基于多智能体深度强化学习的无人机集群自主决策*
2022-05-25刘志飞陈希亮
刘志飞,曹 雷,赖 俊,陈希亮
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引言
对人工操纵无人机来说,同时操控多架无人机完成多项任务且无人机之间形成有效配合是相当困难的,注意力分散或者操控失误都会造成较大的安全风险。无人机的操控还受到电磁干扰和远程控制距离的限制,因此,无人机灵活自主决策能力显得尤为重要。近年来,多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning,MADRL)在复杂游戏中取得完胜人类专家水平的胜利,表明多智能体深度强化学习在解决复杂序贯问题上取得重要突破。强化学习技术应用到无人机群可以提高无人机群的灵活智能性。本文以一个由6架无人机组成的无人机群为例,使用墨子AI仿真实验平台,无人机群组成一个巨大的动作空间,时间步内有200多个组合的动作空间,为每架无人机在每一步行为的机动方向、航线或向目标发出攻击都有提供了上千种选择。使用深度神经网络来预测每个无人机在每个时间步的最优动作,并根据每个无人机的局部观察产生自主决策。MADRL方法生成无人机群作战决策对无人机作战研究具有重要的参考价值,是未来人工智能应用在军事领域的重要方向。
1 无人机集群研究现状
无人机集群作战被公认为未来智能化战争的典型作战样式。由于无人机集群作战概念处在不断探索阶段,因而采用建模仿真方法对无人机集群作战的有关问题开展研究,为这一新型作战样式的发展提供理论支撑。当前,无人机集群研究面临的挑战有:
(1)无人机集群的个体行为刻画简单。鱼群算法、蚁群算法等源自对生物界集群行为观察,其规则简单,涉及群体智能的涌现。但是随着人工智能发展和计算机算力的提高,深度学习得到进一步发展,神经网络的数据拟合能力得到极大提升,具备不同任务能力的智能个体组成的异构集群成为重要发展趋势,由多智能体组成的智能集群将具有较高的智能水平。
(2)无人机集群协同作战研究不足。目前无人机集群作战建模与仿真研究中,大多只针对单一机型和单一简单任务,而实际作战中则需要不同功能类型的无人机组成的异构集群协同完成整体作战任务。
(3)仿真无人机不具备自主决策的能力。现有无人机集群建模研究大多采用规则方法,该方法通常采用If-then式的反应结构来表达无人机个体的行为决策,这种方法难以适应未来战场复杂多变的环境
2 强化学习
近年来,深度强化学习(Deep Reinforcement Learning,DRL)[1]取得显著成绩,这导致了强化学习的应用场景和方法与日俱增。最近的研究从单智能体发展到多智能体系统。尽管在多智能体领域面临诸多挑战,但深度强化学习在一些相对复杂的游戏领域取得了许多成功,如围棋[2-3]、扑克[4-5]、DOTA2[6]和星际争霸(StarCraft)[7]。这些领域的成功都依赖于强化学习(Reinforcement Learning,RL)和深度学习(Deep Learning,DL)两个技术的组合。
2.1 单智能体强化学习
强化学习是一项通过不断试错来学习的技术。智能体通过一系列的步数与环境进行交互,在每一步上基于当前的策略来获取环境状态,到达下一个状态并获得该动作奖励,智能体的目标是更新自己的策略以最大化累计奖励。如果环境满足马尔可夫性质(Markov Decision Process,MDP)[8],强化学习可以建模为一个马尔可夫决策过程,如式(1)所示。

其中st表示时间步t时的状态。
MDP可以用式(2)来表示。

其中S表示状态空间(st∈S),A表示动作空间,at∈A,R表 示 奖 励 空 间(rt∈R),ρ表 示 状 态 转 移 矩 阵(ρSS′=P[st+1=s′|st=s]),γ表示折扣因子,它用于表示及时奖励对未来奖励的影响程度。在深度学习中,有两个重要的概念:状态价值函数和动作价值函数。
状态价值函数用来衡量智能体所处状态的好坏,用式(3)表示:

动作价值函数用来衡量智能体采取特定动作的好坏,用式(4)表示。
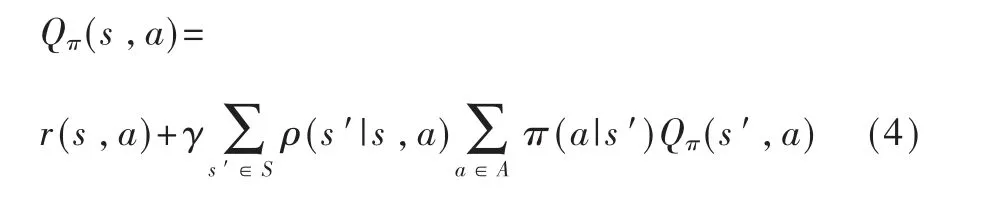
2.2 多智能体强化学习
深度学习已被应用于解决具有挑战性的问题,如从雅塔丽游戏到Alpha Go、Alpha Zero、Alpha Star,再到无人驾驶和工业机器人。深度学习的大多数成功都集中在单智能体领域,建模或预测其他智能体行为在很大程度上是不必要的。然而,在许多实际应用中涉及多个智能体之间的交互,其中紧急行为和行为复杂性是由多个智能体共同作用产生的。例如,在多机器人控制、通信、多人游戏以及社会困境分析等领域中,多智能体自我博弈也是一种有用的训练方法。将单智能体扩展到多智能体系统中,对于构建能够与人类进行高效交互的人工智能系统至关重要。但是传统的强化学习方法(如Q-Learning)和策略梯度算法不太适合多智能体环境。随着训练的进行,每个智能体的策略都在发生变化,环境的不确定性带来了学习稳定性的挑战,并且阻止了直接使用过去的经验回放。同时,当需要多个智能体协调时,策略梯度的方法通常表现出非常高的方差。
多智能体强化学习可以建模为分布式部分可观测马尔可夫决策过程(Dec-POMDP)[9]:一个完全合作的多智能体强化学习任务可以用分布式部分可观测马尔可夫决策过程(Dec-POMDP)来描述。Dec-POMDP可 由 元 组G=(n,S,U,P,r,Z,O,γ)表示。其中n表示智能体的数量;s∈S表示状态;ua∈U表示智能体的动作;ua∈U≡Un表示智能体的联合动作集合,P(s′|s,u):S×U×S→[0,1]表示状态s下采取联合动作u转移到s′状态转移概率;r(s,u):S×U→R表示奖励函数;z∈Z表示每个智能体的观察值由O(s,a):S×A→Z来 描 述;γ∈(0,1)表 示 折 扣 因 子。
2.3 强化学习方法在无人机群上的研究现状
深度学习在游戏领域取得巨大成功,将该方法应用到无人机操控方面的研究也越来越多。文献[10]提出了将单智能体深度学习方法应用到单个无人机的灵活操控上。文献[11]使用近端策略优化(Proximal Policy Optimization,PPO)算法对单个无人机的飞行姿态进行灵活的控制以应对复杂恶劣的环境。文献[12]提出使用深度学习方法对无人机在陌生环境中进行导航。文献[13]提出一种基于深度学习的城市无人机,其在在线和离线状态下均能规划出较优路径。目前研究热点在集中在基于深度学习的单个无人机的操控上,基于MADRL的无人机群的研究还比较少。基于MADRL方法应用到无人机群上主要面临状态动作空间维度灾难、环境不稳定性和信用分配的挑战。
3 无人机集群作战建模
3.1 无人机集群的强化学习建模
采用MADRL方法[14]对无人机集群作战进行建模,可认为是在连续状态空间上的及时决策过程,其遵循马尔可夫过程,用以下五元组形式表示:

其中,n表示无人机的个数;i表示无人机的编号下标;Ai表示第i个无人机的动作空间;Ri表示无人机i在执行动作Ai后获得的及时回报;T表示状态转移函数:S×A1×…×An→S′;γ表示折扣率,γ∈(0,1)。N个智能体的POMDP由所有智能体的组成一组状态S,一组动作A1,…Ai,…An和每个智能体的一组观测O1,…Oi,…On来定义。为了选择动作,每个无人 机i使 用 随 机 策 略πθi:Oi×Ai→[0,1],其 根 据 状 态转 移 函 数S×A1×…×An→S′产 生 下 一 个 状 态。每 个 智能体i获得作为该状态和智能体的动作的奖励函数ri:S×Ai→R的奖励,并且接收与状态相关的观察Oi:S→Oi。初 始 状 态 由 分 布:S→[0,1]确 定。
N个无人机在做出联合动作A1,…Ai,…An后从环境中获取奖励R1,…Ri,…Rn。在POMDP中,无人机集群的目标是学习到最优联合策略,即最大化整体奖励。本文采用墨子AI的实验环境,实验场景如图1所示。

图1 墨子实验场景
其中红方由6架灰鹰无人机组成无人机集群,使用MADRL算法进行自主决策行动。蓝方由6个坦克排(T-72型主战坦克×4)和3个地空导弹排(萨姆-22“灰狗”)组成,使用固定战术规则。红方无人机群的任务是在最短的时间内避开雷达找到地方坦克并有效催化目标。
3.2 奖励函数设计
当无人机击毁一个坦克排,获取及时奖R=1,当无人机进入蓝方地空导弹防御范围并被击毁,获取奖励R=-1,给予惩罚。当无人机互相碰撞时给予奖励R=-0.1,为了引导无人机更快地学习到最优攻击策略,设计连续性函数引导无人机到达预先设定的区域,距离值越小获得的奖励越多。无人机集群的作战任务最优策略是避开蓝方地空导弹,保存自身实力并摧毁蓝方全部坦克排。
3.3 训练流程
训练伪代码如下:

1.For episode=1 to M do 2.初始化一个随机过程以便进行动作探索3.接收初始状态4.for t=1 to max-episode-length do:5. 对于每个无人机i,根据策略网络加噪声采样动作ai=μθi(Oi)+Nt 6. 执行联合动作a1,…ai,…an获得奖励和下一个状态S′7 将(x,a,r,x′)存 入 经 验 回 放 集D中8. S′x′赋 值 给x 9.for无人机i=1 to N do 10. 从经验回放集D中采集s个mini批的 数 据xj,aj,rj,x′j 11. 设置联合动作值函数为:y j=rj i+γQμ′i(x′j,a′1,…,a′i)

12. 最小化损失函数L(θi)=1∑(yj-Qμ S j i·(xj,aj 1,…,aj n))2来更新评论家网络13. 更新演员策略网络:▽θi J=1∑▽θi μi(Oj i)▽ai Qj S j i(xj,aj 1,…,aj i,…aj N)14. 更新每个无人机的目标网络参数:θ′ i ←τθi+(1-τ)θ′i 15. end for 16.end for
4 实验设计及结果分析
实验环境如下:
仿真环境:墨子AI实验平台;
硬件环境:Windows 10操作系统;
CPU:酷睿i5处理器;
内存容量:16 GB;
开发语言:Python3.7。
实验结果:经过500轮的训练,红方无人机逐渐学会了最优策略,能够在最快的时间避开雷达到达目标对蓝方坦克进行有效的攻击,红方无人机集群到达目标并摧毁敌方目标的成功率逐渐提高。如图2所示,红方无人机集群能有效地完成作战任务。损失函数曲线如图3所示。
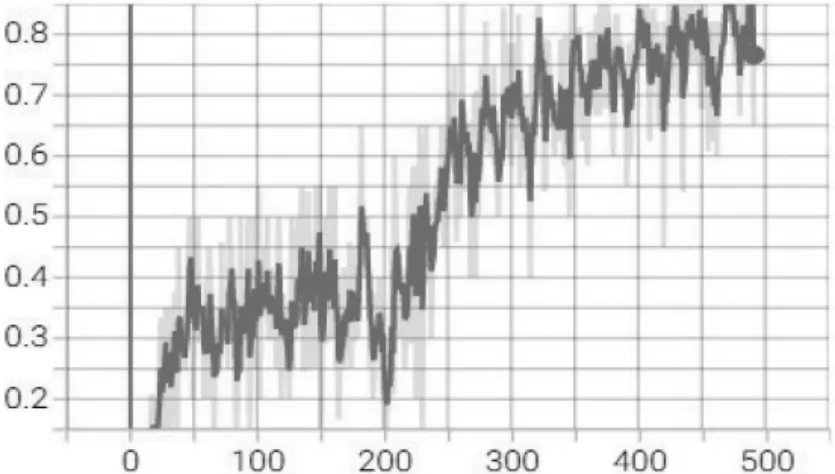
图2 无人机群到达目标并击毁敌方坦克的成功率
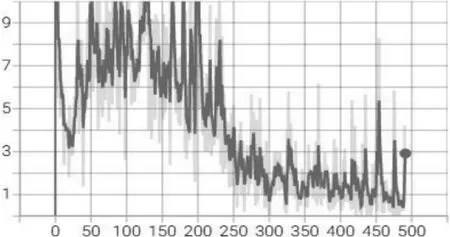
图3 损失函数曲线
通过MADRL方法进行仿真训练,无人机集群可以学习到三种战术:
(1)6架无人机集中优势兵力采取编队飞行从左侧依次对蓝方进行攻击,如图4所示。

图4 无人机群保持队形从左路飞行
(2)6架无人机集中优势兵力采取编队飞行从右侧依次对蓝方进行攻击,如图5所示。

图5 无人机群保持队形从右路飞行
(3)6架无人机兵分两路从左右两侧各三架采取编队飞行依次对蓝方进行攻击,如图6所示。

图6 无人机群保持队形从两侧包抄
5 结论
本文采用多智能深度强化学习的技术,通过最先进的MADRL算法对无人机集群行动进行了建模,并在墨子AI试验平台进行了测试。测试证明,无人机可以在战场环境中获取状态信息,产生最优动作,并作出自主决策,为无人机集群提供灵活的飞行控制,并在遂行任务中开展协调和配合。未来将在无人机上安装训练好的神经网络控制器,在实际场景中再度进行训练和试验。此项研究成果提供了一种无人驾驶集群化的飞行控制方式,在医疗、农业、安全等不同领域都具有应用价值。

