基于CNN和犹豫模糊决策的欺诈攻击检测
2022-05-25蔡红云袁世林任继超
蔡红云,袁世林*,温 玉,任继超,孟 洁
(1.河北大学 网络空间安全与计算机学院,河北 保定 071000;2.河北省高可信信息系统重点实验室,河北 保定 071000)
互联网技术的发展不断刺激着信息资源的快速增长,在大量的信息交互过程中,信息过载已经成为数字行业中的一种普遍现象,由此推动了推荐系统的产生。在众多的推荐方法中,协同过滤推荐是使用最为广泛的一种,尤其是随着深度学习在推荐领域的应用,融合深度学习和协同过滤的推荐系统得到深入研究。然而,由于推荐系统的开放性,协同过滤推荐系统中存在欺诈攻击风险,即恶意用户通过向推荐系统中注入大量设计好的虚假评分概貌达到影响推荐结果的目的。已有研究表明,这些欺诈评分概貌的存在严重影响了推荐结果的准确性,降低了推荐用户对系统的满意度,由此制约了推荐系统的良性健康发展。
自推荐系统中的欺诈攻击问题被发现以来,国内外学者围绕欺诈攻击检测问题展开了深入研究。早期的检测方法大多依赖于人工特征提取,通过有监督学习或无监督学习对特征进行分类或聚类识别出攻击概貌。Chirita和Burke等最先从用户对评分项目的评分值入手,基于用户评分概貌上的评分统计差异提取检测特征。Yang等在已有基于评分值的检测特征基础上进行了扩展,利用集成学习构建分类器。随后,李文涛等针对已知攻击类型,从用户评分项目流行度入手,提出了基于流行度分类特征的托攻击检测方法。Zhou等提出了一种基于SVM和目标项目分析的托攻击检测方法SVM-TIA,从研究攻击概貌的群体特征角度出发,基于人工特征训练SVM分类器,对用户进行初步划分,然后利用目标项目分析从可疑用户候选集中过滤出真正的攻击者。Zhang等从用户评分行为角度出发,提出了一种基于隐马尔可夫和层次聚类的托攻击检测方法UD-HMM;该方法利用隐马尔可夫模型对用户评分项目序列建模,使用层次聚类找出用户可疑度高的攻击用户。Dou等提出了一种基于决策树和隐含因素的方法即CoDetector;该方法通过矩阵分解和词嵌入的方式细化用户和项目之间的隐含关系,将学习到的包含网络嵌入信息的用户隐含因素作为特征来检测攻击者;该方法主要适用于大攻击规模下的用户检测,小攻击规模的攻击检测性能受限。Hao等从用户评分时间和项目新颖性方面设计了17个用户特征,构建了基于集成学习的有监督检测方法。在作者以前的工作中,基于真实用户和攻击用户的评分兴趣差异提取检测特征,利用攻击用户行为相似性识别出攻击用户。基于人工提取特征的检测方法在很多攻击场景下均能有效检测攻击概貌,但人工特征的提取需要依赖专家知识,而且特征的有效性往往与数据集及攻击模型密切相关。
针对人工提取检测特征的局限性,Zhang等提出了基于标签传播的攻击检测方法,利用用户与项目间的评分关系计算用户和项目的可疑度,该方法的检测性能与攻击模型无关,但需事先标记出一些种子用户,且种子数量多少和检测性能有直接关系。目前,深度学习理论在语音识别、机器翻译、图像分类等方面取得了快速发展,这也推动了更多的研究者尝试利用深度学习自动提取检测特征进而识别推荐系统中的攻击概貌。Tong等提出了基于CNN的检测方法CNN-SAD,该方法从评分概貌的评分值视角学习用户低维向量,但未能从用户行为的不同视角学习更全面的深层次特征,使得在真实数据集下的检测性能并不理想。Hao等提出了基于自编码器的特征提取方法SDAEs-PCA,在用户低维向量基础上使用PCA和SVM识别出攻击概貌;该方法先将用户对项目的评分值、用户评分项目的流行度以及用户-用户关系这3方面分别学习到的用户低维向量拼接,再利用弱分类器检测出攻击用户;该方法在多个数据集上都具有良好检测性能,但未挖掘用户在时间维度上的关系特征。Zhang等提出了一种基于图卷积网络和神经随机森林的托攻击检测方法GraphRfi;该方法将系统中稳定的推荐机制与攻击用户检测结合起来,利用推荐系统中对用户评分预测的误差作为计算用户可疑度的主要依据来检测恶意用户,同时将用户被检测为攻击用户的概率值作为权重来降低攻击用户的评价对推荐系统的影响,提高了用户检测的精确率;但该方法需要较多的超参数,攻击检测的效果容易受超参数取值影响。Ebrahimian等提出了融合卷积神经网络和循环神经网络的攻击检测模型;该方法利用了循环神经网络的时间有序性,将通过卷积神经网络提取后的特征向量输入循环神经网络,最终完成对用户的二元分类问题;在Netflix和MovieLens 1M数据集中的实验表明,随着填充规模的增大,该方法的精确率明显偏低。Vivekanandan等提出了基于卷积神经网络和长短期记忆(LSTM)的攻击检测模型;该方法先利用用户-项目评分矩阵、用户-项目流行度矩阵和用户-用户邻接矩阵,训练CNN分类器,再通过LSTM对学习到的用户特征进一步筛选和融合,最终利用softmax实现对用户的二元分类;该方法对低填充规模的攻击具有较好的检测效果,但填充规模增大时检测效率下降。Zhou等提出一种基于深度学习的检测方法DL-DRA,该方法采用插值算法解决输入评分矩阵的稀疏性问题,提高了检测性能,但其仅考虑了用户评分的单一视角。深度学习模型作为一个自动特征提取器,主要负责提取对评分用户分类最有效的深层次特征,将带有标签的样本放入神经网络下不断训练,得到训练过程中的最优参数。基于深度学习的推荐攻击检测方法取得了较好的分类效果,但仍存在一定的局限性。一方面,已有方法往往多基于单一的评分值视角,忽略了用户在评分时间及评分项目偏好方面上的行为特征,使得所提检测方法的检测准确性有待提升;另一方面,尽管已有基于多视图的深度学习检测方法,但这种将不同视图的用户低维向量进行简单拼接的方法仍不能获取较高的准确率。
针对以上局限性,本文提出了一种基于CNN和犹豫模糊集的欺诈攻击检测方法,简称 CNN-HFS(convolutional neural networks and hesitant fuzzy sets),从评分行为的时间和空间两方面入手,基于CNN自动学习不同视图下的特征向量并训练CNN分类器,利用犹豫模糊集群决策方法识别出攻击概貌。与作者之前的工作相比,CNN-HFS克服了人工提取检测特征的局限性;与自动提取特征的CNN-SAD和SDAEs-PCA相比,CNN-HFS基于用户评分值、偏好及时间等多维特征进行了综合决策。MovieLens 1M和Amazon数据集上的实验表明,所提方法相较于已有方法,在不依赖专家知识提取检测特征的同时能更有效地提高检测性能。
1 背景知识与相关理论
1.1 攻击模型
在协同过滤推荐系统中,攻击者可以通过生成一组虚假评分概貌实现对目标项目的推攻击或核攻击。通常来说,一个攻击概貌中包括选择项目集I
、填充项目集I
、 未评分项目集I
和 目标项目集I
。对于不同攻击模型,选择项目和填充项目的选取及评分策略有所差异。本文中的4种典型攻击如下:1)随机攻击(random attack)。I
为 空集,I
中的项目是从非目标项目中随机选取。填充项目上的评分遵循整个评分集的评分均值和评分方差的正态分布。若攻击意图为推攻击,则对目标项目评为最高分;否则评最低分。2)均值攻击(average attack)。I
和
I
的选取方式同随机攻击一致。填充项目评分遵循对应项目评分的正态分布。目标项目的评分根据攻击意图不同分别为最高分或最低分。3)AoP攻击(average over popular attack)。I
为空集,I
从
X
%的流行项目中随机选取。填充项目上的评分值生成方法同均值攻击。4)用户偏移攻击(user shifting attack)。I
为空集,I
从非目标项目中随机选取。不同于均值攻击,对填充项目的评分在标准均值攻击基础上增加一个随机噪声。目标项目评分为推攻击下的最高分或核攻击下的最低分。1.2 相关理论
1.2.1 双三次插值法
双三次插值(bicubic interpolation)是一种常用的图像或视频压缩方法,图像缩放过程中不会过多地改变图像的整体特征,插值前后图像的差异仅体现在大小和分辨率方面。在2维空间中,图像可以表示为像素点矩阵M
=[X
,Y
]。假设原图像维度分别被缩放t
倍和t
倍,压缩后图像的像素点矩阵记为N
=[X
,Y
],即m
=「m
/t
」和n
=「n
/t
」。在双三次插值中,矩阵N
中任意一点o
(x
,y
)均可由图1所示的原矩阵中的16个像素点生成。由图1可知:点o
(x
,y
)由t
×x
=x
和t
×y
=y
确定;为便于表述,将这16个像素点的值依次记为c
,c
,···,c
,c
。
图1 双三次插值Fig. 1 Bicubic interpolation
图1中,每个像素点o
(x
,y
)(
i
,j
∈{0,1,2,3}) 与点o
(x
,y
)间 的距离决定该像素点的权重W
,计算公式为:
w
()为像素点在水平方向或者竖直方向的权重函数,若每个像素点的横坐标与点o
的横坐标差值为Δx
,则计算公式为:
a
为计算系数,其值依赖于插值算法的特性,通常取-0.5。综合图1中16个像素点的权重及对应像素点的权值,可得到矩阵N
中o
(x
,y
)的 像素值c
,计算公式为: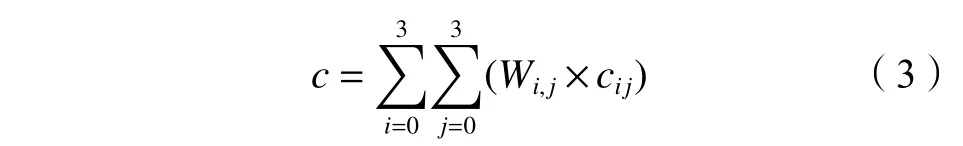
1.2.2 卷积神经网络
卷积神经网络(convolutional neural networks,CNN)是一种前馈人工神经网络,能够在训练过程中自动获取隐式的低维特征向量。由于CNN具有处理多维数据的能力,目前被广泛应用于文本分类、图像识别等多个领域。此外,CNN可将文本信息转化为对应的词向量后进一步提取特征向量,因此也可用于“长度短,特征维度小”的短文本(例如口令)预测。标准的CNN模型结构如图2所示,主要包括输入层、卷积层、池化层、全连接层和输出层。通常在一个完整的卷积神经网络会包含多个卷积层和池化层,卷积层和池化层的通道数由该层对应的卷积核或池化核数量决定。

图2 卷积神经网络结构Fig. 2 Convolutional neural network structure
图2中:CNN的输入层通常是矩阵(例如图像对应的像素点矩阵);卷积层利用卷积核对输入矩阵执行深层次的特征提取;池化层是对卷积后的矩阵进行降维;通常每个卷积层后都有一个池化层,通过卷积层和池化层的多层级联后构成整个深度网络;全连接层在池化层之后,用于将卷积和池化处理后获取的特征向量展平为1维的向量表示,进而传送给输出层;最后由输出层执行分类或回归操作。
1.2.3 犹豫模糊集
犹豫模糊集(hesitant fuzzy set,HFS)是对模糊集的一种推广,被广泛应用于决策、人工智能和预测等方面。其特性为:在分类问题或决策问题中,当判断一个样本对不同类别集合的隶属度时,不同决策者可能会产生不同的决策值。
令X
={x
,x
,···,x
} 为 非空属性集,若∀x
∈X
都对应一个隶属度的集合h
(x
),E
={〈x
,h
(x
)〉|x
∈X
}称为属性集X
上的犹豫模糊集。其中,h
(x
)也被称为犹豫模糊元(hesitant fuzzy element,HFE)。每个犹豫模糊元可包含一个或多个评价值,h
(x
)∈[0,1]为对应犹豫模糊元的第j
个元素。例如,一个项目共有n
个属性,每个属性有j
个专家对属性进行评分,则称评分所构成的集合为一个犹豫模糊元,n
个属性与其对应的犹豫模糊元构成的集合称为犹豫模糊集。若E
和
E
是两个样本在同一个属性集X
上对应的犹豫模糊集,通过计算两个犹豫模糊集合之间的广义犹豫模糊距离可度量两个样本在属性集X
上的相似程度。距离越小,则样本间相似度越大;反之,亦然。犹豫模糊集间的广义犹豫模糊距离计算公式为:
l
为 属性值x
对应的犹豫模糊元中的元素个数,λ为控制参数。当λ=1时,式(4)距离即为犹豫标准汉明距离;当λ=2时,式(4)距离则为犹豫标准欧氏距离。2 CNN-HFS模型
本文提出的基于CNN和犹豫模糊集的检测方法CNN-HFS的检测框架,如图3所示。
从图3可以看出,CNN-HFS主要包括3个阶段:基于时空特性的低维矩阵构建、基于CNN的攻击隶属度计算及基于广义犹豫模糊距离的犹豫模糊决策。1)先对每个用户分别从评分值、评分偏好和评分时间这3个视角抽取3个行为矩阵,再通过双三次插值法对3个矩阵进行缩放得到对应的低维矩阵;2)将每个用户任意视角下的行为矩阵视为一个图像,在3个不同视角下分别训练CNN,计算任意用户在每个视角下属于攻击用户类的隶属度;3)根据每个用户在多视角下的隶属度,构建用户的犹豫模糊集合,利用广义犹豫模糊距离计算用户属于攻击用户类的综合隶属度,将超过阈值的用户识别为攻击用户。

图3 CNN-HFS框架Fig. 3 CNN-HFS framework
2.1 基于时空特性的低维矩阵构建
受人工特征提取方法的启发,CNN-HFS模型同时考虑攻击用户和真实用户在用户-项目的评分值、评分时间及评分偏好上的差异。
定义1
(低维用户评分矩阵) 对于用户集U
中任意用户u
,其低维用户评分矩阵指在基于评分值概貌转换得到的矩阵基础上缩放得到的密集矩阵,记为R
。令项目集为I
,任意用户的评分概貌为1×|I
|的向量,将该向量转换为n
=维原始用户评分方阵R
。R
中j
行k
列的元素为:
r
为用户对项目集中第(j
−1)×n
+k
个项目的评分值。考虑到用户已评项目数量通常远少于项目集规模,由评分概貌直接转换得到的矩阵会较稀疏,不利于下一阶段CNN的分类。为此,本文采用双三次插值法对任意用户u
∈U
的原始评分矩阵R
进行缩放,缩放后得到矩阵R
。定义2
(低维用户时间矩阵) 对于用户集U
中任意用户u
,其低维用户时间矩阵指在基于排序后的评分时间概貌转换得到的矩阵基础上缩放得到的密集矩阵,记为T
。令数据集中最早评分时间为第0天,最晚评分时间为截止时间,按天数递增顺序排列,总时间跨度为D
。将评分时间概貌变换为维度为n
=的原始用户评分方阵T
。T
中
j
行k
列的元素为:式中,t
为用户在第(j
−1)×n
+k
天内发生评分行为的次数。采用双三次插值法对任意用户u
∈U
的原始用户时间矩阵T
进 行缩放,缩放后得到矩阵T
。定义3
(低维用户偏好矩阵) 对于用户集U
中任意用户u
,其低维用户偏好矩阵指在基于项目流行度概貌转换得到的矩阵基础上缩放得到的密集矩阵,记为P
。用户所评项目流行度能在一定程度上反映用户的兴趣偏好。项目流行度大小即项目上的评分数量多少,被评次数最多的项目被认为是最流行的项目。因此,将项目集中所有项目依据项目流行度大小进行重排,按照原始用户评分矩阵的生成方式建立原始用户偏好矩阵。令排序后的项目集为L
,任意用√户的评分概貌为1×|L
|的向量,将该向量转换为n
=维的原始用户偏好方阵P
。P
中 第j
行k
列的元素为:
p
为对项目集L
中第(j
−1)×n
+k
个项目的评分值。采用双三次插值法对任意用户u
∈U
的原始用户偏好矩阵P
进 行缩放,缩放后得到矩阵P
。2.2 基于CNN的攻击隶属度计算
在第2.1节中,用户集中的每个用户均构建了3个低维密集矩阵。同一视角下的所有用户矩阵构成一个图像集,用于训练及测试对应的CNN分类器。
在CNN进行特征提取阶段,卷积层一般连接在池化层之前。通常将每个卷积层和相邻的下一层池化层组成的整体视为一层,本文使用了3个完整的卷积池化层,其中:在第1层的卷积过程中,设置64个卷积核,尺寸大小为3×3,卷积遍历步长为1,边缘外自动补0;在第2层和第3层的卷积过程中,卷积核分别设置为32和16。为了提取用户更深层次的特征,采用多个卷积核分别进行卷积运算,上一层输出的特征图与每个卷积核进行卷积运算后都对应一张特征图。假定有n
个卷积核,则卷积后输出n
张特征图。若第l
层为卷积层,第l
+1层 为池化层,则第l
层第j
个特征图的计算公式为: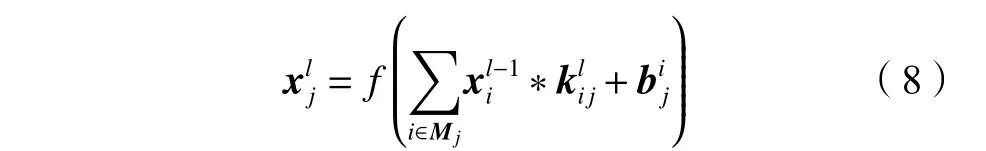
x
为第l
层第j
个特征图,M
为第l
−1层输出的特征图集合,x
为第l
−1层 第i
个特征图, ∗为输入特征图和卷积核的卷积运算,卷积核k
为l
层 中第j
个卷积核中的第i
个 通道,b
为偏置参数,f
()为激活函数。池化操作是对卷积后的特征图进行降维,目的是加快计算速度并防止过拟合。对于池化层,有n
个输入特征图,则输出n
个特征图。池化操作并不改变特征图的数量,只改变特征图的大小,包括平均池化和最大池化两种,本质都是对上一层的特征矩阵中的元素加权求和。平均池化中每个特征元素权重都一样;最大池化中最大元素对应位置的权重为1,其余为0。假设第l
层池化层,第l
− 1层为卷积层,则池化计算公式为: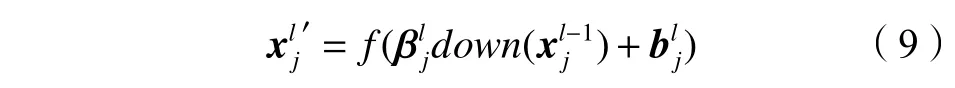
x
为第l
层池化操作后输出的特征图;x
为第l
−1层 卷积层的输出特征图;d
own
()为下采样函数其典型的操作是将特定尺寸大小的池化核与输入图像中相同尺寸的像素块进行同位相乘并求和,以达到特征降维的效果; β为权重矩阵。,CNN-HFS中,设置池化核大小为3×3,采用最大池化方式,步长为2,边缘外设置自动扩充为0。第3层池化之后通过连接两个全连接层将特征矩阵展平为1维特征向量。为了提高模型的泛化能力,防止过拟合,将训练过程中的特征向量随机去除一部分,再输入softmax层进行分类,同时得到每个用户在对应CNN分类器下属于攻击用户类的隶属度。本文设置dropout操作的破坏率参数值为0.5。
定义4
(攻击隶属度) 对任意用户u
∈U
,其在评分值、评分偏好和评分视角对应CNN中被识别为攻击用户的概率称为相应视角下的攻击隶属度,分别记为L
、L
、L
。攻击检测被视为二分类问题,CNN中全连接层的特征向量与权重矩阵相乘得到 (c
,c
),经过softmax函数得到用户在此CNN中被识别为攻击用户的概率,即攻击隶属度,计算公式为: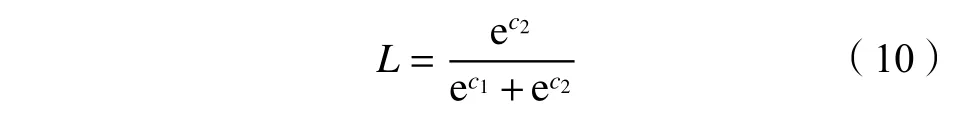
c
为 正常用户特征神经元;c
为恶意用户特征神经元; e为自然常数,其值约为2.718 2。2.3 基于广义犹豫模糊距离的多属性决策
基于第2.2节的3维攻击隶属度,使用广义犹豫模糊距离进行多属性决策。考虑到用户评分矩阵和用户偏好矩阵都与被评项目有关,而用户评分时间是从时间角度切入,将前两个视角下对应的攻击隶属度划分到空间属性下的隶属度,而后者对应的攻击隶属度称为时间属性下的隶属度。令x
为空间属性,x
为 时间属性,则属性集合X
={x
,x
}。定义5
(用户犹豫模糊集) 对任意用户u
∈U
,其犹豫模糊集指两类属性对应犹豫模糊元的集合,记为E
={〈x
,h
(x
)〉|x
∈X
} 。其中:属性x
对应的犹豫模糊元为h
(x
) , 包含L
和L
两类隶属度;属性x
的犹豫模糊元为h
(x
), 即隶属度L
。令绝对恶意用户a
在两类属性的攻击隶属度值均为1,即h
(x
)={1,1}和
h
(x
)={1},犹豫模糊集合E
={〈x
,h
(x
)〉|x
∈X
} 。对任意用户u
,计算其犹豫模糊集合与绝对恶意用户的犹豫模糊集合间的广义犹豫模糊距离d
,若该距离大于阈值则将该用户识别为攻击用户,否则视为真实用户。用户间的犹豫模糊距离计算公式为: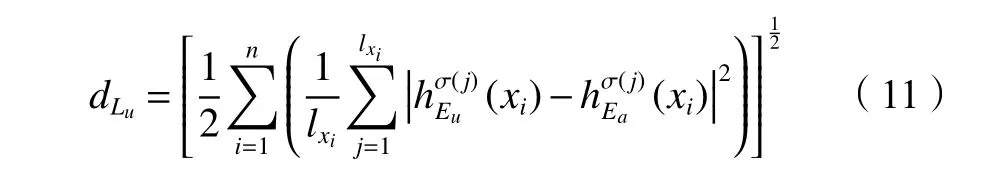
3 实验评估
3.1 实验数据集和参数设置
MovieLens 1M:该数据集中包含6 040个用户对3 952个电影项目的1 000 209个评分和评分时间。评分值均为1~5之间的整数,评分值越高代表用户对项目的满意度越高。类似于已有研究,将数据集中所有用户均看作为正常用户。实验中,根据攻击模型、攻击规模、填充规模产生攻击概貌并注入到训练集和测试集中。攻击规模(attack size,as)设置为{3%,5%,10%,12%},填充规模(filler size,fs)设置为{3%,5%} ,攻击类型为随机攻击、均值攻击、AoP攻击和偏移攻击,目标项目从非流行项目中随机选取。每次实验,在真实概貌和攻击概貌中各选取80%用于训练,剩余20%作为测试集。采用五折交叉验证,取检测结果平均值为最终实验结果。
Amazon抽样数据集:该数据集从Amazon.cn爬行到645 072个用户对136 785个项目的评分及评分时间。为便于检测方法性能对比,使用文献[20]提供的由5 055个标记用户评分历史构成的抽样数据集,共包含17 610个项目上的53 777个评分和评分时间戳。其中,攻击用户和真实用户数量分别为3 118和1 937。实验按照训练集和测试集4∶1比例划分数据集,采用五折交叉验证方式,取平均检测结果为最终实验结果。
实验中,设置CNN全连接层的特征向量节点数为128,破坏率为0.5,学习率为0.000 1。基于犹豫模糊距离决策阈值是依据用户攻击隶属度确定的。在实验过程中容易发现,利用深度学习方法,可以根据提取的特征向量在一定的程度上区分正常用户和恶意用户,但基于数据不均衡和数据稀疏性问题,对用户的二元分类阈值往往并不能以0.5值进行简单的划分,因此本实验借鉴文献[35]所提阈值选取方法。首先,按照用户隶属度值的大小对用户进行降序排列;然后,计算各相邻用户之间的隶属度差值,构成隶属度差值集合;最后,取集合中的最大值作为距离阈值。根据上述方法,在MovieLens 1M数据集中阈值取0.75,在Amazon数据集中阈值取0.57。实验采用五折交叉验证,取5次实验结果的平均值作为对应场景下的检测结果。
3.2 评估指标
为评估本文所提CNN-HFS方法在两种数据集中的检测性能,使用精确率(precision)、召回率(recall)和F1-measure值作为检测指标,分别以P
、R
、F
表示。其中,F1-measure值是精确率和召回率的加权调和平均,其值越高表明对应方法的整体检测性能越好。3个指标的计算公式分别为: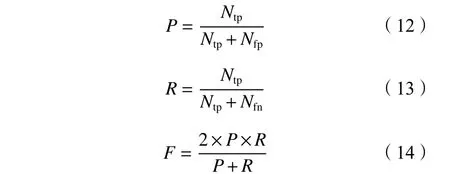
N
为样本中被正确检测出的攻击用户数量,N
为样本中的攻击用户被误判为真实用户的数量,N
为样本中的真实用户被误判攻击用户的数量。3.3 实验结果及分析
为验证本文所提CNN-HFS方法的有效性,实验选取SVM-TIA、CoDetector、CNN-SAD、SDAEs-PCA、CNN-R、CNN-P和CNN-T作为对比方法。其中:SVM-TIA是基于人工提取特征的有监督检测方法,CoDetector利用自动获取的用户和项目间的隐含关系识别攻击用户,CNN-SAD从用户评分值视角学习用户低维向量训练CNN分类器以识别攻击概貌,SDAEs-PCA将用户评分值、评分项目流行度及用户间关系这3方面学习到的用户低维向量拼接成一个向量,CNN-R是仅基于低维用户评分矩阵训练CNN分类器,CNN-P是仅基于低维用户评分偏好矩阵训练CNN分类器,CNN-T是仅基于低维用户时间矩阵训练CNN分类器。
3.3.1 MovieLens 1M数据集上检测结果及分析
将上述8种检测方法在MovieLens 1M数据集中4种攻击模型下的精确率进行对比,实验结果如图4所示。
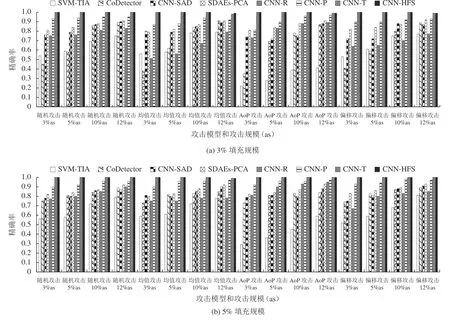
图4 8种检测方法在MovieLens 1M数据集上的精确率对比Fig. 4 Comparison of precision for eight detection methods on MovieLens 1M dataset
从图4可看出:相比于其他7种检测方法,CNNHFS方法对不同攻击规模和填充规模的4种攻击模型均具有更优异的精确率,在AoP攻击下与SVM-TIA方法相比其精确率优势明显,这表明尽管基于AoP攻击模型注入的攻击概貌更接近于真实概貌,但CNNHFS方法通过综合多视角进行决策仍能准确识别攻击概貌。与CoDetector方法相比,CNN-HFS方法在检测低攻击规模和填充规模的攻击模型时,仍保持高精确率,其原因是CNN-HFS方法在生成低维用户矩阵时采用插值算法降低矩阵的稀疏性。CNN-SAD和SDAEs-PCA方法均利用自动提取特征的深度学习方法,精确率要明显优于传统的人工提取特征方法,但仍低于CNN-HFS方法。主要原因是CNN-SAD方法仅利用用户评分矩阵提取特征;SDAEs-PCA方法虽然从多角度提取特征,但仅对特征向量进行简单的拼接;CNN-HFS方法在多视角特征提取基础上融合模糊决策,进一步提高精确率。CNN-R和CNN-P方法在精确率方面均低于CNN-HFS方法,CNN-T方法则和CNN-HFS方法一样具有优异的精确率,这表明在MovieLens 1M数据集上,攻击用户和真实用户在评分时间上比评分值和评分偏好上具有更明显的行为差异。
将上述8种检测方法在MovieLens 1M数据集中4种攻击模型下的召回率进行对比,实验结果如图5所示。从图5可以看出:SVM-TIA方法在不同攻击模型下的召回率较低,尤其是对于AoP攻击。CoDetector和CNN-SAD方法在随机攻击、均值攻击和AoP攻击下,填充规模3%时的召回率均明显低于填充规模5%时的召回率,表明CoDetector和CNN-SAD方法的召回率易受填充规模大小的影响。SDAEs-PCA方法在4种攻击模型下均具有优异的召回率,表明基于用户多维特征拼接的分类器能够将攻击用户分为一类。CNNR方法在攻击规模小于5%时的召回率较低,这是由于数据集中正负样本严重失衡,导致CNN-R方法将不少攻击概貌误判为真实概貌。CNN-P方法的召回率随着攻击规模和填充规模的增加有明显的提升,并且在4种攻击模型下均优于CNN-R方法,但仍低于CNN-HFS方法。CNN-T方法在同种攻击模型和攻击规模下,填充规模为5%的召回率要远远优于填充规模为3%的召回率,这表明填充规模的大小直接影响CNN-T方法的召回率。当攻击规模为3%时,CNNHFS方法在均值攻击模型下的召回率不如CoDetector、CNN-SAD和SDAEs-PCA方法,这是因为在均值攻击中,由于攻击概貌数量较少,且攻击用户的填充概貌与真实用户概貌在评分方面更为相近,导致部分攻击概貌未被有效区分。尽管如此,从图5中可看出,CNN-HFS方法的召回率在其他情形下均可达到1。
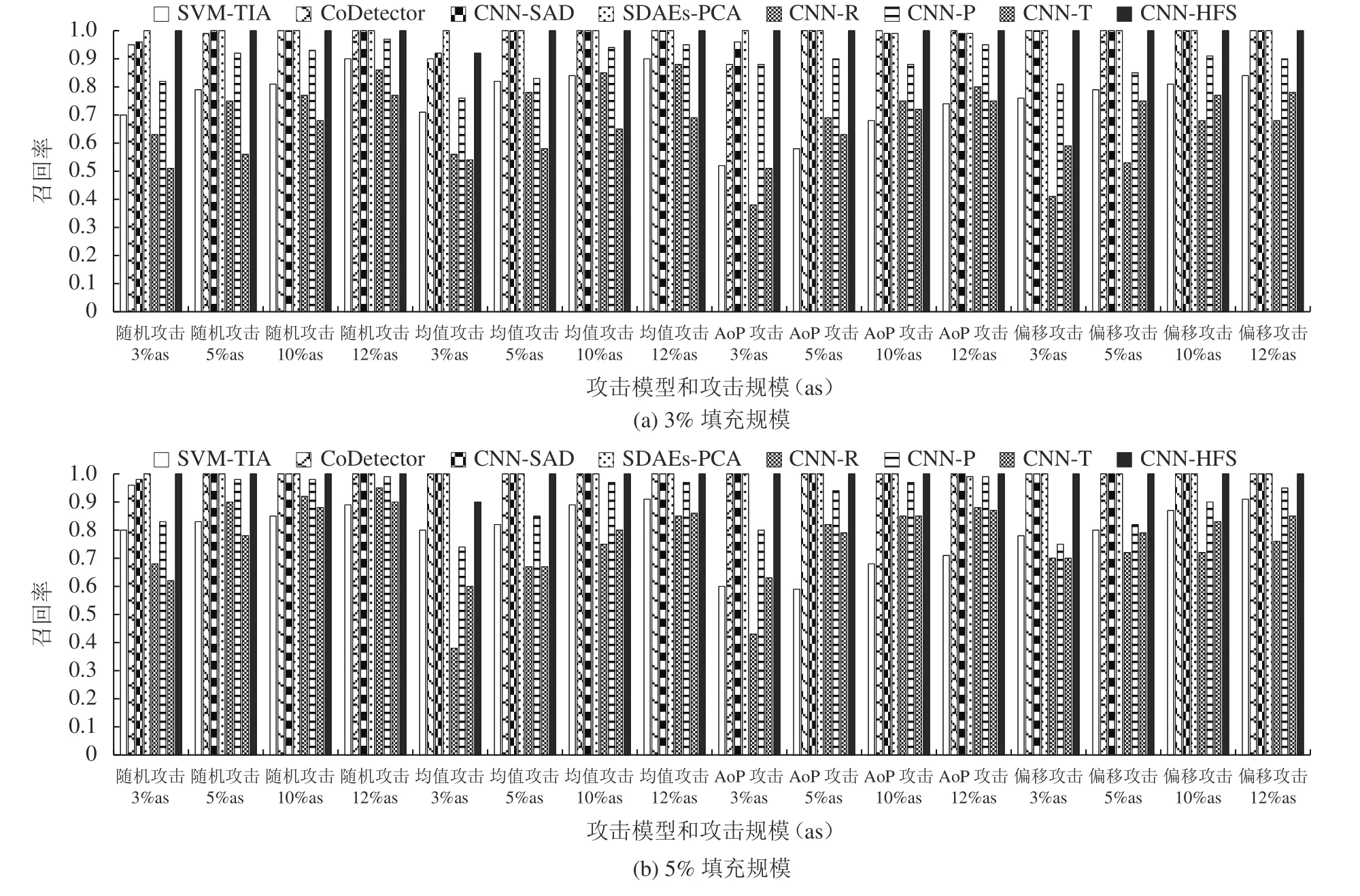
图5 8种检测方法在MovieLens 1M数据集上的召回率对比Fig. 5 Comparison of recall for eight detection methods on MovieLens 1M dataset
将上述8种检测方法在MovieLens 1M数据集中4种攻击模型下的F1-measure值进行对比,实验结果如图6所示。
从图6可看出,CNN-HFS方法在上述8种检测方法中均具有最高的F1-measure值,明显优于基于单一视角的CNN-R、CNN-P和CNN-T方法。主要原因是CNN-HFS方法充分利用了用户的多角度特征。提升了分类效果。这些结果表明,在MovieLens 1M数据集上,CNN-HFS方法能有效检测出不同类型的攻击概貌,并且比其他对比方法具有更优异的检测性能。
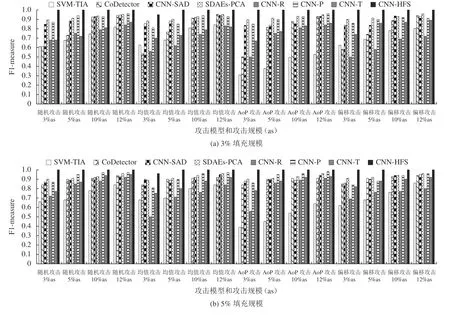
图6 8种检测方法在MovieLens 1M数据集上的F1-measure值对比Fig. 6 Comparison of F1-measure for eight detection methods on MovieLens 1M dataset
3.3.2 Amazon数据集上的检测结果及分析
将8种检测方法在Amazon数据集上的检测性能对比,实验结果如表1所示。
表1 8种方法在Amazon数据集上检测性能对比
Tab. 1 Comparison of detection performance for eight methods on Amazon dataset
方法 召回率 精确率 F1-measure值SVM-TIA 0.69 0.72 0.70 CoDetector 0.82 0.80 0.81 CNN-SAD 0.78 0.73 0.75 SDAEs-PCA 0.88 0.76 0.82 CNN-R 0.73 0.65 0.69 CNN-P 0.84 0.77 0.80 CNN-T 0.64 0.54 0.58 CNN-HFS 0.88 0.82 0.85
由表1可以看出:CNN-HFS方法在Amazon数据集上的精确率、召回率和F1-measure值分别为0.82、0.88和0.85,优于其他对比方法。在其他方法中,CNNT方法的检测性能最低,这是因为该数据集上攻击用户和真实用户的评分数量均较少,且攻击用户的评分时间跨度也较大,这使得真实用户和攻击用户在时间矩阵上的分类效果不够理想。而CNN-HFS方法利用多角度特征提取和决策的方式降低了数据稀疏性的影响。SVM-TIA方法的召回率仅高于CNN-T方法,远低于CNN-HFS方法,原因是有些目标项目上的评分数量较少,部分目标项目不能被发现,从而导致一些攻击概貌被误判为真实概貌。CNN-SAD和CNNR方法的精确率偏低,表明仅基于评分值矩阵会使得有些真实概貌被误识别为攻击概貌。相较而言,CoDetector和SDAEs-PCA方法的检测性能优于SVMTIA、CNN-SAD、CNN-T和CNN-R方法,表明Amazon数据集上攻击用户和真实用户有更复杂的行为差异。尽管SDAEs-PCA方法能达到和CNN-HFS方法同样的召回率,但在精确率和F1-measure值上仍低于CNNHFS方法。由于攻击用户和真实用户在项目选择上的差异,CNN-P方法在该数据集上的精确率、召回率和F1-measure值均高于CNN-T和CNN-R方法,但仍低于CNN-HFS方法。这些结果表明,引入犹豫模糊决策的CNN-HFS方法的检测性能明显优于单一决策的CNNR、CNN-T和CNN-P方法,并且同样超过了其他对比方法的检测性能。
4 结 论
基于自动特征学习的欺诈攻击检测是近来推荐系统安全领域的热点,为此本文提出了基于卷积神经网络和犹豫模糊集决策的攻击检测方法。受CNN在图像分类问题中的启发,首先,将每个用户在单一视角下的评分概貌转化为2维矩阵,采用双三次插值算法对转化后的稀疏矩阵进行降维;然后,训练对应视角下的CNN分类器,计算测试集中每个用户的攻击隶属度;最后,基于多视角下用户的攻击隶属度,利用犹豫模糊距离的多属性决策识别出攻击用户。MovieLens 1M和Amazon数据集上的实验表明,本文所提CNN-HFS方法能达到比所选取的经典对比方法更优的检测性能。
由于恶意用户为逃避检测,在实施攻击的过程中往往会更侧重于模拟正常用户的历史行为,这使得当攻击规模较小时,利用CNN学习到的分类特征不够明显,两类用户隶属度界限不够清晰,导致检测性能一定程度上的降低。因此,在未来的工作中,将寻找更加有效的高维特征学习方法,进一步提高检测方法在小攻击规模下的泛化能力。此外,在实验中也发现,真实数据集中存在一些评分数量过少的用户,评分数量较少直接影响对这类用户的行为分析,因此,下一步工作中,也将对此类攻击用户展开进一步研究。
