水库安全管理文档质量评估系统设计与实现
2022-05-26葛从兵严吉皞
葛从兵,严吉皞,陈 剑
(南京水利科学研究院,江苏南京 210029)
0 引言
我国现有水库9 万多座,数量居世界之首。修建水库是调控水资源时空分布、优化水资源配置及防洪减灾的重要工程措施,是贯彻落实新时期治水方针的重要手段,对保障国家用水安全发挥着不可替代的基础性作用。但水库在发挥其效益同时,也存在一定风险,一旦失事,可能会给下游带来灭顶之灾,不仅影响下游公共财产安全与生态环境安全,而且直接影响社会稳定。
水库安全管理工作是保障水库安全运行的重要的非工程措施。水库安全管理文档质量不仅可反映水库管理单位的安全管理工作情况,而且会影响水库安全管理工作开展。大坝安全鉴定[1]、水库调度规程[2]和水库大坝安全管理应急预案(以下简称水库应急预案)[3]是水库安全管理工作中的3 个重要文档。大坝安全鉴定通过现场检查与大坝安全评价鉴定大坝安全状况:将大坝分为一类坝、二类坝与三类坝,其中三类坝存在较严重的安全隐患,不能按设计正常运行,需进行除险加固;水库调度规程明确水库各项调度依据、调度任务与调度原则、调度要求与调度条件、调度方式等,是水库调度运用的依据性文件;水库大坝安全管理应急预案是在水库大坝发生突发安全事件时用于避免或减少损失的预先制定的方案,是提高水库管理单位及其主管部门应对突发事件能力及降低水库风险的重要非工程措施。由于我国水库数量众多,参与编制以上文档的单位较多,难免会存在质量差的文档。若大坝安全鉴定文档质量差,可能会对大坝安全状况进行误判,使大坝带病运行,或浪费除险加固资金;若水库调度规程文档质量差,可能会提供错误的调度方案,给水库工程带来险情,或使水资源无法得到有效利用;若水库应急预案文档质量差,可能造成应对突发事件不当的情况,不仅不能降低突发事件损失,甚至可能增加损失。如果采用人工查阅方式发现质量差的文档,需要大量专家,且工作量大、时间长。
针对文档质量评估,研究人员已开展了相关研究。如陈琪等[4]在软件文档质量评价方法研究中提出文档质量度量模型,审查人员可根据模型对文档质量进行评价;宁凌[5]提出PDM 文档自动审核算法,该算法在模型训练之前,需要专业审核人员对文档的标题、字词级错误及语法错误进行标注;汤莉等[6]提出Web 文档数据质量评估方法,该方法采用正例样本和负例样本对模型进行训练。本文通过对中文分词与文档质量评估方法的研究,提出一种基于词频的水库安全管理文档质量评估方法。该方法属于无监督学习,训练样本无需专家进行处理,可实现水库安全管理文档质量的自动评估,从而有效提高文档质量评估能力及速度。
1 总体设计
水库安全管理文档质量评估系统对全部文档进行中文分词(Chinese Word Segmentation,CWS),获取词及词频[7];对词进行关键词学习,获得文档质量评估标准;根据文档质量评估标准与单个文档中的关键词及词频,评估文档质量。
1.1 系统框架
水库安全管理文档质量评估系统框架见图1。文档格式可以是TXT、Word、PDF 等,数据库采用MySQL[8],编程语言采用Python[9]。水库安全管理文档质量评估系统采用B/S 架构,选用Python 语言的Web 框架Django[10],内建中文分词、关键词学习、文档质量指数计算等功能模块。
1.2 系统功能
水库安全管理文档质量评估系统功能见图2。
全文档中文分词对全部文档进行中文分词,获得词及词频;关键词选取按照一定选取率从词中选择关键词;关键词学习通过不断剔除关键词和文档,直至文档质量平均指数满足要求;评估标准生成在关键词学习结束时,将最终的关键词及词频作为最终评估标准存入数据库;单文档中文分词通过对文档进行中文分词,获得词及词频;质量指数计算根据评估标准和文档的关键词及词频,计算文档质量指数,给出文档质量水平;用户管理可添加、修改、删除用户,对用户进行认证;参数设置可设置系统所需参数。
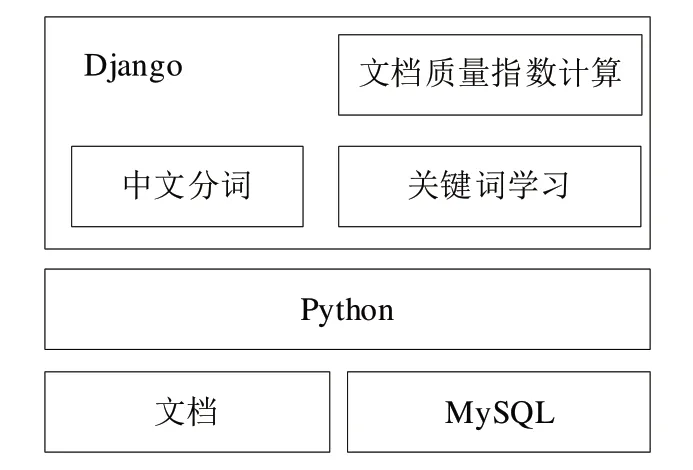
Fig.1 System framework图1 系统框架
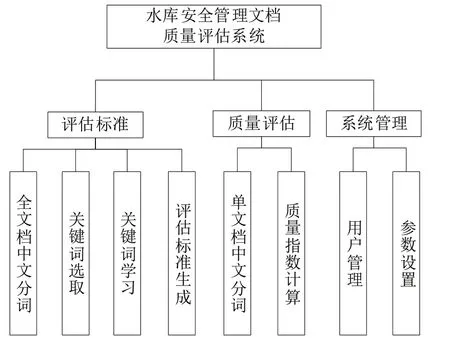
Fig.2 System function图2 系统功能
2 中文分词
分词是指将连续的字序列按照一定规范重新组合成词序列的过程,中文分词是指将一个汉字序列切分成一个个单独的词。
2.1 分词方法
现有分词方法较多,可分为3 大类:基于规则的分词方法、基于统计的分词方法[11]与基于理解的分词方法[12]。
(1)基于规则的分词方法又称机械分词方法,其按照一定策略将待分析的汉字串与一个“充分大”的机器词典中的词条进行匹配,若找到某个字符串,则匹配成功。常用字符串匹配方法有最大匹配法[13]、逆向最大匹配法、最小切分法、双向最大匹配法[14]等。此类方法简单高效、易于实现,但对歧义和未登录词的处理效果不佳。
(2)基于统计的分词方法采用统计模型,对给定的大量已分词文本进行学习,获得词语切分规律,再应用此规律对未知文本进行切分。主要统计模型有N 元文法模型(N-gram)、隐马尔可夫模型(Hidden Markov Model,HMM)[15]、最大熵模型(ME)、条件随机场模型(Conditional Random Fields,CRF)[16]等。此类方法能够结合上下文识别未登录词,自动消除歧义。
(3)基于理解的分词方法在分词的同时还进行句法、语义分析,利用句法信息和语义信息处理歧义现象。通常包括3 部分:分词子系统、句法语义子系统、总控部分。基于理解的分词方法主要有专家系统分词法与神经网络分词法。此类方法准确度高,但速度慢。
2.2 分词工具
中文分词工具有BosonNLP、IKAnalyzer、NLPIR、SCWS、结巴分词(jieba)[17]、盘古分词、庖丁解牛、搜狗分词、新浪云、语言云等,调用形式有REST API、JAR 包、多语言接口、PHP 库、Python 库等。从功能、准确度、易用性等方面综合考虑,文档质量评估系统采用较常用的结巴分词。
结巴分词基于字典树(Trie)结构实现词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(Directed Acyclic Graph,DAG);采用动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用基于汉字成词能力的HMM 模型,并使用Viterbi算法。
结巴中文分词支持4 种分词模式:精确模式、全模式、搜索引擎模式与Paddle 模式。精确模式可将句子精确地切分开,适合文本分析;全模式把句子中所有可以成词的词语都扫描出来,速度快,但不能解决歧义问题;搜索引擎模式在精确模式基础上,对长词再次进行切分,提高召回率,适用于搜索引擎分词;Paddle 模式利用PaddlePaddle 深度学习框架,训练序列标注(双向GRU)网络模型,从而实现分词[18]。
结巴中文分词能够识别新词、去除停用词、提取关键词及标注词性,并支持自定义字典和并行分词。
2.3 词频统计
词频(Term Frequency,TF)是一个词在文件中出现的次数。为了标准化,词频通常用概率表示,见公式(1)。由于水库安全管理文档质量评估会关注文档中的关键词出现次数,故这里词频采用次数表示,而不采用概率表示。
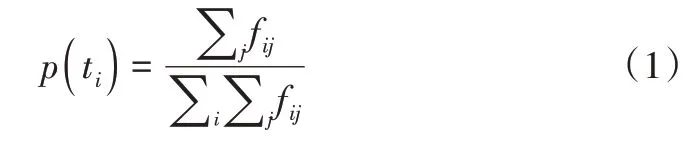
式中,fij为词t i在同类文档dj中出现的次数。
词频统计采用结巴分词对每个文档进行分词,然后统计各词的词频。
3 质量评估
3.1 评估方法
文档质量评估依据是文档中关键词词频是否达到标准要求。评估方法是计算文档中关键词词频与标准中关键词词频的比值,见公式(2)。

式中,e为文档质量指数,fi为文档中关键词ki的词频,sfi为标准中关键词ki的词频,n为标准中的关键词数量。计算e时,如果fi>sfi,则取fi=sfi。当e≥0.9 时,文档质量优;e≥0.8 时,文档质量良;e≥0.6 时,文档质量中;e<0.6 时,文档质量差。
3.2 关键词学习
评估标准是文档中应有的关键词及词频。目前相关专家还无法准确给出评估标准,因此需要对全部文档中的关键词进行学习以获得评估标准。
关键词学习是一个不断剔除关键词和文档的递归过程。学习参数包括关键词选取率s、文档质量指数标准es、关键词初始剔除率kr0与文档初始剔除率dr0。
关键词来自经过结巴分词后全部文档中的词,考虑到大部分词不能成为关键词,为提高学习效率,设关键词选取率s为0.5,即选取词频排序前50%的词。
文档质量平均指数是所有选用文档(即非剔除文档)质量指数的平均值,当文档质量平均指数大于等于文档质量指数标准es时,递归过程结束,设文档质量指数标准es为0.95。
每轮关键词学习都会剔除词频较低的关键词和文档质量指数较低的文档,随着学习的深入,选用的关键词和文档越来越少,剔除率也应越来越低。剔除率递减速度与文档质量平均指数变化量成反比,即指数变化量越大,剔除率递减量越小,以保持较高剔除率;指数变化量越小,剔除率递减量越大,将大幅减少剔除率。由于文档全部参与学习,故文档剔除率递减量小于关键词剔除率递减量,使文档剔除率高于关键词剔除率,从而提高学习效率。剔除率计算见公式(3),初始剔除率kr0与dr0均设为0.1。
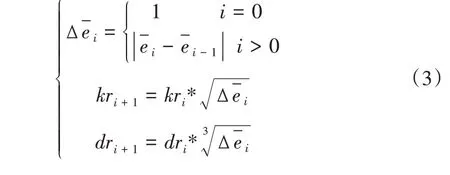
4 系统实现
4.1 主要功能实现
(1)词频统计。词频统计要先进行中文分词。结巴分词提供Python 库,系统通过调用Python 库完成中文分词。在中文分词时,通过添加水利专业名词,以提高分词正确率;通过去除停用词,特别是地名,以提高搜索效率。词频统计主要代码如下:


(2)文档质量标准计算。文档质量评估依据文档质量标准,文档质量标准计算主要代码如下:

(3)关键词学习。关键词学习较为复杂,主要过程如下:①对全部文档进行结巴分词,存储水库名称、文档类型、词、词频等信息;②按词频由大到小对词进行排序,按关键词初始选取率s 选择词作为关键词;③计算文档质量平均指数及其变化量,如果文档质量平均指数大于等于文档质量指数标准es,则学习结束;④按关键词剔除率kri和文档剔除率dri,分别剔除词频较低的关键词和文档质量指数较低的文档;⑤计算kri+1和dri+1,转至步骤③。
4.2 实验测试
选用部分省市水库的应急预案文档,对水库安全管理文档质量评估系统进行实验。首先进行关键词学习,得到应急预案文档质量标准见表1(仅列出词频前20 的关键词,下同),然后对每个文档进行评估。例如,经过评估,某大型水库的应急预案文档关键词及词频见表2,文档质量指数为0.91;某中型水库的应急预案文档关键词及词频见表3,文档质量指数为0.72。

Table 1 Document quality standard表1 文档质量标准

续表
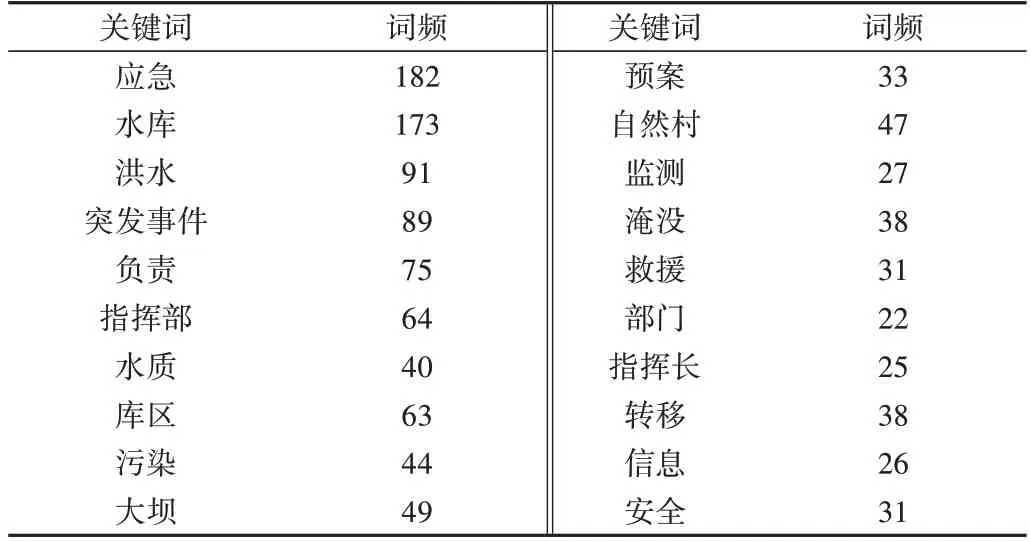
Table 2 Key words and term frequency in some large reservoir document表2 某大型水库文档关键词及词频
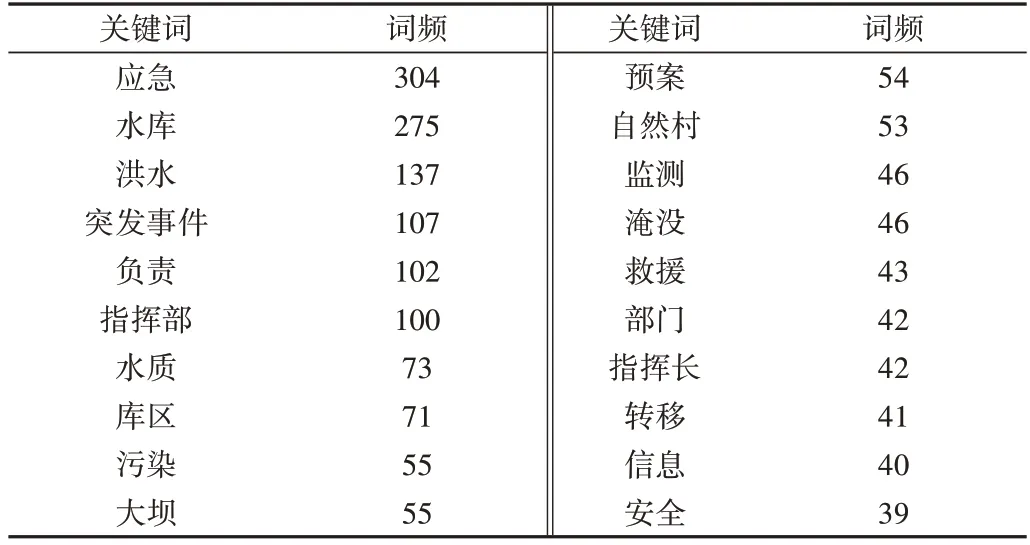
Table 3 Key words and term frequency in some medium reservoir document表3 某中型水库文档关键词及词频
实验结果表明,大部分大型水库的应急预案文档质量指数大于0.85,质量较好;中型水库质量指数通常在0.65~0.85 之间,质量一般;小型水库质量指数通常在0.45~0.65 之间,质量较差。这与现实情况基本一致,主要因为大型水库管理人员多,相关资料多,管理规范;中小型水库管理人员少,相关资料少,管理水平一般。
5 结语
本文研发基于词频的水库安全管理文档质量评估系统对水库安全管理文档的质量评估基本准确,表明词频可作为同类文档的质量评估因子。由于不同水库在工程规模、控制流域面积、库容、坝型、最大坝高、坝顶长度、水工建筑物数量等方面存在差异,客观上造成各水库的大坝安全鉴定、水库调度规程及应急预案等文档在词频上存在一定差异,而本文的质量评估方法与关键词学习算法没有考虑这些因素。因此,为使文档质量评估更加准确,后续将进一步研究上述因素对词频的影响,并在质量评估方法和关键词学习算法中增加相应的权重因子。
