基于遗传算法和长短记忆神经网络组合模型的加油站销量预测
2022-05-27潘诗元易万里李翔宇
潘诗元 易万里 李翔宇
(1.中国石油大学人工智能学院;2.中国人民大学统计学院;3.东北财经大学统计学院)
成品油企业实现准确的加油站销量预测可支撑企业进行准确的库存管理与配送计划编制,具有重要意义。 在成品油二次物流运输中,需要对加油站的销量进行精准预测,从而得到不同加油站的准确需求,做出精确的调度,使企业运行更加高效。 因此,加油站销量预测是成品油二次物流运输中不可或缺的部分。
传统的加油站销量预测一般处理成时间序列预测问题,但加油站销量受很多因素影响且有诸多非线性特征,使得基于时间序列理论设计的销量预测模型精度偏低。 目前的主流销量预测方法主要有周平均、线性回归、指数平滑、ARIMA、机器学习和深度学习。 由于技术的限制,现有加油站销量预测多为利用周平均值或采用时间序列模型(如指数平滑模型)进行预测。 李艳东等提出建立指数平滑模型对第2天的销量进行预测的时间序列模型,该模型目前用于一部分加油站销量预测业务,模型预测速度快但精度较低[1]。张晨和邱彤提出一种基于决策树集成模型的加油站销量预测方法,利用积累的历史销售数据和相关特征数据进行计算, 对加油站的销量进行预测,该模型由于树模型难以避免过拟合,虽然在训练集测试时精确度较高但在测试集时精度较低[2]。唐静等提出一种适应度模型,用于遗传算法参数寻优,建立了基于遗传算法的电路诊断模型参数闭环寻优框架, 并分析参数搜索算法的收敛性,模型使用启发式算法进行参数调优,对故障的识别效果会增强,误分类率降低,同理可应用于各种模型的超参数调优,增加模型的精确性[3]。在国外的能源预测研究中,Laib O等使用LSTM模型通过电力市场、 当地天气与日历3个特征学习每小时时间序列数据的长期关系,并对总电力系统电网损失进行预测[4]。 Li W和Becker D M提出深度LSTM(DLSTM)模型,该方法在预测长间隔时间序列数据集时通过叠加更多的LSTM层避免浅层神经网络架构的局限性,并应用遗传算法优化配置DLSTM的最佳架构,最后将该模型与经典模型进行对比, 发现DLSTM模型均优于其他模型[5]。Sagheer A和Kotb M使用LSTM模型预测阿尔及利亚国内不同地区的天然气消费量,先对不同地区的消费量进行聚类以减少时间序列的非平稳性,最后考虑历史因素、气象因素(如温度、风速、湿度和日照)以及经济因素(石油价格、客户数量、GDP 和天然气价格)并使用LSTM预测第2天的天然气消耗量,最后以阿尔及利亚各地天然气消费量为案例证明了该方法的有效性[6]。Tulensalo J等提出基于LSTM的深度学习方法和特征选择算法的混合模型进行电价预测,先通过基于Shapley值的方法评估特征重要性,再使用LSTM模型进行电价预测[7]。 由于销量的时间序列具有较强的非线性特征,现有的模型存在精度较低的问题。
目前,国内加油站销量预测大多使用时间序列模型(如指数平滑、ARIMA等),但在实际业务中,由于ARIMA的预测速度较慢,一般使用指数平滑模型进行预测,而预测销量曲线对于实际销量曲线会有时间上的偏移,尤其在节假日前后偏移更为明显,需要靠人工经验进行修正。 同时,时间序列模型只能进行单变量预测,对于受多个因素影响的加油站销量预测并不精确。
1 模型提出
文献[2]提出加入其他特征变量(如星期、天气及节假日等), 并使用机器学习中的树模型与集成学习的思想进行多变量销量预测,最后得到的结果中,训练集精度较高,但是测试集精确度并不理想。 究其原因,主要是用树这种分类模型做回归问题难以避免过拟合。
而深度学习领域的长短记忆神经网络(Long Short-Term Memory,LSTM) 适用于处理和预测时间序列中间隔和延迟非常长的重要事件[8]。同时,LSTM能进行多特征回归,也因为其独特的门控机制使其可自动决定记忆或遗忘哪些信息,从而避免多余特征的影响或者因部分数据噪声而造成过拟合导致训练集精度不理想的情况。由于LSTM超参数较多, 人工调参一般难以获得最优参数,于是将LSTM模型的超参数作为种群输入参数,将均方根误差作为目标函数,使用遗传算法(GA)来自动调参,从而将模型的准确度做进一步提升。
2 加油站销量预测原理
2.1 LSTM
LSTM由循环神经网络(RNN)改进而来。RNN会受到短时记忆的影响, 如果一条序列足够长,那它很难将信息从较早的时间步传送到后面的时间步,所以RNN不适合长时间序列的预测。 而LSTM很好地解决了RNN短时记忆的问题,LSTM具有称为门的内部机制,门结构在训练过程中会学习该保存或遗忘哪些信息,随后,它可以沿着长链序列传递相关信息以进行预测。LSTM每个细胞单元的结构如图1所示。
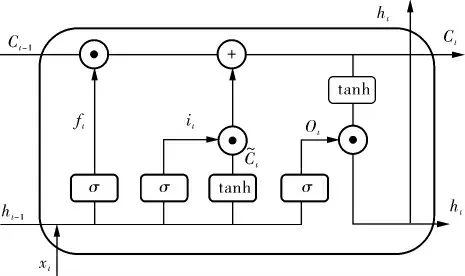
图1 LSTM每个细胞单元的结构
LSTM一个细胞单元里包含遗忘门、输入门和输出门3种门结构, 同时包含细胞状态向量和隐藏层状态两种状态,隐藏层状态是最终网络的输出,而细胞状态会参与隐藏层状态的计算。
设t时刻输入LSTM的向量xt=(x1,x2, …,xn),LSTM隐藏层状态输出ht=(h1,h2,…,hm),则每个细胞单元的计算流程如下:

其中,Wf、Wi、、WO为权重矩阵, 在训练过程中会自动学习更新;bf、bi、、bO为偏移量。遗忘门输出的向量ft与输入门输出的向量it分别通过Sigmoid函数将值调整到0~1;输入门的输出向量通过tanh函数将值调整到-1~1, 再将上一个细胞状态向量与这3个向量相加乘, 得到此次细胞状态向量Ct。 最后,通过输出门的输出向量Ot与细胞状态向量Ct得到最终隐藏层状态输出ht。
2.2 词嵌入
本项目加入的加油站销量特征中含有文本类型特征,需将文本转换为向量,再使用LSTM进行预测。
2.2.1 One-hot编码
One-hot编码又称一位有效编码,主要是采用N位状态寄存器对N个状态进行编码,不同状态的寄存器位置相互独立,并且在任意时刻对同一状态有且只有一个寄存器有效。
One-hot编码是分类变量作为二进制向量的表示。 本试验中将每个分类值映射到整数值。 然后,每个整数值被表示为二进制向量,除了整数的索引之外, 其他都是零值。 如周一到周日的One-hot编码分别是[1000000,0100000,0010000,0001000,0000100,0000010,0000001]。
One-hot编码也是将文本转换为向量的方法之一, 但是如果文本过长,One-hot编码就非常稀疏且不利于计算。
2.2.2 Embedding
Embedding的主要目的是对稀疏特征向量进行降维, 通过Embedding层的权重矩阵计算来降低维度。 除此之外,Embedding矩阵给每个分类变量分配一个固定长度的向量表示,这个长度可以自行设定。
笔者处理文本的思路便是先将文本进行One-hot编码处理,再使用Embedding进行降维,最终得到文本向量。
2.2.3 遗传算法
遗传算法起源于对生物系统进行的计算机模拟研究[9],是模仿生物界进化机制而寻求问题最优解的高效、并行、全局搜索方法。 遗传算法包括编码、初始化种群、评估适应度、判断终止条件、选择、交叉、变异和解码步骤,其流程如图2所示。
由于遗传算法可扩展性强,可将LSTM的每层细胞单元个数、 全连接层L2正则化权重参数、dropout参数、迭代次数、batch_size作为参数集合,将RMSE作为适应度函数, 经过遗传算法的迭代来寻找LSTM模型的最优超参数。 其中L2正则化参数为模型学习过程中的惩罚项,目的是防止模型过拟合;dropout是指在深度学习网络训练过程中,对神经网络单元,按一定概率将其暂时从网络中丢弃,dropout参数是丢弃的概率;batch_size是一次迭代训练选取的样本数;RMSE是预测值与真实值偏差的平方与观测次数n′比值的平方根,是评价模型精度的指标之一。
3 试验及结果分析
3.1 数据处理
3.1.1 特征提取
本项目选取的是昆明某加油站 (92#汽油)2019~2021年共计940日的数据,并在原始数据中添加“星期、温度、天气、节假日、油价”5个特征。对以上特征进行数据统计,结果如图3~7所示(其中1 t的92#汽油为1 379 L)。
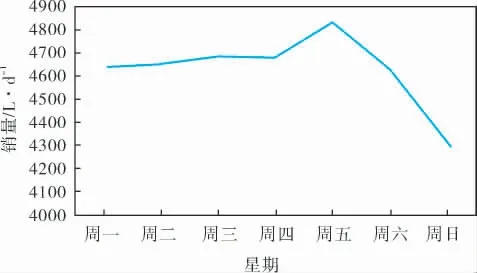
图3 星期与销量
图3对每周周一到周日所有销量加和取平均,可以看出,销量在周一至周五呈上升趋势,在周五达到峰值,并在周六、周日有所下降,周日达到最低点。 加油站销量与星期特征有较强的相关性。
图4对相同温度取平均值来观察温度对销量的影响。 由于地域关系,昆明的温度波动范围在1.5~25.0 ℃,极少出现低温或高温情况。 从图4可以看出,销量与温度特征的相关性较小。
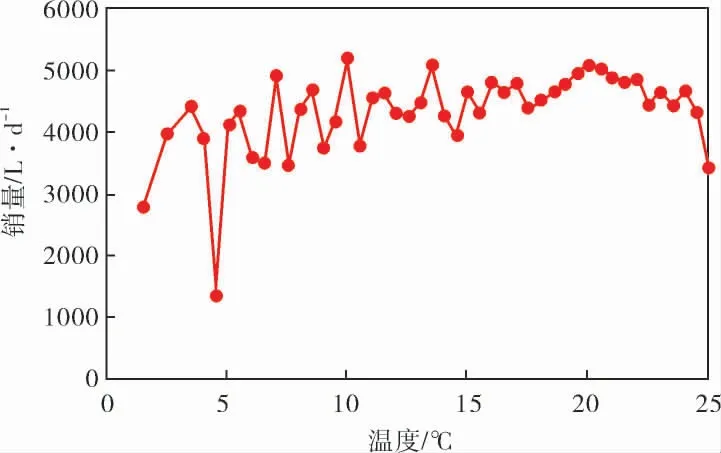
图4 温度与销量
图5对相同天气情况取平均值来观察天气对销量的影响。 因地域关系,昆明当地的天气种类包含不完全,但是仍然可以看出,暴雨等恶劣天气对于销量影响较大。
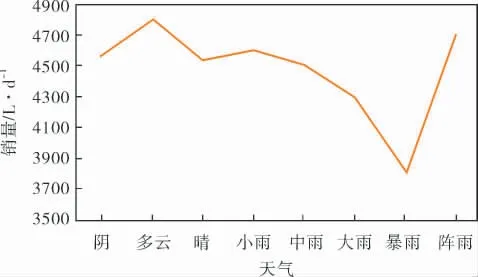
图5 天气与销量
图6对相同油价取平均值来观察油价对销量的影响。 虽然油价受到了部分特殊因素的影响,但是仍然可从图中得出,随着油价上涨,销量呈现略微下降的趋势,说明加油站销量与油价特征有一定的相关性。
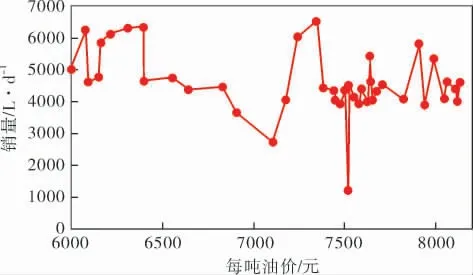
图6 油价与销量
图7对节假日以及节假日前一天取平均值来观察节假日对销量的影响。 通过对比发现,节假日前销量会高于平时销量,节假日期间(除春节)销量略高于平常, 春节期间销量则远低于平常,说明加油站销量与节假日特征有较强的相关性。
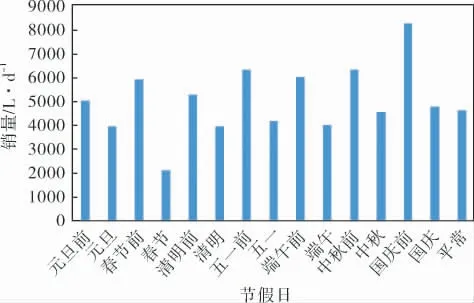
图7 节假日与销量
3.1.2 特征筛选
由于考虑到所增加的特征可能与销量并没有太大的关联性,于是将这些特征通过随机森林[10]评估其特征重要性。
使用随机森林进行特征重要性评估,即计算随机森林中的每棵树特征重要性评分并取平均值。 通常可以用基尼指数作为评价指标来衡量。

其中,K表示随机森林有|K|个类别,pmk′表示节点m中类别k′所占的比例,pmk表示节点m中类别k所占的比例。
特征Xj在节点m的重要性, 即节点m分支前、后的基尼指数评分变为:
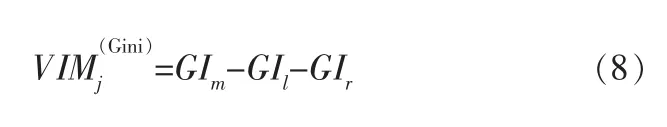
其中,GIl和GIr分别表示分支后两个新节点的基尼指数。
假设特征Xj在决策树i中出现的节点为集合M,那么特征Xj在第i棵树的重要性为:
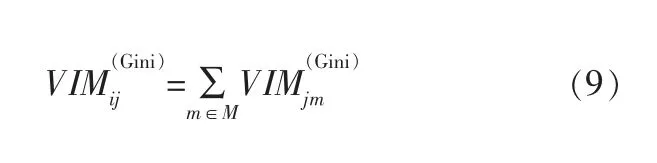
假设随机森林中共有n棵树,则:
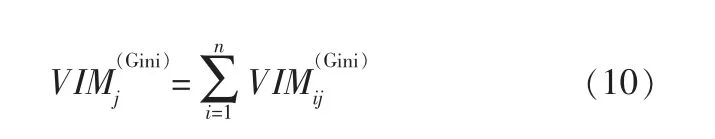
最后,把求得的重要性评分做归一化:
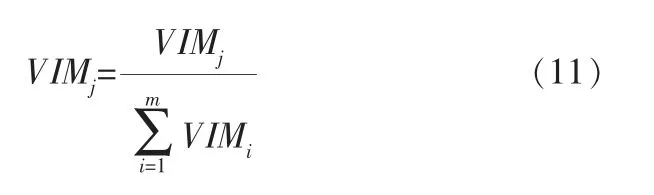
温度、星期、天气、油价、节假日通过随机森林得到的特征重要性评分如图8所示,可以看出,天气和温度特征的重要性评分都较低,但是考虑到恶劣天气对销量的影响较大,仅把温度特征删除。 从客观角度分析,之所以温度对于销量影响不大,其实是地域因素,即本项目预测的加油站地处昆明,温度变化相对较小,如果要预测每年温差较大的地区,温度特征需保留。

图8 随机森林特征重要性评分
3.2 建模过程
本项目的建模流程如图9所示。
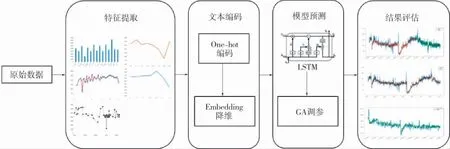
图9 建模流程
本项目原始数据为时间与销量的时间序列数据,建模过程如下:
a. 特征提取。加入温度、天气、油价、节假日、星期特征。
b. 特征筛选。通过随机森林对扩充特征进行特征重要性评分,将温度特征删除。
c. 文本编码。 对天气和星期这两个文本类特征进行One-hot编码; 再使用Embedding方法进行降维,将星期从1×7维度的向量降维为1×1,将天气从1×8维度的向量降维为1×3。
d. LSTM模型预测。 将处理完毕的数据放入LSTM模型进行预测。
e. 遗传算法调参。 将LSTM模型的超参数作为参数集合输入遗传算法, 并将RMSE作为目标函数,通过遗传算法得到最优超参数。
f. 结果评估。 验证模型的准确性。
3.3 结果分析
3.3.1 模型对比
先凭借经验设置LSTM超参数,得到模型预测结果。 细胞单元个数设置为50,dropout参数设置为0.5,L2正则化权重参数设置为0.01, 迭代次数设置为600,batch_size设置为32。
再将LSTM中的超参数放入遗传算法寻找最优超参数。 超参数集合有:细胞单元个数、dropout参数、L2正则化权重、迭代次数、batch_size,目标函数为RMSE。 使用遗传算法对LSTM模型超参数进行调参,设置的种群规模参数为15,最大进化代数为15,差分进化中的参数为0.5,重组概率为0.7,编码方式为RI。 分别调用遗传算法5次,得到的最优参数见表1。
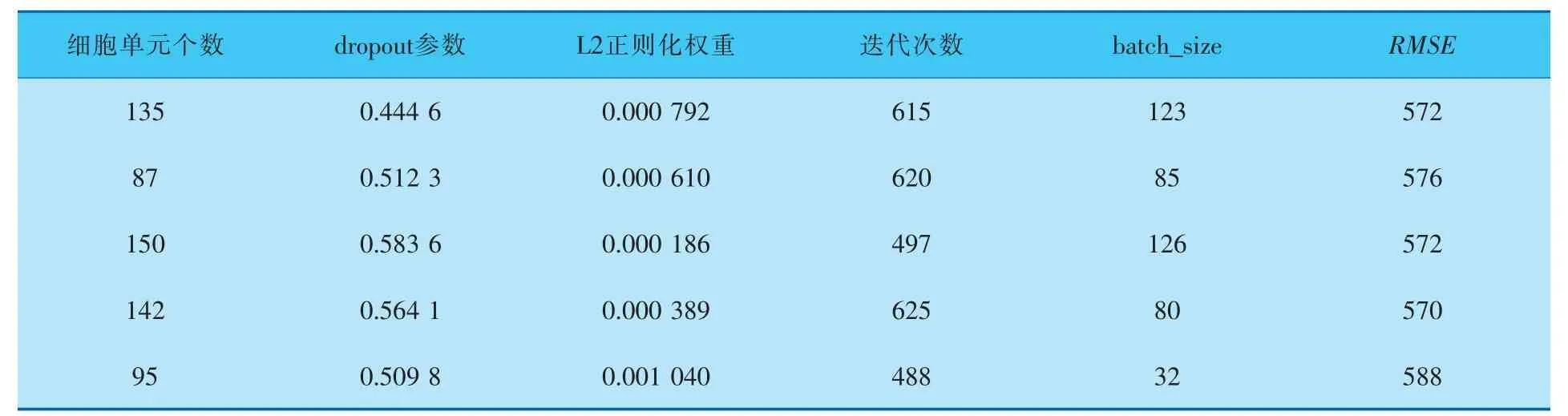
表1 遗传算法最优超参数结果
根据最后5个结果,最终选择的细胞单元个数为140,dropout参数为0.550 0, 全连接层L2正则化权重为0.000 400,迭代次数为620,batch_size为80。
将遗传算法得到的最优参数作为LSTM模型的超参数, 同时将2019年1月至2021年7月共计940天的数据划分训练集与测试集。 将2019年与2020年作为训练集训练,2021年作为测试集预测,并将结果与一次指数平滑进行对比。
目前,成品油调度系统中使用的是一次指数平滑方法对加油站销量进行预测,此方法能够较为有效地实现短期预测,但是其与真实值相比存在滞后,其计算式为:
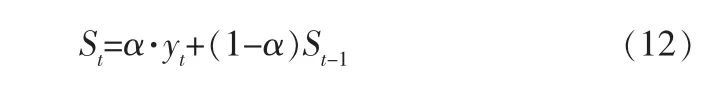
其中,St为t期平滑值,α为平滑常数,yt为t期实际值,St-1为t-1期的预测值。
3.3.2 结果分析
分别采用GA-LSTM与一次指数平滑进行预测,得到的结果见表2,预测图像如图10、11所示。可以看出,一次指数平滑模型存在预测滞后的问题,尤其是在春节前后的时间段,销量波动剧烈,一次指数平滑模型预测滞后明显,并且在测试集后半段预测一次指数平滑基本是一条直线。 而GA-LSTM的预测能较好地预测波峰和波谷,对于加油站销量这种非线性特征明显的数据也能有不错的预测效果。同时因为LSTM超参数较多的原因,使用遗传算法对LSTM的超参数进行调整,GA-LSTM模型比凭借经验设置的LSTM模型精度提升了3%,RMSE下降了40 L/d,使得LSTM模型预测更加精确。
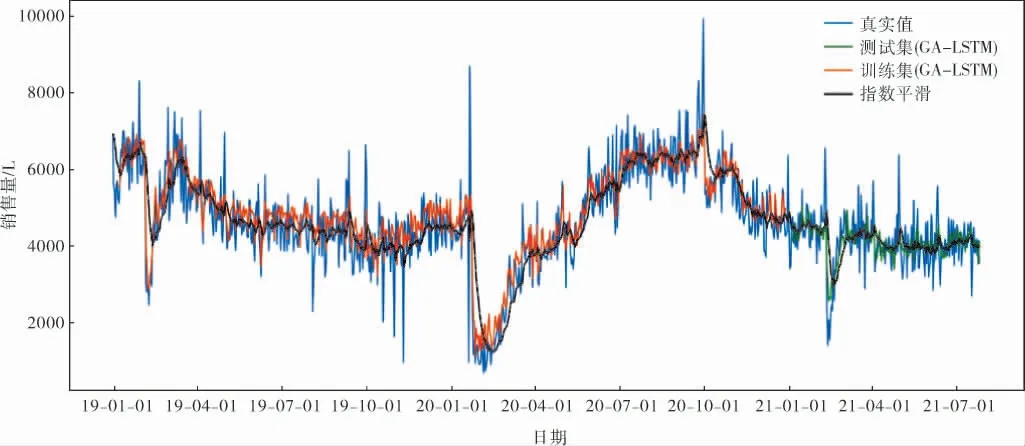
图10 训练集与测试集预测图像
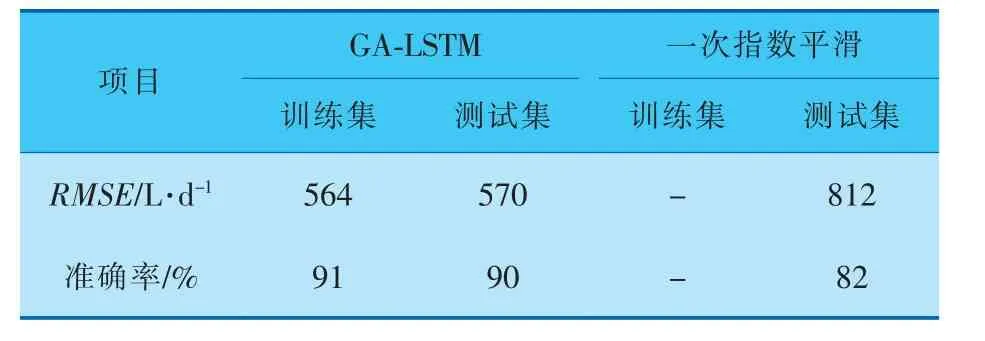
表2 不同模型结果对比

图11 测试集预测图像
从数据分析,GA-LSTM的RMSE比一次指数平滑要小很多,并且准确性提升了9%。同时,由于加入了节假日特征,GA-LSTM对于节假日前后销量波动比较剧烈的部分也较为敏感,能够进行有效预测。
4 结束语
提出基于GA-LSTM组合模型的加油站销量预测模型, 在时间加销量的原始数据上增加天气、温度、油价、星期、节假日特征来辅助预测,提升了预测精度,模型的准确率保持在90%以上,精度也高于目前的成品油调度系统中运用的一次指数平滑模型,并且该模型仅需训练一次,之后预测直接加载模型数据即可, 无需再次训练,具有实际落地应用的良好前景。 模型的预测灵活性强, 可以通过前m天的数据预测后n天的数据,来满足不同预测的需求。 该模型不仅适用于加油站销量预测,还适用于其他受多种因素影响的销量预测。
进一步的探究为加入注意力机制和挖掘潜在影响销量的特征。 将该模型配置在企业的成品油调度系统中,使得该预测模型能在企业系统中落地应用。
