基于模糊聚类和Slope One填充的推荐算法
2022-05-30李磊
李磊
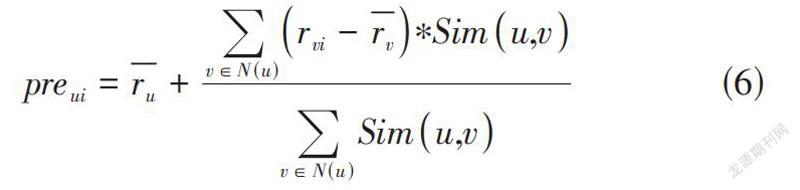


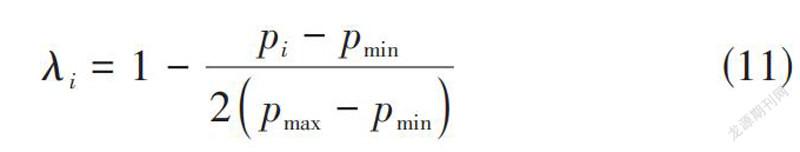
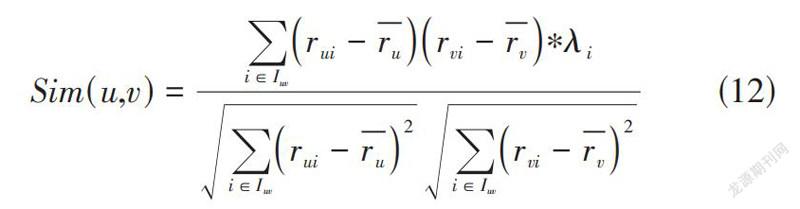
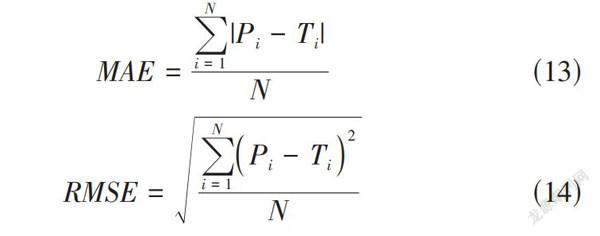

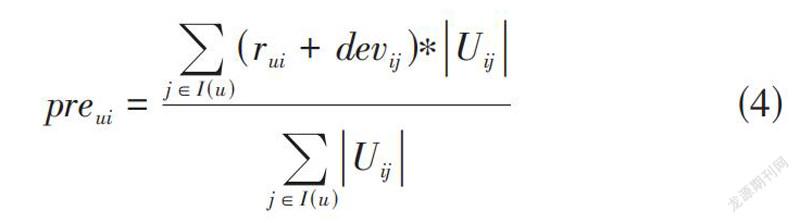
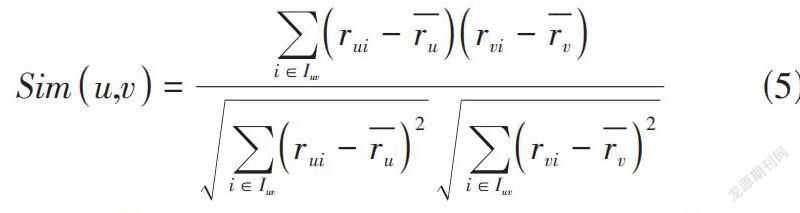
摘要:传统的推荐算法受限于其数据密度低,矩阵規模大进而导致的计算复杂、实时性差且推荐精度低。针对这一问题,设计了一种结合模糊聚类和Slope One填充的推荐方法。算法根据用户的特征进行模糊聚类,利用加权Slope One算法填充c个规模较小的用户-项目矩阵中的缺失数据,并通过改进的相似度计算方法计算出用户间的相似度得出最近邻结果集。仿真对比实验表明,设计的算法对比传统的推荐算法在精度上有着很大提升,同时能缓解数据稀疏性,提升推荐质量。
关键词:协同过滤;模糊聚类;Slope One;相似度
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)10-0068-03
1 引言
由于信息网络的高速增长,世界各地的数据量也正疯狂增加,据有关组织报告称,估计到2025年,世界各地的数据量将会达到惊人的163ZB,是2016年16.1ZB的十倍[1]。面对如此庞大的数据量,我们已然陷入了“信息过载”的时代[2]。若是能够使用一种方法能够挖掘出用户的历史行为记录并分析计算出用户潜在的兴趣,主动地推荐感兴趣的项目给用户,则大概率可避免用户大海捞针似地获取数据。推荐系统应运而生。
推荐系统的质量好坏完全依赖于为该系统设计的推荐算法,作为最经久不衰最为经典的一种推荐算法——协同过滤算法,为缓解大数据环境下存在的“信息过载”问题做出了巨大的贡献。通过构建用户-项目矩阵,通过分析用户行为找出相似的用户,然后根据相似用户的行为做出推荐。但是可扩展性差、数据密度低导致稀疏性高从始至终都是亟须解决的问题。究其原因是用户和项目之间的不对称性,导致大量的项目仅仅被极少比例的用户所标注[3]。
为了缓解由于数据密度低,矩阵规模庞大进而导致推荐精度不高、可扩展性差这一系列问题。论文设计了一种基于模糊聚类和Slope One填充的推荐算法。首先使用模糊c均值算法(FCM)按照用户的特征进行聚类,得到c个聚类中心进而构建c个用户项目矩阵,然后使用加权Slope One算法计算出的结果值回填矩阵中的缺失项,最后和协同过滤算法相融合得出预测评分。实验表明,论文和设计出的算法在各项指标中均优于传统的推荐算法。
2 相关研究
2.1 协同过滤算法
GlodBerg等人[4]在20世纪90年代开创性地提出了协同过滤算法。其基本假设是,“物理类聚,人以群分”。协同过滤技术主要包含以下三个步骤:
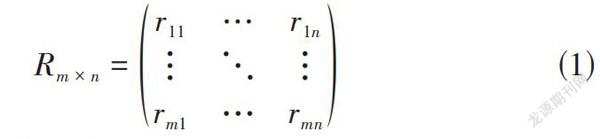
1) 建立用户-项目矩阵。通过日志或其他方式对用户的操作行为,包括显示反馈或是隐式反馈进行收集,得到用户-项目评分矩阵[Rm×n]如公式(1)所示。
[Rm×n=r11…r1n⋮⋱⋮rm1…rmn] (1)
2) 找到用户最近邻集合。描述两个样本特征的相似程度需要使用到相似性计算方法。构建相似度矩阵随后从中提取出与目标样本相似程度最高的前k个样本作为最近邻集合。
3) 产生推荐。通过近邻结果集合加权得出预测评分结果进而产生排序Top-N推荐列表给用户进行推荐。
2.2 Slope One算法
Slope One算法[5]其核心思想是利用一种线性回归模型来对矩阵中存在的缺失值进行预测。使用公式(2) 计算得出各个项目评分差均值[devij],然后使用公式(3) 进行目标用户对其项目的评分预测。
[devij=u∈N(i)⋂N(j)rui-rujN(i)⋂N(j)] (2)
[pui=i∈N(u)|N(i)⋂N(j)|∗ruj+deviji∈N(u)N(i)⋂N(j)] (3)
[rui]代表的是项目i被用户u所标注并给出了评分, [N(i)⋂N(j)] 代表的是针对项目i和j均存在共同标注行为的用户集合。
2.3 Weighted Slope One算法
Slope One算法简单高效可扩展性强。但是未考虑共同评分个数多的要比共同评分个数少的更加可靠,因此在进行评分预测阶段时应当赋予更高的权重比例[6]。加权Slope One算法如公式(4) 所示:
[preui=j∈I(u)(rui+devij)∗Uijj∈I(u)Uij] (4)
2.4 相似性计算方法
相似度计算是产生推荐的重要步骤之一,论文选取皮尔逊相关系数作为衡量相似与否的标准,如公式(5) 所示。
[Simu,v=i∈Iuvrui-rurvi-rvi∈Iuvrui-ru2i∈Iuvrvi-rv2] (5)
其中,[Simu,v]的含义是两个样本u和v之间的相似度, [ru]和[rv]分别表示为各自对它们有过评分行为的项目的平均评分值。
2.5 评分生成
通过相似邻居集合以及其评分信息联合计算得出最终的预测评分,如公式(6) 所示:
[preui=ru+v∈N(u)rvi-rv∗Simu,vv∈N(u)Simu,v] (6)
[preui]表示的是用户u对项目i计算得出的预测评分值, [N(u)]含义为对目标用户u所挑选出的最近邻用户集。
3 本文算法
3.1 用户模糊聚类
在传统的聚类算法中,每个目标样本都只能被划分都一个固定的类别中去,没有达到一种灵活的状态。模糊聚类通过引入隶属度这一特性提供了更有弹性更加灵活的聚类效果[7],根据隶属度的权重将一个目标样本划分到不同的类簇中去。其中最被广泛应用的是模糊c-均值聚类(FCM)算法[8]。
在FCM算法中,将用户特征属性映射到n维向量u上,[u=r1,r2,…rn],将数据集[X=x1,x2,…, xn]中各个样本点根据自身的特征属性按照相应的隶属度模糊划分到不同的聚类簇中心,不断迭代前后两次的目标函数之差直到比最初设置的最小值小或是已经达到了最大的系统设置的迭代次数则终止,此时即可获得相对最佳的聚类效果[9]。原问题可以看作求解拉格朗日条件极值问题,其目标损失函数为公式(7) 所示,其约束条件为从各个样本点出发最终到达所有的聚类中心必须满足隶属度权重总和为1,如公式(8) 所示。
[J(U,ci)=i=1cj=1nuixjmxj-ci] (7)
[i=1cuixj=1,∀j=1,2,…,n] (8)
[uixj]表示的含义是对于样本集中的某个样本[xj]其隶属于第i个聚类中心的程度,m为加权指数,通常取2时效果最好。[xj-ci]代表的是样本点[xj]到某一个固定的聚类中心[ci]之间第二范数,也被称作欧几里得距离。为了使得目标损失函数(7) 能够取得极小值,需要构造并求解拉格朗日函数,对[ci]与[uixj]求偏导数即可得到相应的必要条件使得原目标函数能够取得极小值,如公式(9) 、公式(10) 所示。
[ci=j=1nuixjmxjj=1nuixjm] (9)
[uixj=i=1kxj-cixj-ck2m-1-1] (10)
FCM聚类算法步骤流程如下所示:
输入:数据集样本和聚类个数c;
输出:使得公式(7) 取得极小值的聚类中心集合[ci]。
Step1:指定聚类个数c,初始化加权指数m;
Step2:使用随机函数生成各个聚类中心;
Step3:求解出每个样本点到达各个聚类簇中心的隶属度,并构建出相应的隶属度矩阵;
Step4:计算迭代得出各个簇的聚类中心;
Step5:不断迭代前后两次的目标函数之差直到比最初设置的最小值小或是已经达到了最大的迭代次数则终止,否则返回Step3;
Step6:得到聚类中心集合[ci]。
3.2 改进的相似度计算方法
针对大多数行业中,如电商、影视等,越是热门的项目越容易被曝光使得更多的人购买或观看,相比之下,越是曝光度不高的项目越难被用户所发现。这种现象也被称作“马太效应”。所以引入项目流行度因子[λ]以此来降低热门商品的所占的权重。
[λi=1-pi-pmin2pmax-pmin] (11)
[pi]代表項目i的流行度,反映出的是项目i被标注过的次数,[pmax]是所有项目中最大标注数目,[pmin]为最小标注数目。[λi]的取值范围为[0,1]区间上。则改进后的相似度计算方法为:
[Sim(u,v)=i∈Iuvrui-rurvi-rv∗λii∈Iuvrui-ru2i∈Iuvrvi-rv2] (12)
3.3 基于模糊聚类和Slope One填充的推荐算法
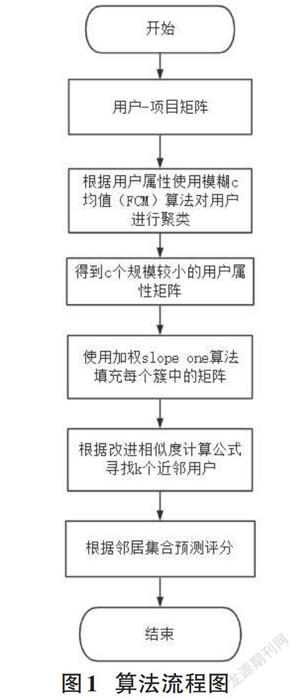
为了缓解协同过滤算法中一直以来存在的数据密度低致使在相似度计算时,未能抓到最相似的近邻集合进而导致推荐精度不高的问题,论文使用模糊聚类方法根据用户特征进行聚类,也即等价于对原始的用户-项目矩阵进行降维,降维后可得到c(c为聚类个数) 个小规模的矩阵。利用加权Slope One算法为每个矩阵进行属性填充,根据聚类的特性这就会使得在同一个聚类簇下的用户相似程度显然比非同一簇下的相似度要高。所以Slope One算法在填充矩阵时会尽可能避免到不相似用户的干扰,从而可以提升推荐的精度,论文的算法流程图如图1。
算法执行步骤如下:
输入:数据集,聚类数c,最近邻数量k;
输出:待预测用户对某个项目的最终评分预测值。
Step1:加载数据集,构建用户-评分矩阵D,使用公式(7) 、公式(8) 、公式(9) 、公式(10) 根据用户属性特征进行聚类,形成c个聚类簇,并构建c个规模较小的用户-项目评分矩阵;
Step2:在这些小规模的用户-项目矩阵当中,使用公式(2)得出[devij];
Step3:在得到[devij]的基础上通过公式(4)计算出[preui];
Step4:[preui]的值回填矩阵中空缺的数据,得到c个新的规模较小且稠密用户-项目评分矩阵[Dβ];
Step5:在稠密的矩阵[Dβ]上使用公式(12) 构建出相似度矩阵,挑选出最相近的k个用户;
Step6:在测试集中根据上一步骤得出选出目标用户的最近邻集合,借此来预测目标用户对某个项目的评分;
Step7:通过公式(6) 得到最终的评分预测结果。
4 实验结果分析
4.1 实验数据
实验选取由GroupLens研究小组发布的电影评分MovieLens数据集。这是个性化推荐算法中最为经典的数据集,选取ml-100k来验证论文算法。数据集的评分范围为1~5中的整数,评分的高低代表着用户的喜欢或是不喜欢程度。
4.2 评测指标
论文选取平均绝对误差(Mean Absolute Error,MAE) 、均方根误差(Root Mean Square Error,RMSE)作为实验的评测指标。MAE和RMSE是在推荐系统中流传最为经典、使用频率最高的评估指标,得出的结果越小则可以充分反映出算法的误差小准确率高。
[MAE=i=1N|Pi-Ti|N] (13)
[RMSE=i=1NPi-Ti2N] (14)
其中[Pi]是论文提出算法得出的预测评分,[Ti]是样本真实打分,N是在测试集中待预测样本的总数。
4.3 实验设计与结果分析
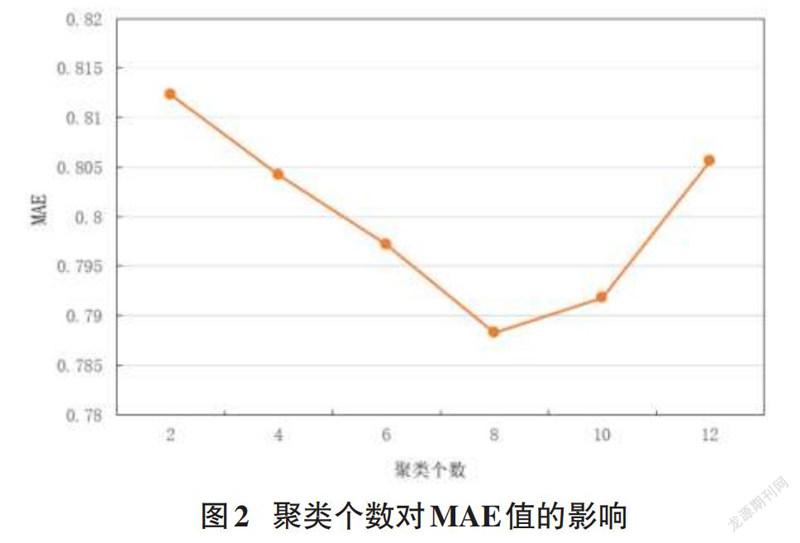
实验一:验证聚类个数对算法实验结果的影响并根据实验结果挑选取最佳聚类个数。
设定聚类个数为[2,12],每组的间隔为2进行了多组实验,从图中能够明显看出当聚类个数达到8时,误差最小效果最好。
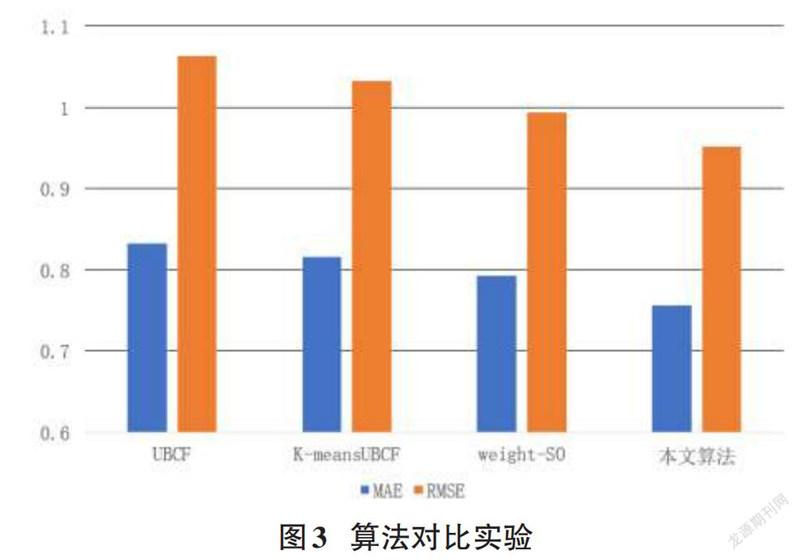
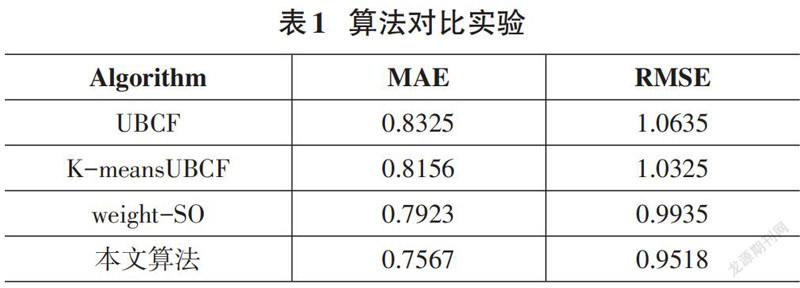
实验二:对比传统的基于用户的协同过滤算法(UBCF) 、基于加权Slope One算法(weight-SO) 、基于k-means聚类的协同过滤算法。论文选取近邻个数为60,聚类簇数为8,实验结果如图3和表1所示:
从图表中能够清晰地看到,论文设计的算法的误差均小于其余算法,MAE值对比UBCF、K-meansUBCF、weight-SO算法分别降低了大约有7.58%、5.89%、3.56%,RMSE值降低了大约11.17%、8.07%、4.17%。相比于UBCF算法由于其数据密度低稀疏性高导致近邻选择不准确影响了推荐结果。相比于WSO算法,由于其未考虑用户之间的相似度,是在全局范围内进行预测填充,影响了其推荐的精度。论文提出的算法不仅考虑到
了项目的流行性,优化了相似度的计算方法,而且考虑到数据稀疏性带来的负面影响,从而提升了推荐精度。
5 结束语
数据稀疏,可扩展性一直以来都是传统推荐算法面临的问题,针对问题出发,在深入理解模糊聚类和Slope One算法理论模型的基础上,设计了基于模糊聚类和Slope One填充的推荐算法,根据实验结果可以分析出设计的算法能够缓解由于数据密度低,稀疏性高导致的推荐精度较低的问题,由于聚类都是离线完成的,在进行评分预测时不需要遍历整个用户-评分矩阵,只需在属于的簇中计算相似度即可,减少了计算时间,可扩展性强。 在以后进一步研究当中将会考虑引入更多的辅助信息,如用户偏好、兴趣度、信任度、长短期兴趣等模型并融入算法中并针对FCM算法其目标函数是一种非凸函数导致其难以取得全局的最优解 ,考虑引入智能优化方法进一步提升推荐质量。
参考文献:
[1] 李悦,谢珺,侯文丽,等.融合用户偏好优化聚类的协同过滤推荐算法[J].郑州大学学报(理学版),2020,52(2):29-35.
[2] 王岩,张杰,许合利.结合用户兴趣和改进的协同过滤推荐算法[J].小型微型计算机系统,2020,41(8):1665-1669.
[3] 张艳菊,陆畅.数据缺失下的IFCM-Slope One协同过滤推荐算法[J].统计与决策,2020,36(9):185-188.
[4] Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[5] Lemire D,Maclachlan A.Slope one predictors for online rating based collaborative filtering[C]∥Proceedings of the 2005 SIAM Data Mining Conference,2005:471-480.
[6] 馬浩,黄俊,孔麟,等.动态k近邻辅助多权值Slope One算法[J].计算机工程与设计,2020,41(11):3072-3077.
[7] Manochandar S,Punniyamoorthy M.A new user similarity measure in a new prediction model for collaborative filtering[J].Applied Intelligence,2021,51(1):586-615.
[8] 贾俊杰,张玉超.基于用户模糊聚类的综合信任推荐算法[J].计算机工程,2021,47(6):60-67.
[9] 李建军,付佳,杨玉,等.基于混沌粒子群聚类优化的协同过滤推荐[J].计算机工程与设计,2021,42(8):2173-2179.
【通联编辑:谢媛媛】
