基于多Transformer网络协同生成的自动作曲
2022-05-25王嵩超李金龙
王嵩超,李金龙
(中国科学技术大学 计算机科学与技术学院,安徽 合肥 230026)
0 引言
多目标序列生成技术在多轨音乐生成等任务中有着重要应用,这需要同时确保多个生成的序列自身的连续性与序列之间很强的相关性。本文关注音乐生成背景下的多序列生成问题。现代音乐歌曲通常包含多个音轨,包括旋律音轨和用于伴奏的多个乐器音轨。早期的研究[1-2]专注于只有单轨的旋律生成,而最近的工作[3-4]已经开始探索多轨音乐生成。在本文中,仅关注使用基于序列的方法的多轨音乐生成问题。
基于序列的方法首先会将乐谱序列化为一个或多个符号序列,并输入至序列模型。通常,会设计出类似MIDI协议的序列格式来表示一个单轨音乐序列[1-2,5]。 与单轨生成相比,多轨生成任务需要其生成的轨道具有很强的相关性,同时保持其自身的连续性。
最近几年提出的多轨音乐生成模型主要有Muse-GAN[4,6]、XiaoIce Band[7]以 及PopMAG。这 些 模 型 并没有细致地模拟不同音轨之间的音符依赖关系。具体而言,正如Ren等人[8]指出,MuseGAN仅仅在多个生成器的参数上共享了一些特征,这样并不能细粒度地去为单个音符间的依赖关系建模;对于XiaoIce Band,在一个生成步骤中不同解码器的生成过程仍然是独立的,所以同一时间步骤中音符标记之间的依赖关系仍然没有被建模;而对于PopMAG,将多条轨道合并至单条序列的操作会破坏单轨乐谱的序列结构,影响生成效果。
本文提出了用于多轨音乐生成的MuseTransformer。MuseTransformer遵循多生成器样式。每个生成器都是一个基于Transformer的网络,包含一个Transformer编码器和一个解码器。为了对当前生成的符号和各个音轨的历史内容之间的依赖关系建模,来自各生成器的编码器与解码器通过全相联连接,这样每个解码器均可以获取到任意轨道任意历史时刻的上下文信息。通过在每个轨道上使用一种迭代生成的策略,本文模型在生成过程中也能够模拟在相同演奏时刻中产生的音符之间的依赖关系。为了模拟大时间跨度的人类作曲行为,MuseTransformer将来自合并序列方法的位置标记引入其序列格式,这使得模型能够在任意乐谱位置生成未来的音符,而不受限于固定的时间步长。
为了提高训练效率以及支持长序列的生成,乐谱的序列表示长度应尽可能短。本文基于MuMIDI[8]和REMI[9]设计了一种新的序列格式,以进一步缩短序列长度,即MuseSeq。MuseSeq引入了一种名为KPS的新型位置符号来标记乐谱中的符号位置。与常规位置符号不同,KPS仅插入在每组紧凑音符序列的开头。实验证明,与传统的位置标记相比,使用KPS标记时,表示相同长度的乐谱所需的符号要少得多。综上,本文的贡献总结如下:
(1)提出了多轨音乐生成框架MuseTransformer,采用多输入、多输出的Transformer网络变体,能够对当前符号与任意时刻任意轨道的历史符号间的依赖关系进行建模。
(2)设计了MuseSeq,一种新颖的紧凑序列格式,能够显著缩短多轨音符序列编码后的总长度。
1 带有关键位置标记的多轨音符序列表示
在MuseSeq多轨序列表示中,包含两种符号序列:一个和声符号序列与多个音轨序列。在多个音轨序列中,有一个序列被指定为主旋律序列。
1.1 符号定义
MuseSeq序列表示的符号类型与PopMAG工作[8]类似,包含了音符符号(Note Symbol)、和声符号(Chord Symbol)与位置标记(Position Symbol)三种类型。与PopMAG不同的是,MuseSeq提出了关键位置标记(Key Position Symbol,KPS)来替代传统的位置标记。
1.1.1 音符符号
一个音符符号由Note表示,记为yn。一个音符包含三个属性,如式(1)所示:

其 中,ynp∈{0,1,2,…,127},ynv∈[0,120]与ynd∈{0,1,2,…,80}分别表示音高、音量与音符时长。对于音符时长的编码,定义一个四分音符的1/8为最小的基本时长单位,并忽略时长小于该时值的音符符号。对于原乐谱中的多个相同音高的连续音符,使用时值相同的单个音符符号来表示它们。MuseSeq不对休止音符进行编码。
1.1.2 关键位置标记
一个关键位置标记记作yk。yk是一个二元组,如式(2)所示:

其中pbar∈{0,1,…,100}是小节位置,poff∈{0,1,…,63}是小节内偏移数。
与传统位置标记类似,KPS一般在序列中位于音符符号的前面,其作用是明确序列中的音符符号的演奏时刻。在生成模型中,KPS的另一个作用是将多个序列中的符号按时序进行对齐。与传统位置标记不同的是,KPS仅被插入在少量关键的音符前面。具体的插入规则在1.2小节介绍。
1.1.3 和声标记
和声标记记为yc,用来指明序列中特定位置的和声类型。与音符符号不同,和声标记并没有使用单独的关键位置符号来标记位置,而是将位置信息直接编码至符号内容中。因此,和声标记的结构如式(3)所示:

其 中pbar、poff定义同1.1.2小节,而ych∈{0,1,2,…,83}是一整型数,用来表明和声类型。根据乐理知识,和声类型ych由根音的音高与和声色彩(Chord Quality)两个因素决定。 类似Ren等人[8]与Huang等人[9]工作,和声标记符号选择了12个根音音高级与7个和声色彩,总共有84个和声类型。
1.2 MuseSeq的乐谱表示与排布
在MuseSeq中,一张乐谱S的结构如式(4)所示:
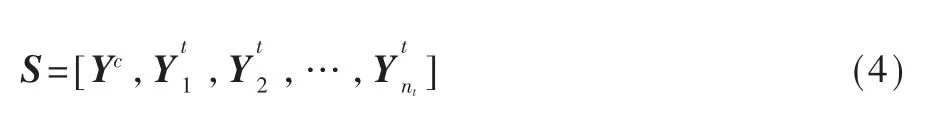
其中Yc是和声标记序列,Yti(i=1,2,…,nt)是第i个音轨的音符序列。
和声标记序列Yc仅由和声符号组成,如式(5)所示:
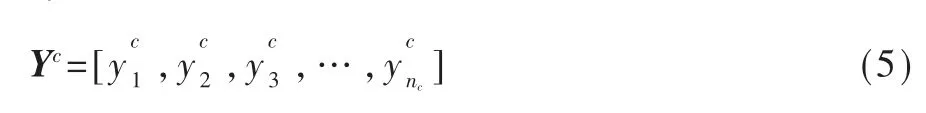
第i个音符序列包含两种符号类型:位置符号yp与音符yn,如式(6)、(7)所示:
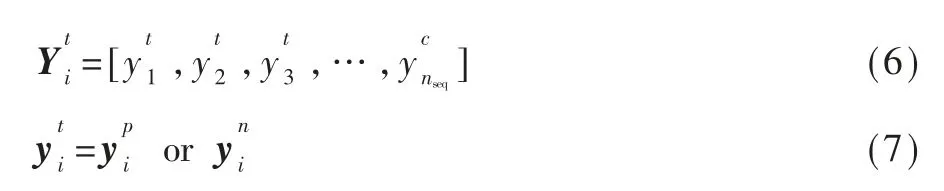
在每个音轨序列中,音符符号按照符号的演奏开始时间升序排列。在每个音符符号的前面,可以存在一个KPS符号来指明音符的位置。然而,不一定每个音符都会有对应的KPS存在其前面。KPS当且仅当如下两个条件之一成立时才被附加到音符前面:
(1)当前音符位于强拍位置。
(2)上一个音符与当前音符的演奏间隔大于等于1个四分音符。
作为例子,图1展示了同一段乐句被序列化为MuseSeq与包含传统位置符号的序列(以PopMAG工作的Mu-MIDI为例)的比较,可见MuseSeq序列在空间复杂度上的明显优势。

图1 单轨乐谱被序列化为MuseSeq表示与Mu-MIDI表示的对比
2 MuseTransformer模型框架
2.1 模型介绍
如图2所示,MuseTransformer由四大模块组成:嵌入表示模块、编码器模块、解码器模块与输出模块。嵌入表示模块接收一个和声序列的输入和nt个音轨序列的输入,输出模块分别输出nt个音轨序列的每个下一个符号的概率分布。

图2 MuseTransformer架构
2.2 嵌入表示模块
嵌入表示模块包含一个和声符号嵌入器Embc与音轨符号嵌入器Embt。
2.2.1 和声符号嵌入器
和声符号嵌入器Embc对和声符号yc进行编码,将和声类型与谱面位置ycpos编码成词向量xc,如式(8)所示:

其中Wct是可训练的嵌入矩阵,而Embpos是sinusoid位置嵌入函数[10]。此处为了简洁,忽略了下标中的符号序列数。
2.2.2 音轨序列嵌入器
音轨序列嵌入器Embt将第i条音轨的符号yti编码得到相应的词向量xni,如式(9)所示:

具体的嵌入过程取决于符号yti的类型,如式(10)所示:
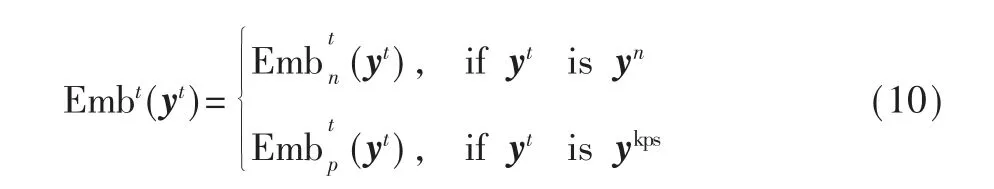
对于音符符号yn,通过各种嵌入矩阵分别编码,如式(11)所示:

其中Wpi、Wdur、Wvol分别是对应音高、时长与音量的嵌入矩阵。是位置符号的嵌入函数,它将小节数与小节内偏移ynoff进行编码,如式(12)所示:

其中Wbeat与Woff分别是对应小节数与小节内偏移的嵌入矩阵。
对于KPS符号yp,使用与音符符号同样的位置嵌入函数进行位置嵌入。
2.3 编码器与解码器模块
2.3.1 编码器
MuseTransformer中有nt+2个编码器,即nt个音轨 的 编 码 器En1,En2, …,Ennt,1个 旋 律 音 轨 编 码 器Em与1个和声序列编码器Ec。
Ec将和声序列编码成相应的特征向量Cc,如式(13)所示:

Em与Ei(i=1,2,…,nt)将各音轨的音符序列编码成相应的特征向量,如式(14)所示:
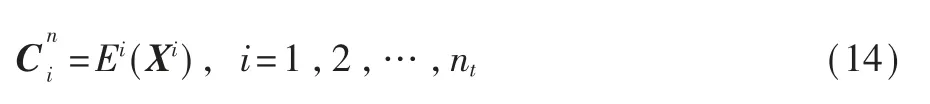
2.3.2 解码器
解码器模块包含nt个解码器{D1,D2,…,Dnt}。每个解码器Dk(k=1,2,…,nt)接收所有编码器的特征向量作为输入,包括和声序列特征向量Cc与音轨序列特征向量,然后生成解码器输出向量如式(15)所示:
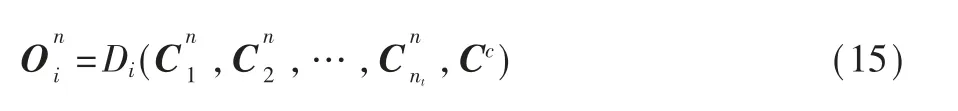
每个解码器Dk(k=1,2,…,nt)由nt+1个线性堆叠的LSH注意力块B0,B1,…,Bnt组成,如式(16)所示:

每个LSH注意力块Bi接收一个关键字向量Ki、值向量Vi与查询向量Qi作为输入,并产生注意力输出,如式(17)所示:

模型采用序列式的方法混合来自各个音轨的编码器输出,如图3所示。每个注意力层的查询向量输入Qi均是前一个注意力块所计算得到的注意力输出,如式(18)所示:
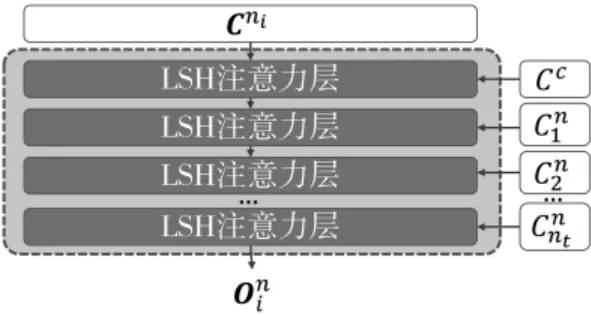
图3 Dn的各个解码器块

第i个LSH注意力块的值向量输入Vi与关键字向量Ki输入是相同的,均依次取自各个编码器输出:

2.4 输出模块
在输出模块中,对应各轨道的各个解码器的输出被输入到一前馈层,得到logit向量,如 式(20)所示:

2.5 训练和推理
2.5.1 训练方法
MuseTransformer使用teacher-forcing策略来完成训练,按照层次结构依次遍历集中每个曲谱、每个音轨与音轨中的每个符号。在每个训练步骤中,渐增式地将数据集中的真实音轨数据的前段部分输入各编码器Eni,并预测每条轨道的下一个符号与计算损失函数。为了使模型能够学得利用其他轨道的当前时刻与历史时刻的信息,在每条音轨被训练时,其他音轨会根据当前被训练音轨的训练进度,仅保留与被训练音轨相同的演奏时间部分,输入对应的编码器。
训练用到的损失函数由以下两项损失函数构成:第一项称为类型损失,它度量预测出的符号类型与真实符号类型的差距;第二项称为内容损失,它度量生成符号内容与真实内容的差距。两个损失函数的定义如式(21)~(23)所示:

2.5.2 生成方法
在生成过程中,和声序列与一条音轨序列会作为输入,而MuseTransformer会从零生成其他音轨信息。
序列生成策略:每个生成步骤中,均会为多个轨道中的某个轨道生成一个符号。为了保证各个轨道能生成时长相同的内容,每次生成步时,都会选择当前所生成内容最少的那条轨道进行生成。MuseTransformer会对每个新符号做两个校验测试:(1)新符号若是KPS类型,其位置值需要比之前的KPS符号大;(2)KPS类型符号的下一个符号需要是音符符号。若校验测试通过,新符号会附加到当前音轨的最后,若未通过,则重新生成直至测试通过为止。当所有序列的长度都大于等于最大序列长度nseq时,或者最大谱面小节数与节内偏移超过max([pbar,poff]),即[100,64]时,生成过程停止。 图4展示了一个多轨序列按照序列生成策略的生成过程。

图4 生成过程示例
3 实验结果
本文设计了三个实验来验证方法的有效性以及与其他方法进行效果对比:(1)消融实验;(2)采用MuseSeq序列表示的序列长度与其他表示法的序列长度的对比;(3)MuseTransformer与其他方法的生成性能比较。
3.1 模型设置
在实验中,轨道数nt设为5,音轨序列长度上限nseq设为512,和声序列长度上限nch设为256。每个编码器均由12层LSH注意力层组成,并具有8个注意力头。训练过程使用了SGD方法,在一块24 GB显存的NVIDIA 3090显卡上训练模型,学习率设为0.0002,mini-batch被设成50张乐谱。
3.2 数据集
所有实验在以下多轨乐谱数据集上进行:
(1)MuseData数据集。该数据集是本文提出的多轨乐谱数据集,含有6579张由MuseScore社区用户上传的高质量管弦乐乐谱。每张乐谱的音轨数量在5~30,且每个音轨至少包含40个音符,平均音符数为324。
(2)Lakh MIDI数据集。该数据集由哥伦比亚大学的Colin等人提出[11],包含176581个MIDI乐谱。为了让Lakh MIDI数据集能与MuseData数据集以相同的方式使用,在该数据集中筛选出了音轨数大于5且音轨长度都大于40的8327张乐谱,这些乐谱的平均音轨长度是102个音符。
3.3 针对生成内容的评价指标
由于音乐体裁的特殊性,传统的NLP评价指标并不适合评估音符序列。为了同时评估生成序列的准确性与多轨序列之间的关联性强度,设计了如下评价指标:
(1)和弦饱和度(Chord Saturation),记为CS,该指标用于评估生成内容与真实和弦类型的匹配程度。对于一个生成的音符序列片段,首先计算出该片段所涵盖的调性音高级(Tonal Pitch Class)的集合,再将该集合与对应的真实和弦类型所包含的调性音高级的集合求交,和弦饱和度则定义为求交后的集合与原集合的元素数量比值,如式(24)所示:
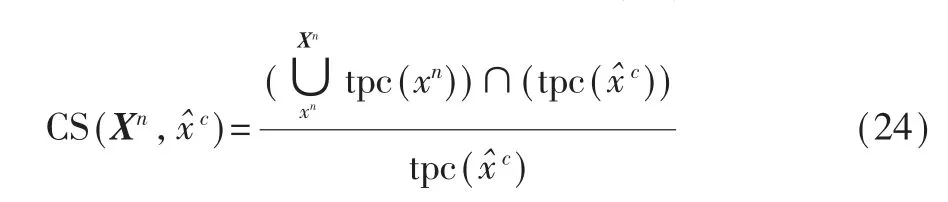
其中Xn表示模型生成的音符序列片段,x^c为输入的真实和弦类型,tpc(xc)表示音符xc的调性音高级。
CS指标既可以针对单轨音符序列计算,也可以针对多轨音符序列计算。在这两种情况下,均依次以每个小节为单位,将小节内一个或多个轨道的所有音符作为一个片段来计算和弦饱和度。整个音轨或乐谱的和弦饱和度则取自各个小节的和弦饱和度的均值。
(2)等音高级音程数量(Number of Same Pitch Intervals at Same Time),是一个多轨相关程度衡量指标,记为SPIAST。来自不同音轨的音符经常会构成音程(interval)关系。在这些音程关系中,纯八度(perfect octave)与纯一度(perfect unison)音程最有代表性。在不同轨道间,这些音程的高频率出现也就代表着轨道间生成内容的高相关性。所以,对于多轨音轨片段,通过度量这两个音程的出现次数来作为评估关联性程度的参考。
(3)音高级数量(Used Pitch Class),记为UPC。受MuseGAN工作[12]的启发,该指标将乐谱连续均匀划分成相等时间段,并统计在每个时间段内乐谱所用到的音高级数量,最后将每个时间段的音高级数量取平均得到。UPC既可以用于评价单轨音符序列的连贯性,也可以用于多轨音符序列,以评价整体和弦的饱满程度。在MuseGAN中,UPC所计算的单位为每个小节。为了避免统计多轨序列的UPC时音符过于拥堵,本文选择的时间跨度为每个四分音符。对于多轨序列,更高的UPC值通常意味着更少的相关性,因为各个轨道倾向于各自独立,音符会有较少重叠。
(4)困惑度(Perplexity),记为PPL。与Ren等人[8]、XiaoIce乐队[7]的工作类似,实验中也使用了常用于NLP任务的困惑度来评价每条生成音符序列的准确性。由于MuseSeq中的音符符号包含多个字段,首先计算音符符号的每个字段的PPL,再将它们相乘得到整个符号的PPL。
3.4 消融实验
消融实验用来证明含有KPS的符号序列格式(见1.2小节)、序列生成策略(见2.5.2小节)和输入混合策略(见2.3.2小节)的有效性。所有的消融实验均为执行从旋律音轨到其他音轨的生成任务,且均在MuseData数据集上完成训练,但使用的是不同的MuseTransformer变种。对于PPL指标,直接采用训练过程中用到的teacher-forcing完成评估,每次根据新生成符号的概率分布与真实符号的内容来计算PPL,并将每步的PPL相乘得到最终的PPL。对于其他评价指标,在生成的多轨序列上完成评估。
消融测试的实验结果见表1,这里“CS”列指生成多轨序列上的和弦饱和度,“CS0”列指原真实序列上的和弦饱和度,其他列均对应为其他评价指标。
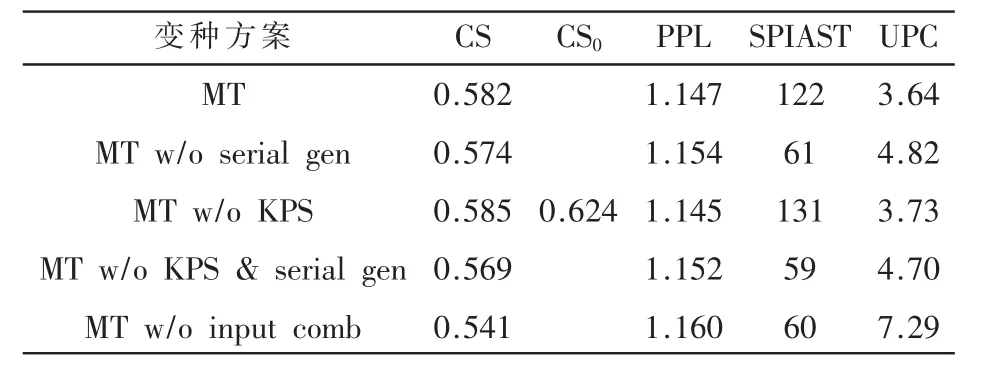
表1 本文模型在MuseData数据集上的消融测试
3.4.1 序列化生成策略的消融测试
为了验证本文提出的序列生成方案的有效性,设计了一个生成算法的变种,它并行地运行对应各个音轨的多个生成器,而没有采用异步执行策略。本小节比较了该变种(记为MT w/o serial gen)与原始模型(记为MT)的生成性能,结果如表1前两行所示。通过比较CS与SPIAST两列的结果,可以发现序列化生成策略带来了更饱满的和弦实现,这表明不同轨道间有更强的关联性。在UPC数据方面,原始模型具有不超过4的平均音高级数量,也意味着较为集中的和弦分布。
3.4.2 含有关键位置标记序列的消融测试
为了验证关键位置标记相对于普通位置标记,并不会对模型性能产生显著不良影响,设计了MuseTransformer的另一变种,该变种所使用的音符序列中,为所有音符符号都加入了普通位置标记。该变种(记为MT w/o KPS)与原始模型的性能比较如表1的第3行与第1行所示。可以观察出,原始模型与该变种的性能较为接近,这说明关键位置标记的引入并不会对模型性能带来显著影响。
3.4.3 输入混合策略的消融测试
为了验证输入混合策略有助于增强序列间的相关性,使MuseTransformer的解码器仅使用其对应轨道的编码输入,即让各个生成器完全独立工作,该变种(记为MT w/o input comb)的实验结果如表1的第5行所示。可以发现,虽然在生成准确性方面(如PPL值)该变种并不明显逊于其他变种,但在多轨关联性方面(如CS与UPC指标),该变种在所有消融实验变种中为最差,SPIAST值也处于较低水平。这说明输入混合策略对于保障生成序列的相关性起到了至关重要的作用。
3.5 效果对比
3.5.1 序列表示效率对比
分别使用MuseSeq与PopMAG工作中的Mu-MIDI表示对MuseData数据集中随机选择的100张有代表性的乐谱进行编码。各音轨编码后的平均序列长度与总乐谱平均长度的对比如表2所示。
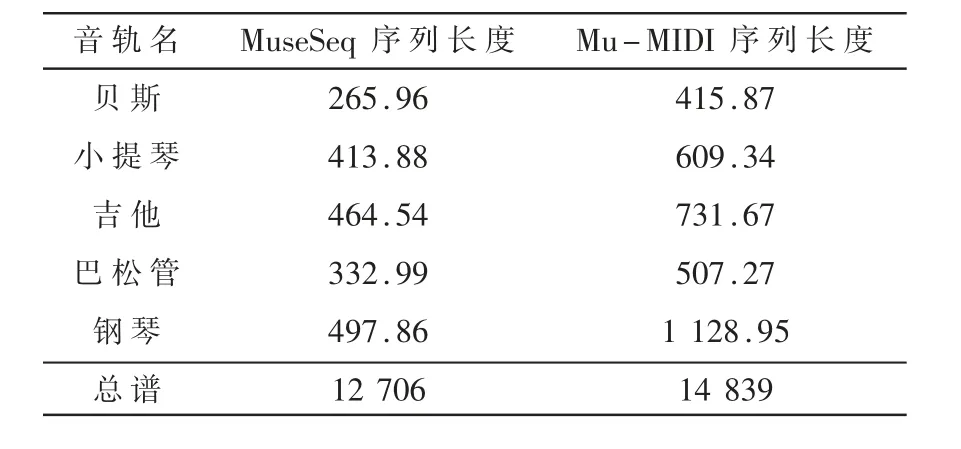
表2 各音轨在不同表示下的平均序列长度
从表2可以看出,对于各个音轨序列,得益于MuseSeq缩减了冗余的位置符号信息,其表示长度比含有完全位置符号的Mu-MIDI序列减少40%左右。而对于包含全部音轨的总谱,MuseSeq序列长度也要比Mu-MIDI减少15%左右。
3.5.2 多轨生成效果对比
本小节将本文模型与MuseGAN[12]相比较。为了让MuseGAN生成与本文工作类似的乐谱结构与配置,将MuseGAN的生成器数量设成4,单小节内的时间单位数设为与本文工作等同的64,并使用文献[12]中所描述的作曲家模型(Composer Model)与track-conditional生成方法。为了简化工作流程,MuseGAN使用了其原先工作中的四件乐器(贝斯、小提琴、吉他、钢琴),而在MuseTransfomer生成器中也保留了这4件相同的乐器。MuseGAN所用到的LPD-matched数据集的钢琴卷帘表示被转换为含有KPS符号的MuseSeq序列表示,以供MuseTransformer训练。各项指标的实验结果见表3。实验统计了CS、UPC与SPIAST三 个 评 价 指 标,其 中CSa、SPIASTa与UPCa列 均表示针对所有轨道计算的指标值,而其他指标均表示针对单个轨道计算的指标值。
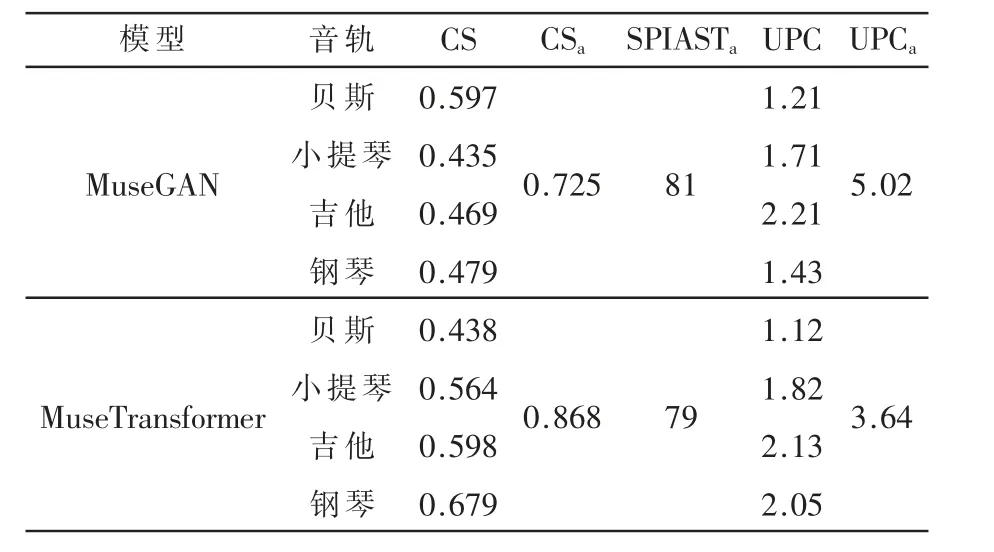
表3 MuseTransformer与MuseGAN的性能比较
如表3所示,在和弦准确性方面,本文模型的CS指标在多数轨道以及整体上均优于MuseGAN,说明了本文模型的生成内容无论在单轨还是多轨方面都更加准确地反映出和弦类型。在UPC指标方面,两模型的单轨UPC数据不相上下,说明了在单轨连贯性方面,两模型表现相近;而在多轨UPC数据上,MuseGAN超过5的指标说明了其生成的多轨序列在音高级上的分布较为分散,关联较少,而MuseTransformer在3与4之间的指标,表明其多轨序列较强的关联性。
4 结论
本文根据多轨音符序列轨道间的强关联性、单轨的连续性等特征,在Transformer网络基础之上,针对性地设计了包含多个生成器的生成模型以及相应的协作生成策略,以及更优化的含有关键位置标记的序列表示。经实验验证,本文提出的网络结构能够明显地提升生成内容的关联性与和谐性;而更优化的序列表示,也在显存空间的限制下,为未来长序列的音乐生成打下了基础。
