基于小波能谱熵和改进ELM 的转辙机故障预测
2022-05-25刘伯鸿王萌萌
刘伯鸿,王萌萌
(兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070)
由于铁道转辙机结构复杂,运行环境多变,导致其故障发生带有不确定性和随机性,难以建立精确的故障分析模型,因此针对转辙机进行故障预测,实现安全预警是十分重要的.在实际运营中,转辙机容易受到环境的影响导致其退化过程具有不稳定性和非线性,因此转辙机故障预测方面的研究较少.故障预测技术作为故障预测与健康管理(Prognostics Health Management,PHM)技术中的核心技术,是在当前设备状态的基础上,综合设备的结构、参数和历史数据对设备未来出现故障的可能性进行分析,得出设备故障发展的趋势并向用户发出报警[1].戴乾军[2]通过计算转辙机剩余寿命达到故障预测的目的,但其需要获取转辙机全寿命周期的数据,工作量较大;文献[3-6]采用不同的算法对道岔或转辙机故障诊断问题进行深入研究,取得了良好的效果,但都未对未来发生故障的可能性进行研究;侯大山[7]提取道岔动作功率曲线时域和频域特征参数进行特征融合,构建道岔退化性能指标,预测道岔发生故障的动作次数,但其特征参数的选取有一定的局限性.本文将采集到的转辙机正常非故障数据进行预处理,提取其特征向量,构建转辙机随动作次数变化的退化性能指标,采用自适应鲸鱼优化算法(Adaptive Whale Optimization Algorithm,AWOA)算法优化极限学习机(Extreme Learning Machine,ELM)的转辙机故障预测方法,实现对S700K 型转辙机故障趋势的预测.
首先,采取完备集合经验模态分解(Complementary Ensemble Empirical Mode Decomposition,CEEMD)方法对转辙机功率数据进行预处理,CEEMD方法能较好地适应转辙机功率信号的非线性、非平稳性;然后提取各个固有模态函数(Intrinsic Mode Function,IMF)的小波能谱熵,构建转辙机退化性能指标,小波分析具备良好的时频局部化优点,IMF 小波能谱是CEEMD、小波分析及信息熵相结合的结果,是信号在时−频域的一种能量表示[8];最后利用AWOA 算法优化ELM 模型值实现对转辙机故障趋势的预测,ELM 方法解决了传统单隐层前馈神经网络(Single-hidden Layer Feed forward Network,SLFN)神经网络参数设定困难和复杂的问题,同时在运算效率和网络训练速度等方面也有显著的提升,AWOA 算法通过对ELM 模型权值与阈值进行全局寻优以提高ELM 模型的预测精度.
1 功率数据预处理
CEEMD 方法待处理信号中加入一对相位相反、幅值相同的白噪声,有效地抑制了模态混叠,并且减小了由白噪声引起的重构误差.本文参考文献[4]的6 种典型故障(如表1 所示),利用相关系数法确定IMF 分量的个数,表示IMF 分量cj与原始信号x的相关系数,计算公式如下:

表1 S700K 转辙机常见故障现象Tab.1 Common failures of S700K switch machine
其中,N为信号长度,x(i)为原始信号,cj(i)为IMF分量,为x(i)的平均值,为cj(i)的平均值.相关系数越大,与原始信号的相关性就越高,越能反映原始信号的物理信息.各种模式的相关系数如图1 所示(f0为正常模式),由于不同模式下,经CEEMD 分解后的IMF 分量各有不同,本文统一选取与原始信号相关性较大的8 个IMF 分量作为此次研究对象,CEEMD 分解效果如图2 所示.
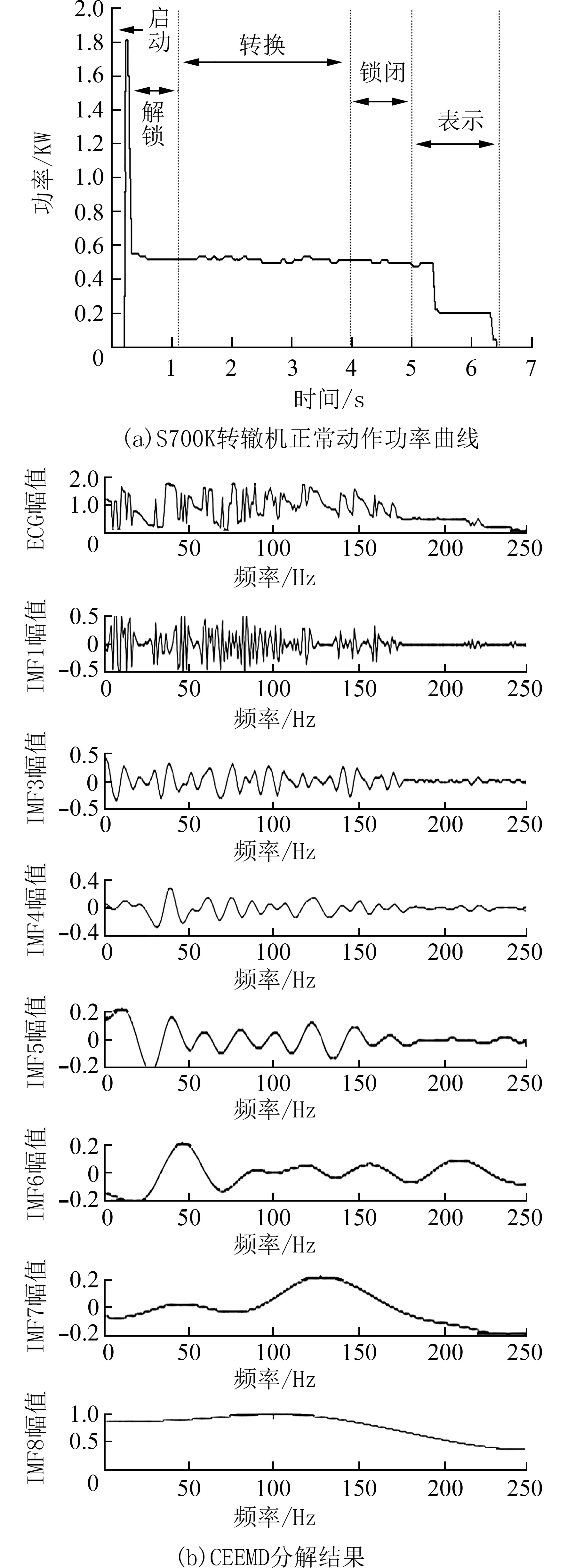
图2 S700K 型转辙机正常动作功率曲线及其CEEMD分解效果图Fig.2 Normal operating power curve and CEEMD decomposition results of S700K switch machine
2 退化性能指标构建
铁路信号集中监测系统中保存的历史数据大部分都是正常数据,但目前针对正常数据的研究相对较少.本文就主要以正常数据为研究对象,从中提取有效信息,构建转辙机退化性能指标,实现对转辙机的故障预测,为转辙机日常维护提供理论依据.
2.1 IMF 小波能谱熵提取S700K 转辙机功率信号一般呈现出非线性、非平稳性的特点,单一变换域的信号分析方法存在着一定的局限性,而小波分析则有着较好的时频局部化的优点.将CEEMD、小波分析和信息熵相结合,就构成了IMF 小波能谱熵,表示信号在时−频域的能量.IMF 小波能谱熵提取步骤如下:
步骤 1对各个IMF 分量采用3 层小波分解,分解结构如图3 所示.

图3 IMF 分量3 层小波分解结构图Fig.3 3-level wavelet decomposition structure diagram of IMF component
图3 中,S为待分解信号,Ca1、Ca2、Ca3为低频分解系数,Cd1、Cd2、Cd3为高频分解系数,小波基为db4.
小波变换前后能量是不变的,则小波能量谱:

其中,ψ(w) 是小波基函数 ψ(t) 的傅里叶变换,W(a,b)为信号f(t)的连续小波变换,E(a)表示信号f(t)在尺度a时的能量,E={E1,E2,···,EN}表示相应的N个尺度下的小波能量谱.
步骤 2计算小波能谱熵:

对一个简单的规则的单频信号而言,其能量全部都分布在一个频段内,那么对应的IMF 小波能谱熵值也比较小.但是如果是一个复杂的信号,每一个频段内都有能量分布,IMF 小波能谱差别相对较小,那么得到的IMF 小波能谱熵值也就相对较大.图4 所示为转辙机功率信号在7 种模式下的小波能谱熵.当转辙机在正常工作时,其功率信号的能量均匀地分布在整个谱中,不确定性较大,熵值偏大;当出现故障时,能量分布较为集中,不确定性较小,熵值也就偏小.然而由于信号选择的具有随机性,导致该数据段信号的熵值可能存在正常状态下的熵值小于故障状态下熵值的情况,但总体上而言,信号熵值分布上的差异性,体现出了不同模式间信号能量分布的特点.

图4 各种模式下小波能谱熵分布情况Fig.4 Distribution of wavelet energy spectrum entropy in different modes
2.2 退化性能指标建立本文选取S700K 型转辙机正常动作功率数据488 组,按动作时间的先后顺序排列;6 种典型故障每种故障取2 组功率数据,总共12 组故障数据,随机排列;采用CEEMD 方法对选取的功率数据进行预处理.功率数据经CEEMD 预处理后,计算各IMF 分量的小波能谱熵值,得到能表征转辙机功率数据特征的8 维特征向量,为实现转辙机的故障预测,需要对此8 维特征向量进行降维处理.采用KPCA 方法对特征向量进行降维,KPCA 是传统PCA 的改进形式,其主要思想就是用核方法的优势来处理非线性问题.本文采用的KPCA 方法构建转辙机退化性能指标,具体步骤如下:
步骤 1将得到每一维小波能谱熵值减去该维小波能谱熵值的平均值;
步骤 2计算核函数矩阵;
步骤 3计算核函数矩阵的特征值以及特征向量;
步骤 4按照特征值从小到大的顺序将特征向量进行排列,取前k行;
步骤 5前k行组成的矩阵即为新的k维数据,本文k=1.
本文核函数选择的是高斯径向基函数,参数sigma 设定为1,将8 维特征向量作为输入,得到1维转辙机退化性能指标属性值,如图5 所示.
由图5 可以看出,随着转辙机动作次数的增加,退化性能属性值虽然在小范围内有波动,但总体呈现单调递增的趋势.1~200 次,退化性能指标属性值波动范围较小,变化平稳;200 次以后的波动范围明显变大,变化较为明显,尤其在250~300 次变化最为明显;300~400 次属性值波动范围略大,但总体变化趋势较为平稳,在400~488 次,属性值最达到0.758,12 组故障数据的属性值在0.762 到0.894 之间,因此选定0.76 作为失效阈值,如图5 中的红线所示.

图5 转辙机退化性能指标属性值Fig.5 Attribute value of point machine degradation performance index
3 改进ELM 的转辙机故障预测
3.1 自适应鲸鱼优化算法(Adaptive Whale Optimization Algorithm,AWOA)2016 年,澳大利亚学者Mirjalili 在观察鲸鱼捕食时受到启发提出一种新的智能优化算法−鲸鱼优化算法(Whale Optimization Algorithm,WOA)[9].WOA 算法的核心思想是通过模仿鲸鱼捕食行为来求解目标问题[10],其主要包括3 个部分:包围捕食、螺旋更新位置和随机搜索.
3.1.1 鲸鱼优化算法(Whale Optimization Algorithm,WOA)
(1)包围捕食.当座头鲸发现猎物后,所有鲸鱼迅速调整更新自己的位置向着最优位置收缩包围,此过程的数学模型为:

其中,X(t)是当前鲸鱼所在位置,t是当前迭代的次数,X'(t)是猎物所在的位置,A和C表示系数向量.A、C计算公式为:

其中,r表示一个在[0,1]区间上的随机数,a为控制参数,它将随着迭代次数的增加从2 逐渐递减为0,即:

其中,Tmax表示的是最大迭代次数.
(2)螺旋更新位置.在鲸鱼向猎物进行气泡攻击的同时,螺旋式游动向着最优解靠近,达到局部寻优的目的,其计算公式为:

其中,D=|X'(t)-X(t)|表示的是鲸鱼和猎物间的距离,l为[−1,1]区间上的随机数,b为常量系数,一般设为1.
(3)随机搜索.鲸鱼搜索猎物的过程中,当|A|>1时,在随机群中选取一个鲸鱼位置作为参考,
以参考鲸鱼的位置为基础随机对猎物进行搜索并更新其他鲸鱼的位置,以此达到全局寻优的目的.其模型为:
其中,Xrand表示参考鲸鱼位置.
3.1.2 AWOA 算法 AWOA 算法的核心思想是根据权重大小自适应地调整搜索方式.权重大,搜索范围也随之变大,权重小,就对局部进行较为精确的搜索.当鲸鱼靠近猎物时,权重较小,利用对局部进行精确搜索的特点来更新最优鲸鱼位置,进而使局部寻优的能力得到提升.即:
其中,t是当前迭代的次数,ω是自适应权重,Tmax是最大迭代次数.用式(11)对式(6)进行改进,即:

3.2 AWOA 算法优化ELM 的转辙机故障预测模型由于ELM 的权值和阈值是随机产生的,一般得不到最优的参数[11-13],所以利用AWOA 算法对传统ELM 模型的权值和阈值进行优化.首先,假设当前最优解是距离猎物最近的位置;当|A|>1时,对猎物进行随机搜索,根据最低适应度值来确定最优个体所处的位置,然后将得到的最优权值和阈值赋给ELM 模型,具体步骤如下:
步骤 1随机地选取权值和阈值,确定寻优范围.
步骤 2设置相关参数.本文ELM 模型的隐含层节点个数设为6,初始化鲸鱼个体的位置,AWOA 算法的上下界设为[−1,1],种群数量设为300,最大迭代次数为100.
步骤 3输入训练集和测试集样本.将前450组数据作为训练集,后50 组数据作为测试集.
步骤 4在达到最大迭代次数之前不断地更新最优个体的位置,根据最低适应度得到最优解.
步骤 5将得到的最优参数输入到ELM 模型.
4 实例分析
本文用Matlab 软件进行仿真,利用选取的500 组功率数据计算出其退化性能指标属性值,前450 组作为训练集,后50 组作为预测集,采用本文所提出的方法对该转辙机进行故障预测,并与ELM 和SVM 预测方法进行比较.选择均方误差和决定系数作为[14]预测效果的评价指标,均方误差越小,预测精度越高,假设有n个预测值,每个预测值的误差为ε1、ε2,···,εn,则此组预测值的均方误差σ为:

决定系数是相关系数的平方(相关系数表示预测值与期望值之间的相关度),决定系数越接近1,则预测模型参考价值越大,其计算公式如下:
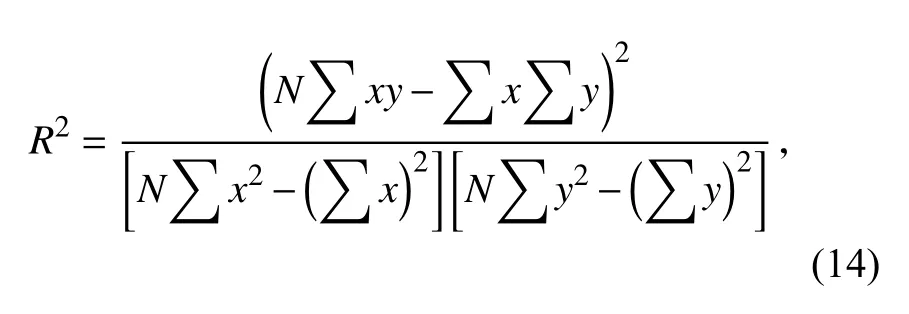
其中,x表示预测值,y表示实测值,N表示数据个数,本文N=n=50,预测结果如图6 所示,各预测模型评价指标对比如表2 所示.
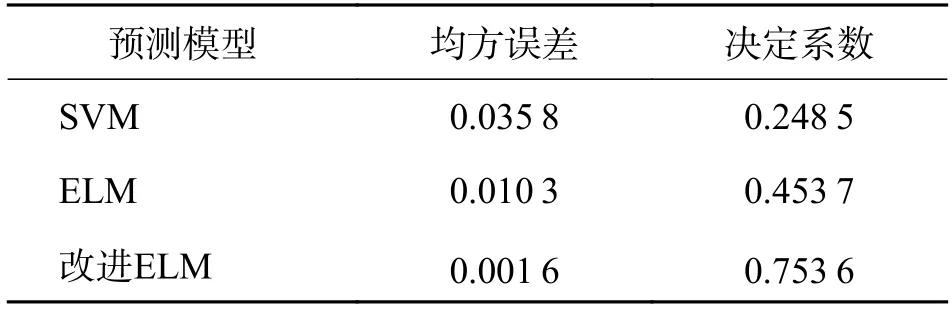
表2 各预测模型评价指标对比Tab.2 Comparison of evaluation indexes of each prediction model

图6 改进ELM 预测结果图Fig.6 The prediction result of improved ELM
从图6 中可以看出,在将要发生故障时(485~487 次)预测值稍有波动,但波动范围较小,在488~500 次中,预测出现故障的动作次数与实际故障发生次数相差已较小.
从表2 可以看出,改进ELM 预测模型均方误差比前两者较小,决定系数比前两者较高,且更接近于1,说明预测效果优于其他两种传统预测模型.
5 结论
本文采用小波能谱熵和AWOA 算法优化ELM 的转辙机故障预测方法,将CEEMD 方法、小波分析和信息熵3 种方法结合在一起,提取各个IMF 分量的小波能谱熵值,构建了转辙机的退化性能指标;利用AWOA 算法对ELM 预测模型的权值和阈值进行优化,预测转辙机发生故障的动作次数.通过实例仿真证明了AWOA 算法有效地优化了ELM 预测模型的始权值和阈值,与传统预测模型相比,AWOA 算法优化ELM 模型的均方误差小于0.002,决定系数更接近于1,表明该模型的预测精度更高,性能更好.由于本文收集的样本数据有限,下一步将尽可能多地收集更全面的样本数据,进一步提高模型预测精度.
