基于知识图谱的软件配置漏洞分析技术研究
2022-05-25张慕榕许凤凯魏利卓邹志博
张慕榕,张 尼,许凤凯,崔 轲,魏利卓,邹志博
(华北计算机系统工程研究所,北京 100083)
0 引言
随着信息化、工业化的发展,科技不断推陈出新,信息系统在人们生活中的应用越来越普遍,其中的组件功能也愈加丰富,配置愈加复杂。例如MySQL服务器的每个软件含有至少200个配置项,要想在纷繁复杂的配置项中找到正确的配置方式是一件非常耗费人力物力的事情。有研究表明,错误的配置不仅有可能导致系统瘫痪致使企业的业务中断,还会花费大量资源和财力来排除可能的故障。
安全配置错误可以发生在一个应用程序堆栈的任何层面,包括平台、Web服务器、应用服务器、数据库、框架和自定义代码。从黑客攻击的角度,安全配置错误往往是安全攻击的第一个环节(或者可以理解为跳过信息搜集环节),在捕获此类安全问题后,往往可以获取较高权限,黑客可以修改配置、提升权限、爆破口令或者连接内部服务器或数据库,安全配置错误威胁甚至等于或高于“后门”安全威胁。从安全防护角度,传统的安全配置错误防护成本极高,比如至少要开展如下工作:自动化安装部署开发环境,及时更新IT环境安全补丁,使用高安全性应用架构,开展定期或不定期的漏洞扫描和安全审计。
随着Google提出的图结构数据[1]——知识图谱的发展,人们开始借助其可视化等优点展开研究。通过图结构中的关联特性来连接知识与数据,在海量的知识库中挖掘并处理问题。本文主要基于知识图谱在软件配置漏洞方向展开分析与研究。
1 知识图谱概要
知识图谱是Google在2012年提出的[2],它的第一个特点即它是一种由节点和边组成的多边关系图,类似于一种语义网络,其中包含了实体与实体之间的关系。知识图谱从多源数据中抽取出实体,实体间的关系,实体的属性、概念等,它可以划分为通用知识图谱(General-purpose Knowledge Graph,GKG)和专业领域知识图谱(Domain-specific Knowledge Graph,DKG)。通用知识图谱包含的范围很广,有着丰富且庞大的知识体量。而专业领域知识图谱则更加专一化,侧重于该专业知识的深度扩充,在检索方面,专业领域知识图谱的准确性要高于通用知识图谱。目前常见的通用知识库有Wikidata[3]、DBpedia[4]和Zhishi.me[5]等。除了语义网络这个特点之外,它还有庞大的知识体量支撑,在2012年发布之初,Google知识图谱就具有5亿多的实体。然而,知识图谱的特殊之处不仅仅体现在具有庞大的知识库作为背景,它更能够挖掘海量数据中更深一层次的关系,通过数据间的关联关系为研究分析提供帮助。
知识图谱的数据来源往往有两类:网页数据和数据库[6]。数据库中多体现为结构化数据,网页上的则是非结构数据和半结构数据,还需要通过语义抽取等方式来提取实体及其关系,并映射到领域本体以形成知识图谱。而知识图谱的存储也主要有两种方式,分别是RDF存储和图数据库存储。RDF存储即将数据以三元组(Subject,Predicate,Object)的形式进行存储[7],而常见的图数据库存储使用Neo4j进行存储[8-10]。两种存储方式各有其优点与不足,RDF方式的查询、链接等效率要高于Neo4j等图数据库,而图数据库的方式更适合进行存储与查询,还能支持图挖掘算法。考虑到用途,本文使用Neo4j图数据库来存储安全配置漏洞知识图谱。
知识图谱在网络安全领域主要涉及网络安全本体设计和信息抽取。在该系统框架的设计过程中,需要建立安全配置知识图谱,并将收集到的多源数据融合到高级知识图谱中。
2 总体设计思路
软件配置漏洞产生的原因往往是操作人员配置不当,不同的组件不同的配置需求会耗费大量的精力和资源来分析调整配置,尤其是在开发和运维的阶段。本文所提出的基于知识图谱的软件配置漏洞分析系统,结合了知识图谱的可视化功能,并通过图结构对软件配置项等数据进行关联处理,帮助操作人员分析配置,节约了人力物力,可高效达成安全配置的目的。本文将软件配置漏洞知识图谱的构建主要分为以下三个方面:漏洞数据预处理、漏洞知识融合和配置漏洞知识图谱构建。框架如图1所示。
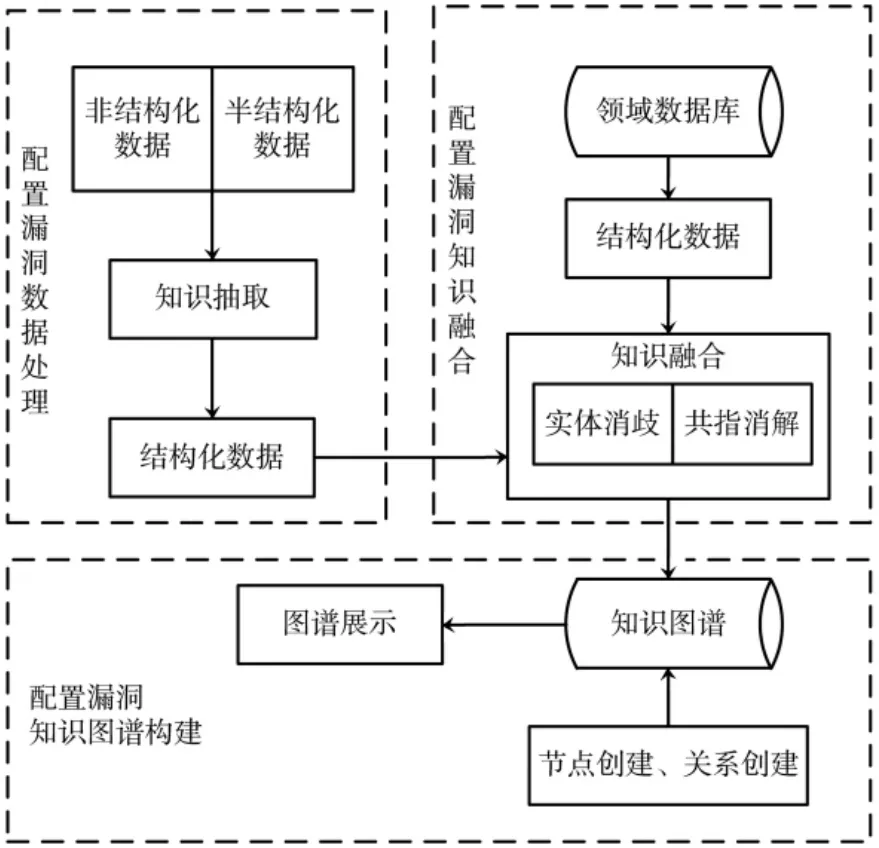
图1 配置漏洞知识图谱构建流程
配置漏洞数据处理模块将获取到的与配置漏洞相关的半结构化数据或非结构化数据通过实体抽取、关系抽取和属性抽取等知识抽取功能,得到结构化的数据。配置漏洞知识融合模块则通过专业领域的知识数据库来获取结构化数据,然后将处理后的非结构化数据和直接获取的结构化数据进行知识融合。最后在配置漏洞知识图谱构建模块通过节点和关系的创建来搭建配置漏洞知识图谱,然后进行数据的可视化逻辑展示。
3 图谱构建
本研究采取的构建知识图谱的方法主要有以下三个步骤:知识库构建、知识融合以及图谱构建。
3.1 知识库构建
知识图谱依靠庞大的知识库存在,所以知识的获取对于知识图谱的搭建至关重要。目前有两种途径可以收集安全漏洞数据,其一是自动进行漏洞收集,它的原理在于通过脚本利用网站插件等工具收集一些开源或专业网站的漏洞信息,然后将其进行信息抽取转化为结构化数据;其二则是需要专业人员手动进行漏洞收集。
3.1.1 信息抽取方式
信息抽取是知识图谱构建的第一步,在目前的研究方法中,信息抽取的方式主要有两种。
第一种主要基于规则提取[11],这类知识来源于知识数据库,数据库中的知识通常是结构化的数据,便于提取,并且精确度高,这类数据是专业领域知识图谱中知识的主要来源,但是它的缺点是覆盖面小,且需要领域相关的专业人士参与。
第二种则需要基于机器学习的方法[12],这类知识通常来源于网页数据等。机器学习的方法需要大量训练数据,基于训练数据得到训练模型,通过训练出来的模型来提取所需要的知识。通过大量的训练数据建模,从而从非结构化的文本中提取到所需要的相关信息,所以这类方法更加适用于通用领域的知识图谱构建。
针对非结构化的开源配置漏洞知识,大部分通过文章形式来描述问题,所以需要先用自然语言处理生成句子图,再通过知识抽取的方式从中提取出实体、关系和属性,最后转化为结构化数据。
知识抽取可以大致分为三个部分:实体抽取、属性抽取和关系抽取。实体抽取也叫命名实体识别,早期主要依靠大量人力物力以基于规则的方法抽取,更适用于领域知识图谱。后来发展了基于机器学习的方法,常见的是通过长短期记忆网络(Long Short Team Memory Network,LSTM)来实现从原始语料库中自动抽取命名实体[13-15]。属性抽取则是抽取实体的属性,属性使得实体的抽象形象更加饱满,可以将其转化为关系抽取问题。关系抽取则是利用学科方法来抽取实体之间的语义关系,包括了词性标注、句法分析以及命名实体识别等多个步骤。
3.1.2 安全漏洞知识库体系结构
图2描述了安全漏洞知识库体系的结构,这个结构主要包含了三部分内容:数据的来源,数据的处理——信息抽取,以及本体的结构描述和知识图谱的轮廓。数据的来源有结构化数据和非结构化数据,可以通过上一小节中的信息抽取方式来获取相应数据库中的数据,抽取的主要信息即为本体所需要的内容。

图2 安全漏洞知识库体系
3.2 知识融合
3.2.1 结构化数据
CVE和CNNVD中的漏洞信息是漏洞数据库中结构化数据的主要来源。CVE中的漏洞信息主要包括以下字段:漏洞名称、网址、avd编号、危害等级、CVE编号、漏洞类型、发布时间、攻击路径、CVSS评分、厂商、漏洞简介、漏洞公告、参考网址、受影响实体、补丁、相关组件、信息来源、CWE编号、攻击复杂度、权限要求、影响范围等,而CNNVD中的漏洞信息主要字段有:漏洞名称、网址、CNNVD编号、危害等级、CVE编号、漏洞类型、发布时间、威胁类型、更新时间、厂商、漏洞简介、漏洞公告、参考网址、受影响实体、补丁等。
这些主要字段详细记录了漏洞自身的信息,同时也记录了相关的产品和事件以及解决办法等。在抽取信息的过程中需要将这些信息提取出来,抽取出其中的重点部分,并将其形成节点,以搭建知识图谱。
收集到的数据经过清洗整理以及去除冗余和错误的信息之后,可以通过一致性描述语言来表示。表1展示了漏洞节点,表2展示了组件节点,表3展示了攻击节点的部分信息。通过其中共有的属性,如CVE-ID、组件名称、CWE-ID等可以建立三类节点间的关联关系。

表1 CVE-2021-20334漏洞节点

表2 mongodb组件节点

表3 CWE-269攻击节点
3.2.2 知识融合
(1)知识融合
通过信息抽取时在非结构化和半结构化等数据中获取的结果,以及在实体抽取和关系抽取后,可以获得实体单元,其中大多较为统一。然而其中还可能会存在与之前知识有所重复或冲突的冗余信息,且该类信息部分存在关系层次不明确的问题或结果呈扁平化,尚未建立关系,对构建图谱具有一定的影响,因此需要对这些结果进行融合加工。知识融合可以剔除冗余的、不正确的概念,并为概念消歧,从而提升获取的信息的质量。知识融合通常分为两步:实体链接和知识合并。实体链接即将抽取出的实体对象链接到知识库中的正确的实体对象[12]。
本系统的数据来源为专业领域的数据库,所以实体存在歧义的现象较少,但由于来源的数据库不同,因此存在实体对齐和属性融合的问题。数据实体和属性来自于阿里云的CVE库和CNNVD之间交叉互补信息,由于规范不同,故同一漏洞实体字段信息存在一定差异,在知识图谱构建中可能产生歧义,造成系统一定开销,因此需要将两个漏洞库之间的信息进行对齐,统一为本文所构建本体规范的实体和属性字段。以阿里云的CVE库和CNNVD库中编号为CVE-2020-14828的漏洞为例,如图3漏洞知识融合图所示,这两个漏洞属于同一实体,将CVE编号统一规范为“CVE-ID”;阿里云的CVE中的属性字段“漏洞描述”对应CNNVD中的“漏洞简介”,统一规范为“漏洞描述”;阿里云的CVE中的属性字段“披露时间”对应的是CNNVD中“发布时间”,表示的是漏洞的发布时间,统一规范为“发布时间”。实体对齐能够使信息更加规范、准确,有效地减少系统的开销。相同的CVE漏洞,在CNNVD中部分属性字段缺乏,但在阿里云的CVE中能够有效互补,如受影响实体、CVSS得分等,两者交叉互补使得信息更加丰富全面。通过知识融合有效解决了部分字段不匹配问题,建立起异构本体和实例之间的关联关系,实现实体之间的互联互通[11]。

图3 配置漏洞知识融合
(2)知识推理
在知识库的实体关系数据的基础上,经过分析推理,建立实体间新的关联操作就是知识推理。知识推理能够通过从已有的知识关系中分析得到新的知识,从而丰富知识网络。知识推理可以大致分为三种类型:基于传统规则的推理,基于分布式特征表示的推理和基于深度学习的推理[12]。
3.2.3 数据存储
本文选取了Neo4j图数据库来存储安全配置漏洞分析图谱,Neo4j图数据库目前被广泛用于知识图谱的可视化存储,它查询高效,稳定性高,接口丰富且容易扩展功能。Neo4j有许多方法实现数据的存储,常见的有:(1)通过Cypher的create语句,比如“create(n:Label)”;(2)Cypher中的load csv方式;(3)Neo4j官 方 提 供 的neo4j-import工 具;(4)Neo4j官方提供的Java API Batch Inserter;(5)batch-import工具等。其中官方提供的neo4j-import和Batch Inserter仅支持初始化导入,在导入数据的时候必须脱机,停止Neo4j数据库。但由于neo4j-import占用资源少,导入速度快,而Batch Inserter仅支持在Java环境中使用,因此在初次导入数据时,宜选用neo4jimport方式,达到高效快速批量导入数据的目的。在后续进行增量更新的时候,使用Python提供的py2neo库对数据进行进一步的存储。
3.3 图谱构建
本文提出的基于知识图谱的安全配置漏洞分析方法首先从阿里云的漏洞库中提取出CVE漏洞的原始漏洞信息,然后从CNNVD中提取全部的177715条安全漏洞,一并形成漏洞节点。此外对提取出的漏洞原始信息进行半自动化分析,提取出设计的产品及其CVE-ID,形成组件节点,将各类节点及其节点间的信息注入关联分析引擎,对漏洞与组件的关联关系进行梳理。
经过知识融合得到完整的、结构化的配置漏洞知识数据集,可方便后续进行图谱构建。图谱构建选择Neo4j图形数据库,Neo4j提供了大规模可扩展功能,在一台机器上可以处理数十亿节点/关系/属性的图,同时可扩展到多台机器并行运行[9]。图谱构建分为节点创建和关系创建两方面。
3.3.1 知识抽取
根据3.1.2小节中安全漏洞知识库体系结构所需的节点及其知识,对漏洞数据库依次进行信息抽取,并将其整合到csv格式文件中。
3.3.2 节点及关系创建
通过对实体进行分析,构建漏洞节点,节点包括了漏洞CVE编号、漏洞描述、发布时间等漏洞自身的属性,图4所示为cveNode.csv文件。

图4 cveNode.csv文件结构
由于CVE漏洞节点个数较多,因此采用了neo4jimport方式将其导入Neo4j中,首先需要编写脚本将数据存储到csv文件中,通过命令行输入指令如“neo4j-admin import--database=neo4j-nodes=cve="importcveNode.csv"”,即可将CVE漏洞节点上传到名为Neo4j的数据库中。
在节点创建的同时,将关系设计好存入csv文件,并与节点文件一同上传。由于neo4j-import要求目标数据库必须为空时才可以导入数据,因此可以在csv文件中通过表头的“:START_ID,:TYPE,:END_ID”来创建节点与节点之间的关系文件,每行至少三列,分别为头节点、关系以及尾节点,也可以增加节点的标签列使得节点更加完善,如图5所示。最后创建的配置漏洞分析图谱如图6所示。
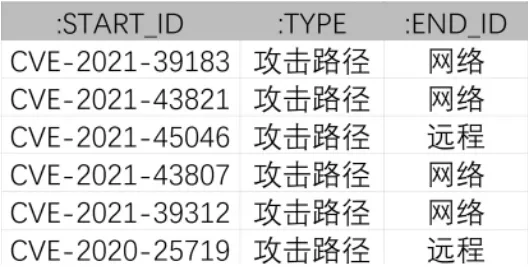
图5 AttackVector.csv文件结构
4 安全配置漏洞知识图谱分析
4.1 知识图谱可视化
本文通过Neo4j知识图谱的可视化,使用cypher查询语句来展现某个节点及其关联的节点和边之间的关联关系。如图7所示,所有CVE节点看似是孤立存在的,但其实都存在关联关系。
由于节点数据量过大,因此无法全面地展示所有CVE节点及其关联关系。本文只截取部分节点示意图用作展示。图8是厂商Huawei制造的部分云服务产品版本,展示了厂商节点和受影响实体之间的关系,通过“制造商”将产品实体与其厂商相关联。
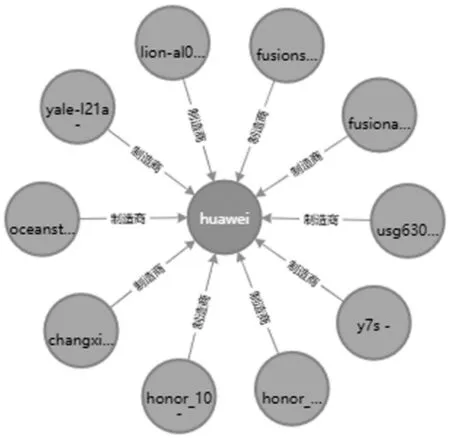
图8 厂商Huawei及其部分产品
通过分析图谱可以看到,一个厂商可能有多种产品,一个产品可能会被一个或多个漏洞影响,图9展示了部分Huawei受到影响的产品名称以及具体CVE漏洞信息。漏洞信息包含了部分漏洞的属性,如CVE编号、漏洞名称、发布时间、漏洞描述等信息。图中展示了两种关系,即漏洞影响产品,产品由制造商制造,通过这两种关系将三类节点关联在一起。

图9 部分节点与产品的关系
4.2 配置漏洞属性分析
漏洞的属性反映了漏洞自身基础信息、漏洞的风险以及目前的修复状况等。通过知识图谱对漏洞属性以及攻击链路属性等进行多维度分析,使漏洞的特征更清晰,可视化界面使研究人员更直观地看到漏洞的状态,以及其可能带来的潜在风险。
从漏洞角度来看,对目前漏洞库进行分析,如图10所示,目前Neo4j中存储CVE漏洞170558个。其中,关于配置错误的漏洞有368个,在总漏洞数中占比0.22%;关于MySQL组件的漏洞有1109个,在总漏洞数中占比0.65%;关于weblogic的漏洞有320个,在总漏洞数中占比0.19%。

图10 漏洞数量查询
4.3 配置漏洞关联关系分析
通过知识图谱中的“关系”,可以从关联关系的角度来对漏洞、攻击以及组件进行可视化分析。通过查询语句:MATCH p=()-[r:′危害等级′]->()RETURN p LIMIT 25,得出图11中的结果。

图11 “危害等级”关系图
其中“危害等级”这个关系记录了CVE漏洞的危害等级,可以根据其等级判断CVE漏洞的危险性。
5 结论
本文主要在知识图谱的辅助下,对软件配置漏洞进行分析,根据目前软件配置漏洞面临的问题现状和知识图谱庞大的知识体量以及多源数据的优势,提出了软件配置漏洞知识图谱构建的思路。通过软件配置漏洞数据处理、软件配置漏洞知识加工、软件配置漏洞图谱构建等技术,构建出适合软件配置漏洞分析的知识图谱,借助知识图谱的可视化效果,更加直接明了地观察到软件配置漏洞导致的问题与可能引发的关联问题,可以辅助完成软件配置的过程,避免一些错误漏洞再次发生。
