面向智慧文博的知识图谱构建综述
2022-05-26张浩然
赵 卓,田 侃,张 殊,张 晨,吴 涛,张浩然
(1.重庆中国三峡博物馆文物信息部,重庆 400015;2.重庆邮电大学网络空间安全与信息法学院,重庆 400065)
0 引言
随着社会经济的发展和生活水平的不断提高,人们越来越重视精神生活,也更加有条件享受丰富多彩的精神文化产品。博物馆是征集、典藏、陈列和研究自然遗迹和人类文化遗产的场所,拥有大量具有科学性、历史性和艺术价值的物品,能够为公众提供知识、教育和公益性文化服务[1]。如何让文物活起来,使博物馆成为公共文化服务体系的重要载体,成为大众终身学习的精神课堂,是近年来社会对博物馆行业的普遍期望,也是博物馆行业的重要工作方向。如何更好地挖掘传播地区历史文化、创建具有吸引力的文化产品以及提供良好的公共文化服务是博物馆工作的重要诉求。
围绕文博行业现状以及社会实际需要,我国频繁出台文物保护和博物馆建设的政策,使文博行业能更好地服务于国家文化发展需要,满足人民群众精神文化需求。2015年2 月,国务院发布了《博物馆条例》,鼓励博物馆向公众免费开放。2016 年3 月,国务院印发的《关于进一步加强文物工作的指导意见》倡导大力发展文博创意产业。2017年4 月,文化部出台《文化部“十三五”时期文化科技创新规划》,提出要实现我国文化、艺术与科技的融合。实际上,通过近20 年的信息化建设,博物馆数字资源数量、质量稳步上升,藏品资源、藏品管理、多媒体展示、专用业务系统等均取得了不斐成绩。然而,随着大数据、人工智能等新兴技术的出现,科技与文化融合成为博物馆领域新的发展趋势,智能化技术应用成为未来博物馆发展的必由之路。
知识图谱以结构化的形式描述客观世界中概念、实体间的复杂关系,提供了一种高效组织、管理海量信息的方式。传统的图像、语音等人工智能领域主要关注感知智能,而知识图谱的重点在于通过知识与模型的融合实现认知推理,支持高水平的知识表示与计算。目前,知识图谱通过与问答、搜索、推荐等应用相结合已被广泛应用于金融、医疗、电商等领域。为显著提升文化遗产传承能力,本文聚焦适合博物馆的知识图谱系统构建问题,首先对文博领域知识图谱系统的构建过程和方案进行概述,然后介绍知识图谱构建的主要流程和关键技术,最后对未来值得关注的研究方向进行初步探讨。
1 文博知识图谱研究现状
知识图谱在文化、博物馆领域的应用处于起步阶段,取得了一定研究成果。例如,张建星[2]研究了基于大数据环境的中国传统文化知识图谱构建框架,设计了由事件、人物、时间、地点、社会背景、文化领域六元组组成的中国传统文化本体模型,构建了中国传统文化知识库;万静等[3]介绍了知识图谱在国内外的研究应用情况,探讨了其在智慧博物馆建设中的初步应用设想;张娜[4]针对当前文物知识图谱依赖于人工构建、缺乏自动化方法的问题,对文物知识图谱构建过程中的文物关系自动抽取技术进行了研究,设计并实现了完整的文物知识图谱构建与展示方案;刘芳等[5]设计了以藏品、多媒体、展览、项目、人员、机构、文献等实体为核心的知识图谱,探讨了知识图谱在检索优化、智能推荐、可视化展示和智能问答领域的应用方式;杨伟强[6]以山西博物院专家选取的100 件具有代表性的馆藏文物作为构建知识图谱的基础性文物扩展相关知识节点,通过与领域专家合作,提出用于知识表达的本体模型和标准规范,采用构建文物知识图谱的形式形象地展示文物知识的结构及其之间的联系;刘绍南等[7]提出利用文物知识图谱对不同来源、不同格式的海量文物数据进行分析、展示和利用,然后基于语义检索、推荐和问答开发等典型应用支撑智慧博物馆的建设。
2 系统架构与知识建模
2.1 系统架构
以文博知识图谱构建为目标,聚焦人物、文物、遗迹、建筑、交通、书画等数据,在收集相关古籍资料、研究成果、学术文献、网络资源等基础上,综合利用自然语言处理、数据挖掘、深度学习以及图计算等技术进行数据分析与知识抽取,整体知识图谱系统构建框架如图1 所示。具体阶段介绍如下。
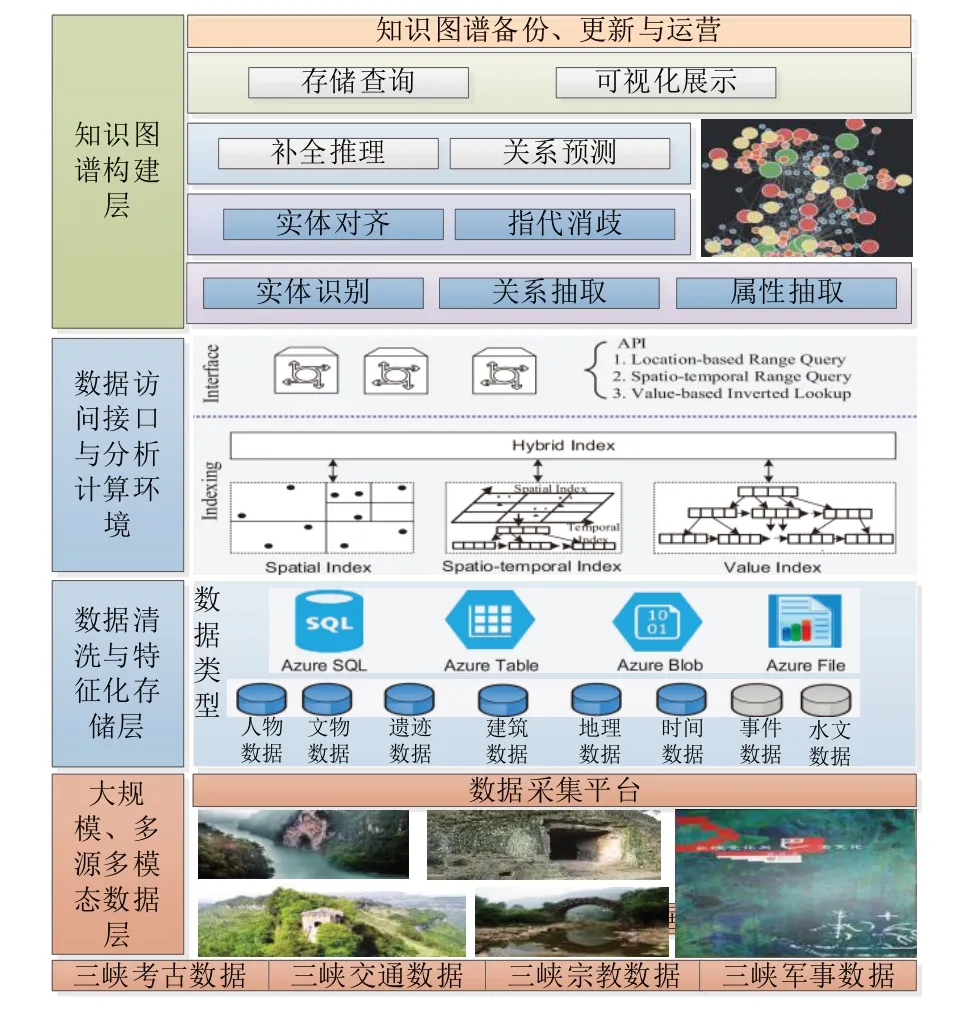
Fig.1 Framework of knowledge graph cultural museum system construction图1 文博知识图谱系统构建框架
(1)数据存储与访问架构设计。数据采集平台能够获得大量来自考古、交通、宗教等不同领域的文博数据,这些数据往往具有来源广泛、规模庞大、种类繁多、非结构化等特征,现有平台的存储方式无法很好地支持如此复杂数据的高效查询和分析。如果孤立地管理这些数据,会直接影响平台运作效率和效果。因此,除了对每类数据单独索引外,还需要对多源异构数据进行特征学习,建立混合式索引,以提高数据访问效率。
(2)知识特征提取。针对考古、交通、军事、宗教等不同领域的数据,通过自然语言处理、机器学习领域前沿理论模型,构建多源异构数据的知识特征提取与融合方法,进行文化数据的知识抽取,将多源异构数据转化为统一的知识表达形式。
(3)知识库构建。根据数据的结构特征,在数据库知识抽取的基础上,建立文化数据知识表达模型,对文物、环境、历史文献、考古资料、历史事件等海量、多源、异构的文化数据进行规范化组织,使文物知识可检索、可计算、可自动关联,形成文化数据标准知识库。
(4)文化知识图谱构建关键技术研究。研究实体识别、关系抽取、实体链接、推理补全、语义消歧等理论与技术,为知识图谱系统的构建提供理论与技术支撑。同时,分析面向知识图谱构建文博数据的特性问题,展开针对性研究以突破技术瓶颈。
(5)知识图谱系统构建。遵循统一、集约、高效、规范的原则,构建允许知识检索、关联挖掘、可视化呈现的知识图谱系统,支持可移植、跨平台、可配置的需求,自动抽取半结构化文本中的属性和值,实现知识审核与校对,形成知识图谱更新管理机制,建立运营管理体系。
2.2 知识建模
文博知识图谱构建以古籍资源、学术文献、文物信息等数据资源为依托。文物资源包含石刻、建筑、书画、交通、军事、考古等,各类文物有相关的金石著录、发掘报告、研究论文、著作等材料对其进行描述介绍,每个文物都具有差异化的属性、特质。古籍资源往往以神话传说、历史事件、民间故事等形式介绍历史知识文化,具有故事差异性大、内容庞杂的特点。著名人物数据包含出生于或曾到过各个地区的书画家、诗人,以及与之相关的交通、军事事件等。文化旅游数据包含著名地点以及与之相关的历史事件、名人等,涉及文物、古籍、历史和名人等信息。基于以上内容分析,文博数据知识表达模型如图2所示。
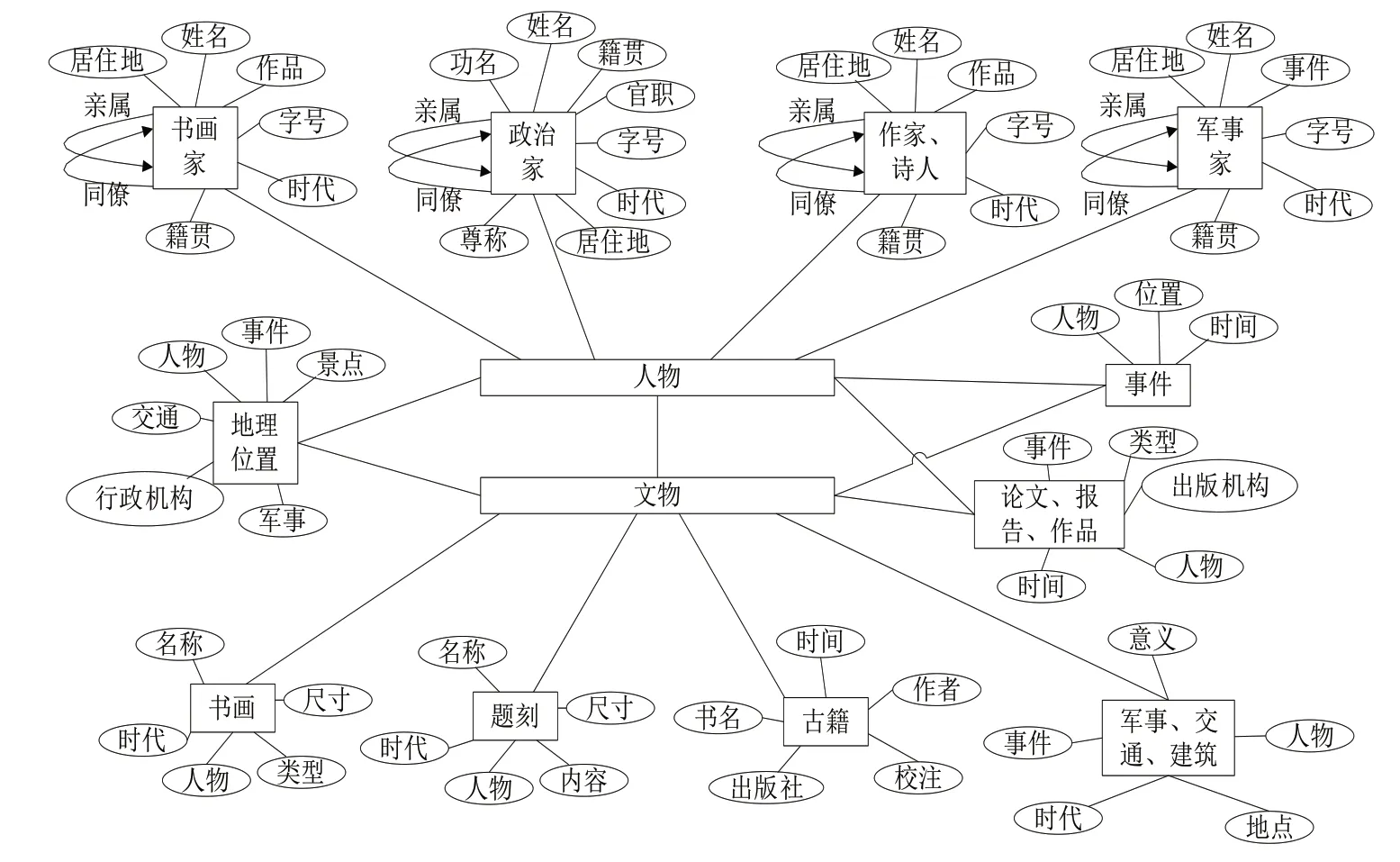
Fig.2 Cultural data knowledge representation model图2 文博数据知识表达模型
2.3 数据组织与处理规范
为了进行文博题刻知识图谱的构建,本文收集整理大量历史文化数据,其中题刻数据示例如图3 所示,其文字内容为:“涪江石鱼,镌于波底,现则岁丰。数千百年来,传为盛事。康熙乙丑春正,水落而鱼复出。望前二日,偕同人往观之,仿佛双鱼莫蓂莲隐跃。盖因岁久剥落,形质模糊,几不可问。遂命石工刻而新之,俾不至湮没无传,且以望丰亨之永兆云尔。时同游者旧黔令、云间杜同春梅川,州佐、四明王运亨元公,旴江吴天衡高伦,何谦文奇,西陵高应乾侣叔,郡人刘之益四仙,文珂奚仲。涪州牧旴江萧星拱薇翰氏记略。”

Fig.3 Example of Xiao Xinggong reengraving double fish rubbing图3 萧星拱重镌双鱼记拓片示例
可以看出,文博数据具有较强的历史性和专业性特征,传统的知识图谱技术无法直接应用于文博数据处理,需要设计合理的文博知识图谱构建方案。在查阅相关文博资料的基础上,综合分析不同数据组织形式的优缺点,设计用于文博知识图谱构建的数据组织与处理规范,如图4 所示。总体来说,基于关系型数据库实现结构化数据的简单、高效检索,基于实体、关系与属性抽取技术实现数据的结构化处理,基于图数据库实现复杂关联数据的存储与检索。通过该数据组织与处理规范,可以对文博数据资源进行预处理和标准化存储,以支撑数据的知识表达与高效计算。
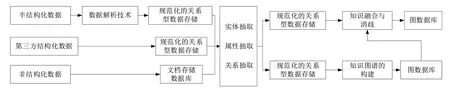
Fig.4 Data organization standard for the construction of cultural relic knowledge graph图4 文博知识图谱构建的数据组织与处理规范
3 文博知识抽取方法
3.1 命名实体识别
命名实体识别(Named Entity Recognition)又称为实体识别,其对知识图谱的构建具有重要意义。命名实体是一个词或短语,命名实体识别是指在输入文本中识别具有特定属性的实体。在文本被识别为实体后,开发人员可以对不同类别的实体执行各种操作。传统的命名实体识别方法主要包括基于规则的方法、知识库方法、监督学习方法和半监督学习方法。早期由于计算能力限制,知识库方法和基于规则的方法被广泛使用,多通过维护专门的词典库或由专家根据专门词汇的特点构建规则以识别命名实体。一般来说,每个规则都有一个权重,发生规则冲突时,权重最高的规则用于确定命名实体的类型。基于规则的实体识别系统通常需要使用实体字典进一步确认候选实体。当字典内容详尽时,基于规则的系统运行良好。然而,基于特定领域和不完备字典的规则往往导致命名实体识别系统召回率低,且这些规则难以适用于其他领域。近年来,机器学习被广泛应用于各种自然语言处理任务中,并取得了巨大成功。与知识库和基于规则的方法相比,机器学习方法减少了大量人工干预,具有优越的可移植性。基于机器学习模型的命名实体识别方法会预先标记语料库作为训练集,并通过训练模型学习相关特征识别实体。
知识图谱命名实体识别中最具代表性的方法为BERT预训练模型[8-9]和Bi-LSTM 与CRF 的融合模型[10-11]。Bi-LSTM 与CRF 的融合模型是在Bi-LSTM 的条件上加了一层条件随机场作为模型的解码层,以预测结果的合理性。同时,由于文博数据的专业性和特殊性,基于常见标记语料库的实体识别模型无法完全有效识别数据中存在的文物、古籍、年号、官职等专业术语与历史名称。因此,本文通过爬虫、文本分析等方法构建功名、官职、年号、节日等专有名词库,示例如图5 所示。然后,结合基于知识库和算法模型的方法进行命名实体识别,从而支撑文博领域实体信息的准确识别与发现。
3.2 知识图谱关系抽取

Fig.5 Example of proper nouns for official positions图5 官职专有名词库示例
关系抽取(Relationship Extraction)是指在命名实体识别之后,根据句子中的语义信息学习实体间的关系。准确的关系抽取有利于构造逻辑结构清晰的图谱[12-13]。基于规则的关系抽取方法通过语言学知识对文本结构抽象出一个固定的模式集,并对给定的文本进行模式匹配以确定其中关系。总体上,传统的关系抽取方法需要大量人力设计特征,难以应用于大规模的关系抽取任务。近年来,基于深度学习的关系抽取模型被提出,其可自动学习有效的关系特征。目前主流的深度学习关系抽取方法包括基于卷积神经网络模型的关系抽取方法[14-17]、基于循环神经网络模型的关系抽取方法[18-20]以及基于词法句法模型的关系抽取方法[21-23]。然而,深度学习模型往往需要大量已标记训练数据。为解决训练数据短缺问题,降低模型训练成本,远程监督(Distant Supervision)模型方法被提出[24]。此外,为降低命名实体识别错误对关系抽取准确率的影响,实体关系联合抽取方法[25-27]被提出。
为进行文博数据中实体关系的准确抽取,本文提出基于规则的方法以及基于正反向迭代式消除的方法。文博数据中书名、字号等信息往往标识性强、规则清晰,在获取人名、地名等实体的基础上,基于简单规则即可准确发现人物字号、官职等关系信息。而对于语句中的复杂关系,本文提出首先进行实体和属性识别与消除、然后在剩余内容中正、反双向识别语义关系的迭代式解决方案。
3.3 知识图谱关系推理
知识图谱关系推理(Relationship Inference)是指基于已有的知识图谱结构和内容信息推理出新的知识或识别错误知识的过程,可解决文博领域数据稀疏的问题,并削减数据质量不高对知识图谱准确率和完整性的影响。知识图谱关系推理方法主要包括基于规则的方法、基于结构相似性估计的方法、基于结构建模的方法以及基于知识表示的方法。其中,基于规则的关系推理主要通过文博数据本体模型中的相关约束和规律进行推理;基于结构相似性估计的方法主要包括共同邻居方法、资源分配方法、局部路径法等;基于结构建模的关系推理方法借用网络数据分析领域的模型算法,包括标记传播(Label Propagation)方法、随机行走(Random Walk)方法、图神经网络模型(Graph Neural Networks)等;基于知识表示的方法首先对知识图谱中的实体和关系进行降维表示,然后基于表示结果直接计算实体之间存在关系的可能性。知识表示学习方法通过机器学习算法自动从数据中获得知识表示,能够根据具体任务学习到合适的特征。目前,最具代表性的知识表示方法包括TransE[28]、TransH[29]、TransR[30]以及TransD[31]。
本文提出不同显著性的文博知识图谱关系,采用结构相似性估计方法、图神经网络模型方法以及基于卷积特征表示的少样本学习方法进行知识图谱的关系推理。具体来说,对于局部性、显著性强的潜在关系,采用结构相似性估计方法进行预测;对于大范围的复杂结构关系,基于图神经网络模型方法进行结构建模和学习,然后利用学习到的结构模式指导潜在关系的推理预测。由于知识图谱中的关系往往存在长尾现象,即关系数量主要集中在少数几种类型上,其他类型的关系数量较少,不利于建模学习,本文提出基于少样本学习的知识图谱关系推理方法。
4 基于Neo4j的知识图谱构建
知识图谱数据应用的前提是关联数据的有效表示和存储,其数据模型主要分为三元组和图模型两种[32]。图数据库因其对节点间复杂关系的良好支持而成为多数知识图谱的首要存储选择。
图数据库中,数据的基本元素包括节点集合与关系集合。关系型数据库能够较好地凸显单条数据的内容和存储情况,而图数据库以非结构化的方式存储关联数据,可以直接显示数据的关联特征,在知识图谱关系查询中效率更高。目前代表性图数据库包括Neo4j、JanusGraph、GraphDB、HugeGraph 等[33]。本文选择能够轻松表示关联数据的Neo4j,其操作简便灵活。基于Neo4j,本文构建的部分知识图谱结果如下。
示例1:与“进士”相关的人物包括“刘心源”“赵熙”“寇凖”“陈文烛”“庞恭孙”等,其中每个人物又有相关的实体和关系。例如,人物“寇凖”涉及到书籍《十朋梅溪后集》以及官职“校书郎”,由此形成了以“进士”为中心的知识图谱,具体如图6所示。

Fig.6 Knowledge graph centered on"Jinshi"图6 以“进士”为中心的知识图谱
示例2:与“萧星拱观石鱼记”直接相关的人物包括“萧星拱”“陈曦震”等,其中每个人物又有相关的实体和关系。例如,人物“萧星拱”涉及到书名《清萧星拱传记》以及官职“郡守”,以“萧星拱观石鱼记”为中心的知识图谱如图7所示。
5 文博知识图谱的应用与管理
5.1 知识图谱的应用
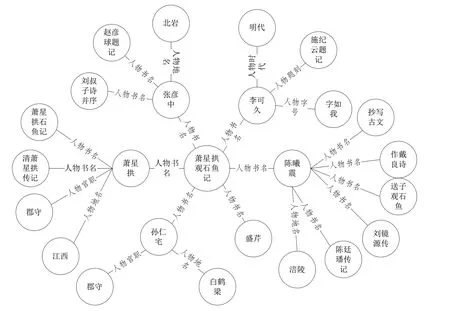
Fig.7 Knowledge graph centered on"Xiao Xinggong view stone fish"图7 以“萧星拱观石鱼记”为中心的知识图谱
知识图谱是融合数据与算法的新型知识表达形式,其可将数据中的知识组织成<主,谓,宾>三元组的形式以表征客观世界中实体之间的关系[34]。基于知识图谱的可视化技术可以构建直观的数据展示系统,优化用户交互体验;基于知识图谱的推荐系统可以利用图谱中的关系推理用户的兴趣偏好,同时支持对推理过程和推荐结果的解释;基于知识图谱的搜索避免了传统机械的关键词匹配搜索形式,能够根据人们的思考习惯检索查询相关信息,给出直接的答案;基于知识图谱的问答系统能够将问题逻辑解析到知识图谱中,通过推理计算直接给出问题答案。
文博知识图谱构建的主要目标是解决长期以来文博领域旧拓资料散落各地而无法形成一套完整体系的问题。收集、整理特定主题的数据资料,通过数据清洗、整合以及知识图谱构建,自动化形成较为完整的知识体系,有助于文化遗产的科学发掘[35]。同时,通过知识图谱构建以及可视化展示,能使观众直观地了解历史文化知识,提升其观感体验,更好地传播历史文化知识。具体示例如图8所示。

Fig.8 Example of visualization for cultural knowledge graph图8 文博知识图谱可视化展示示例
5.2 知识图谱的运营管理
知识图谱的运营管理是指在知识图谱初次构建完成后,根据用户的使用反馈以及不断出现的新知识进行知识图谱演化和完善的过程,更新过程中需要保证知识图谱的质量可控以及内容丰富衍化。
知识图谱的运营管理是一个体系化工程,覆盖了知识获取到知识计算的整个生命周期。知识图谱的运营主要有两个关注点:一个是基于增量数据的知识图谱构建过程监控,另一个是通过知识图谱的应用发现知识错误和新的业务需求,例如错误的实体属性值、缺失的实体间关系、未识别的实体、重复实体等问题。总体来说,知识图谱运营管理需要用户反馈、专家修正、运行监控、算法调整更新等相结合,是一个人机协同、领域专家与算法相互配合的过程。
6 结语
作为人工智能的重要应用之一,近年来知识图谱受到各个领域的广泛关注。文博系统是国家精神文明建设的重要领域,如何结合前沿科技实现文化创新成为其当前面临的重要问题。文博领域数据资料体量庞大且零散,文博知识图谱的构建对于博物馆的智能化建设、智慧文化产品开发具有重要支撑作用。然而,相关学者虽然对知识图谱的理论与应用问题进行了研究,但针对文博知识图谱构建的研究仍然较少。
本文剖析了文博知识图谱的背景、内涵及发展现状,提出了基于多源文化数据进行文博知识图谱构建的系统架构、知识模型以及组织规范,基于实体识别、关系抽取、关系推理等关键技术展示了基于图数据库的知识图谱构建方法,然后介绍了知识图谱的应用以及现实运营管理问题。需要注意的是,由于文博领域数据的专业性与稀疏性,直接应用常规知识图谱关键技术往往不能获得满意结果。例如,前期本文进行了DeepDive 等知识图谱构建工具的测试,但结果并不令人满意。因此,文博知识图谱构建需要结合文博数据特征进行针对性的理论与技术研究。为了面向文博知识图谱的特征提出针对性解决方案,同时保留进一步创新优化的可能性,本文给出了文博知识图谱构建的初步技术并基于相关前沿算法进行了实现与优化,未来将在此开放式方案的基础上进一步优化与提升。
