融合LDA主题和Doc2vec算法的DeepFM模型的 推荐算法研究
2022-05-25刘伦珲吴丽萍
刘伦珲,吴丽萍
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
随着5G时代的序幕渐渐拉开,大数据流如同潮水一般涌入人们的生活,其中包含大量不同领域的专业知识和信息。用户需要一种辅助工具,帮助他们从这些专业或者冗余的信息中筛选推荐得到符合用户个性的产品或内容。目前为了得到准确的个性化推荐信息,依旧存在一些问题需要去解决,如在分析用户历史评论内容时,由于每条评论的长短不同,评论的方式不同。传统的机器学习方法如协同过滤并不能很好地理解评论获得更准确的推荐结果。因此辅助决策算法需要更好地去挖掘评论中的特征,理解评论中的上下文信息。
为了得到评论中用户的情感极性,YIN ZHANG等人在文献[1]中提出了一种为情感打分的方法,根据情感词汇表对每一条评论进行打分,从而得到每一条评论的情感状态。为了更好地挖掘数据中的深层和表层的信息,Google公司提出了Wide&Deep模型,其核心思想是结合广义线性模型的记忆能力和深度前馈神经网络模型的泛化能力,利用广义线性模型从数据中学习特征相关性,再通过深度神经网络结构去挖掘隐藏特征。但如CHEN J 等人在文献[2]中所说,Wide&Deep模型在wide part部分的数据输入依旧需要专业人工特征工程。为了使模型能够更好地考虑数据中特征组合交叉的影响并且不需要人工特征工程,GUO H等人在文献[6]中提出了DeepFM模型,可以更快地训练并且更精确地学习。为了让模型能够更好地应用在医疗信息推荐领域,本文提出一种在DeepFM模型的基础上融合了狄利克雷分配(Latent Dirichlet Allocation,LDA)主题模型和Doc2vec算法的方法。实验表明,这种方法能较好地应对数据冷启动问题,并且有较好的推荐性能表现。本文以真实的医疗评论数据集为例,验证了所提出的改进DeepFM算法的优越性。
1 融合LDA主题模型及Doc2vec算法的DeepFM模型
1.1 主题模型
主题模型是针对文本数据中的隐藏主题的一种建模方法。以一条评论文本来说,可能以不同的概率包含了多个不同的主题,而每个主题中又以不同的概率包含着许多个不同的单词词汇。主题模型本质上起源于向量空间模型,将文本映射到向量空间中,可以更加方便地进行操作和计算相似度等。为了能更好地挖掘出医疗评论中的隐藏主题特征,本文采用了主题模型中的狄利克雷分配(Latent Dirichlet Allocation,LDA)方法。
1.2 LDA主题模型
狄利克雷分配(Latent Dirichlet Allocation,LDA) 是由BLEI等人在文献[3]中提出的一种主题生成模型,通过无监督学习的方法发现文档中隐藏的主题信息。一条文本评论可以看成一组有序的词序列,而文本的生成过程可以简单地理解为三步:首先对于每一篇文档从主题分布中抽取一个主题,其次从上述被抽到的主题所对应的单词分布中抽取一个单词,最后一步就是重复上述过程直到遍历文档中的每一个单词。LDA概率图模型表示如图1所示,可以看出,LDA为一个三层的贝叶斯模型。其中,K为假定的主题数,α为每篇文章的主题分布的先验分布参数,β表示K个主题的词分布,θ是一个m×K(m为文档个数)的矩阵,表示文档的主题分布,z表示文档中的词语被分配的主题向量,W表示文档中的词语。

图1 LDA概率图模型表示
首先选择一个主题分布向量θ,得到每个主题被选择的概率,在生成每一个单词的同时从主题分布向量θ中抽取一个主题Z,按照主题Z中单词的概率分布生成一个单词。因此在给定先验参数α和ϕ的前提下,LDA联合概率分布的公式如式(1)所示:
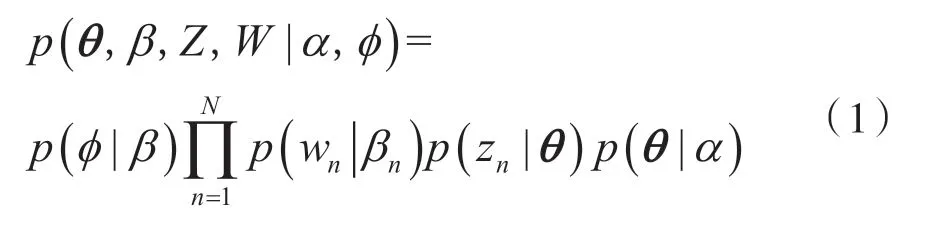
根据式(1)可以估计出θ和β的值,而本文的实验需要用到的参数是主题分布向量。
将主题数K设置为10,利用LDA对yelp医疗评论数据进行建模,将医疗评论划分为10个隐藏主题。表1为划分出的十个隐藏主题中概率最高的9个关键词。根据关键词可以对每一个隐藏主题进行合理的解释。

表1 K=10时LDA挖掘隐藏主题情况
由表1中的关键词可知,10个隐藏主题大体为:(1)眼部医疗服务;(2)预约等待时间;(3)运动护理损伤康复;(4)保险;(5)口腔牙部护理; (6)医院医药基础设施环境;(7)专业的医疗水平,友好的服务态度;(8)手术及手术护理;(9)按摩,放松,减压;(10)美容,女性皮肤护理。

表1 几种方法的均方差比较
1.3 Doc2vec算法
LDA主题模型虽然能够挖掘到医疗评论中的隐藏主题和特征,但在实验中发现由于每一次生成的隐藏主题不同,使得这种方法很难调整。当挖掘到的隐藏特征不够好时,会使最后的推荐准确度降低。为了让模型的性能更加稳定,本文利用Doc2vec方法来保留更多表层特征和信息,使模型更好地理解评论的语义。
Doc2vec又叫做段向量(Paragraph Vector),是由MIKOLOV在文献[4]中基于word2vec提出来的。Doc2vec是一种无监督的学习方法,可以使用不同句子长度的数据作为训练样本,最终目标是用预测的向量来表示不同的文档。Doc2vec的训练方法和词向量的训练方式十分相像,其本质就是根据每个单词的上下文进行预测,其结构框架如图2所示。

图2 Doc2vec结构框架图
用矩阵D中的某一列向量代表一句话,每一个单词也用一个唯一的向量即矩阵W中的某一列来表示。其主要过程主要分成两步:第一步为训练模型,通过已知的训练数据得到词向量以及句向量/段向量;第二步则是推断过程,对于新的段落,利用梯度下降的方法更新矩阵D,增加新的列,从而得到新的段落向量。经过训练后,段落向量可以当做段落的特征,可以将这些段落特征直接输入到后面的模型中。Doc2vec算法本身有两个关键点:一是无监督训练得到字向量W,二是推理阶段得到段落向量D。Doc2vec算法的主要优势在于:首先,Doc2vec能够从未经过标签处理的文本数据中学到特征,同时能够很好地应对有时数据不够丰富的问题;其次,继承了词向量在向量空间中对于单词语义的理解;最后,Doc2vec算法保留了很多的文本信息比如词语之间的序列信息等。这些优势能够使最后推荐的性能变得更加稳定且能够在一定程度上提高推荐的准确度。本文将在第2部分对融合了Doc2vec后对于模型的影响进行分析 和对比。
1.4 DeepFM模型
1.4.1 因子分解机
因子分解机(Factorization Machines,FM)是由RENDLE在文献[5]中提出的一种与支持向量机(Support Vector Machine,SVM)类似的预测器,但因子分解机能很好地应对数据稀疏的情况,即使在数据高稀疏的情况下也能估计得到可靠的参数。FM具有线性复杂度,并且能够考虑特征之间的相互关系。普通的线性模型如式(2)所示:

式中:y为目标值,w0为偏置项,wi为每一个特征的权重,xi为第i个特征。由式(2)可知,普通的线性模型独立地考虑每一个特征的影响,对于特征2阶及以上的交叉情况并未考虑。而FM模型则对此进行了改进,如式(3)所示:

式中:n表示输入数据经过OneHot处理(将评论文本通过独热编码转换成向量表示)后的数据维度,xi表示第i个特征,wij是特征组合的参数。当数据十分稀疏的时候,特征xi和xj都不为0的情况较少,导致特征组合的参数比较难训练。为了更好地求解得到特征组合参数wij,FM对于每一个特征xi引入了辅助向量Vi=(Vi1,Vi2,Vi3,…,Vik),然后利用向量之间的内积得到特征组合参数wij,如式(4)所示:

与词向量的表现形式类似,词向量是将一个词转换成一个向量,而在FM中则是将一个特征转换成了一个向量。利用辅助向量对特征组合参数矩阵进行分解的主要优势在于:首先,求解的参数数量降低,从本来的n(n-1)/2个参数变成了求解矩阵V,即参数数量变成了n×k;其次,削弱了高阶参数间的数据独立性,k值越大,辅助向量对于特征的表现能力越强,而高阶参数间的数据独立性越强,模型则越精细,而较小的k值则会使模型获得更好的泛化能力。因此在实验中选择较小的k值以获得较好的医疗推荐效果。
1.4.2 DeepFM
DeepFM模型由GUO H等人于2017年提出[6],可以将其看成是因子分解机FM的衍生,将深度神经网络(Deep Neural Networks,DNN)与FM相结合,利用FM挖掘低阶特征组合的同时利用DNN挖掘高阶特征组合,通过并行的方式将两种方式组合。其模型框架如图3所示。

图3 DeepFM框图
由结构图可以看出DeepFM由FM和DNN两部分构成,模型最终的输出也由这两部分构成,如式(5)所示:

本文的上一部分已经详细地介绍了FM部分,DeepFM模型中DNN部分的具体结构如图4所示。

图4 DNN部分结构图
DNN部分的作用是构造高维的特征,挖掘高阶特征相互作用的影响。其输入与FM层一样,是嵌入层的嵌入向量,这也是DeepFM模型的特点之一即权值共享。在Wide&Deep模型之后,很多模型都延续了双模型组合的结构。DeepFM相对于谷歌公司提出的Wide&Deep[7]模型而言,用FM部分替换了原来的Wide部分,加强了浅层网络部分特征组合的能力,使Wide部分具有了自动的特征组合能力,其主要过程就是利用FM部分对不同的特征域的Embedding进行了两两交叉,最后将FM的输出与DNN部分的输出一同输入最后的输出层,参与最后的目标拟合。
DeepFM模型的优势主要在于结合了广度模型和深度模型的优点,在训练了FM模型的同时也训练了DNN模型,同时学习到了低阶组合特征和高阶组合特征[8]。DeepFM模型并不像Deep&Wide模型一样在输入层需要进行人工特征工程。
1.5 融合LDA主题模型及Doc2vec的DeepFM
通过实验对比发现,DeepFM模型在真实的医疗数据集上的推荐性能优于传统的机器学习方法和普遍使用的深度学习方法。本文在DeepFM模型的基础上,利用LDA主题模型和Doc2vec方法进行了优化,使最后的推荐性能有了一定的提升,其框架结构如图5所示。
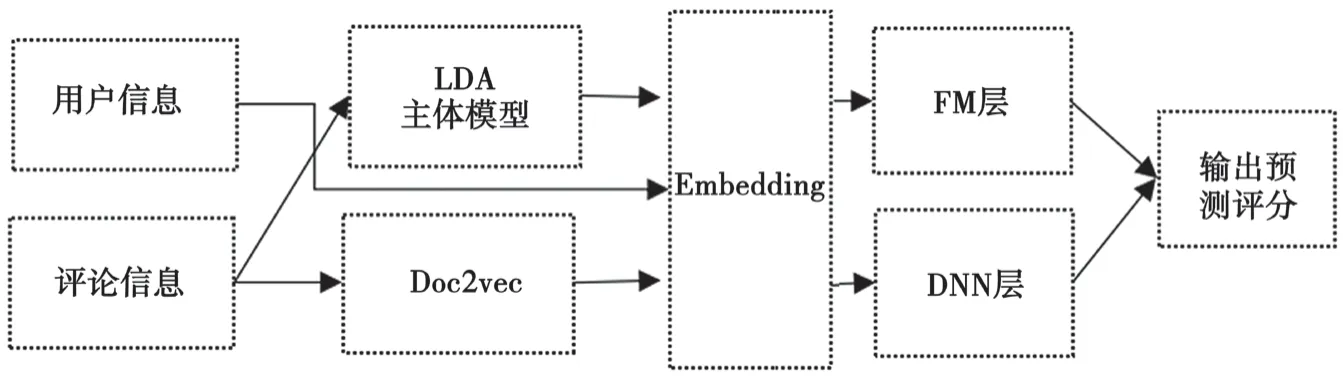
图5 融合LDA主题模型以及Doc2vec方法的DeepFM模型框架图
利用LDA主题模型挖掘评论信息中的潜在主题和特征,同时利用Doc2vec方法保留文本浅层的特征,使模型能够更好地理解文本语义信息并增加模型推荐效果的稳定性。将LDA模型挖掘出的特征和段向量拼接后输入DeepFM模型,得到预测的评分并与实际评分拟合。
该方法相较于DeepFM方法增强了模型对于隐藏特征和隐藏特征交叉情况的学习和挖掘,同时相比传统的OneHot方法,LDA主题模型和Doc2vec拼接的方法可以降低输入层的维度。经过实验发现,该方法在医疗评论数据集上的推荐性能相对于DeepFM模型有了一定的提高。
2 实验设计及结果分析
本文的实验旨在验证融合了LDA主题模型和Doc2vec的DeepFM模型相较于传统的机器学习方法和深度学习方法有更好的准确性和稳定性。本文所有的实验都运行在一台具有8 GB内存、3.6 GHz主频 Intel(R)Core(TM)CPU的机器上。实验主要分为两个部分:第一部分对比DeepFM模型、传统协同过滤方法、宽深网络结构(Deep&Wide)方法以及经典的循环神经网络(Rerrent Neural Network,RNN)深度学习方法的准确率;第二部分对比DeepFM模型和分别加入LDA主题模型、Doc2vec的DeepFM模型以及将三者结合的模型的准确率和稳定性。
实验使用的数据来源于Yelp数据集。Yelp数据集是一个经典的推荐数据集,因拥有大量的真实数据而被广泛地使用。从Yelp数据集中筛选抽取134 701条有关医疗评论的数据记录进行整合和预处理。将预处理后的数据集的80%抽取作为训练集,并将其中20%的数据抽取为验证集。剩余的20%的数据抽取为测试集,用来检测算法的效果。实验使用的评价标准为均方根误差(Root Mean Square Error,RMSE)。RMSE是推荐领域最常见的评价标准之一,其计算如式(6)所示:

式中:n为测试的总数量,p为模型预测的评分,r为用户的真实评分。显然,RMSE的值越小越好。
首先需要找到LDA主题模型中最优的隐含主题数K值和Doc2vec中段落嵌入向量的大小M,如图6、图7所示。

图6 寻找最优K

图7 寻找最优M
由实验结果可以发现,当LDA主题模型中的隐藏主题数目K设置为20时实验效果接近最优,当Doc2vec嵌入向量大小设置为300维时实验效果接近最优。
2.1 DeepFM方法与其他常用推荐算法的对比
为了验证DeepFM模型方法能够提高评分推荐的准确度,分别使用传统的协同过滤方法、经典的深度学习RNN方法、近几年提出的宽深网络模型方法以及DeepFM模型方法在数据集上进行试验。实验结果如图8所示。在该数据集上,DeepFM方法相较于另外三种方法,对于评分推荐的准确度有了一定的提升。

图8 DeepFM和其他方法结果的对比情况
2.2 融合LDA主题模型和Doc2vec的DeepFM模型与普通的DeepFM模型对比
融合LDA主题模型和Doc2vec的DeepFM模型与普通的DeepFM模型对比实验结果如图9和图10所示。可以看出,融合了LDA的模型收敛速度更快,且在推荐性能上表现更好。但在实验过程中发现,由于LDA主题模型每一次生成的隐藏主题不同,当隐藏主题划分情况较好时推荐性能较好,反之推荐性能会受到一定的影响。因而在多次实验的过程中,评估标准RMSE值表现出一定的波动性和不稳定性。但当加入了Doc2vec段落嵌入后,测试结果的稳定性增加。结果如图11所示。
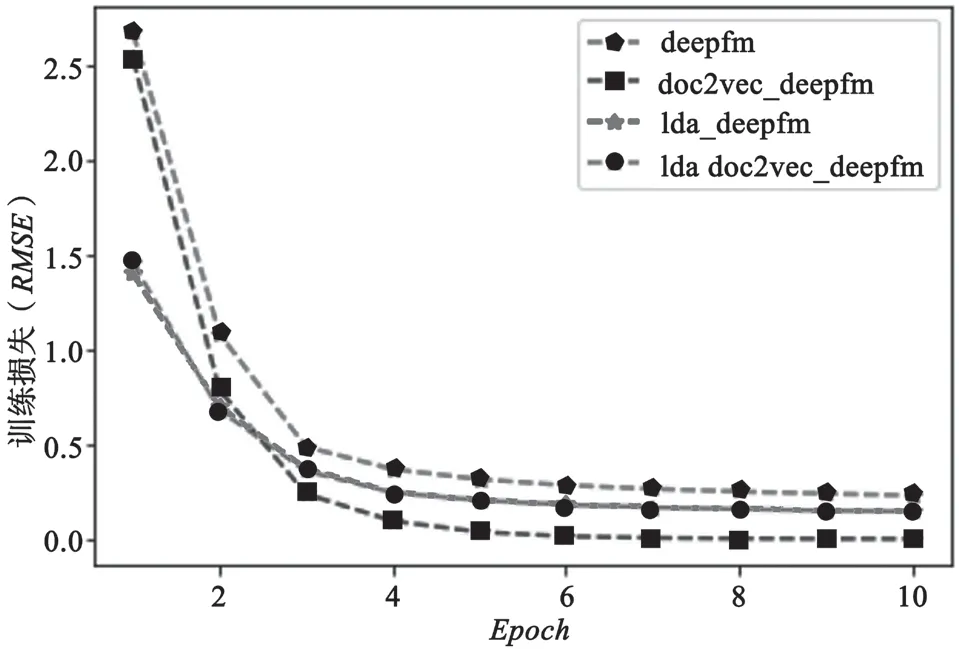
图9 训练时RMSE下降情况
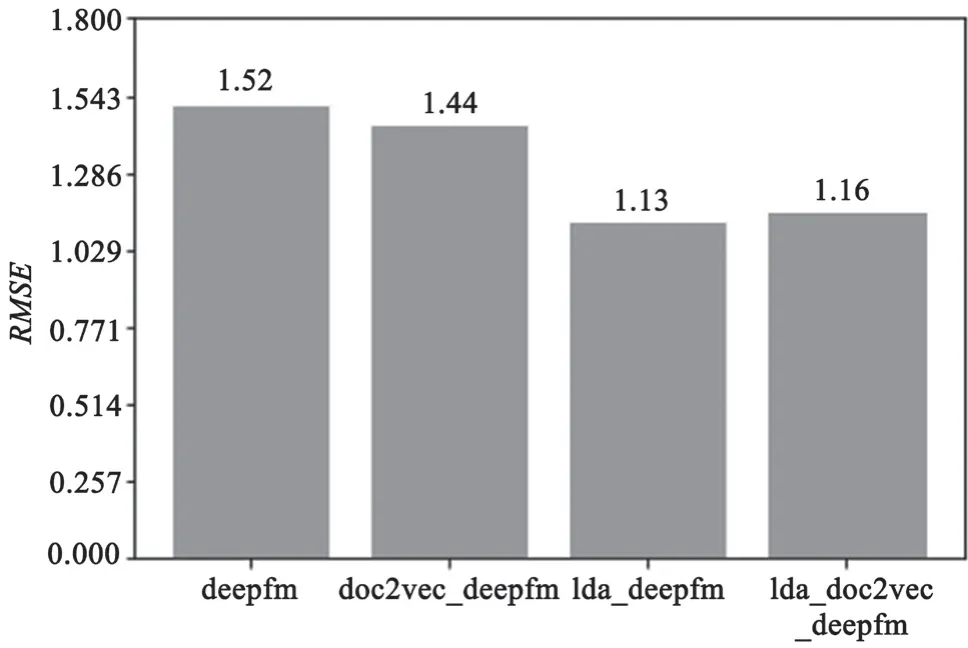
图10 在测试集上模型的RMSE比较情况
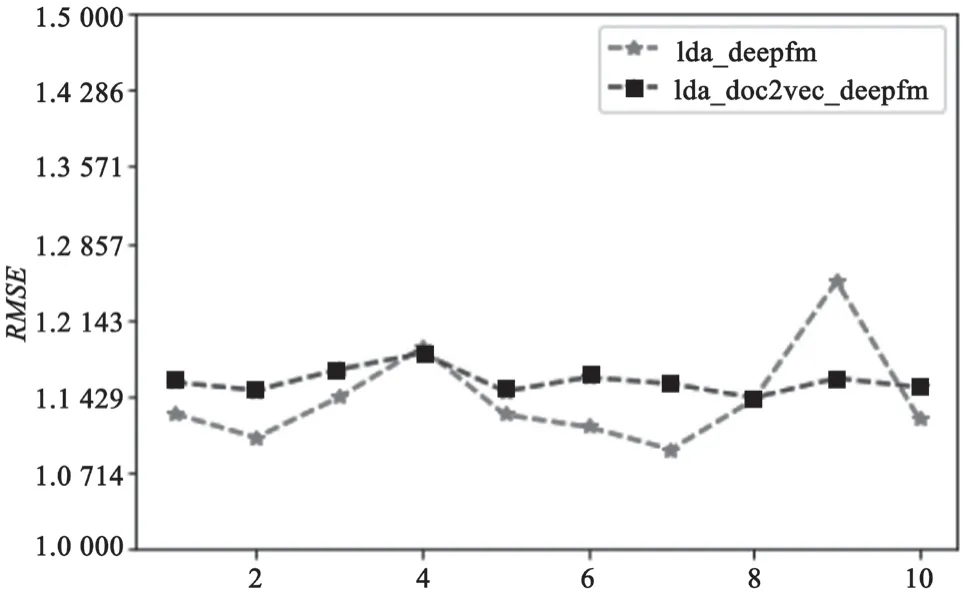
图11 多次实验中两个模型的稳定性比较情况
实验结果对比显示,DeepFM模型相较于经典的机器学习方法和目前常用的深度学习方法在医疗推荐方面具有一定的优势。根据RMSE评估,融合了LDA主题模型后,其推荐性能又得到了一定的提高但稳定性下降。结合了Doc2vec段落嵌入后,虽然其RMSE值比只融入了LDA主题模型的DeepFM模型上升了3%,但该模型的稳定性得到了提高,使得模型更好操控和调整。
3 结 语
现实生活中为用户实现个性化的推荐是一个难题和挑战。为了解决这个问题,本文提出了融合LDA主题模型和Doc2vec的DeepFM模型来挖掘用户评论中的隐藏主题和隐藏特征,并且学习其中浅层和深层的特征,为辅助用户决策得到较为准确的推荐结果。实验结果表明,本文提出的方法在真实数据集上的医疗推荐性能比传统的协同过滤方法、宽深网络模型(Wide&Deep)、RNN以及一般DeepFM方法表现更优。未来,希望能够从社交网络数据中抽取出更多的特征并且尽可能实时地为用户提供更准确、更可靠、更个性化的推荐内容。
