基于可解释性机器学习算法的开颅手术患者重症监护室住院时间预测模型
2022-05-28王绍博王琪琪焦增涛刘有军于荣国
王绍博,王琪琪,焦增涛,刘有军,于荣国
1.北京工业大学 环境与生命学部,北京 100124;2.医渡云(北京)科技有限公司,北京 100191;3.福建省立医院 外科重症医学科,福建 福州 350001
引言
开颅手术是一种神经外科疾病治疗方法,包括脑肿瘤摘除术、血肿清除术、脑挫裂伤去骨瓣减压术等,由于这种手术的难度大、医疗费用高且术后并发症较多,建议开颅手术患者进入重症加强护理病房(Intensive Care Unit,ICU)进行监护,尽可能降低患者各种风险[1]。ICU内住院时间(Length of ICU Stay,LoICUS)是一种常见的作为护理质量与资源使用的衡量指标[2]。对于大部分患者而言,ICU内的医疗费用是高额支出,而随着患者LoICUS的增长,患者在承受痛苦的同时,还需承担高额医疗费用,会造成较大医疗负担。从人员成本和资源管理的角度来看,预测LoICUS是否过长并提供相应的干预和决策建议具有重要价值[3]。部分研究探讨了护理路径对重症颅脑损伤患者LoICUS的影响,并发现通过实施干预或改善临床护理路径,可缩短患者LoICUS,改善患者病情[4-5]。
预测模型(Predictive Model,PM)作为一种重要的风险评估与知识发现工具,已有相当数量的学者对LoICUS进行了研究。2017年,有学者基于神经网络算法建立了LoICUS是否大于5 d的模型,准确率为80%[6]。2019年,基于线性回归与长短期记忆网络算法,建立的LoICUS是否大于7 d的模型准确率为84%[7]。2021年,通过对比线性回归、随机森林(Random Forest,RF)模型、支持向量机等6种算法建立的LoICUS二分类模型,通过患者LoICUS的中位数(2.64 d)将其分为两类,认为RF模型效果较好(准确率为65%)[8]。
本文的研究对象为需要进行开颅手术并进入ICU住院的患者,有研究发现因脑肿瘤而开颅的患者LoICUS不超过1 d[9],还有研究表明LoICUS的中位数在2~6.9 d[10],基于此本研究将开颅手术患者LoICUS较长定义为患者LoICUS≥8 d。
本研究基于开颅手术患者电子病历,通过自身可解释性较强的逻辑回归(Logistic Regress,LR)模型、RF模型以及梯度下降决策树(Gradient Boosting Decision Tree,GBDT)模型三种机器学习算法建立PM,对此类患者的LoICUS进行分类预测,并通过对其进行评估挑选效果较好的模型并从中挖掘影响开颅手术患者LoICUS较长的风险因素,为ICU内临床医生提供辅助性决策或干预建议的相关参考,尽可能减少患者高额医疗费用支出、减轻医疗负担。
1 材料与方法
1.1 数据来源
本研究选取在福建省立医院外科ICU专病库2005年3月至2018年9月接受过开颅手术的患者836例,其中男性493名,女性343名,平均入院年龄为55岁,ICU内住院天数的平均数为41.79 d、中位数为12.61 d、众数为0.94 d,69名患者的结局为死亡。上述数据通过医渡云(北京)科技有限公司的智能大数据平台导出,不包含任何患者的个案数据,且通过医院伦理委员会认可。
本研究将此类患者的各项临床检验指标作为数据源。患者的纳入规则为年龄≥18岁,经历过开颅手术(包括脑挫裂伤去骨瓣减压术、血肿清除术、脑膜瘤摘除术、垂体瘤摘除术、动脉瘤出血介入术)需进入ICU监护治疗,且至少有一次完整的ICU内相关检查记录的患者。患者的排除规则为LoICUS不足24 h或LoICUS为空值或患者的院内结局为死亡。对于患者院内死亡的规定为患者入院24 h后,“死亡记录”登记为“死亡”的,或“出院情况”为“自动出院”的。经过上述患者纳排规则后,最终纳入患者病例为677例。
1.2 方法
本研究首先对患者数据进行预处理,然后对患者特征进行统计学分析,建立两种患者特征集。通过三种机器学习算法对两种特征集建立PM,根据模型评估方法挑选最优模型,并对最优模型进行解释分析。
1.2.1 数据预处理
经过患者纳排规则以及具有丰富临床经验与知识的福建省立医院外科ICU主任确认,最终本研究筛选得到67个字段作为构建PM的候选变量,这些变量包括患者的人口学信息(如年龄、性别等)4个、既往病史(如高血压、糖尿病等)7个、脑损伤诱因(如脑积水、癫痫等)5个、感染源(如肺部、泌尿系等)4个、生命体征(如舒张压、收缩压等)6个、格拉斯哥昏迷指数(Glasgow Coma Scale,GCS)评分、血肿性质(如蛛网膜下、硬膜下等)4个、实验室检查(如血红蛋白、血小板计数等)31个以及治疗指标(如手术时间、麻醉类型等)5个,并去除缺失率高于30%的临床变量。
本研究将包含67个字段的候选特征集按照获取时间分为开颅手术前特征集与开颅手术后特征集,并将特征集中的字段分为静态指标与动态指标。静态指标为只有唯一取值的变量,如患者入院年龄、性别等;动态指标为随时间变化的临床变量,如患者的血压、脉搏等,本研究提取患者在ICU住院期间此类变量的首次值、最大值与最小值。
对于候选特征集中的离散型变量,缺失部分使用该变量中类别频率最高的一类进行填充(即使用众数进行填充);对于连续型变量,缺失部分则使用该项的均值进行填充并进行归一化处理。对于纳入的所有连续型特征F={F1,F2,F3,…,Fi,……,Fn},i[1,n],其中每个特征Fi所对应的特征集记为XFi={XFi1,XFi2,XFi3,…,XFij,……,XFim},j[1,m],将XFi中的每个值XFij减去XFi中的最小值(minXFi),并除以最大值(maxXFi)与最小值的差,得到X'Fij,如式(1)所示,X'Fij为归一化结果,其范围为0~1。

首先将上述经填充与归一化处理后的候选特征集结合具有统计学意义的(P<0.05)筛选结果形成医生挑选特征集(医学)和医生与统计学共同挑选特征集(医学+统计学),然后将上述两种特征集均划分为训练集与测试集,其比例均为7:3(训练集473,测试集204)。训练集用于进行PM的训练与参数调整,测试集用于进行模型效果的评估。验证模型参数的方法为10折交叉验证,即训练集数据样本被随机分为10份子样本集,其中1份为验证集,9份为训练集。
1.2.2 机器学习方法
本研究基于机器学习技术进行PM的构建,分别使用LR、RF以及GBDT进行建模。机器学习中存在一些黑盒的模型,如支持向量机、神经网络等,它们具有极高的特征抽象和非线性拟合能力,但是人类对此类模型的拟合过程无法理解,特别是在医学研究领域,即使神经网络的效果优于传统方法,由于其不可解释性依旧使医学工作者无法完全信任模型的价值。本研究所选模型的优势在于可解释性较强,并且大部分模型可以建立特征之间的关系,即自身可解释。
(1)逻辑回归。LR是线性回归模型的扩展,可用于预测二分类问题中每一类别的概率。由于LR具有应用广泛、可解释性强的优点,因此LR在医学PM中得到广泛的应用[11]。但是LR模型作为一种线性模型,其缺点也显而易见,即LR仅可对数据进行线性拟合,并且无法体现特征之间的关联。
本研究通过LR的95%置信区间比值比(Odds Ratio,OR)对其进行解释。比值(odds)表示某件事发生与不发生之比,计算公式如式(2)所示;OR表示某个特征xj增加一个单位前后odds的比值,如式(3)所示,其中βj为特征xj对应的系数,特征xj对应的OR值为exp(βj)。
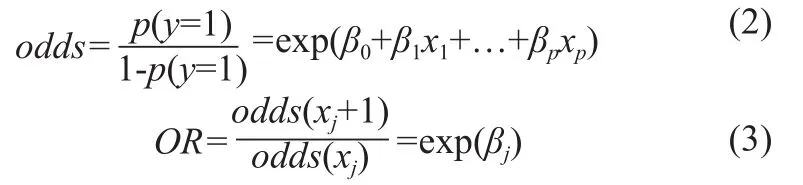
一般OR值为1的特征,表示该特征对结局无明显影响;OR值>1的特征表示该特征对结局影响较大(正相关);OR值<1的特征表示该特征是一个保护因素,即与结果呈负相关。另外,置信区间的上下限最好均>1或者均<1,例如:若95%置信区间为0.9~1.1,则不符合要求,即这种跨越1的区间可能会出现该特征同时与结局呈正相关与负相关的可能性。本研究引入假设检验的方法,对OR值进行假设检验,计算其P值,若P<0.05,则本研究认为该特征的OR值具有统计学意义。本研究基于python语言(3.7.3版本)中的statsmodels模块进行建模。
(2)随机森林。RF是集成学习中bagging框架的扩展变体[12],通过生成多个决策树并引入随机特征选择,从而完成分类任务。这种方法具有较强的解释性,并且建立了特征之间的关联。本研究通过RF模型的特征重要性以及风险树的方法对其进行解释。每个特征的重要性通过该特征及子节点的基尼系数(Gini)得到,Gini值计算公式如式(4)所示,其中t为类别,pi为类别i的样本占总样本的比例。特征重要性计算公式如式(5)所示,N为样本总数,Nt为当前节点的样本数,NtR(L)是右(左)子节点的样本数,Cini_R(L)为右(左)子节点的Cini值。本研究基于python语言(3.7.3版本)中的scikit-learn模块进行建模。
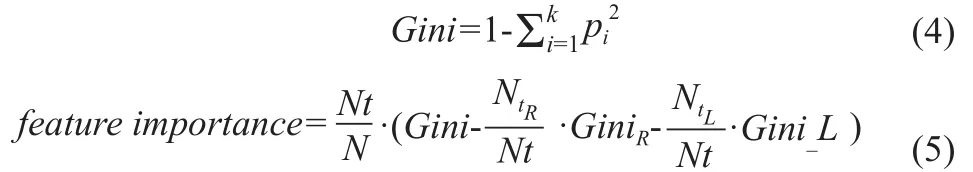
(3)梯度下降树。在机器学习领域,GBDT是一种对真实分布拟合效果较好的方法[13],通过boosting的理念,用多棵分类回归树模型的训练结果乘以其所对应的权重值集成样本预测结果,这些树不是独立的,而是后面的树在前面的基础上学习误差,即GBDT将弱分类器组合为强分类器,所有树的结果加起来是预测得到的结果,通过梯度下降的方法优化目标函数。该算法可建立特征间的关联,并具备自身可解释性。
本研究通过特征重要性以及风险树的方法对此模型进行解释。特征j的全局重要性通过特征j在GBDT多棵树中的重要性的均值衡量,见式(6),其中M为树的数量。特征j在单棵树中的重要性计算公式如式(7)所示,其中L为树m的叶子节点数量,νt为与节点t相关的特征,为节点t分裂后平方损失值,计算公式如式(8)所示,其中friedman_mse为节点的分割准则,其计算公式如式(9)所示,wL(R)表示左(右)子节点中样本权重加和,其中表示左(右)子节点中样本目标y的加权均值。基于python 语言(3.7.3版本)中的scikit-learn模块进行建模。
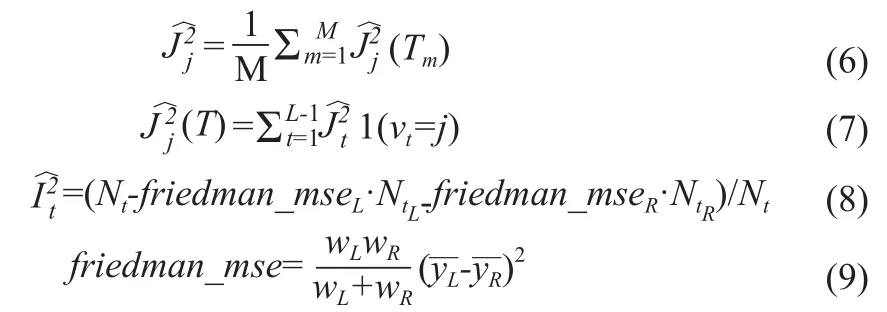
1.2.3 模型评估方法
对于模型的评估方法,首先通过混淆矩阵计算出真阳性例数(True Positive,TP)、真阴性例数(True Negative,TN)、假阳性例数(False Positive,FP)与假阴性例数(False Negative,FN)。其次,根据上述4个指标计算出PM的准确率、精确率、召回率(Recall)、F1值(F1)以及受试者工作特征(Receiver Operating Characteristic,ROC)曲线下的面积(Area Under the Curve,AUC),并对模型的预测性能进行评估[14]。
ROC曲线由真阳率(True Positive Rate,TPR)和假阳率(False Positive Rate,FPR)绘制而成,ROC曲线的AUC值越高表明模型分类性能越好。对于模型的校准方法,本研究通过绘制校准曲线,并且计算模型的Brier值来表示模型的校准程度。Brier值是对风险和实际结果之间的均方差的度量,其取值范围为0~1,Brier值越小则模型校准程度越高[15-16]。
1.3 统计学分析
对于离散型特征,本研究使用类别n(%)表示,并通过χ2检验比较组间差异性。对于连续型特征,首先判断该组数据是否符合正态分布,若符合正态分布,则使用±s表示,若不符合正态分布,则使用上分位数、中位数和下分位数[median (Q1,Q3)]表示;对于两组样本均符合正态分布的特征使用t检验,否则使用Wilcoxon检验判断组间差异性。若上述假设检验P<0.05则为有显著性统计学差异。本研究统计学分析使用Python语言(3.7.3版本)中Scipy模块实现。
2 结果
2.1 统计结果
本研究对677名患者进行统计分析的结果为:LoICUS≥8 d的患者数量为392人(57.90%),患者队列的平均年龄为56岁,男女比例为407:270,术前特征包括年龄、性别、是否高血压等21个特征,术后特征包括手术中麻醉类型、GCS值、舒张压、收缩压等123个特征(其中包括部分动态指标的首次值、最大值或最小值)等。
根据统计结果,在开颅手术前获取的字段中,患者LoICUS较长(≥8 d)具有统计学意义的特征为:入院年龄(P=0.037)、是否高血压(P=0.022)、脑损伤诱因为血管类疾病(P<0.001)等;开颅手术后获取的字段具有统计学意义的特征为:是否气管切开(P<0.001)、体温最大值(P<0.001)、高密度脂蛋白胆固醇最小值(P<0.001)、是否鼻饲(P<0.001)等。
2.2 分类器性能评估
2.2.1 测试集结果
将两种特征集(医学、医学+统计学)分别作为三种PM的输入,并在训练集上进行训练,生成6种开颅手术患者LoICUS是否过长的PM。随后在测试集上进行模型验证,并通过准确率、精准率、Recall、F1、AUC以及Brier六种评价指标分别对六种模型在测试集中的效果进行评估,结果如表1所示。
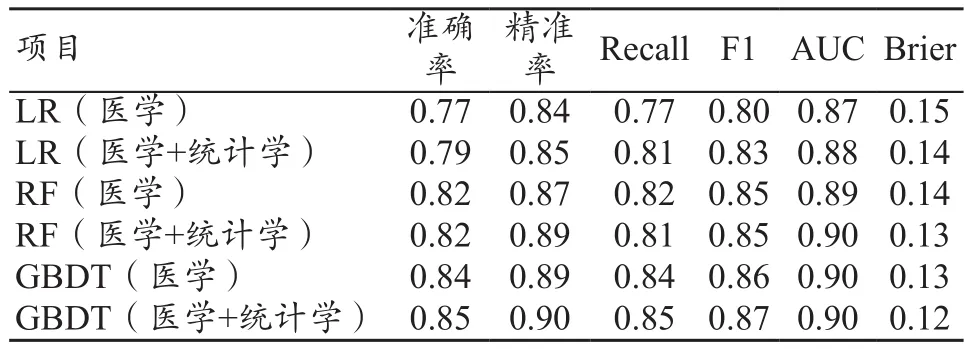
表1 六种模型在测试集上的评估结果
根据三种机器学习方法建立的六种PM在测试集的表现为:基于医学+统计学特征集的PM效果普遍优于基于医学特征集的PM。首先在模型准确率方面,GBDT(医学+统计学)效果最好(准确率为0.85);其次在精确率、召回率以及F1值方面,GBDT(医学+统计学)模型的精确率(0.90)、召回率(0.85)和F1值(0.87)均高于其他模型;RF(医学+统计学)、GBDT(医学)模型的AUC值均为0.90,与GBDT(医学+统计学)相同;从模型拟合评判指标Brier值的角度评判,GBDT(医学+统计学)模型的效果最优(0.12)。
2.2.2 测试集评估曲线
本研究测试集评估曲线包括ROC曲线、校准曲线以及P-R曲线。
(1)ROC曲线。根据各模型结果在不同阈值下的TPR与FPR绘制ROC曲线,其中横轴为FPR、纵轴为TPR,ROC曲线下的面积为AUC,作为模型评估指标中的一种(图1)。基于(医学)特征集的三种模型ROC曲线如图1a所示;基于(医学+统计学)特征集的三种模型ROC曲线如图1b所示。
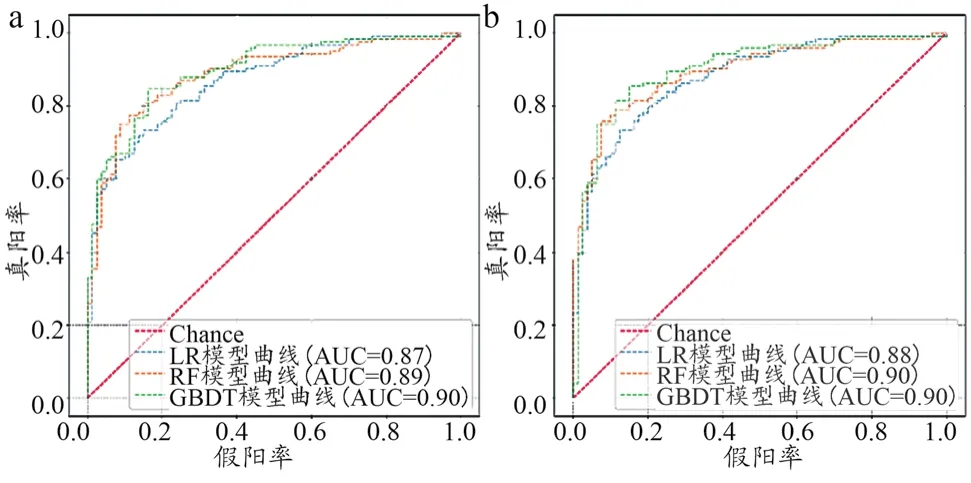
图1 不同阈值下TPR与FPR绘制的ROC曲线
通过ROC曲线可知:LR(医学)模型AUC为0.87,RF(医学)模型AUC为0.89,GBDT(医学)模型AUC为0.90;LR(医学+统计学)模型AUC为0.88,RF(医学+统计学)模型AUC为0.90,GBDT(医学+统计学)模型AUC为0.90。
(2)校准曲线。使用分桶法观察分类模型的预测概率是否接近真实情况,从而绘制出不同特征筛选条件与不同场景下的模型校准曲线,理想情况下校准曲线是一条对角线。各模型的不同情况下校准曲线如图2所示。

图2 各模型的不同情况下校准曲线
通过校准曲线可知:LR(医学+统计学)(Brier值为0.14)与GBDT(医学+统计学)(Brier值为0.12)模型校准效果较好,其中GBDT(医学+统计学)模型的Brier值优于其他模型。
(3)P-R曲线。根据各模型结果不同阈值下的精确率(Precision)与召回率(Recall)绘制P-R曲线,横轴为Recall值、纵轴为精准率值,P-R曲线下的面积也可作为评判标准。相比于ROC曲线,P-R曲线更加侧重于关注样本中的正例,在类别不平衡问题中,ROC曲线会兼顾正负样本,因此通常会给出较为乐观的效果,但对于正样本的预测情况P-R曲线更为适宜。各模型不同情景下P-R曲线如图3所示。
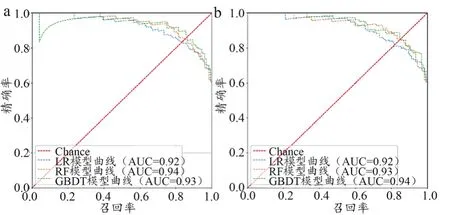
图3 各模型不同情景下的P-R曲线
通过比较P-R曲线及曲线下面积可知:RF(医学)模型以及GBDT(医学+统计学)模型P-R曲线下面积较大(均为 0.94)。
通过上述分析,在特征选择层面,通过对比PM的结果,本研究认为经过医生和统计学共同筛选特征的方法普遍优于仅经过医生筛选特征的方法。对于PM评估指标,本研究首先考虑模型在测试集中的准确率、AUC以及F1值(其中F1值是由精确率与召回率共同决定),对于模型的校准程度,除了Brier值外,本研究还需通过校准曲线来评估模型的校准程度。经过综合考虑,在预测开颅手术患者LoICUS是否过长(≥8 d)的场景中,本研究认为GBDT(医学+统计学)模型表现最好,优于其他模型,故本研究选择该模型进行分析。
2.3 模型可解释性分析
本研究选择GBDT(医学+统计学)模型构建开颅手术患者LoICUS是否过长的PM。由于GBDT的自身可解释性,因此通过特征重要性以及风险树对模型进行解释。
2.3.1 特征重要性
本研究选取了重要性最高的前20个特征(图4)。可以发现在此场景中,患者术后特征对结局的影响普遍高于术前特征。在这20个重要特征中,排在前三名的特征分别为是否气管切开(is_tracheotomy)、高密度脂蛋白胆固醇最小值(min_HDL_C)以及是否鼻饲(is_nasal_feeding),其次依次为直接胆红素最小值(min_DBIL)、体温最大值(max_temperature)、降钙素原最小值(min_PCT)、渗透压首次值(first_OSM)、天门冬氨酸氨基转移酶最大值(max_AST)等。术前特征只有是否诊断为血管类疾病(diagnosis_blood_vessel),并且其特征重要性远低于上述术后特征。
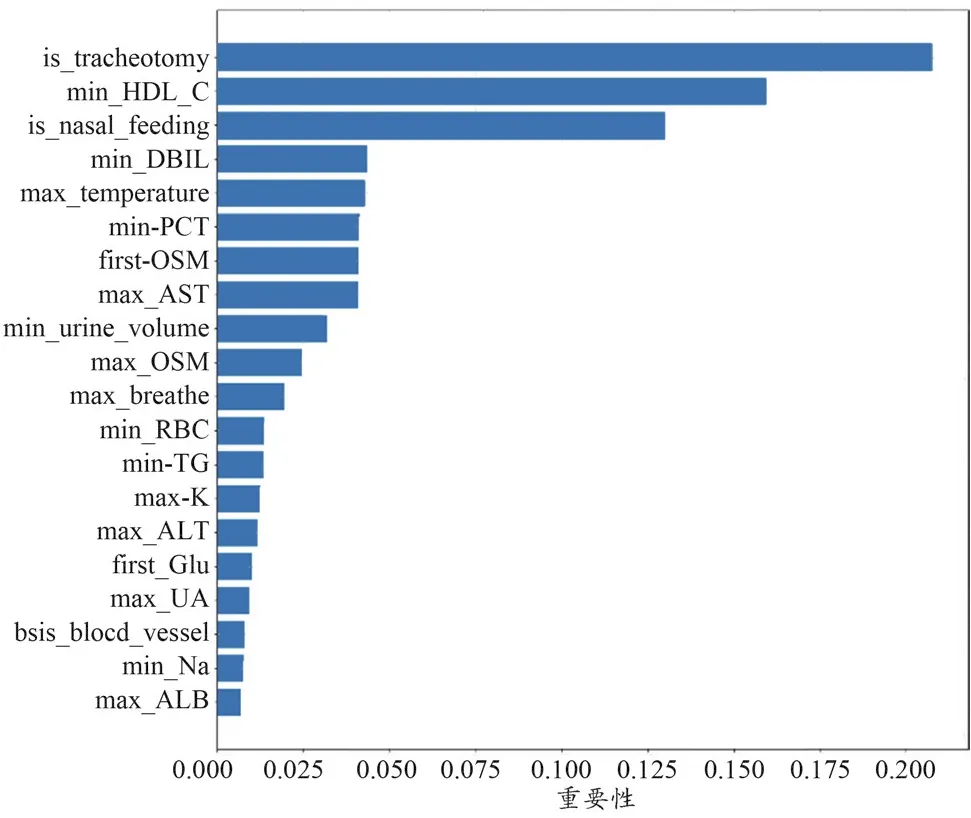
图4 GBDT(医学+统计学)模型特征重要性
2.3.2 风险树
本研究通过风险树的形式对开颅手术患者LoICUS是否过长的GBDT PM决策过程进行解释。如图5所示,对于训练集数据中的473名开颅手术患者:模型首先通过特征“是否鼻饲”将患者进行划分;其次,对鼻饲的患者(217人)的决策规则为高密度脂蛋白胆固醇最小值是否≤0.875 mmol/L,对于无须鼻饲的患者(256人)的决策规则为是否气管切开;其次,对于高密度脂蛋白胆固醇最小值≤0.875 mmol/L的患者(193人)的决策规则为天门冬氨酸氨基转移酶最大值是否≤43.8 U/L,对于无须气管切开的患者(218人)的决策规则为渗透压首次值是否≤281.213 mOSM/L。根据上述决策规则,如图中圆形部分所示,可得到6组患者人群(组1~6),并根据风险比例将其分为开颅手术患者LoICUS较长的高风险组(组2与组4)、中风险组(组1与组6)与低风险组(组3与组5)。组2(需要鼻饲且min_HDL_C≤0.875 mmol/L且max_AST>43.8 U/L)中患者的风险为94.35%(167/177),组4(无须鼻饲但需要气管切开)患者的风险为76.32%(29/38),组1(需要鼻饲且min_HDL_C≤0.875 mmol/L且max_AST≤43.8 U/L)患者的风险为56.25%(9/16),组6(无须鼻饲且无须气管切开且first_OSM>281.213 mOSM/L)患者的风险为51.11%(23/45),组3(需要鼻饲且min_HDL_C>0.875 mmol/L)患者的风险为33.33%(8/24),组5(无须鼻饲且无须气管切开且first_OSM≤281.213 mOSM/L)患者的风险为18.50%(32/173)。
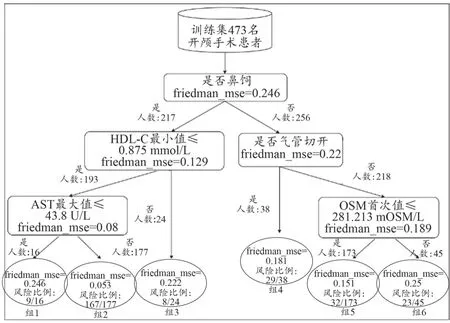
图5 开颅手术患者LoICUS超过8 d风险树
3 讨论
本研究认为基于机器学习算法的PM可用于预测开颅手术患者LoICUS是否过长(>8 d),并且模型在测试集具有较好的表现(准确率为0.85,AUC为0.90),可为福建省立医院院外科ICU医生提供一定的辅助决策建议。同领域研究还包括:Gentimis等[6]基于神经网络对LoICUS是否大于5 d的预测研究中,模型准确率约为0.80;Harutyunyan等[7]基于深度学习的方法建立了LoICUS是否>7 d的PM,并认为这种方法优于线性回归模型,AUC值为0.84;2021年,Alghatani等[8]建立了 LoICUS是否超过2.64 d的PM,他们使用了与本研究类似的模型,并认为RF效果较好(准确率为0.65)。本研究的PM在其他数据集中的表现尚未讨论,因此该模型在不同场景的有效性还需后续研究进一步验证。
通过对PM的解释,本研究从特征层面进行分析并构建风险树:对于术前特征,研究认为患者在术前诊断为血管类疾病会导致LoICUS较长;对于术后特征,研究发现影响开颅手术患者LoICUS较长的主要风险因素为气管切开、鼻饲以及ICU内检测到的高密度脂蛋白胆固醇最小值,其次为体温最大值、降钙素原最小值、天门冬氨酸氨基转移酶最大值以及直接胆红素最小值等。Scales等[17]发现,在ICU中气管切开往往用于延长机械通气时间,而机械通气患者一般在9~12 d接受气管切开,因此气管切开势必会延长LoICUS。有学者使用随机对照试验研究间接性鼻饲对ICU内患者的影响,并发现此类患者LoICUS超过21 d[18],因此需要进行鼻饲的患者LoICUS较长。有研究发现对于严重败血症患者,在ICU内高密度脂蛋白胆固醇过低与死亡率和不良的临床结果显著相关[19],但是低水平的高密度脂蛋白胆固醇对于开颅手术患者ICU内的术后情况尚不清楚。Diringer等[20]发现,在神经科ICU中体温最大值是导致患者住院时间延长的风险因素。通常情况下,开颅手术后患者降钙素原会升高[21],而低水平的降钙素原是排除合并感染的预测指标[22],而对于开颅患者的降钙素原最小值对LoICUS的影响没有明确的研究,有研究发现有40%的患者在开颅手术后伴有至少一种感染[23],因此降钙素原最小值的出现可解释为患者感染消除,感染的消除时间较长可能导致LoICUS延长。有探究根据统计学分析认为天门冬氨酸氨基转移酶是影响LoICUS的因素[24],本研究认为ICU内监测到的天门冬氨酸氨基转移酶最大值对开颅手术患者LoICUS超过8 d具有一定影响。有研究将直接胆红素用于ICU内死亡率的预测中,但是效果并不理想(AUC为0.62)[25],目前对于ICU内监测到的直接胆红素最小值对于开颅手术患者住院时间较长的影响的研究较少,因此还需后续研究进一步验证。
4 结论
本研究基于可解释性机器学习算法建立了开颅手术患者LoICUS是否超过8 d的PM,并取得了较好的预测效果(模型准确率达到0.85,AUC达到0.90)。通过对PM的分析与解释,挖掘并发现了影响LoICUS的风险因素并构建风险树,可为临床医生提供辅助性决策或干预建议,有利于缩短患者LoICUS,减少患者医疗费用支出,减轻医疗负担。
