基于深度学习的移动端安全帽检测系统设计与实现
2022-05-23杨雪陈刚
杨 雪 陈 刚
中通服咨询设计研究院有限公司
0 引言
近年来,随着我国基础设施的大量建设,工地上工人的安全问题也日益凸显。据统计,在工地安全事故中,由于工人未正确佩戴安全帽,高空坠物撞击引起的死伤事故时有发生。为改善这一情况,在工地上对工人进行安全帽的检测,对保障工人的生命安全具有重要意义。
目前,许多专家学者提出各种方法对工地上工人是否佩戴安全帽进行检测。有人提出基于ResNet50-SSD的安全帽佩戴状态检测,但该方法精度欠缺,误报率较高。有人提出的基于改进Tiny-yolov3方法能对工人是否佩戴安全帽进行识别,但是受人体复杂运动的影响,导致检测率也较低。还有人提出基于改进Yolov4-Tiny网络模型的安全帽检测,但受光线、目标大小因素影响较大,准确率同样有所欠缺。且以上系统都不具备便于移动的特点。
针对以上问题,考虑到施工环境的复杂性,本设计提出一种基于YOLOv4的移动端安全帽检测系统,在公开数据集上训练YOLOv4网络,将训练好的权重网络移植到嵌入式移动端平台,最终实现安全帽的佩戴检测。
1 YOLOv4介绍
1.1 网络结构
YOLOv4相较于YOLO系列的前几代版本,其速度更快,精度更高。这得益于YOLO网络结构的不断优化与改进。YOLO目标检测算法衍生到第四代版本YOLOv4,其网络结构主要由主干特征提取网络(CSPDarknet53),空间金字塔池(SPP),路径聚合网络(PANet),YOLOv3检测头组成。
(1)CSPDarknet53
CSPDarknet53是在YOLOv3主干提取网络Darknet53基础上,借鉴CSPNet(Cross Stage Paritial Network)的经验而形成的新的网络结构。该结构共有72层卷积层。包含5个CSP模块,每个CSP模块前面的卷积核大小都是3*3,步长为2。因此可以起到下采样作用。CSPNet模块结构如图1所示。基础层的特征映射按照通道维度拆分为两部分,然后通过跨阶段层次结构进行拼接。该结构可以获取更丰富的梯度融合信息以增强网络的学习能力,同时在保证精度的情况下降低计算量。
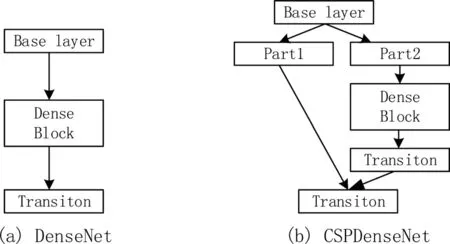
图1 CSP模块
(2)空间金字塔池
空间金字塔池(SPP)结构能够实现局部特征和全局特征的融合,有效增加感受野,丰富最终特征图的表达能力。YOLOv4的SPP结构如图2所示,在输入图像大小为608*608的情况下,经过CSPDarknet53特征提取网络,得到最终特征图大小为19*19。对该特征图层进行最大池化(maxpool),卷积核大小分别为13*13、9*9,5*5、1*1。池化时采用padding操作,移动步长为1,以保证池化后的特征图大小仍为13*13。然后将不同池化大小得到的特征图进行拼接。
图2 SPP结构
(3)路径聚合网络
YOLOv4中采用路径聚合网络(PANet)替换YOLOv3中的特征金字塔网络(FPN)进行多通道特征融合。FPN算法中,浅层的特征传递到顶层要经过几十甚至一百多个网络层,显然路径太长会丢失部分浅层特征。在PANet中,浅层信息从P2沿着自下而上的路径增强传递到顶层,该自下而上的路径增强的层数不到10层,极大缩短较低层与顶层之间的信息路径,能较好地保留浅层特征信息,使得网络学习到更加复杂以及具有不变性的特征。如图3所示。

图3 PANet结构
1.2 损失函数
图片输入到网络后会分成S*S个网格,每个网格产生B个候选框,每个候选框最终会得到相应的bounding box。在这过程中,需要利用损失函数确定具体的bounding box计算误差更新权重。YOLOv4的损失函数LOSS由回归损失Lciou,置信度损失Lconf,分类损失Lclass三部分构成,具体如公式(1)所示。

2 实验
2.1 数据集
数据集采用roboflow上的开源安全帽数据集,该数据集是由东北大学提供,共包含7035张图片。均在工地拍摄采集。本设计只区分工作场所中遵守安全规则的工人和不遵守安全规则的工人,因此标注安全帽(helmet)和人头(head)两类标签。训练集图片划分5628张,测试集图片划分1407张。该数据集的示例如图4所示。

图4 示例图片
2.2 模型训练
该YOLOv4网络模型的训练采用Darknet深度学习框架,训练平台为GPU。GPU配置信息为GeForce GTX 1080 Ti,拥有11GB GDDR5X显存。网络训练输入图片大小为416*416,每次迭代训练图片64张,分16批次。网络其他参数配置如表1所示,在网络达到训练次数为20000次时,学习率调整为0.0001,在达到训练次数为30000时,学习率为0.00001。
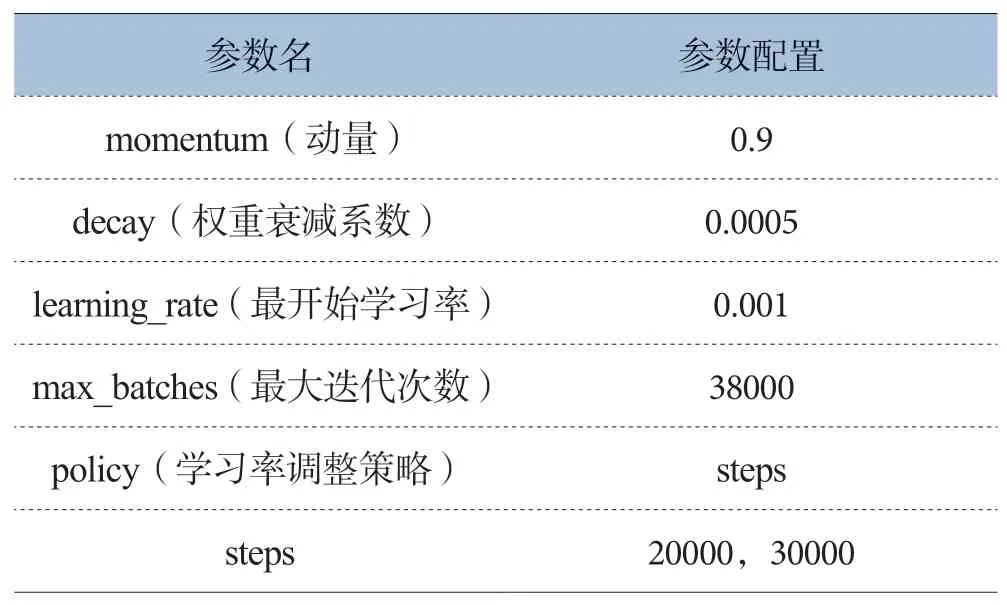
表1 网络模型训练参数配置表
2.3 模型过程可视化
将安全帽数据集制作完成与网络参数配置完成后,在Darknet深度学习框架下训练YOLOv4网络。将训练过程中的日志保存,根据保存的日志信息绘制损失值变化。损失值是衡量预测值与真实值之间的距离,损失值计算如公式(1)所示,其值越小,表示网络的预测值越接近真实值。训练过程损失值变化如图5所示。随着网络迭代次数的增加,损失值不断减少,在网络迭代到35000次后,损失值稳定在0.3左右,模型已经开始收敛,直至迭代到38000次,并保存迭代38000次后的网络权重值。最终网络的mAP为88.2%。

图5 训练过程损失函数
3 嵌入式平台实验
3.1 Jetson Nano介绍
Jetson Nano嵌入式平台是NVIDIA公司发布的一款主打低功耗的人工智能计算机。该平台采用CPU+GPU异构结构,CPU为四核Cortex-A57,GPU采用规模最小的Maxwell架构显卡,拥有128个CUDA单元。同时该平台还拥有4GB LPDDR4内存。该嵌入式平台可以提供472 GFLOPS的浮点运算能力,能并行运行神经网络,因此,该平台可以运用到图像分类、目标识别、分割、语音处理等领域。为了快速构建AI项目,NVIDIA公司为该平台提供一套开发者套件JetPack,该套件中包括Ubuntu18.04操作系统和TensorRT。可以根据开发者需要安装Darknet、Caffe等深度学习框架进行AI项目的开发。
3.2 实验结果
将训练完之后的网络权重文件部署到Jetson Nano移动端平台上,配置该平台深度学习环境。进行安全帽识别的实验,如图6所示。

图6 在Jetson Nano嵌入式平台实现场景
图7展示了安全帽部分测试集在Jetson Nano移动端平台的检测效果,选取的场景包含检测角度不佳、目标过小、目标密集等不同的复杂场景。从检测效果来看,YOLOv4网络在嵌入式平台表现出良好的检测性能,能够准确区分工人是否正确佩戴安全帽,预测一帧图片也只需0.33s,能够满足工地实时性要求。

图7 检测结果
3.3 实验结果比较
本设计提出的基于Yolov4的检测方法mAP达88.2%,相较于文献提出的基于ResNet-SSD算法的mAP,本方法mAP提高了9.7%;相较于文献提出的基于改进yolov3-Tiny算法的mAP,本方法mAP提高了44%;相较于文献提出的基于改进yolov4-Tiny算法的mAP,本方法mAP提高了8.7%,准确率达到一定的提升,结果如表2所示。且其他文献提出的安全帽检测系统都是基于PC端实现,不能较好落地,本设计不仅在PC端实现安全帽检测,也成功移植嵌入式平台,实现每帧图像0.33s的检测速度,也为后续目标识别算法的移植提供参考。

表2 各算法检测结果比较
4 结束语
本设计提出一种基于嵌入式平台的安全帽检测系统,便于移动与装卸。试验结果表明,YOLOv4网络的损失值稳定在0.3左右,mAP达到88.2%。将网络部署在Jetson Nano嵌入式平台上,该平台能够准确实时地识别工人是否佩戴安全帽。该系统可用于施工场地工人安全帽佩戴情况的检测。
