基于MFFT-SCA的复杂光照条件下的行车检测
2022-05-27任庆坤
任庆坤
(昆明理工大学a.信息工程与自动化学院;b.云南省计算机技术应用重点实验室)
近些年,随着5G、云计算等高新技术的发展,自动驾驶、辅助驾驶技术吸引了研究机构和各大汽车厂商的广泛关注。 在实际应用中,为了保证安全性,需要准确且清晰地了解和把握车辆周围的行车环境情况,因此,对于自动驾驶任务而言,感知是尤为重要的前提条件。车辆的感知模块主要包含光学摄像头、毫米波雷达及激光雷达等传感器组件。由于基于光学摄像头的感知能够检测目标的外形、颜色和轮廓信息,因此,摄像头一直以来都是最重要的感知传感器,尤其是随着深度学习的提出和硬件算力的极大提升,基于深度学习的图像目标检测算法在自动驾驶检测任务中得到了广泛的应用和巨大的发展。视觉检测方法主 要 的 检 测 信 息 包 括 车 底 阴 影[1]、边 缘 对 称 性[2]等车辆特征信息,还包括基于帧差法[3]、光流法[4]等获得的图像运动信息。而识别阶段的主要任务是 利 用 模 板[5]和 机 器 学 习[6,7]的 方 式 完 成 车 辆 识别和定位。Luo W等提出了改进的孪生网络[8],通过内积直接获得匹配结果,极大地提高了运算效率,使该技术应用到无人驾驶领域成为可能。
然而,在光照条件复杂的环境下,如夜间、雨天及混合天气等情境下,视觉传感器很难区分目标和背景,单纯依靠视觉传感器无法满足实际任务需求。 因此,需要不受光照条件影响的非视觉传感器的加入, 以提供更加丰富的目标信息,从而应对夜间、雨天及混合天气等光照不足或光照条件复杂的应用场景。
毫米波雷达具备全天候工作的能力,同时可通过多普勒效应获取车辆等目标的速度、方位和距离信息,且价格优势明显,因此更适合该方向的研究。 然而,毫米波雷达获得的雷达点比较稀疏,无法明确表现出物体的边界,且横向分辨率有限的不足也同样需要重视。 因此,可以根据毫米波雷达和视觉传感器的特性, 来设计融合方案, 以增强复杂光照环境下障碍物检测的稳定性,从而满足车辆感知环境的需求。
针对基于深度学习的图像数据和雷达数据融合,Schlosser J 等尝试了多种不同组合方式来融合雷达数据和图像数据[9],提出通过采样雷达的点云信息获得密度深度图。Wu S G等引用贝叶斯公式,对预测结果进行动态融合[10]。 而Esi J等提出了一种基于雷达和立体视觉传感器的特殊欧氏群决策融合方案[11]。 Yang L等利用全向立体视觉(OSV)进行目标检测,使用Lucas-Kanade光流检测方法用于检测全景图像中的目标[12]。 蒋雯等提出一种新的数据融合方法,并与多卡尔曼滤波框架下的集成概率数据关联(IPDA)技术相结合[13]。 Chadwick S 等 提 出 将 雷 达 点 转 换 成 图像[14],作为卷积神经网络的输入数据,然后用元素级加法将雷达图像特征与视觉图像特征进行融合, 但这种融合方法受制于雷达点的稀疏性,很难提取具体的特征,因此性能提升有限。Jhon V和Mita S提出一种建立在YOLO框架上的融合模型,称为RVnet[15],该网络模型包含视觉与雷达的单独分支,采用级联的方式进行特征融合,同时引入了更多的权重。 Nobis F等提出Camera Radar Fusion Net(CRF-Net)来自动学习视觉传感器与雷达在哪个层次融合的性能最好[16]。Chang S等提出了一种利用毫米波雷达生成注意力矩阵来控制视觉传感器检测区域权重的毫米波雷达和视觉传感器的空间注意力融合 (Spatial Attention Fusion,SAF)方法[17],SAF方法在一定程度上避免了数据级融合的漏检现象。
通过对国内外研究现状的分析和总结,目前辅助驾驶领域仍存在以下问题亟待解决:
a. 雷达数据位置信息不足,无法提供更加精准的感兴趣区域建议,对于视觉检测的引导作用有限。 而当前所提出的关于雷达点云的增强技术,大多采用插值的方法,虽然一定程度上解决了点云稀疏的问题,但仍存在雷达数据位置信息不足, 无法表征目标物体边界的问题。
b. 多模态融合过程中,受限于雷达信息的不足,无法表征足够的特征信息,造成点云图像与视觉图像特征提取不平衡,信息会在一定程度上丢失, 导致检测效果在复杂光照环境下表现一般。 现有解决方法主要通过提升视觉检测模块的性能来弥补雷达信息不足的问题,未能从根本上发挥毫米波雷达的优势,也使得现有系统在复杂光照环境下的检测效果不佳。
针对国内外研究现存的问题,笔者有针对性地做出了研究,主要特点如下:
a. 提出了基于点云半径扩充的雷达位置信息增强技术。 笔者利用雷达点云的定位,对点云图中的稀疏点云进行信息扩充,增大点云所标注图像范围,对稀疏点云进行信息扩充,提高对视觉图像的检测引导,解决了因位置信息不足而导致的无法生成精准感兴趣区域的问题。
b. 提出了基于融入空间和通道注意力机制的多模态融合技术 (Multimodal Feature Fusion Technology-Spatial and Channel Attention,MFFTSCA)的复杂光照环境下的行车检测算法。以多模态融合技术为基础,首先强化了空间信息融合模块,提出一种改进的多模态空间融合策略,使经过增强处理的雷达空间位置信息与视觉特征更好地结合,得到更精准的感兴趣区域引导;然后引入通道注意力机制,对各通道的依赖性进行建模,增强雷达通道有用特征;最后通过特征金字塔(Feature Pyramid Networks,FPN),利用多尺度特征完成相应的目标检测任务。 所提出的MFFTSCA框架充分发挥了毫米波雷达全天候工作的优势,解决了毫米波雷达信息在融合过程中占比不高所造成的信息丢失问题,提高复杂光照环境下目标检测的准确度。
1 研究方法
1.1 位置信息增强
单个毫米波雷达所发出的电磁波范围是平行于地面的扇形区域,只能在单一平面高度反映目标的位置,因此,无法立体且准确地反映前方目标的形态和大小,同时,无法为图像检测任务提供准确可靠的感兴趣区域 (Region of Interest,ROI),降低了目标检测任务的准确性。因此,在将雷达数据输入网络之前,需要进行预处理,即首先进行空间位置信息增强。
笔者的做法是,以雷达原始点云中的各点为圆心,增加点的半径,生成以点为圆心,1.5 m为半径的圆形区域, 以此来增加雷达数据的位置信息,增强点云信息量。 利用增强位置信息的雷达数据生成空间二维矩阵,为视觉检测网络提供空间上的重点检测区域,引导检测网络在有重要目标的空间范围内对图像进行着重检测,同时不忽略其他空间位置的信息,实现空间上雷达数据与视觉图像数据的融合, 提高检测效率和检测效果,具体流程如图1所示。
经过对雷达点半径的扩大,提取雷达点所覆盖的图像的空间信息,为视觉检测提供感兴趣区域选择引导,同时,对雷达点覆盖范围的空间特征进行提取,生成空间二维矩阵,与图像特征做融合处理,实现空间信息融合。
为了验证增强位置信息对检测效果的有效性,笔者通过实验,测试了不同半径下位置信息对实验效果的影响。 同时针对混合天气、夜间及雨天条件下,不同光照的特质,针对性地对3种行车环境进行了位置信息增强实验,得出在不同环境下, 不同半径的大小对目标检测任务的影响,并找出了最佳的位置信息增强策略。
雷达空间位置信息如图2所示, 可以看出经过位置信息增强后,雷达点云更加清晰,目标边界特征更加明显,可以更好地为视觉检测提供感兴趣区域的引导。
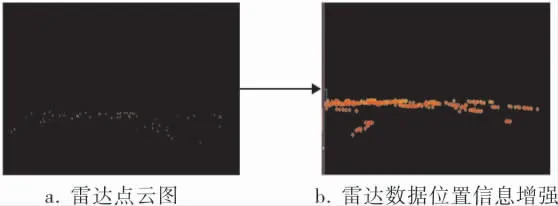
图2 雷达空间位置信息
1.2 空间信息融合
在夜间、 雨天及混合天气等复杂光照环境下,如何更好地利用毫米波雷达位置信息确定重点检测范围是值得探讨的问题。 针对此问题,需要在对位置信息进行增强的同时,融合双模态的空间特征信息,以有利于利用毫米波雷达所提供的位置信息对重点检测范围进行精确定位,尤其是在光照条件复杂的情况下。
如图3所示, 将图像信息和雷达信息同时送入网络, 根据R-Block1处理后的增强雷达位置信息生成空间二维矩阵,映射到视觉图像的所有通道上,与经过V-Block1处理之后的视觉图像相乘,得到特征矩阵,确定重点检测空间。 然后特征矩阵与V-Block1提取的视觉特征进行像素级相加,增强视觉的空间特征区域,引导视觉重点检测的空间。 这种空间信息融合方法能够有效地利用毫米波雷达不受天气影响、能提供准确的位置及距离等物理信息的优势。 需要说明的是,图3仅为空间融合生成二维注意矩阵的简单示例, 实际上,经过3层卷积后, 输出的特征矩阵要远比图中矩阵复杂得多,该图为了形象描述融合过程中感兴趣区域的引导,同时说明该结构并未摒弃区域外信息,进行了相应的简化处理。
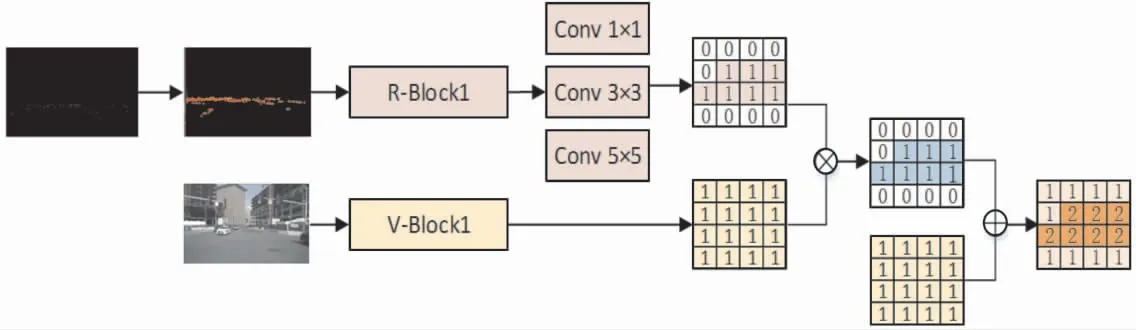
图3 空间信息融合生成二维注意矩阵简单示例
笔者提出了由3层卷积层组成的空间信息融合机制,用于提取空间特征信息,得到二维注意矩阵从而对视觉分支的特征图进行加权处理,得到准确的感兴趣区域引导,同时不忽略区域外的图像信息。 Conv 1×1层即卷积核为1×1, 步长为(1,1),填充[0,0],而Conv 3×3和Conv 5×5层分别设置为(3×3×256×1,(1,1),[1,1])和(5×5×256×1,(1,1),[2,2])。 该3层卷积结构需做进一步处理,将雷达特征图中的通道数减为1,从而使输出的二维注意矩阵与视觉特征矩阵具有同样的高度和宽度。
1.3 通道注意力
由于车辆检测模型对于数据表征能力有一定要求,因此需构建注意力机制模块,以发挥相应的能力提升作用,具体表现为使网络学习到图片特征中的重要信息,同时对非重要信息实施抑制。
注意力机制通过学习的方式获取特征间的依赖关系和各部分的重要程度,并根据重要性突出高频信息,筛除无用干扰信息。 Hu J等在对特征图各个通道之间的依赖性进行探究时[18],创造性地采用了通道注意力机制的方式搭建相关模型。 通过权重值大小表征各个通道的重要程度,获得显著性特征映射,指导网络重点关注信息量丰富的特征,抑制冗杂特征的干扰。 通道注意力模块如图4所示。 利用通道注意力机制,可以强化雷达通道的权重值,使雷达通道的信息在全局信息中的权重更大。 笔者在级联操作后,设计了相关的通道注意力模块,通过挤压、激励等操作,并依据通道信息依赖性构建分析模型,以增强有效通道中的特征信息。 并通过实验证明了通道注意力的有效性。
输入图像X的维度H′×W′×C′,经过特征提取操作Ftr后得到维度为H×W×C的特征图U,3个维度分别为高度、宽度和通道数。 通道注意力机制通过下述步骤实现。
提取通道特征权重。 通过挤压进行权重提取,具体操作是:从各通道上压缩特征图的高度和宽度, 将维度为H×W×C的特征图压缩为1×1×C,可以看出,特征图通道数量并未发生改变。 挤压过程可以用以下函数表达:
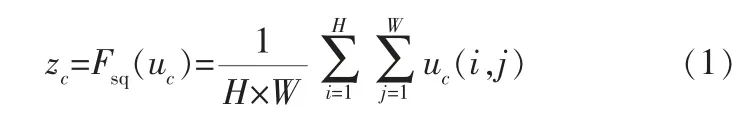
特征通道权重更新。 特征经全连接层进行通道信息融合, 通过学习的方式获取0~1之间的归一化权重,基于权重大小得到各通道特征的重要程度。 权重更新过程用下式表达:

权重映射。 将上述归一化后的输出权重值与原输入特征图进行逐通道加权,得到经过权重映射后的增强特征。 尺度函数为:
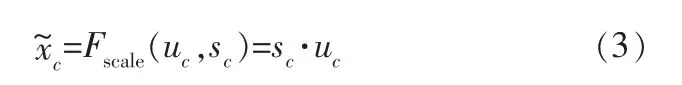
该函数式叫做挤压函数,其中uc代表第c个通道特征;i、j对应特征图上每一个像素点的位置,对输入特征进行平均池化,得到输出特征zc。挤压函数计算了全局平均值,也可以称之为全局平均池化,即对各个通道内的特征值进行加和后再计算平均值。
1.4 网络结构
笔者提出的网络结构主要通过对RetinaNet框架的改进实现,用改进的VGG网络进行特征提取。 将网络扩展到处理增强图像的附加雷达通道上,整体网络包含雷达模块、视觉模块、位置信息增强模块、空间信息融合模块、通道注意力模块、特征融合提取模块、特征金字塔模块以及分类与回归模块。 整体网络结构如图5所示。
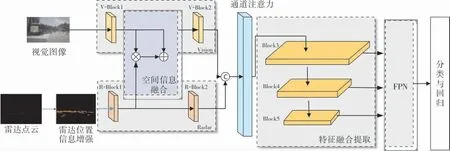
图5 整体网络结构
雷达数据送入主干网络前,首先经过位置信息增强,再送入改进的特征提取网络进行特征提取,经过R-Block1提取特征后,与视觉特征在空间上进行融合,生成重点检测区域,为视觉检测在空间上提供指引。 空间融合后的特征矩阵经过VBlock2进一步提取特征后与R-Block2提取的雷达特征进行级联。 再将级联后的融合特征经过通道注意力模块, 对其在各通道的依赖性上进行建模,学习毫米波雷达与视觉摄像头双模态融合的全局特征信息, 增强有用特征所在通道的权重。笔者所提出的融合方法能够充分利用毫米波雷达与视觉传感器两种模态的特征信息,通过空间信息和通道注意力,更大程度地提取和整合双模态中的有用信息,使得整个系统结构能够更加适应全天候的任务环境,尤其是在复杂光照环境的任务条件,能够有效提升系统的适用性。
经过融合,将融合后的数据输入特征金字塔网络,采用金字塔结构的多尺度特征对目标进行检测,以便获取并检测出不同远近、不同大小的车辆目标并对其进行标定。 笔者所采用的特征金字塔结构参考RetinaNet网络中的结构,同时沿用RetinaNet网络中分类模块的思想,在每个特征层均输出一个融合后的检测结果,通过分类模块的比较,自适应输出成绩最高的检测结果将其作为最终的结果。
2 实验与分析
2.1 实验设置与数据
本节将通过实验证明笔者提出的毫米波雷达与视觉融合网络结构的可行性,同时验证所提出的相关改进对于复杂光照环境下行车检测准确度的提高。
实验在tensorflow下实现MFFT-SCA方法,实验均在具有16 GB显存的显卡Telsa V100上训练模型。 训练时,输入图片大小为450×450,设置学习率为0.000 1,训练30代。
数据集采用NuScenes多模态数据集,从该数据集中按6∶2∶2的比例选取出混合天气、雨天和夜间的场景进行模型训练。 参与训练和测试的雷达-视觉对数据共20 480个, 分别针对上述场景进行训练和测试。
2.2 实验数据集
NuScenes 多模态数据集用6 个分辨率为1600×900的摄像机,5个频率为77 GHz、探测距离为250 m的毫米波雷达,1个32线激光雷达、GPS以及惯导系统,采集车辆前、后、左、右、左前及右前等多个方向,涵盖所有角度的850个场景数据。 该数据集不仅标注了大小、范围,还标注了类别、可见程度等。
针对笔者的研究内容和需求,实验只选取了前向毫米波雷达和前向摄像机的关键帧数据进行训练、测试和评估。 其中,毫米波雷达包含了18个物理状态信息,包括相对速度、相对距离等信息。 笔者只使用位置和距离的相关信息,针对前方车辆进行有针对性的检测。
2.3 实验结果与分析
2.3.1 雷达点半径对检测效果的影响
为了验证增强雷达位置信息对检测效果的影响,同时确定最佳效果下的雷达点半径,笔者针对不同半径的雷达点进行了对比实验。 实验以CRF-Net网络为基准目标检测算法, 做初步的雷达数据位置信息增强实验,得到表现最佳的半径数值, 为后续采用笔者所提出的MFFT-SCA模型做检测时提供半径参数。 实验结果见表1、2。

表1 不同雷达点半径和不同光照条件下障碍物检测的平均精度均值
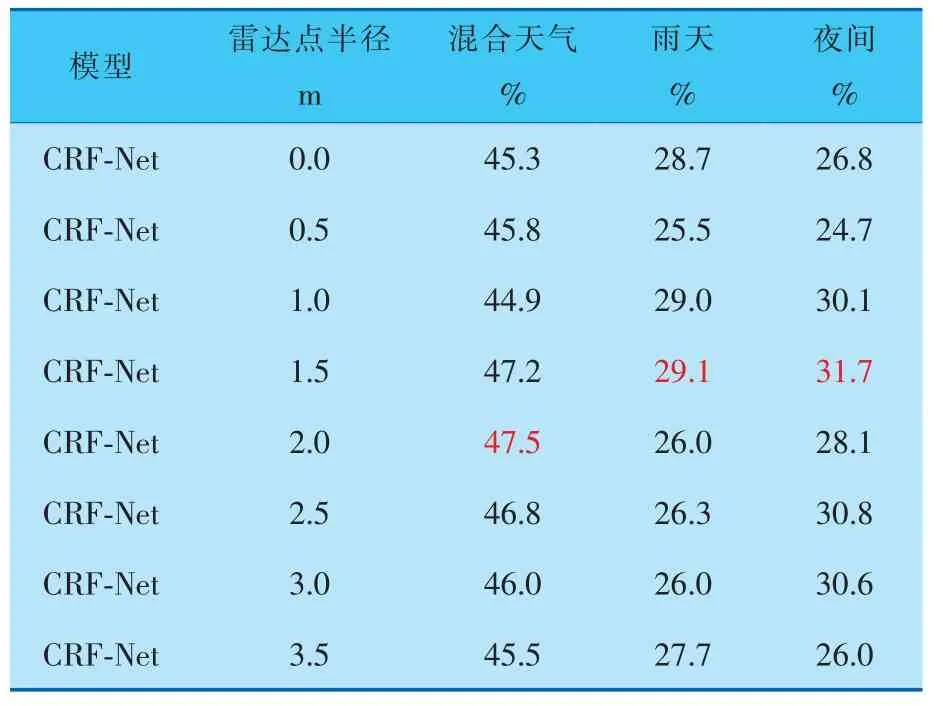
表2 不同雷达点半径和不同光照条件下障碍物检测的平均召回率均值
实验为了对比不同半径的雷达点对检测效果的影响, 在0.0~3.5 m的雷达点半径范围内,每间隔0.5 m做一次对比实验。 由表1可得, 在0.0~3.0 m的雷达点半径范围内,随着雷达点半径的不断增大,检测效果随之增强,而当雷达点半径达到1.5~2.0 m时,检测效果达到最佳(表中红色数字)。 继续增大雷达点半径,检测效果不再有明显提升。 因为此时,雷达点半径已经包含了足够的位置信息,可以为视觉检测提供准确的感兴趣区域引导,继续扩大雷达点半径,只会加入冗余信息,导致检测精度达到阈值。
由表1、2可知, 雷达半径为0.0 m时与雷达半径经过增强后的数据进行对比,3种场景下的平均精度均值和平均召回率均值都有所提高。 当雷达点半径增强至1.5 m时, 平均精度均值提升了0.3%~4.1%, 而平均召回率均值提升了0.4%~4.9%。 由此可以肯定,对雷达数据的位置信息进行增强可以有效提高检测效果。
2.3.2 不同雷达点半径在雨天检测的对比实验
由于不同种类目标物的高度不同,笔者研究了不同雷达点半径对不同障碍物在复杂光照环境下检测效果的影响。
在行车环境为雨天的条件下, 选取了小型汽车、公交车和卡车作为检测目标,实验结果见表3、4,可以看出,不同种类目标的最优检测效果与雷达点半径呈现正相关: 即雷达点直径越接近目标实际高度或尺寸, 则检测精度和召回率越高。
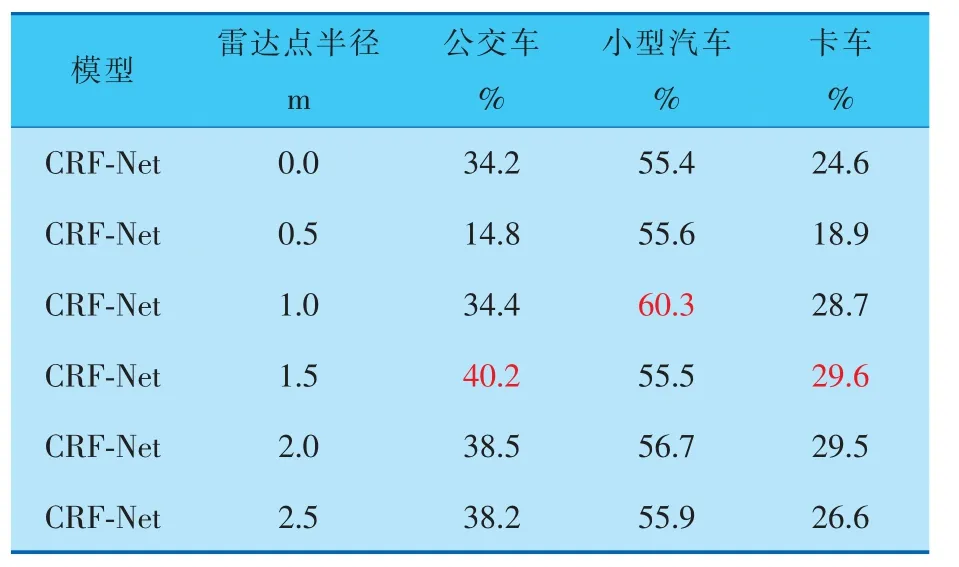
表3 不同雷达点半径在雨天检测各类障碍物的平均精度
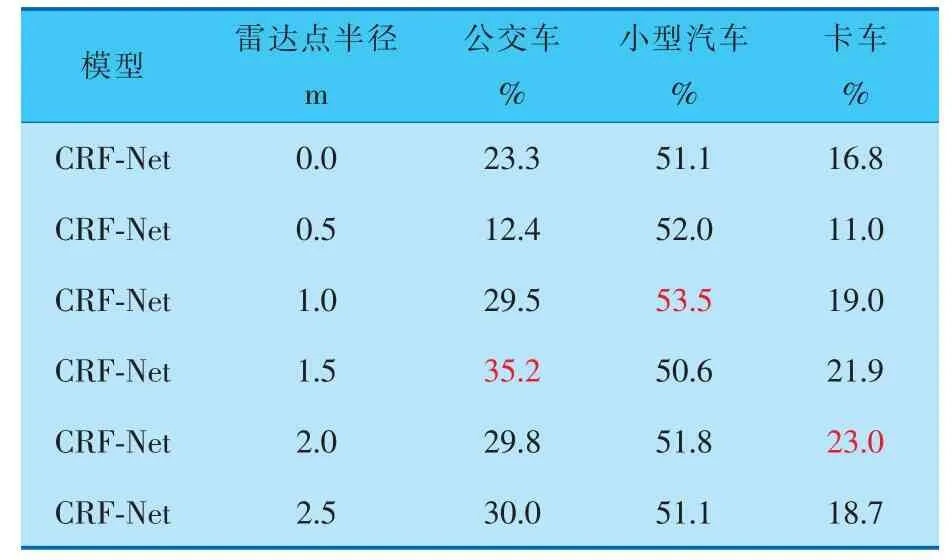
表4 不同雷达点半径在雨天检测各类障碍物的平均召回率
由表3、4可以看出,当雷达点半径为1.0 m时,在雨天检测环境下, 小型汽车的检测效果最好,相较于基线模型,平均召回率和平均精度分别提高了2.4%和4.9%。而当雷达点半径为1.5 m 时,对公交车和卡车的检测识别效果达到最好。 由此对比各种类目标的实际尺寸和高度,可得在雨天检测环境下,当雷达点直径与目标实际尺寸和高度越相似,检测精度和召回率越高。
2.3.3 不同雷达点半径在夜间检测的对比实验
在夜间行车时, 往往光照条件更为复杂,一般情况下只有车灯和路灯作为光源,为行驶车辆提供光照,因此,夜间环境下的检测与白天完全不同。 受制于光照的不足,夜间场景下同一物体的全局特征相较于光照条件好的场景下会有不同程度的削弱。 因此,对于夜间物体的检测,最佳雷达点半径与目标的局部特征的相关性更高,检测结果见表5、6。

表5 不同雷达点半径在夜间检测各类障碍物的平均召回率
由表5、6数据分析可知,在夜间行车环境下,当雷达点半径为0.5 m时,小型汽车的检测精度和召回率均达到最佳,较基线模型,平均召回率提高了0.3%,平均精度提高了3.1%。 而当雷达点半径为1.0 m时,公交车和卡车的平均召回率达到最佳,当雷达点半径为1.5 m时,公交车和卡车的平均精度数值达到最佳。 由此可得,在夜间行车环境下,受制于复杂的光照环境,雷达点半径与目标实际尺寸或高度的相关性相较于雨天环境有所降低,而与目标的局部特征的相关性更高。
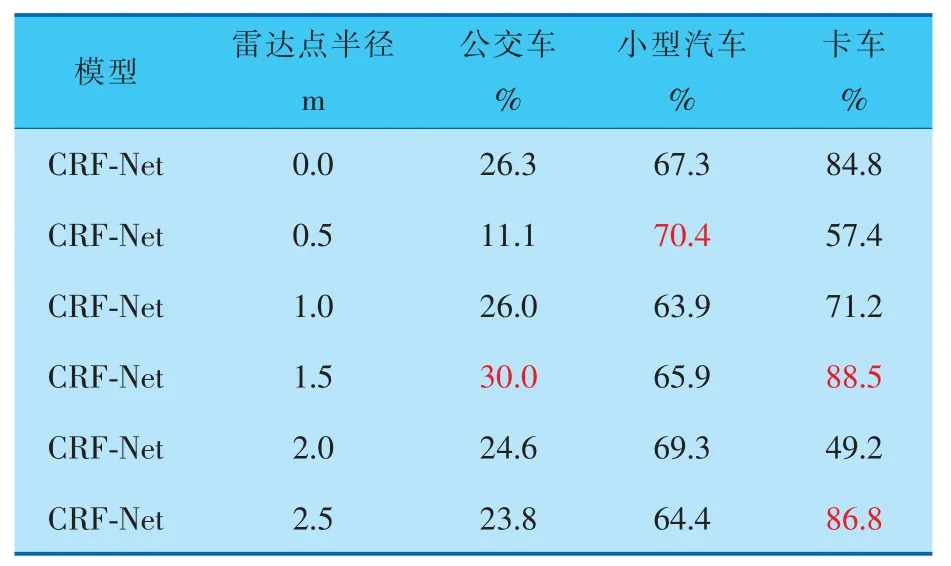
表6 不同雷达点半径在夜间检测各类障碍物的平均精度
综上所述, 通过比较各环境下检测效果,可以得到,当雷达点半径为1.5 m时,在各环境下均能达到较好的检测效果。 因此,笔者选择雷达点半径为1.5 m作为最佳的半径参数, 继续后续实验。
2.3.4 消融实验
为了验证所提出方法的检测性能, 笔者以NuScenes多模态数据集中各类车辆的分类和定位为基础,对比模型在公交车、小型汽车和卡车这几种常见车型上的检测平均精度,以及各类别综合检测的平均精度。 为此设计了消融实验,以验证笔者所提出方法的各部分模块对系统检测效果的提升。
笔者从NuScenes数据集中, 按6∶2∶2的比例选取出混合天气、 雨天和夜间的场景进行模型训练。 在不补充雷达信号位置信息和将雷达点半径扩展为1.5 m的情况下,分别测试了空间信息融合与通道注意力机制对检测效果的影响。 检测结果见表7、8。
由表7、8可知, 在对雷达数据的位置信息进行增强后,MFFT-SCA模型的检测效果比基线模型有了明显提升, 尤其是在夜间的检测效果上,平均精度均值和平均召回率均值分别提高了11.2%和6.0%;雨天场景下,平均精度均值和平均召回率均值分别提高了2.2%和1.6%;混合天气下平均精度均值和平均召回率均值分别提高了0.3%~1.5%。在同样的模型下,对雷达数据的位置信息进行增强处理, 效果较不增强条件下更好。实际检测效果如图6所示。 可以看出, 由MFFTSCA模型主导的复杂光照环境下的行车检测,能够在雨天、夜间等光照不足或有干扰的行车环境中,完成对车辆运行前方各行车目标的识别和检测。 证明了笔者所提出模型的有效性。

图6 混合天气、雨天和夜间场景下的检测效果
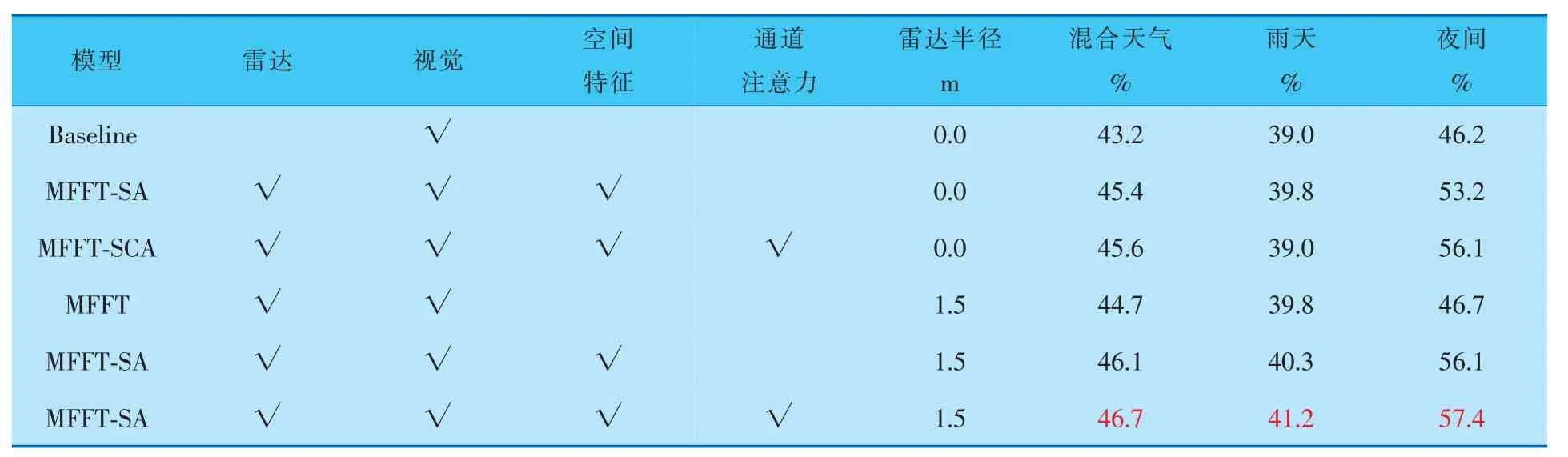
表7 消融实验设置及不同场景下检测各类障碍物的平均精度均值
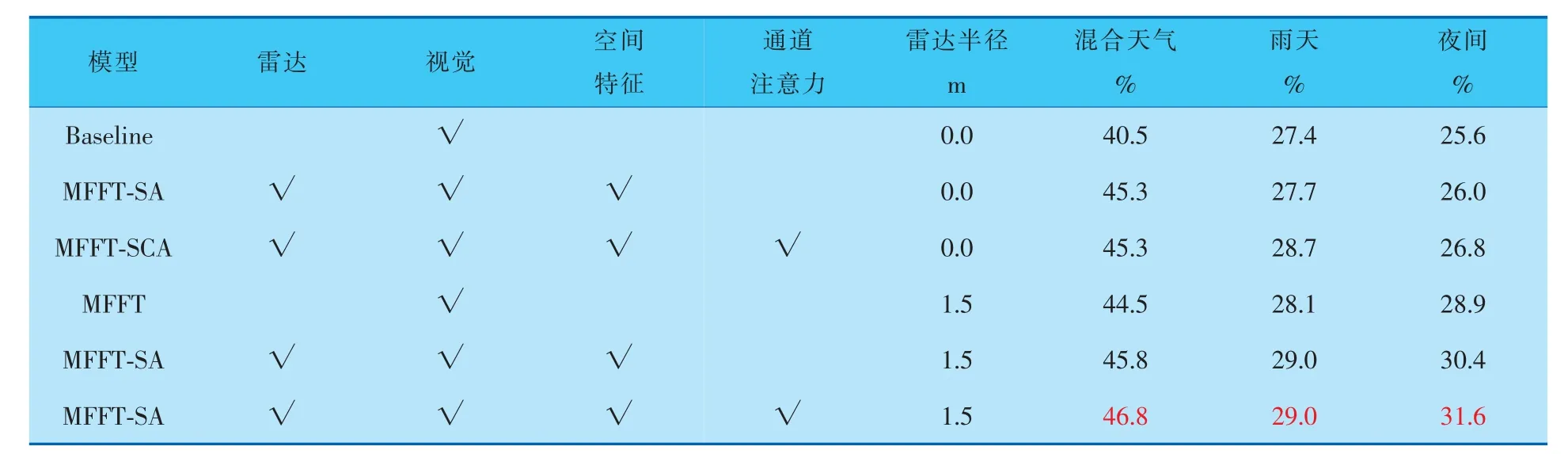
表8 消融实验设置及不同场景下检测各类障碍物的平均召回率均值
3 结束语
提出了一种基于毫米波雷达与视觉传感器融合的检测算法MFFT-SCA, 以解决复杂光照环境下行车检测的问题。 在所提出的检测方法中,加入了空间信息融合和通道注意力机制的相关内容,并通过实验验证了各部分结构对检测效果的提升。 与其他融合方法相比,笔者提出的方法首先对雷达数据的位置信息进行了增强,在一定程度上解决了毫米波雷达点云稀疏,空间位置信息少所导致的信息丢失问题;其次,利用毫米波雷达的空间位置信息与视觉信息进行空间信息融合,生成特征矩阵,从而更好地引导感兴趣区域的确定, 在突出视觉重点检测空间的前提下,同时不忽略其他检测空间的信息,进一步避免了信息丢失的问题;最后,通过改善雷达特征与视觉特征的融合方式,引入级联形式对双模态信息进行融合,利用通道注意力机制,对通道的依赖性进行建模,增强有用通道信息的权重,抑制无用通道信息,从而提升了毫米波雷达数据在融合过程中的权重,同时,进一步增强了检测效果。 通过实验证明,笔者所提出的方法能够有效地提高在夜间、雨天及混合天气等光照条件复杂的行车环境下的检测效果。
