性和泛化能力。
