基于随机森林的能耗预测调度
2022-05-26许晔炫潘景山王继彬
许晔炫,潘景山,王继彬
(1.山东建筑大学计算机科学与技术学院;2.国家超级计算机济南中心,山东济南 250101)
0 引言
云计算可以按需提供可扩展和可靠的计算服务,如基础设施、平台和软件服务,改变了信息和通信技术行业,成为一种新兴的计算范式[1]。云计算主要是一种结合虚拟化、服务管理自动化和标准化的技术,它可以提供灵活的计算能力和高性能的数据分析方法[2-3]。企业可以在云平台上运行多种服务,无需构建数据中心。云计算的广泛应用构建了大量的数据中心,这些数据中心消耗了大量的电能,产生了大量的热量。云计算数据中心的机架式服务器每台消耗可高达1 000W,最高温度可达100℃[4]。服务器温度升高不仅导致冷却成本增加,还会产生严重影响系统可靠性的热点。在使用云服务的过程中,由于每台服务器中的任务不同,耗能不同,会出现某一台服务器处于高能耗状态,使得服务器温度上升,从而形成热点。热点的出现会增加服务器故障率,损害服务器使用寿命。研究表明[5],当服务器温度高于21℃时,服务器温度每增加10℃,故障率翻倍。因此,避免服务器出现热点现象具有重要研究意义。
目前,国内外对如何避免服务器热点现象的研究较少。预测服务器能耗能够帮助服务器提前感知下一时刻的状态,从而作出相应调整,避免出现热点现象。随机森林由于其运算速度快、预测精准度高且应用范围广等优点,已广泛应用于各种算法和计算机等交叉学科。鉴于此,本文使用随机森林预测服务器未来能耗。OpenStack作为开源云平台的行业标准[6],能够提供可靠的云部署方案,目前国内外许多云计算企业都以OpenStack 作为云计算架构的基石。因此,本文使用OpenStack 作为云计算管理平台,管理云计算各种物理资源。
本文工作主要如下:①基于OpenStack 调度策略,通过使用随机森林获取预测服务器能耗参数,为虚拟机创建、迁移提供数据支撑,进而降低能耗,避免服务器出现热点现象;②针对预测不可避免地出现误差问题,本文设计了一种预测容错机制,避免由于预测误差过大而出现虚拟机不迁移/不必要迁移问题;③通过在服务器上进行负载实验,确定最优连续预测次数。同时,将能耗结果进行比较,实验结果表明,ECPRF 算法能将能耗控制在阈值以下,避免服务器热点现象出现。
1 相关工作
在预测方面,杨鹏史等[7]结合公交车实测GPS 数据,利用线性回归预测了公交的平均运行速度和运行模式分布,更适合面向大型公交车系统进行实时动态的排放能耗预测。郭树昌等[8]使用全球预报系统分析场数据,利用岭回归处理共线性数据,得到闪电潜势预报模型,预报命中率达0.75。顾艳文等[9]使用Lasso 回归方法对变量进行筛选,建立SVR 模型预测消费者信心指数,预测效果较好。
随机森林使用Bagging 的方法是将多个决策树组合在一起,以投票机制进行分类的有监督学习算法,它具有计算速度快、泛化能力强、分类性能好的优点[10]。
随机森林在预测方面应用较为成熟,刘兴等[11]对风力数据使用聚类分析,使用核主成分分析法处理特征数据,采用随机森林方法进行预测,降低了预测误差。闫政旭等[12]提出一种基于Pearson 系数的随机森林组合模型算法,该算法利用Pearson 系数删除无关特性,通过改进网格搜索法对决策树进行调优,最后通过随机森林进行回归预测,实现了对股票价格的短期回归。因此,本文使用随机森林方法对服务器未来能耗进行预测。
在云计算调度策略方面,邓志龙等[13]研究了在Open-Stack 中资源负载动态变化情况下的虚拟机迁移问题,通过衡量虚拟机与计算节点的匹配度选取节点,减少了迁移成本,降低了数据中心的能耗。罗平等[14]考虑到数据中心在部署大规模虚拟机时并未将全局能耗、服务器性能作为参考因素,于是设计一种基于动态平衡的双策略差分进化算法的虚拟机放置策略,在大规模创建虚拟机时,使数据中心总功率增加到最小,从而达到减少数据中心能耗的问题。PIAO 等[15]、Kantarci 等[16]将CPU、内存和带宽作为评估参数,提出混合整数线性规划(MILP)使功耗最小化,从而实现云数据中心资源的公平利用和能耗优化。Corradi等[17]提出一种动态迁移方法来平衡服务器资源,它仅使用CPU 利用率作为主机过载检测参数,不考虑虚拟机迁移后目标主机的未来状态。Yang 等[18]实现一个可以监控OpenStack 和OpenStack 上虚拟机实时状态的云基础设施,监控项目包括CPU 利用率、内存负载和功耗。此外,通过实时迁移实现节能。Pyati 等[19]提出一种在OpenStack 云中动态整合虚拟机的新方法,监控每个主机的CPU 利用率、RAM 利用率和实例数,使用SVM 分类模型执行主机过载检测并根据分类结果进行负载均衡整合。Khan 等[20]提出一种通过整合虚拟机、容器和容器化应用程序之前的有效迁移以降低数据中心能耗。
2 基于随机森林的能耗预测调度算法
本文所提出的基于随机森林的能耗预测调度算法(ECPRF)结构如图1 所示,主要分为3 部分:能耗采集、能耗预测、OpenStack 调度策略。其中,OpenStack 调度策略分为具有容错机制的虚拟机创建、虚拟机迁移两部分。

Fig.1 Flow of ECPRF algorithm图1 ECPRF算法流程
2.1 能耗采集
IPMI(Intelligent Platform Management Interface)是智能平台管理接口的缩写,用于带外管理计算机,使用IPMI 可以获取服务器当前能耗,如图2所示。ECPRF 算法使用IPMITOOL 中ipmitool sdr list 命令周期向服务器发送,并将服务器返回的能耗数据写入MySQL 数据库,并标注采集时间,构成服务器能耗数据集。
2.2 随机森林预测
随机森林采用BootStrap 方法对含有M 个样本的数据集有放回地随机抽取N(N≤M)个样本组成新样本,每一次的样本不完全相同,根据这些样本构建决策树,并在Bagging 的基础上对每棵决策树进行随机特征的选择,然后对测试集进行回归预测,对预测结果进行整合,投票得出最终结果。如图3 所示,在使用随机森林模型预测能耗变化的过程中,由于能耗为单变量数据,能耗值与时间相对应,特征数较少,体现不出特征的随机性,因此将能耗数据特征分为平滑特征和时间特征两大部分。其中,平滑特征是指将数据向前平移得到的特征,时间特征是根据日期等时间特性得到的特征。根据这些特征建立决策树进行回归预测,最后将得到的所有回归结果进行投票选择,投票最高的结果为最终模型输出。

Fig.2 Energy consumption acquisition process图2 能耗采集过程

Fig.3 Random forest prediction model图3 随机森林预测模型
2.3 OpenStack调度
本文使用OpenStack 作为云计算管理平台。OpenStack是一个免费的开源云计算平台,是Rackspace 和美国国家航空局(NASA)于2010 年合作开发。OpenStack 主要使用池化虚拟资源构建和管理私有云及公共云,用户通过Web界面、命令行工具或RESTful API 进行管理。OpenStack 中有关虚拟机创建及管理主要通过Nova 项目完成,在Nova中,各组件通过RPC 进行通信。Nova 主要是由API、Compute、Conductor、Scheduler 4 个核心组件构成,其中Nova-Scheduler 负责虚拟机调度相关策略。目前,Nova 实现了随机选择的ChanceScheduler 调度策略、过滤选择的Filter-Scheduler 调度策略、将主机资源信息缓存在本地内存的CachingScheduler 调度策略。Nova 支持自定义调度器,FilterScheduler 调度策略是通过服务器的硬件条件过滤筛选出符合条件的服务器队列,为了筛选物理资源符合虚拟机运行的服务器,本文使用基于FilterScheduler 的调度策略筛选硬件条件符合创建条件的服务器。通过外键将服务器基础数据与服务器能耗关联,使用Nova 中的BaseHost-Filter 类构建基于随机森林预测的调度算法。在硬件条件符合创建条件的服务器基础上筛选出未来能耗较低的服务器队列。
2.3.1 容错机制
尽管使用随机森林算法可提升预测精确度,但预测结果与真实值之间难免存在误差。考虑到预测结果存在误差,为防止出现误差过大而引起虚拟机迁移/不迁移情况,本文采取了连续预测的容错机制,即将预测时间分为连续的时间间隔,将最后一次时间间隔预测的能耗值作为服务器未来能耗值,若之前的时间间隔预测能耗值与服务器真实值相差无几,则认为最后一次时间间隔预测值是准确的。使用该容错机制可以有效避免由于预测值与实际值差距过大而引起的虚拟机错误迁移。
2.3.2 调度策略
服务器能耗越高,则服务器温度越高,进而造成了热点现象。通过设置能耗阈值,将能耗阈值作为服务器运行时的最高能耗,服务器能耗若超过能耗阈值则认为该服务器出现热点现象。将服务器能耗长期控制在能耗阈值之下,可以避免服务器热点现象出现。
ECPRF 算法的调度策略分为虚拟机创建和虚拟机迁移两部分。如图4 所示,在虚拟机创建时,首先获取每台服务器上的预测能耗值,筛选出低于能耗阈值的服务器队列,在此队列基础上选择符合创建所需资源且能耗最低的服务器,避免将虚拟机创建在高能耗服务器上。如图5 所示,ECPRF 算法周期性获取每台服务器预测能耗值,遍历服务器队列,将高于能耗阈值服务器中的虚拟机迁移至符合该虚拟机运行所需物理资源且预测能耗最低的服务器中。通过迁移虚拟机使服务器能耗长期处于能耗阈值以下,从而避免热点现象出现。
在虚拟机迁移过程中,ECPRF 算法使用OpenStack Live Migration(热迁移)方法,即虚拟机在运行状态下进行迁移,保证虚拟机中的任务不会因为虚拟机迁移而中断。迁移虚拟机个数由迁移后能耗下降范围决定。能耗下降计算可由式(1)表示:
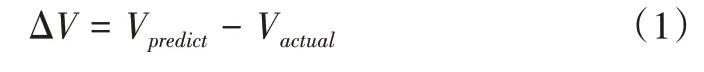
其中,ΔV表示能耗下降的最小范围,Vpredict表示预测能耗值,Vactual表示实际能耗。若迁移后能耗差值大于V,则停止迁移虚拟机。
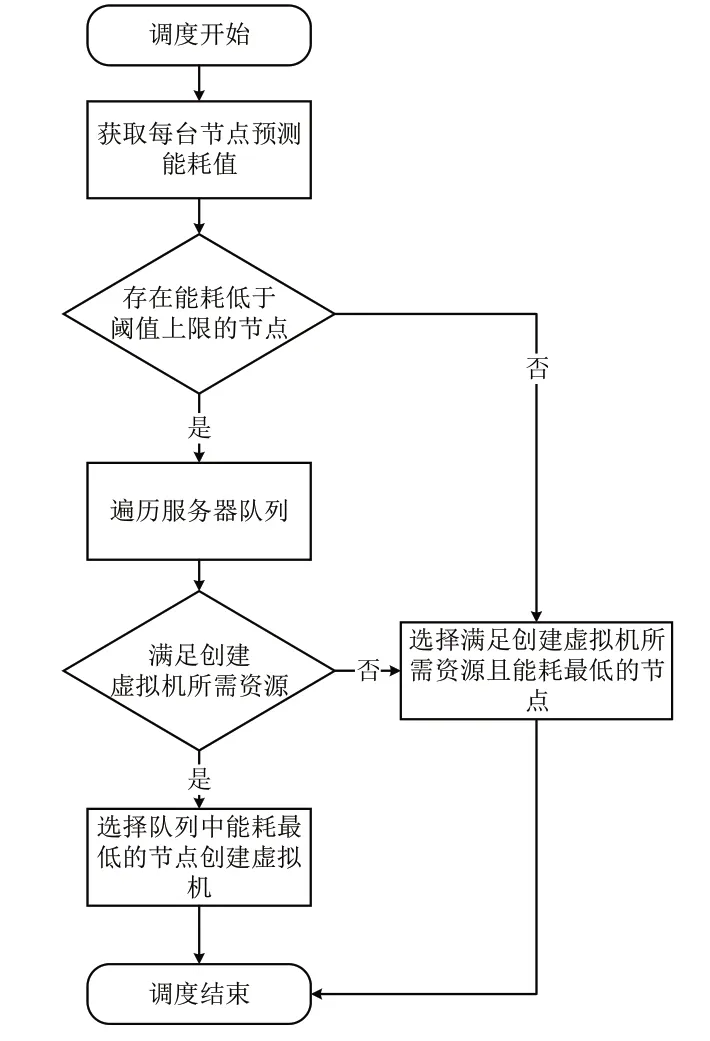
Fig.4 Virtual machine construction图4 虚拟机创建
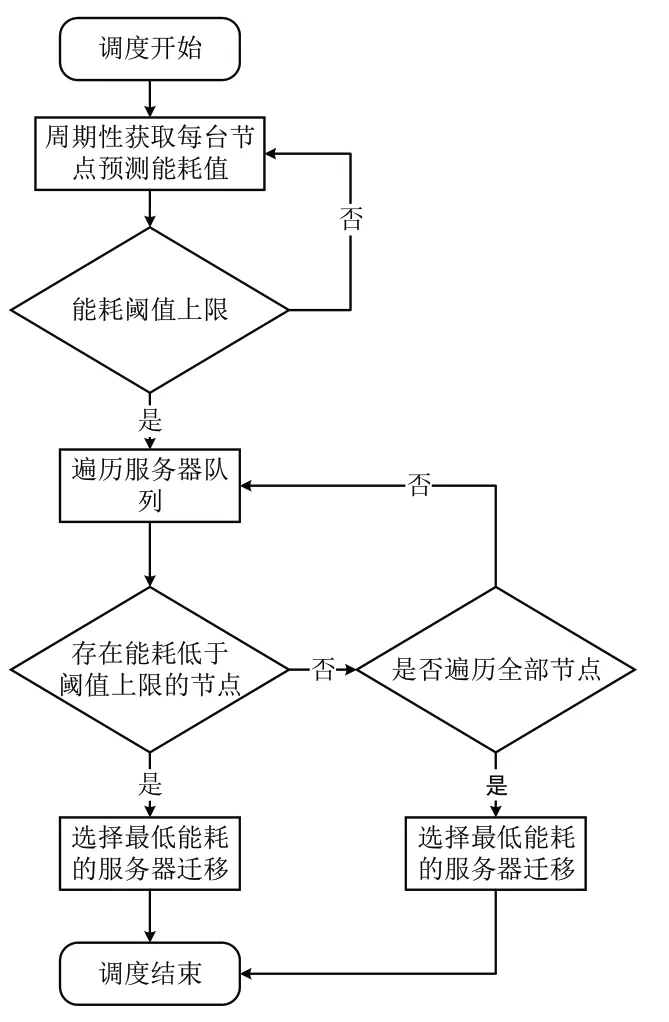
Fig.5 Virtual machine migration图5 虚拟机迁移
3 实验分析
3.1 实验环境与数据集
3.1.1 实验环境
本次实验在国家超级计算济南中心研发云平台进行,实验选取4 台曙光A620-G30 服务器作为计算节点。采用对照实验的方式,将服务器分为两组,每组两台服务器。一组使用ECPRF 算法,节点名称为node1、node2。一组使用OpenStack 基础调度策略,节点名称为node3、node4。计算节点配置详细参数和节点拓扑图如表1、图6所示。

Table 1 Server configuration表1 服务器配置
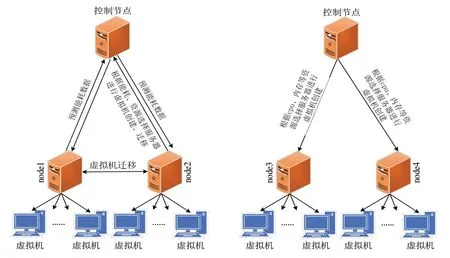
Fig.6 Testbed topology architecture图6 测试环境拓扑架构
3.1.2 实验数据
本文对不同负载下的服务器进行监控,每5 分钟收集一次服务器能耗数据,如表2所示。
3.1.3 实验数据处理
(1)数据清理。node 属性对预测结果无影响,在建模时删除node 属性,使能耗数据变为时间—能耗的单变量数据。通过pandas 库中的to_datetime()函数将时间参数转换为时间格式。
(2)数据集划分。由于数据集为时间序列型,为了防止破坏时间顺序,将数据集按照时间顺序以7∶3 的比例将其划分为训练集和测试集。
(3)特征建立。处理后的能耗数据为单变量数据,将特征分为平滑特征与时间特征,平滑特征是指将能耗值向前做平滑,时间特征为每分钟均值、每小时均值、工作日均值和周末均值。具体名称和含义如表3所示。
3.1.4 评估函数
为了评价模型精准度,本文使用平均绝对误差(MAE)和R 平方得分(R2_score)对预测结果进行分析。评价指标计算如下:

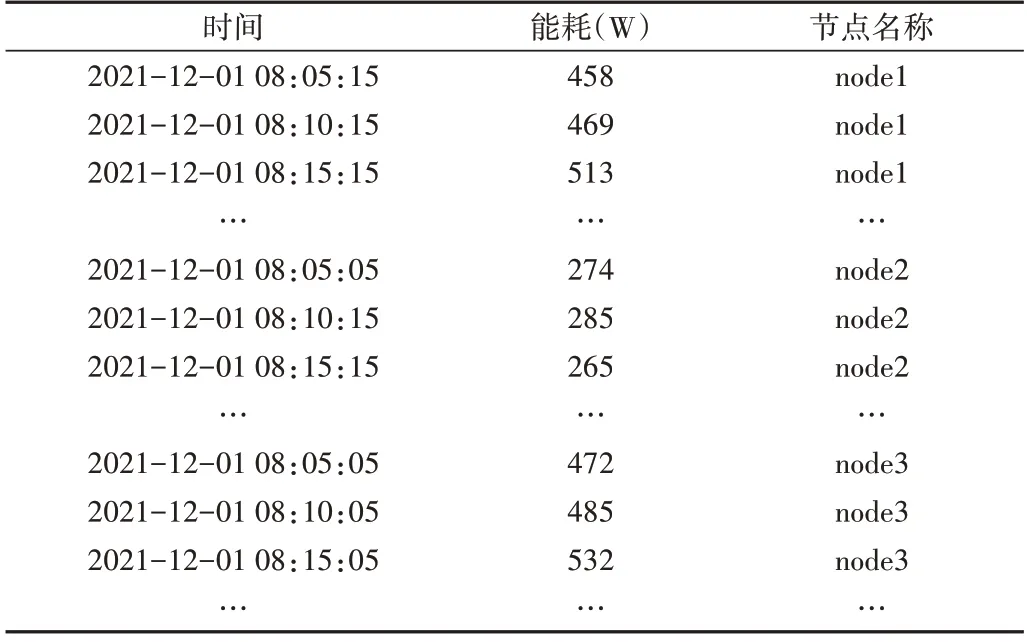
Table 2 Energy consumption data set sample表2 能耗数据集样例

Table 3 Data set characteristics表3 数据集特征
3.2 实验方法
对数据集分别使用随机森林、线性回归、岭回归、LASSO 回归模型进行预测,并对预测结果进行验证评估,证明使用随机森林进行预测的准确性。同时设置对照组,通过两组的服务器能耗变化,证明ECPRF 算法避免服务器出现热点现象的有效性。具体实现方法如下:①对能耗数据进行处理,构建符合要求的数据集;②通过调用训练集完成对随机森林模型的训练,并对预测效果进行分析,判断预测的精准度并与同等条件下使用线性回归、岭回归、LASSO 回归模型进行比较;③根据预测结果对超过能耗阈值的物理机执行虚拟机迁移处理;为了确定最优的连续预测次数,将预测次数分为3 次、4 次、5 次,每次时间间隔为5分钟,则预测10 分钟、15 分钟、20 分钟后的能耗变化,同时设置可接受预测能耗误差范围为20,寻找最优预测次数。若之前预测结果正确,采用最后一次预测能耗作为该服务器未来能耗。若出现预测错误,则将出现错误时间下服务器的实际能耗值与能耗阈值进行比较,如果超出阈值上限,则进行虚拟机迁移操作;④设置对照组,在node1 与node3 上创建14 台相同的虚拟机,每台虚拟机都是有8 核CPU、16GB 内存、40GB 磁盘组成,操作系统为Ubuntu 18.04.5。在node1与node3运行相同程序以产生相同能耗,node2 与node4 不创建虚拟机。设置能耗阈值上限为800。运行一段时间后,对比两组节点能耗变化情况。
3.3 实验结果
3.3.1 各模型误差比较结果
各模型在该数据集上的平均绝对误差和R 平方得分结果如图7-图8 所示。可以得出,在MAE 中,从测试集的预测结果来看随机森林模型的预测精度最高,MAE 仅为9.94,而线性回归、岭回归、LASSO 回归分别为69.61、43.22、54.86;在R2_score 中随机森林依旧得分最高,预测精度达0.99,最差是线性回归,得分仅为0.71。结果表明,随机森林预测精准度最高,因此使用随机森林模型进行预测。
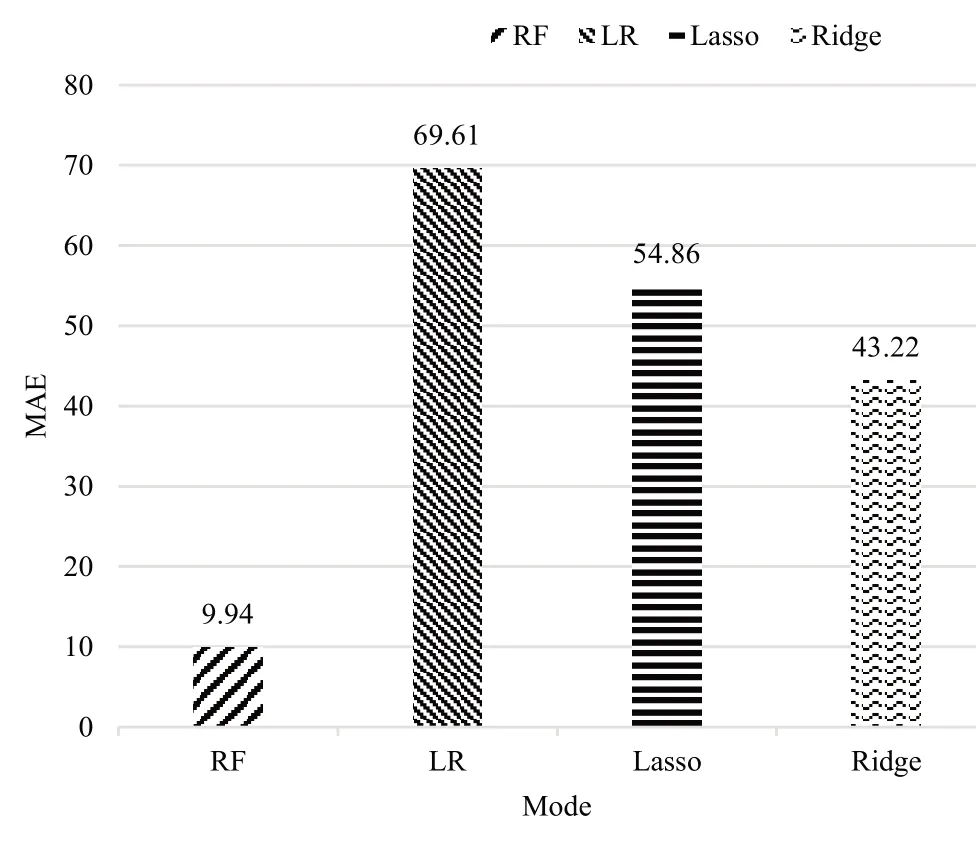
Fig.7 Comparison of MAE图7 平均误差结果比较

Fig.8 Comparison of R2图8 R2结果比较
3.3.2 预测结果比较
使用随机森林模型对经过预处理和转换后的测试集数据进行预测,预测结果和实际结果如图9 所示。可以得出,在小幅度震荡时会影响预测精准度,但是在整体上随机森林模型可以很好地预测数据,预测的服务器能耗和实际服务器能耗曲线趋势相吻合。因此,随机森林预测模型在预测服务器能耗上是可行的。
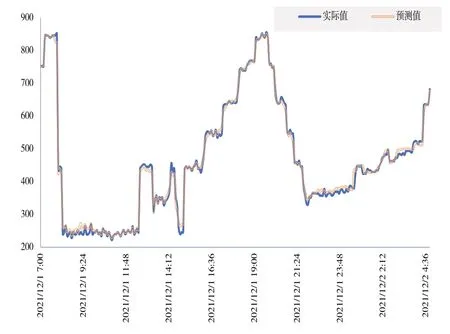
Fig.9 Comparison between predicted with the actual results图9 预测结果与真实结果比较
3.3.3 容错机制预测次数分析
设定能耗误差范围为20W,对于连续次数预测利用网格搜索法在[3,4,5]范围内进行实验分析。如表4 所示,当预测连续次数为3 次时,预测100 次和1 000 次的正确率均为100%,而预测连续次数为4 次、5 次,预测正确率逐步降低。因为随着预测时刻和当前时刻距离的增大,当前时刻数据对预测结果的影响越来越小,导致误差越来越大。当误差超过预设范围时,即认定模型预测失败。因此,本文设定连续预测次数为3。

Table 4 Prediction accuracy under different times of prediction表4 不同预测次数下的预测正确率
3.3.4 ECPRF算法有效性分析
图10 为各节点能耗值。node1 能耗为683,node3 能耗为875。node2 能耗为432,node4 能耗为234。由于能耗值超过设定阈值上限,node1 使用随机森林预测将虚拟机提前迁移至node2,导致node2 能耗上升,node1 能耗保持在阈值以下,而node3 高于阈值,出现热点现象。图11 为node1 与node3 在一天内的最高能耗变化情况,node1 能耗维持在能耗阈值以下,而node3 能耗超出能耗阈值,node3出现热点现象。综上所述,ECPRF 算法能有效避免服务器出现热点现象。
4 结语
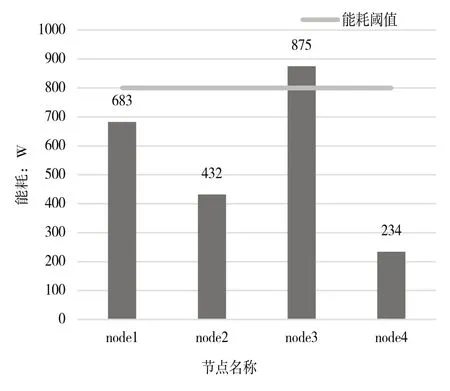
Fig.10 Node energy consumption图10 节点能耗值
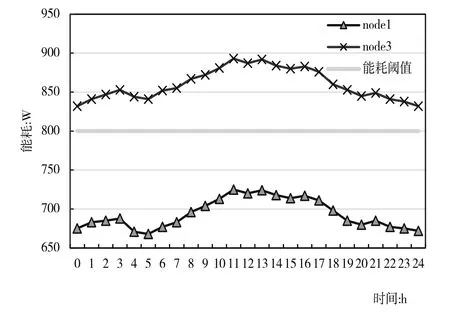
Fig.11 Node energy consumption change图11 节点能耗变化
本文针对服务器出现的热点现象,提出了一种基于随机森林的能耗调度算法(ECPRF)。ECPRF 算法首先根据一段时间内的能耗构建时间序列向量,然后以时间—能耗序列作为输入,使用随机森林模型预测未来服务器能耗变化,最后根据未来服务器能耗进行虚拟机迁移,避免出现热点现象。本文分别使用线性回归、岭回归、LASSO 回归进行预测对比,证明了使用随机森林模型预测的准确性。同时,将ECPRF 算法与OpenStack 提供的算法进行对比,证明ECPRF 算法在保持服务器能耗稳定、避免出现热点上具有较好有效性。
