基于情感分析和随机森林的中国电视剧产业研究
2022-05-25李坤琪李晓峰宋卓远杨秀璋罗子江
李坤琪,李晓峰,袁 杰,杨 鑫,赵 凯,宋卓远,杨秀璋,罗子江
(贵州财经大学信息学院,贵阳 550025)
0 引言
随着人们物质生活质量的提高,大众精神文化上的需求也在日益增加,观看电视剧已成为人们日常生活中一种不可或缺的娱乐休闲方式。近年来,中国电视剧产业发展良好,电视剧收视比重由2017年的30.9%提升至2018年的32%;2018年中国网络视频用户规模达6.12亿,较上一年增长5.8%。同时,随着互联网技术的迅猛发展,人们更愿意从网络渠道搜寻优质电视剧,并在观看后参与对其的评论和打分,进而表达自己的态度和情感。在这些电视剧数据中蕴藏着影响制片方决策和用户观看的价值信息,因此,对电视剧的相关信息进行有效挖掘十分必要。
然而,国内外对电视剧等影视作品进行数据挖掘等深层次的研究相对较少,如王晓东等基于文献资料和对比研究的方法,对中国电视剧市场的现状进行研究,并针对存在的问题提出对策和建议。Pang等首次通过机器学习实现对电影评论的情感分类,并证明SVM模型的分类效果最佳。但这些研究方法较为单一,难以发现数据中更多的潜在规律,并且没有将用户情绪进行多维度的细致甄别和应用。
针对以上问题,本文提出一种基于情感分析和随机森林的研究方法,并结合共词和可视化技术对中、韩、美、英、日5国的电视剧数据进行详尽分析。通过构建电视剧领域情感词典,实现从剧评中有效提取观众的情绪诉求和分布状态;借助共词分析来计算各演员间的合作关联度,明确不同演员阵营;利用随机森林分类算法预测电视剧口碑好坏,进而实现优质电视剧的智能推荐。
1 中国电视剧产业相关研究进展
电视剧作为一种文化产品,早已紧密融入到人们的生活中,并发挥着寓教于乐、以文化人的作用。目前,在互联网的推动下,电视剧的传播和收看方式均发生改变,网络剧逐渐被大众所青睐。据艺恩咨询数据显示,2018年上线网络剧286部,较2017年的225部增加了27%,播放量呈现增长态势。2016年6月国家广电总局发布《关于进一步加快广播电视媒体与新兴媒体融合发展的意见》,提出加强网络剧的创作。网络剧的崛起拓宽了市场需求,并为电视剧产业注入新鲜力量。
与此同时,随着云计算、互联网的蓬勃发展,网络数据呈爆炸式增长,大数据及人工智能等技术迅速兴起并广泛应用于各个领域,改变了人们以往的生活方式,其中电视剧的评论、主演及口碑等因素极大影响着观众们的择剧意愿,因此通过数据挖掘等技术来优化中国电视剧产业,进而打造出符合大众需求的优质电视剧显得尤为重要。
当前国内外关于电视剧研究的方法主要有统计分析、机器学习、情感分析和口碑挖掘等。在电视剧数据分析上,梁文凤以网络改编剧的观众为研究对象,借助SPSS统计工具对观众的收视行为、忠诚度、满意度及产品涉入度之间的关系进行深入分析。朱寒婷等提出一种在首播前预测电视剧流行度的方法,通过时间序列和多元线性回归模型对搜索数据展开预测,并取得良好效果。
在剧评情感分析上,冯悦悦利用doc2vec词嵌入技术对已标记评论进行词向量训练,并在此基础上实现未标记评论的情感预测。陈浩然等通过情感词典和节目要素词典对综艺弹幕进行挖掘,证明观众情感值和对节目的认可度之间具有一定相关性。
在口碑挖掘上,朱琳等从口碑主体、交流介质、讨论内容三个方面对中国电视剧网络口碑形成的影响因素进行深入挖掘。苑清敏等基于口碑营销理论和实证分析,构建了网络口碑对消费者观看选择的结构模型。
因此,本文在已有方法的基础上,将情感分析、随机森林和共词分析等技术进行结合并加以创新,从多个维度去挖掘电视剧的风格类型、文化差异、观众情绪、参演人员和质量口碑之间的关联及内在规律,以期能更好地推动中国电视剧产业的健康发展。
2 中国电视剧产业的研究思路及方法
2.1 整体思路
本文研究的整体思路框架如图1所示。

图1 电视剧数据分析整体思路
2.2 数据获取
本文数据源自豆瓣网,借助八爪鱼数据采集器实现中、韩、美、英、日五国热度前10部电视剧评论和前100部剧集详细信息的获取。其中,共采集评论11000条,剔除无效及重复评论,得到有效评论10768条,和五国的500条剧集信息一同存储至Excel中。
2.3 数据预处理
为使实验结果最佳,分析前还需对数据进行预处理操作,以保证数据质量,具体操作如下:
2.3.1 数据清洗
旨在使数据更加规范、详细和可靠。针对数据缺失问题,文中参照百度百科进行手动填充,此外,对极个别异常值数据进行剔除处理。
2.3.2 剔除停用词
评论内容中常常包含大量无意义的词语和符号,如“的”“等”“…”“/”等,会给分析带来影响,因此,本文构建停用词表对其进行过滤去除。
2.3.3 中文分词
实验调用Python内的中文分词库来完成此项操作。同时,分词中会出现词语误判现象,如“不忍直视”可能在分词后会变为“不忍”和“直视”两个词语。为避免此类情况,文中增加了自定义词典,进而提升分词精度。
2.4 情感分析
情感分析是对文本内容中的情绪进行识别、抽取、分析及推理的研究。本文采用词典匹配模式来辨别、提炼用户评论中的情感词,并据其所在词典内的情感类别进行统计分析。实验中情感词典选用的是大连理工大学情感词汇库,该词典将情感细致划分成“乐”“好”“惊”“怒”“哀”“惧”“恶”7类,能够较好满足实验需求。此外,运用Word2vec模型来实现情感词典的扩充。
2.5 随机森林算法
随机森林是在多个决策树的基础上进阶而成的集成学习算法,属于监督学习,其内每棵决策树为一个弱分类器。汇集多棵决策树的随机森林可以并行化运算,进而提升整体的分类性能。本研究将从Sklearn机器学习包中调用随机森林算法对各国电视剧口碑好坏进行预测。
3 实验分析及结果评估
3.1 电视剧领域词典构建
近年来,随着影视网络的不断发展,各种网络新词层出不穷,这类词语往往包含独特的情感内涵,不能被忽略,然而基础情感词典中并没有更新此类词语,因此,本文采用Word2vec模型进行电视剧专属领域的词典构建,基本步骤如下。
(1)对各国电视剧评论数据进行结巴分词、停用词剔除、词性标注和训练词向量等操作;
(2)将分词后的情感词按词频降序排列,从中挑选前50个词语作为情感种子词;
(3)通过Word2vec模型寻找与情感种子词相关联的候选词,并于基础词典中完成重复值筛选,进而扩充、完善情感词典。
为使电视剧评论的情感分析效果最佳,实验中由3名相关专业研究生对候选词进行情感类别标注,并从结果中挑选两次及以上的相同结果作为词最终的情感类别,标注不同的,以3人商讨后的结果为准。最后将93个候选词和相应的情感类别加入情感词典,完成电视剧领域专属情感词典的构造。
经扩展后的领域词典在性能上得到较大提升。以《庆余年》为例,图2是扩展前后两种词典对其评论的情感分析对比图,从中发现,在7个维度上领域词典的情感词识别度均有不同程度的提高,尤其在“乐”“好”“恶”3个维度上效果更为显著,为后续分析奠定了基础。
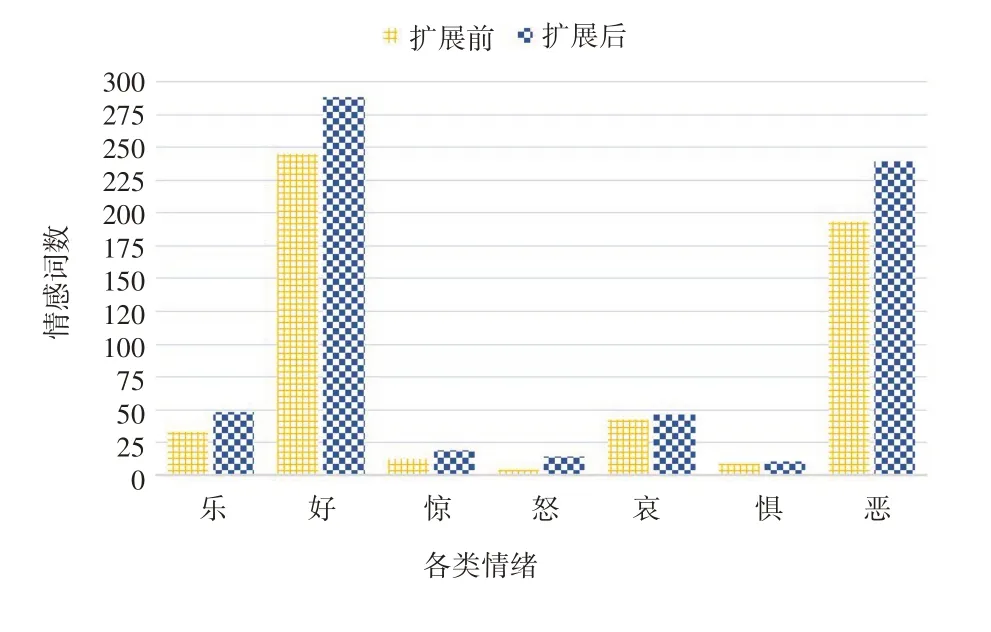
图2 《庆余年》评论中两种词典的性能比较
3.2 电视剧评论情感分析
对剧评进行细粒度情感研究,可以使投资方和制片人更好地获悉广大观众的确切需求,从而站在观众的视角描述电视剧,进而实现观众情绪分析、剧集风格对比、文化差异比较等实际应用。
3.2.1 观众情绪分析
在基于领域词典的剧评情感分析方面,同样以诙谐幽默的《庆余年》为例,剧评内容情感分布如图2所示。由图2可知,该剧以正向欢快的情绪(乐、好)为主,同时亦伴随着一定的负面情绪(恶、怒)和些许悲伤情绪(哀),观众评论中情绪和剧集内容所呈现情感状态十分吻合。但具体到单条评论,文中随机抽取两条个例,并将其情感分布用饼图形式加以展现(见图3),显然图3(a)的该观众感受到的更多是美好和温暖,而图3(b)的观众感受却是厌恶、悲伤和恐惧。借助可视化,能够清晰地洞悉观众在情绪感知上的差异。
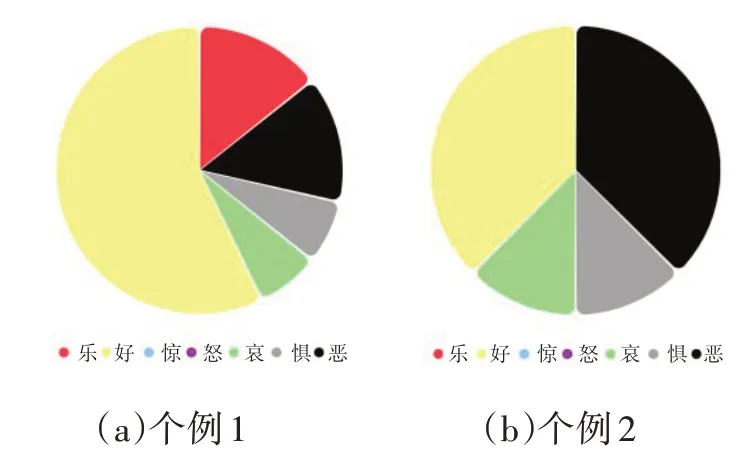
图3 《庆余年》个例评论情感分布
3.2.2 剧集风格对比
电视剧风格类型的不同,带给观众们的情绪感知亦有差异。图4为热度前10部国剧的评论细粒度情绪分布对比图,细致地呈现出观众在不同电视剧上的感受。图4显示,《三生三世枕上书》《下一站是幸福》《锦衣之下》的“乐”“好”情绪占比较高,其中《下一站是幸福》居首,说明观众较于偏爱这类爱情、青春偶像等题材电视剧,究其原因,是该类型剧情较为迎合观众的审美期待,呼应了人们的情感生活;此外,《大明风华》《鹤唳华亭》《庆余年》中“恶”的情绪占比较大;《鹤唳华亭》《锦衣之下》《将夜2》的“哀”的情绪占比较多;而《大明风华》《鹤唳华亭》《唐人街探案》的“怒”的情绪占比较高,表明观众对《大明风华》《鹤唳华亭》等历史古装剧持消极态度较多;同时还可以发现观众对《锦衣之下》的感知呈现两极分化,对《鹤唳华亭》的情绪丰富,各占比均较高,说明观众对其争议较大,而《唐人街探案》的“惧”情绪占比最高,这与其悬疑推理剧的风格十分符合。

图4 10部国剧的用户评论情感分布
3.2.3 国度间剧集差异比较
图5为五国电视剧评论的用户情绪分布图,由图5可知,用户对各国剧评的情绪感知在整体上呈现为正面情感,这说明国内大多观众对于英、美、日、韩4国电视剧的内容较为认可,亦表明我国的影视市场包容性强,对差异性文化接受度高等特点。然而在多维度的情绪分布中,5国剧集又有明显区别,如美剧和英剧中“哀”“惧”情绪都占比较多,但美剧更偏向于“怒”,英剧更偏向于“惊”,符合实际中美剧、英剧的剧情编排。日剧中“惊”和“惧”的情感较为明显。韩剧中“乐”“好”“哀”居多,与生活中观众喜爱其唯美浪漫、催人泪下情节的普遍现象基本一致,这是韩剧剧情与人们内心情感产生共鸣的缘故。通过对不同国家的影视评论进行情感挖掘,有助于把握各国的影视编制特色,进一步了解其各自的文化差异,从而打造出极具自身魅力的精品电视剧。
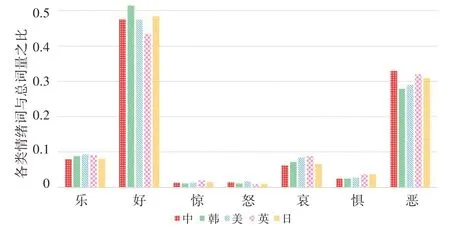
图5 五国剧评各类情绪分布
3.3 共词分析演员关系图谱
演员是观众与剧集角色情智交流的桥梁,一部优秀电视剧的产生需要合适演员来将特定角色形象演绎到位,因此演员人选不仅是电视剧成败的关键还是观众择剧时考虑的重要因素。为了深入探究各演员间合作关系及其潜在规律,本文采用共词分析法计算豆瓣电视剧中各国热度前100部的所有演员共现情况,计算规则是:两位演员同时出演一部电视剧就视为共现,并存在一条关系边,反之则没有。
以国剧为例,运用Gephi软件绘制演员关系知识图谱,结果如图6所示,共挖掘出核心演员200名和关系边4864条。图中节点代表演员,其颜色为相似类别,大小表示演员的重要程度,这可以更好展现演员间的关联情况。图6显示,该图谱中演员分成不同阵营,各阵营相对独立但彼此又间互相联系,其中“杨紫”“迪丽热巴”“易烊千玺”“李现”等新生代演员和“王劲松”“王永泉”“靳东”“王凯”等实力派演员活跃于荧屏,深受广大观众喜爱。同时,推荐制剧方和这些演员合作,以提高剧集收视率。

图6 豆瓣国剧演员关系图谱
3.4 随机森林分类算法
本文将对豆瓣网中各国热度前100部的电视剧(共500部)进行随机森林分类实验,并根据电视剧的豆瓣评分对其划分成三类,即口碑较差、口碑中等和口碑较好,进而实现电视剧质量的预测。其中将豆瓣评分位于区间[0,6)、[6,8)、[8,10]的电视剧分别定义为口碑较差、中等、较好3个等级(满分10分)。该数据集共包含9个特征,如表1所示。
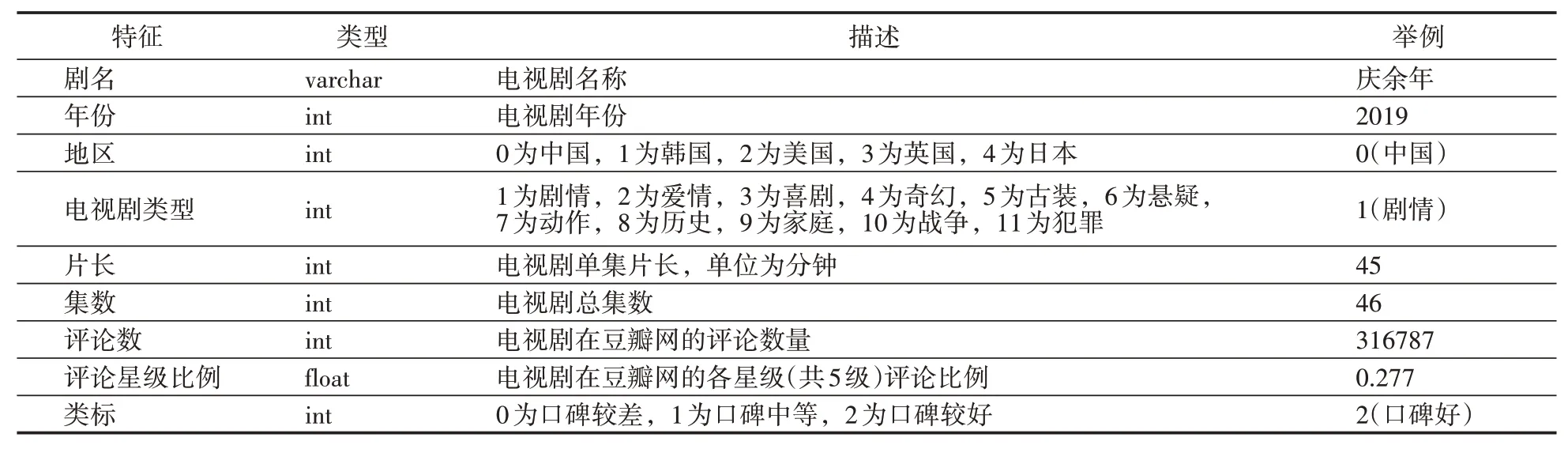
表1 数据集特征
为保证实验公平有效,文中将数据集按4∶1进行随机划分,以400部电视剧作为训练集,100电视剧作为测试集。并基于随机森林进行口碑等级预测,最后选取准确率、召回率、特征值三个指标评估算法的分类性能。实验结果如表2所示。
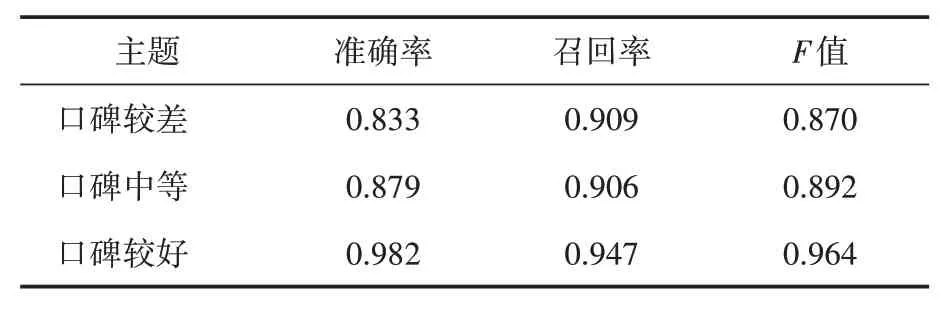
表2 随机森林分类结果
从表2可知,口碑较好的电视剧实验结果最佳,准确率为0.982,召回率为0.947,值为0.946。
4 结语
本文以豆瓣网电视剧数据为研究对象,借助情感词典、共词分析和随机森林等方法实现观众细粒度情绪分析、演员间关系挖掘以及电视剧口碑好坏预测,通过可视化技术将结果多维度呈现。得出以下结论。
(1)构建的领域词典在性能上得到较大提升,可以从电视剧评论中有效提取出观众的情绪诉求和分布状态,并加以可视化展现,能够为影视业提供一种新的分析视角。
(2)通过对电视剧评论的情感分析得出:观众评论中蕴含的情绪和剧集内容所呈现的情感状态具有一致性。同时,观众的情感感知亦存在差异,需更更深入地获悉观众在评论中的情感需求。
(3)我国电视剧市场呈现兼容并包的良好局面,韩、英、美、日等国剧集的加入,极大丰富了广大观众的文化娱乐生活。五国剧集风格不尽相同、各有所长,与观众的情绪分布具有一定的相关性。同时,我国也需吸取各国剧集的优点,并加强自身的创新能力。
(4)共词分析的演员合作关系图谱共发掘出200名核心演员与4864条关系,其中相似度较高的演员被聚类为同一阵营,各阵营相对独立但彼此间又互相关联,直观地展现出演员们的合作现状,这可以为制剧方在选择合适演员方面提供一定的参考价值。
(5)随机森林算法对豆瓣网各国共500部的电视剧进行口碑预测分析,并将结果分为口碑较差、中等、较好三类。经验证,整体预测效果良好,是向观众推荐优秀剧集的有效方法。
总之,本文研究方法能够有效挖掘出我国电视剧数据中蕴藏的价值信息,对于打造出更符合大众口味的优秀电视剧具有重要的理论意义和实际价值。
