知识图谱引导的贝叶斯网概率推理
2022-05-27李彦柯祁志卫李剑宇
李彦柯,祁志卫,李剑宇,胡 矿
(云南大学 信息学院,昆明 650500)
1 引 言
贝叶斯网(Bayesian Network,BN)是一种表示和推理不确定性知识的有效模型,被广泛应用于故障诊断[1]、金融投资决策[2],以及疾病风险评估[3]等领域.BN通过一个有向无环图(Directed Acyclic Graph,DAG)以及条件概率表(Conditional Probability Table,CPT)量化变量之间依赖的不确定性,为多变量间复杂的不确定性依赖关系的表示和概率推理提供了统一框架[4].给定证据节点集合,基于BN计算查询节点的条件概率、后验概率或边缘概率,是BN推理的基本任务.例如,基于图1(a)所示的疾病评估BN,可推断用户因“营养不良”而患“淋巴炎”的概率为60%,以此判断用户罹患淋巴炎的可能性.然而,BN推理在具有高效需求的应用场景中有待进一步扩展.一方面,受领域知识专业性强、知识体系庞大等因素影响,实际应用中的BN规模都较为庞大.例如,Onisko[5]等开发的用于肝脏疾病诊断的大型BN系统,用于辅导学生解决物理学问题的ANDES系统[6],都具有上百个节点,并且BN中CPT参数数目与父节点及节点的状态数目呈指数级数量关系.在基于BN的概率推理算法中,以变量消元[7](Variable Elimination,VE)为代表的精确推理算法和以吉布斯采样[8](Gibbs Sampling,GS)、前向采样[9](Forward Sampling,FS)为代表的近似推理方法均为NP困难问题.另一方面,由于缺乏节点间潜在的关联信息,节点在推理任务中的重要性无从判断,因此,产生了许多与推理任务无关的节点计算,导致推理效率低下.例如,针对图1(a)中的推理任务,在已知“营养不良”的情况下,推断罹患“淋巴炎”的可能性,在领域知识中已知“骨髓造血功能异常”以及“熬夜”不是当前推理任务的重要因素[10],因为二者与“淋巴炎”的潜在关联强度弱,所以在推理计算过程中不予考虑.为此,针对BN推理任务,本文旨在引入外部领域知识,以提高BN推理任务的效率.
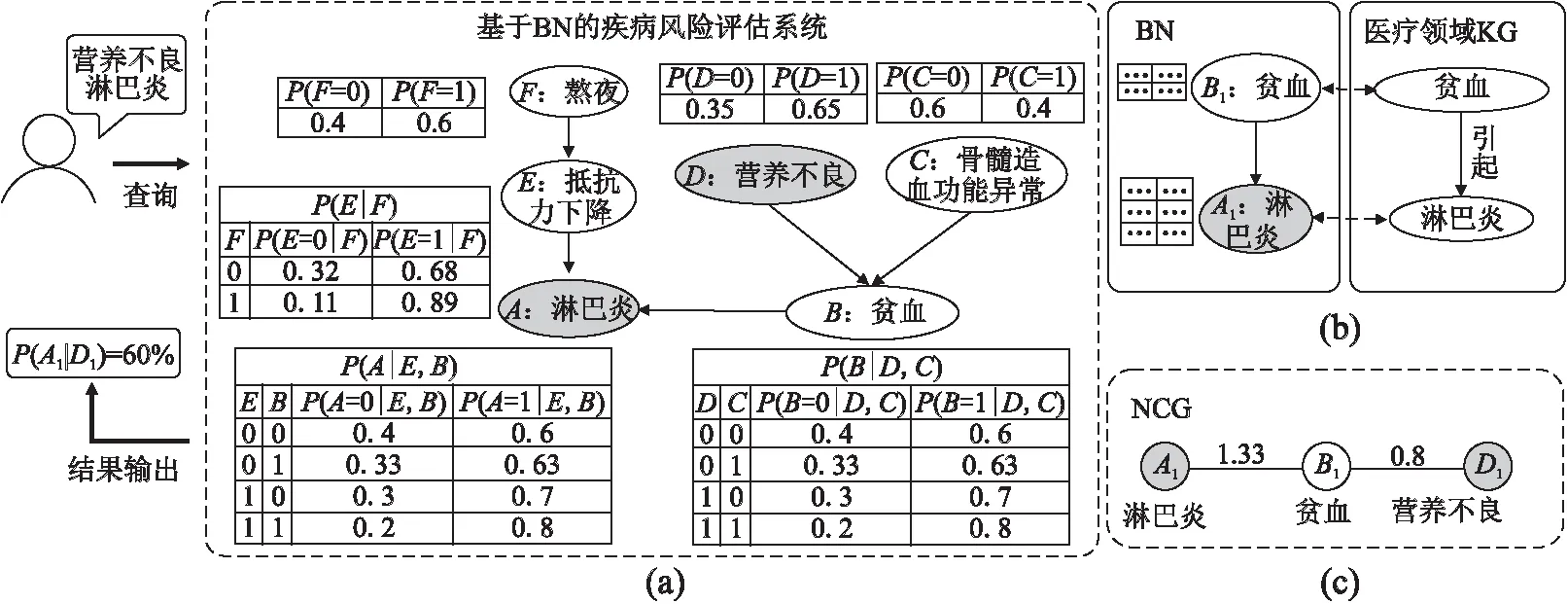
图1 疾病风险评估BN、BN节点与KG实体的映射示例
近年来,研究人员提出了许多提高BN推理效率的近似推理方法,主要分为基于随机抽样的近似推理方法和基于BN子图抽取的近似推理方法.
基于随机抽样的近似推理是基于BN的结构及其节点参数,随机抽取BN中每个节点的取值并生成数据样本,基于满足条件的样本统计数近似地模拟BN的概率.GS算法是在BN所有变量的联合状态空间中与证据节点一致的子空间里随机采样的一种近似推理方法.Qi等[11]通过在BN中随机采样生成采样样本,以此将BN表示为点互信息矩阵,保留了BN中的CPT及DAG信息,并进一步基于奇异值分解方法将点互信息矩阵分解生成节点的嵌入来支持BN推理.然而,上述基于随机游走的BN推理方法收敛都较为缓慢.
基于BN子图抽取的近似推理方法利用BN的结构和节点间的依赖关系对查询节点进行近似推理,以加快推理速度[12].Draper等[13]提出局部偏序评估算法,该算法聚焦于与查询节点最相关的节点集合进行推理,与查询节点最相关的节点集被称为活动集,每次计算都通过增加一些节点和边来扩大活动集以提高精度.Sarkar等[14]通过找到最近似BN结构的最优联结树来对BN进行近似推理.Nicholson等[15]提出局部联结树算法,该算法以已知的查询节点为中心,基于互信息构建带权BN子图,并将该子图转换为小规模的联结树来实现推理.上述方法均是基于一定机制抽取BN子图用于推理,未考虑BN节点间潜在的关联信息,与推理任务无关的节点参与计算导致推理效率不佳的问题依然存在.
因此,如何引入BN外部的领域知识来补充BN节点间潜在的关联信息,合理抽取BN子图用于计算,以提高BN推理效率,是本文研究的重点.为此,拟解决以下3个问题:
1)如何在BN推理过程中引入外部领域知识?
2)如何抽取BN子图以提高BN推理效率?
3)如何在引入领域知识后实现概率推理?
知识图谱(Knowledge Graph,KG)通过将现实中的事实建模为<头实体,关系,尾实体>三元组,使知识得到结构化表示,被广泛运用于信息检索[16]、智能问答[17]等领域.为此,本文将KG中的领域知识作为BN推理的知识补充,以抽取BN的子图结构.具体而言,我们首先建立KG实体与BN节点之间的映射,然后,利用TransE模型[18]将KG中的实体嵌入到低维向量空间,最后,通过余弦相似度计算得到KG中不同实体之间的相似度,以此作为BN节点之间依赖关系的补充.
为了抽取BN子图,首先按KG实体间相似度在BN结构中选择从查询节点到证据节点集合的最大实体相似度的最短路径,路径构成用于支持BN推理的节点关联图(Node Correlation Graph,NCG).选择最大相似度的最短路径的过程演变为搜索以查询节点为根节点的生成树问题.基于Prim算法思想[19]提出NCG构建算法.与此同时,本文为了保证BN推理结果的有效性,给出基于KG实体相似度与BN节点参数的NCG权值计算方法.
为了在引入领域知识后实现BN的推理计算,本文通过图嵌入方法,将BN中的高度复杂计算任务转化为NCG节点嵌入后的证据节点向量与查询节点向量间的关联度强度计算.采用Node2vec[20]的可调偏置随机采样策略准确捕捉NCG节点邻居信息及其全局结构的特征,以获取节点序列样本,基于Skip-Gram模型对生成的节点序列样本进行嵌入[21],并进一步通过NCG节点向量计算证据节点与查询节点之间的关联强度在NCG中所有节点与查询节点关联强度总和中所占的比重,从而得到推理结果.
在不同规模BN上的实验结果表明,本文方法的效率高于经典的Gibbs采样和前向采样方法,且能得到准确的推理结果.
2 相关定义及问题陈述
2.1 相关定义
定义1.KG表示为K=(E,R),其中E={e1,e2,…,en}是KG实体集合,R表示实体间的关系集合.
定义2.BN表示为B=(G,P),其中G=(X,ε)是一个有向无环图,X={x1,x2,…,xm}是BN的节点集合,且BN中所有节点X均在E中具有对应实体,即ei↔xi(1≤i≤m,m≤n).ε表示BN中有向边的集合,P为CPT的集合.
为了有效融合B与K,基于B的子图结构构建如图1(c)所示的NCG,其节点及边都是B的节点集合与K边集合的子集,并基于中节点的参数与中实体相似度计算NCG节点间的权值.
定义3.NCG为带权无向图,表示为T=(N,M,W),N(N⊆V))为NCG节点集合;M(M⊆ε)为NCG边的集合,W表示边的权重集合.
2.2 问题陈述
给定一个BN、一个与BN描述领域知识一致的KG、查询节点xq以及证据节点集合Xs={x1,x2,…,xn}(Xs⊆X).基于查询节点xq与证据节点xi(1≤i≤n)得到NCG,并以NCG为依据计算xq与xi之间的条件概率值P(xq|xi),或查询节点xq与证据节点集合Xs的条件概率值P(xq|Xs).
3 NCG的构建
3.1 NCG的结构构建
给定一个BN B和KG K,为了从B中抽取子图构建NCG T的结构,首先,从K中查询与B节点vi相对应的实体ei,例如图1(b)所示,B中节点“A1:淋巴炎”表示当“A:淋巴炎”节点状态取值为1时,“淋巴炎”节点状态为“存在”与中的“淋巴炎”实体相对应,以此得到与B节点集合对应的K的部分实体集合Es(Es⊆E).然后,计算Es的实体间相似度.最后,将实体相似度作为B中节点之间依赖的领域知识补充,并以此为依据抽取B的子图.
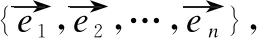
(1)
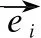
上述思想见算法1.
算法1.构建NCG结构
输入:B:一个BN,B=(G,P),G=(X,ε);
xq:查询节点;
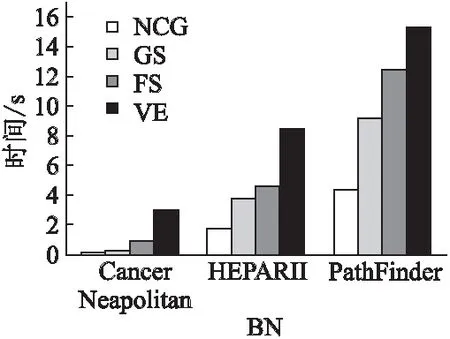
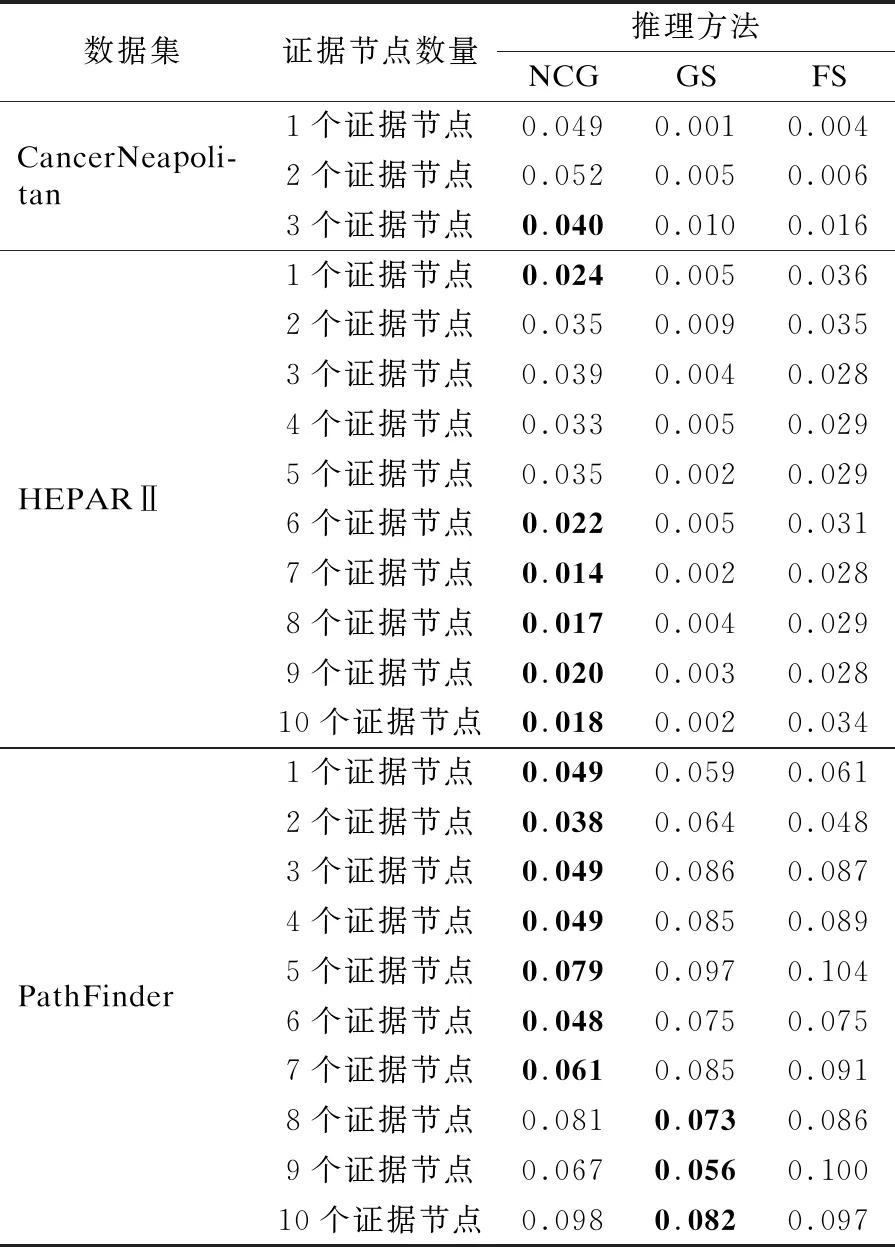
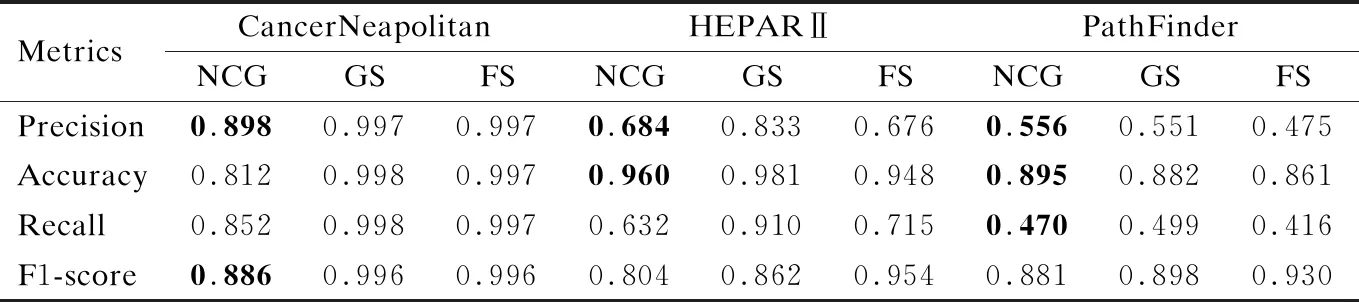
Xs:证据节点集合{x1,x2,…,xn}(1≤n 变量:cand:候选节点集合 输出:NCG结构T=(N,M,W) 1.N←Ø,M←Ø,X←Ø 2.while{xq,Xs}N//当N包含xq与Xs时结束 3.N←xq//xq作为起始节点 4.fori=1to|N|do 5.cand←{X-xq}//遍历候选节点集合 6.forj←1to|cand|do 7.ifMij←inεthen//若边Mij在边集合ε中 9.endif 10.endfor 11.forMijinsorted(W(Mij))do//根据权重对M降序排序 12.N←N∪{xi,xj}//取排序第一的边的首节点xi与尾节点xj添加到N 13.M←Mij 14.cand.remove{xi,xj}//将xi与xj从候选节点集合中移除 15.endfor 16.endfor 17.endwhile 18.returnT=(N,M,W) 例1.针对图1(a)所示的BN,依据推理任务P(A:淋巴炎|D:营养不良)获取NCG的结构.首先以查询节点“A:淋巴炎”为起点,在B中查找节点“A:淋巴炎”的一阶邻居集合{“E:抵抗力下降”、“B:贫血”},由式(1)计算“A:淋巴炎”与其邻居节点的实体相似度分别为0.35、0.75.然后选取实体相似度最大节点“B:贫血”加入节点集合N,同时,将边MAB加入M边集合.继续将节点“B:贫血”作为起点重复上述步骤,当证据节点“D:营养不良”在已选节点集合N中时结束算法,最终得到如图1(c)所示的NCG结构. (2) 通过实体相似度计算T的每条边的权重Wij,进而得到带权无向图T. 为了将复杂的推理计算任务转化为简单灵活的NCG节点向量计算,采用Node2vec[20]图嵌入方法将节点嵌入到低维向量中.具体而言,给定T=(N,M,W),通过随机采样及Skip-gram两个步骤实现对的嵌入. 首先,在随机采样T的节点序列样本过程中,采用可调偏置的随机采样策略,以T中包含领域知识的W为引导进行随机采样.设x0∈N为起始节点,xi为随机采样的第i个节点.计算xi到xi+1的转移概率π(xi,xi+1): π(xi,xi+1)=αφη(xi-1,xi+1)×Wxi,xx+1 (3) 其中,Wxi,xx+1为T中节点xi与xi+1之间边的权重.αφη(xi-1,xi+1)是由xi-1与xi+1之间最短距离确定的超参数,xi-1为xi的另一个邻居节点.φ和η是用于控制随机采样偏置的参数. 然后,采样得到多个节点序列样本之后,基于Skip-gram模型将节点序列样本嵌入.具体而言,将节点xi的独热向量,以及由W引导获得的节点序列样本中,xi邻居节点的独热向量组成的集合Nb(xi)作为输入,目标是在权值W的引导下最大化xi周围邻居的概率Pro(Nb(xi)|f(xi)),即最大化对数似然函数: maxf∑xi∈Xlog[Pro(Nb(xi)|f(xi)) (4) 其中,Nb(xi)是由包含领域知识的转移概率π(xi,xi+1)引导随机采样得到的xi邻居节点集合. (5) 采用3个医疗领域的BN,包括CancerNeapolitan(1)https://www.norsys.com/netlibrary/index.htm、HEPARⅡ(2)https://www.bnlearn.com/bnrepository/discrete-large.html#hepar2以及PathFinder(3)https://www.bnlearn.com/bnrepository/discrete-verylarge.html#pathfinder作为实验数据.其中,CancerNeapolitan是用于诊断癌症的BN,HEPARⅡ是用于诊断肝脏疾病的BN,PathFinder是协助诊断淋巴结疾病的BN.数据集信息如表1所示. 表1 BN数据集信息 此外,采用公开的医疗领域的KG数据作为BN的外部知识,KG数据的基本信息如表2所示. 表2 医疗KG的实体与关系类型 为了评估本文提出的推理方法的效率以及有效性,将NCG与VE[7]、GS[8]、FS[9]3个经典的BN推理方法进行比较. 为了评估模型推理效率,对NCG、VE、GS、FS的执行时间进行比较. 为了评估NCG推理的有效性,采用均方误差(Mean Square Error,MSE)、准确率(Precision)、精确率(Accuracy)、召回率(Recall)以及F1值(F1-score)作为评估指标. MSE用于评估NCG、GS、FS生成的结果值与真实值之间的误差,本文以精确推理方法VE的推理结果作为真实值,计算NCG推理得到的结果偏离真实值的平方和的平均数,MSE公式如下: (6) 准确率、精确率、召回率以及F1值用于评估模型推理结果的偏向与真实值是否一致.将VE推理结果作为真实值,设定阈值为0.5,推理结果大于等于0.5为正偏向,反之为负偏向.推理结果为正偏向则归入正例,推理结果为负偏向则归入负例.准确率(Precision)、精确率(Accuracy)、召回率(Recall)和F1值(F1-score)分别定义如下: (7) (8) (9) (10) 其中,TP表示待测模型的推理结果为正例,同时真实值也为正例的数量;FP表示待测模型推理结果为正例,真实值为负例的数量;TN表示待测模型推理结果为负例且真实值也为负例的数量;FN表示待测模型推理结果为负例,真实值为正例的数量. Intel(R)Core(TM)i5-8265U CPU @1.60GHz处理器,8GB内存,Windows 10(64位)操作系统,使用Python 3.6作为编程语言. 为了平衡NCG推理的效率及有效性,将TransE的学习率设置为0.0001,KG嵌入维度设置为100.另外,在CancerNeapolitan上将Node2vec的嵌入维度、游走步长、游走次数分别设置为10、3、50,在HEPARⅡ上分别设置为50、10、100,在PathFinder上分别设置为50、20、100.另外,将Node2vec中用于控制游走策略的参数和分别设置为1和20. 为了评估不同BN规模对NCG的推理效率的影响,首先,在不同规模的BN数据集上分别基于NCG、GS、FS、VE执行100次随机推理任务,记录NCG、GS、FS以及VE的平均执行时间并进行比较,结果如图2所示.结果表明,各模型推理时间随BN规模的扩大而增加,其中NCG在不同规模的BN上实现推理的平均时间比GS快53%,比FS快65.3%,比VE快66.9%,这是因为NCG在推理过程中基于KG中的实体相似度补充了BN节点间潜在的关联信息,合理精简地抽取用于推理的BN子图,减少了因BN节点以及参数数量过多导致的大量计算步骤,从而提高了BN推理效率. 图2 不同BN对各推理方法推理效率的影响 然后,为了测试证据节点数量对NCG推理时间的影响,通过改变证据节点的数量来比较NCG与VE、GS、FS的执行时间,如图3所示.结果表明,随着证据节点数量增多,NCG推理时间趋于稳定,得出NCG的推理效率对证据节点数量不敏感的结论.这是因为在构建NCG的过程中,以查询节点为中心,向外扩散到证据节点,推理效率只与查询节点与证据节点之间的路径长度有关. 图3 不同推理方法的执行时间 为了测试NCG推理的有效性,采用VE精确推理结果作为真实值,通过MSE来评估推理的准确性,使用精确率、准确率、召回率、F1值来评估NCG模型推理结果的偏向与真实值偏向的一致性. 首先,测试NCG在不同规模BN中执行100次随机推理的精度,结果如表3所示.可以看出,在PathFinder数据集中证据节点数量不大于7时,NCG的误差比GS和FS都小,这表明随着BN规模的扩大,NCG的推理结果越精确. 表3 不同推理方法的MSE比较 然后,测试NCG在3个不同规模BN中分别执行100次随机推理,并计算精确率、准确率、召回率、F1值,结果如表4所示.可以看出,随着BN规模的扩大,NCG的精确率和准确率与GS和FS的测试结果接近,在PathFinder中NCG的精确率、准确率均超过GS与FS的测试结果.另外,召回率和F1值随BN规模扩大而减小,NCG在不同规模测试集上推理的F1值均高于80%,不仅说明KG中的领域知识与BN中的推理逻辑相符,且进一步反映了KG引导BN概率推理的有效性. 表4 不同推理方法的推理效果对比 本文提出基于KG引导的BN推理方法,在BN的小范围内实现推理.基于KG实体相似度抽取BN子图得到NCG结构,并给出BN节点参数与KG实体相似度的叠加方法,最终得到带权无向图NCG用于推理.实验结果表明,本文的方法在BN推理效率方面有较大提升,在推理的有效性方面与GS和FS的推理结果接近.在未来的工作中将进一步学习KG中实体间的其他特征,更好地表征KG中的领域知识,使知识引导的BN推理效果得到进一步的提升.
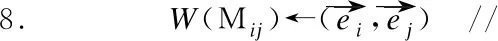
3.2 NCG权重计算
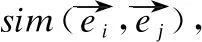

3.3 NCG嵌入
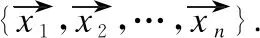
3.4 基于NCG的推理
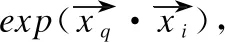
4 实验设置
4.1 实验数据


4.2 对比模型
4.3 测试指标
4.4 实验环境
4.5 参数设置
4.6 推理效率测试

4.7 有效性测试
5 总 结
