精度矩阵置信区间在高维网络数据中的研究*
2022-05-23郑泽敏周慧婷
郑泽敏,周慧婷
(中国科学技术大学管理学院统计与金融系, 合肥 230026) (2020年4月15日收稿; 2020年6月28日收修改稿)
大数据时代为我们带来了海量的个体信息,这些个体间的联系构成了纵横交错的网络数据。网络数据涵盖了社交网络[1]、在线营销[2]、医疗数据[3]以及气候分析[4]等一系列当代应用。这些数据通常具有成千上万的维度,这就使得高维数据的作用越来越突出。研究这些高维网络数据间的联系具有非常实际的意义。图模型可以作为研究变量条件关联的一种工具[5]。在图模型中,图模型的条件独立性可以由它的精度(逆协方差)矩阵来确定[6]。在高斯图模型中,图模型的条件独立结构完全由精度矩阵的零元素来确定[7]。因此,挖掘网络数据变量间联系也就是恢复图模型的精度矩阵。
然而由于高维数据的出现,往往会出现变量大于样本容量的情形。在这种情况下,用样本协方差矩阵的逆来估计精度矩阵不再可行。即使可行,求解一个高维矩阵的逆,在内存和时间上的成本也是巨大的。这就使得高维图模型精度矩阵的求解成为各学者研究的热点。当前的研究主要集中在精度矩阵的点估计上[8-15]。我们知道,通过置信区间来评估估计量的精度是很重要的[16-17]。然而由于现有估计量抽样分布的复杂性,目前对高维稀疏精度矩阵的置信区间还很少涉及。
近年来,对于高维统计推断的研究主要转向高维线性和广义线性模型回归系数上[18-21]。特别是van de Geer等[19]对Lasso估计量进行KKT(Karush-Kuhn-Tucker)反转得到高维线性回归系数的渐近正态统计量。后来他们又将该方法推广到广义线性模型中。遵循文献[19]的思想,Jankov和van de Geer等[22]将这种消除惩罚偏差的思想运用到精度矩阵的统计推断中。他们通过对Glasso(graphical Lasso)[11]估计量进行KKT反转得到De-Glasso(De-sparsified graphical Lasso)统计量,并给出渐近正态性的理论保证,进而得到精度矩阵各个元素的置信区间。遵循这种KKT反转的思想,文献[23-24]都通过对精度矩阵点估计的似然函数KKT反转得到不同设定下的渐近正态统计量。还有一类统计推断方法是Ren等[14]提出的ANT(asymptotically normal estimation and then do thresholding)方法,它是每2个变量对剩余变量进行回归得到一个渐近正态估计量。
本文研究发现,置信区间的计算成本主要来自于精度矩阵的点估计。上述提出的第1类置信区间由于各自点估计具有复杂的似然函数以及需选择调优参数而计算不有效。第2类置信区间由于ANT点估计需要进行O(p2)次scaled Lasso回归而使得计算成本加大。当维度适中时,两类方法都可以有效地计算精度矩阵的置信区间,然而当维度逐渐增加时,上述方法的计算效率开始变低。为解决上述问题,本文受文献[22]渐近正态统计量的启发提出De-ISEE统计量,并给出对应元素的置信区间。
本文提出的De-ISEE统计量是ISEE点估计的简单运算,且ISEE估计量有成熟的算法,这使得De-ISEE统计量易于计算。相比较其他方法,De-ISEE方法由于ISEE点估计具有可伸缩、易调参等优点可处理超高维精度矩阵。从仿真实验中可以看出,De-ISEE方法得出的置信区间不仅覆盖率更接近于理想覆盖率,而且计算高效。并且本文将De-ISEE方法运用到核黄素数据集以及前列腺肿瘤基因表达数据集,发现De-ISEE方法很好地恢复了变量间的联系,这可作为研究基因学的一种辅助工具。
1 精度矩阵的置信区间
1.1 模型建立
选用高斯图模型来模拟网络数据。设X为p维服从多元高斯分布的随机变量,即
X=(x1,…,xp)T~N(μ,Σ*).
(1)
定义μ为p维均值向量,Σ*为协方差矩阵。设G=(V,E)为高斯无向图,V={x1,…,xp}为G的顶点集,E={(i,j)}为高斯图模型边的集合。xi与xj满足以下的性质
xi⊥xj|x-(i,j)⟺(i,j)∉E,
也就是xi和xj之间无边与xi和xj条件独立相互等价。

设X1,…,Xn∈p为独立同分布于(1)的样本。为方便计算,全文假设均值向量μ=0。
1.2 De-ISEE统计量
本节将基于ISEE估计量(innovated scalable efficient estimation)构造De-ISEE统计量。ISEE方法是由Fan和Lyu[15]提出,是为了高效地估计超高维精度矩阵的点估计。他们是受创新变换的启示,将估计精度矩阵的问题转化为大协方差矩阵估计问题。它的求解如下:
通过创新变换得到Y=Θ*X,则有Y~N(0,Θ*)成立。则估计Θ*的问题可转变为估计Y的协方差。为了估计Y,Fan等将长向量Y分解成小的子向量,即:
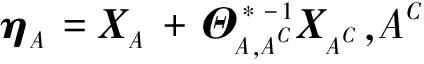
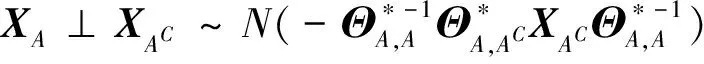
XA=XACCA+ηA,
(2)
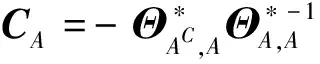
为估计残差向量ηA,用文献[25]提出的scaled Lasso惩罚回归的方法对模型(2)进行拟合。对于(2)中A的每个节点j,有
Xj=XACβj+ηj,
(3)
这里Xj,βj,ηj分别是XA,CA,ηA的第j个列向量。对(3)进行scaled Lasso惩罚回归:
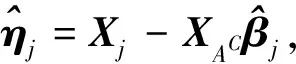
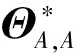
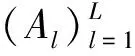
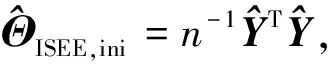
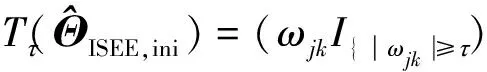
由于ISEE估计量计算步骤的复杂性,以致很难研究ISEE估计量的分布性质。为了构建精度矩阵Θ*基于ISEE估计量的置信区间,本文需要一个优良的统计量。为要消除正则化惩罚为ISEE估计量带来的偏差,本文受文献[19,22]构造去偏统计量的启发,基于文献[22]提出的渐近正态模型
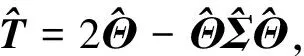
(4)
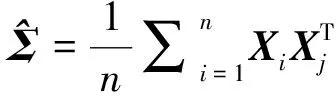
(5)
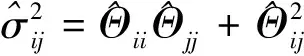
2 仿真实验
通过仿真实验来检验De-ISEE统计量对网络数据变量联系的恢复效果及计算效率。并与De-Glasso统计量[22]进行对比研究。
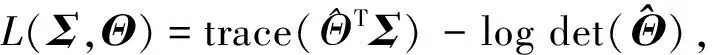
使用文献[22-24]使用的平均覆盖率指标来比较两种方法的覆盖准确性。分别为: ACS,ALS,ACSc,ALSc。其中ACS为在支撑集S上的平均覆盖率,它的定义为

表1分别展示维度p=200, 1 000, 2 000,ρ=0.3时,De-ISEE统计量与De-Glasso统计量构成的置信区间平均覆盖率的比较。当p=2 000时,由于De-Glasso统计量计算时间过长,为避免过多的计算损失,只计算De-ISEE统计量的平均覆盖率。
可以看出,当精度矩阵维度p
另一方面,De-ISEE方法在S上的平均覆盖率始终高于De-Glasso方法,而De-Glasso方法在SC上的平均覆盖率始终高于De-ISEE方法。这表明由De-Glasso方法恢复的图模型更容易丢失变量间联系。这不利于在海量信息中挖掘变量间联系。大数据时代促使网络数据的维度激增,例如在经济分析中,影响经济的因素越来越多,然而各个因素之间的联系却是广泛而又稀疏的。这就需要借助工具发现变量间联系,再针对性分析。De-ISEE统计量很好地恢复了图模型,由它得出的平均覆盖率更接近理想覆盖率。这也在一定程度上,弥补了De-ISEE方法平均置信区间长度长于De-Glasso方法平均置信区间长度这一缺陷。另外,平均置信区间长度也在某种程度上反映了样本的随机误差。
为验证De-ISEE统计量的稳定性,设置另一参数ρ= 0.4,计算结果见表2。
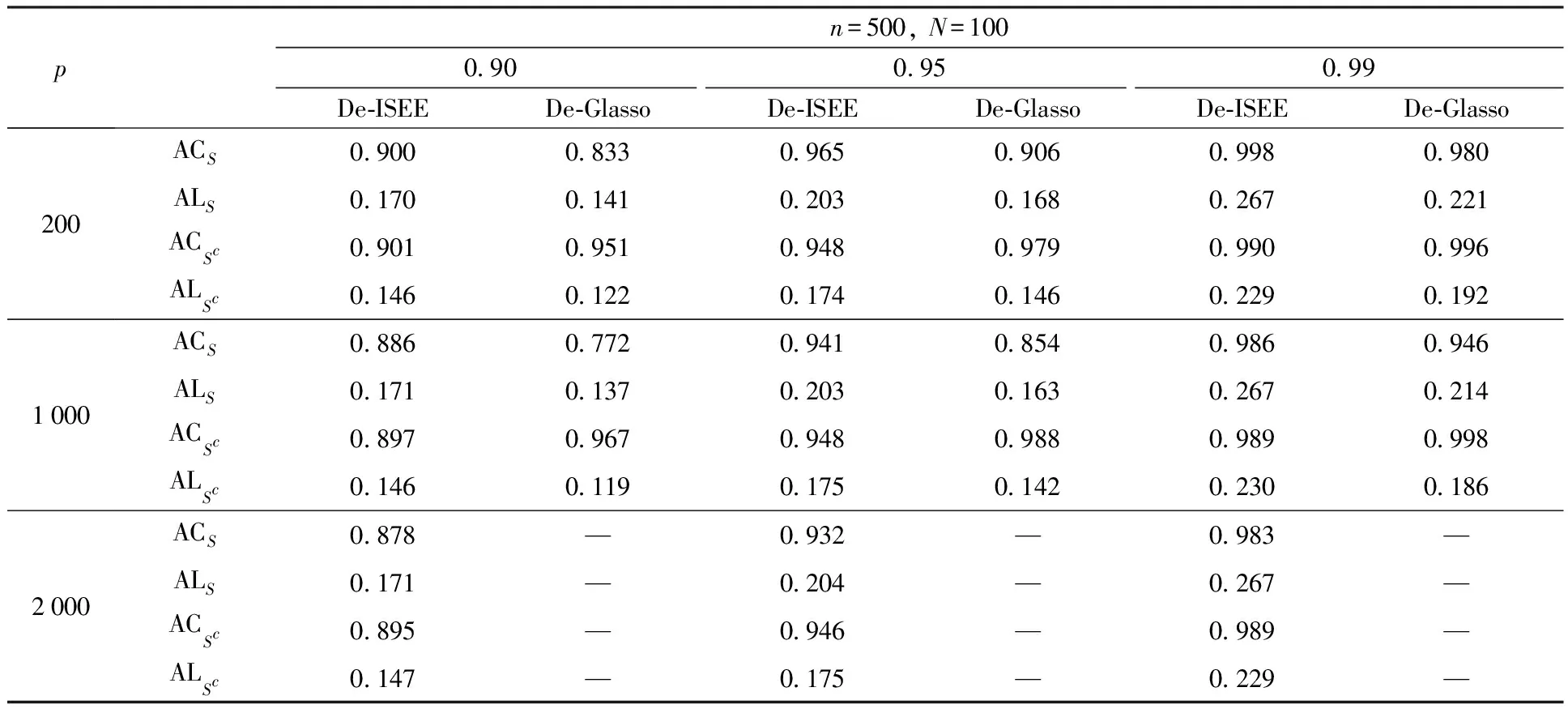
表1 ρ=0.3时, De-ISEE方法与De-Glasso方法平均覆盖率的比较Table 1 The comparision of average coverage for De-ISEE method and De-Glasso method when ρ=0.3
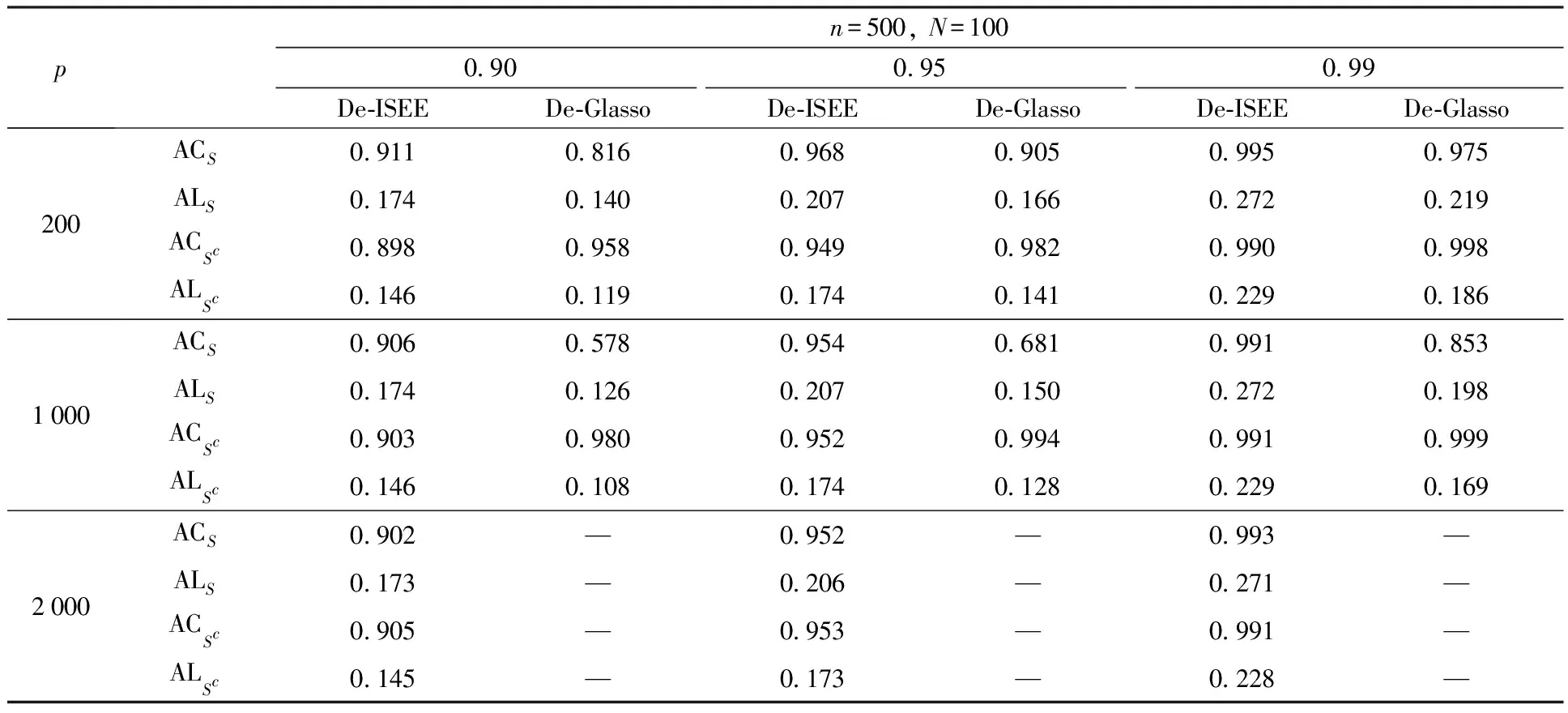
表2 ρ=0.4时,De-ISEE方法与De-Glasso方法平均覆盖率的比较Table 2 The comparision of average coverage for De-ISEE method and De-Glasso method when ρ=0.4
表2设置了一个更大的三对角矩阵参数值ρ。同理,为了节省时间与空间损失,在表2中,当p=2 000时,只计算De-ISEE方法的平均覆盖率。可以发现表2的结论与表1保持一致。并且相比较于表1,可发现当参数值ρ变大时,De-Glasso方法在S上的平均覆盖率明显变小,而De-ISEE统计量基本保持不变,可见De-ISEE方法不受参数值变化的影响,具有较高的稳定性。
为了比较计算效率,使用文献[15]使用的平均计算时间指标, 分别计算置信水平为1-α的De-ISEE方法和De-Glasso方法的CPU运行时间(s)对数的平均数。参数设置为n=500,ρ=0.3,α=0.05,N=100。计算结果为图1,x轴为维度p,y轴为CPU运行时间(s)对数的平均数。
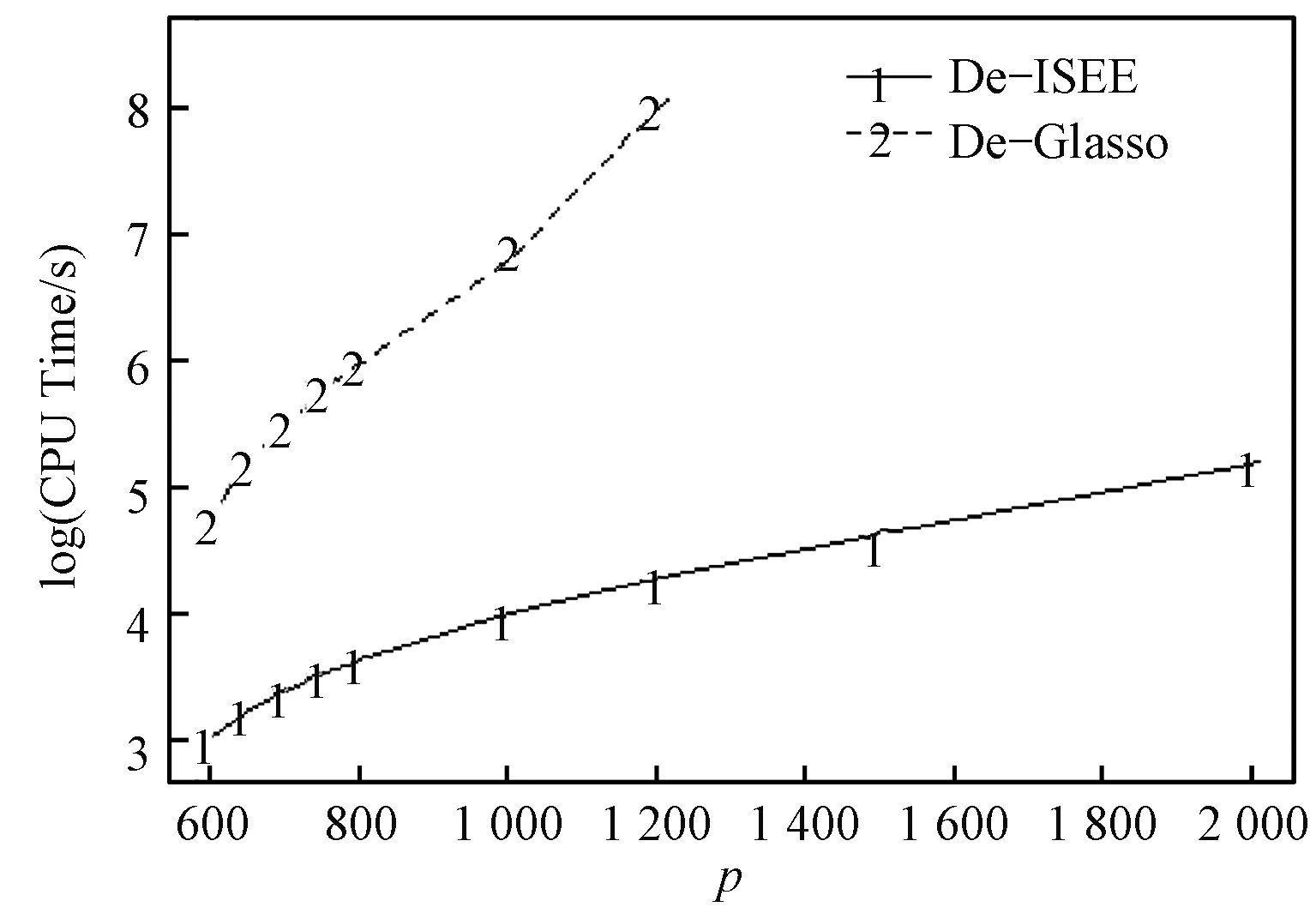
图1 De-ISEE与De-Glasso随着维度p增加的 CPU运行时间对数的平均数Fig.1 The average logarithm of CPU running times of De-ISEE and De-Glasso as dimensionality p increases
由图1可见,随着维度p的增加,De-ISEE的平均运行时间增长缓慢,而De-Glasso的平均运行时间增长快速。当维度很高时,De-Glasso方法甚至无法计算。
综上可见,通过比较De-ISEE方法与De-Glasso方法的平均覆盖率,可发现,在高维网络数据中,De-ISEE方法的平均覆盖率不随维度p以及参数值ρ的变化而显著变化,具有较高的稳定性。而De-Glasso方法的平均覆盖率却对维度p和参数值ρ的变化较为敏感。当精度矩阵的维度p变大时,De-ISEE方法依旧计算高效。在处理高维矩阵时,无论从平均覆盖率,还是平均运算时间来看,De-ISEE方法都比De-Glasso方法有效。
3 实例分析
将De-ISEE方法运用于实际网络数据,选用2个实际数据集,分别运用De-ISEE及De-Glasso方法来恢复网络数据间的联系。网络数据间的联系形成图模型,本节的目标是分别运用2种方法计算图模型精度矩阵的置信区间,比较它们恢复图模型的边以及各自运行时间。第1个数据集是由枯草芽孢杆菌产生的核黄素(维生素B2)数据集,可在hdi R包中获得。第2个数据集是前列腺肿瘤基因表达数据集(prostate tumor gene expression),它来自于spls R包。
对于这2个数据集,为了更方便地分析,选择前500个方差最大的变量进行建模。随后分离样本,用10个随机选择的观察值来估计500个变量的方差。再次利用估计的方差缩放剩余观察值的设计矩阵。在实例分析中,当计算De-ISEE统计量时,调优参数λ选用Fan和L[15]提出的λ=B/(n-1+B2)1/2,这里B定义为B=tq(1-n1/2/(2plogp),n-1),tq(a,m)为自由度为m、下分位数为α的t分布。在计算De-Glasso统计量时,与仿真实验同理,选用5折交叉验证选择调节参数。显著性水平都设为α=0.05。
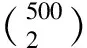
第2个数据集包含n=102个样本观察值以及p=6 033个变量。本节分别使用De-ISEE方法与De-Glasso方法计算置信区间以此来识别边。通过De-ISEE方法可识别出121条边为显著的,它的CPU运行时间为1.994 s。De-Glasso方法识别出28条边为显著的,它的CPU运行时间为4.013 s。通过对比再次发现,由De-Glasso统计量识别的边是De-ISEE识别边的子集。且De-ISEE方法的计算速度比De-Glasso方法快。
这样的结论与仿真实验类似,De-Glasso方法识别出的边集更稀疏,容易遗漏个体间的联系。而De-ISEE方法估计的边集基本涵盖真实边集。在个体数量逐渐增加的网络数据中,个体与个体之间的联系广泛而又稀疏,通过De-ISEE方法发现个体之间潜在的联系可以帮助研究者从庞大的数据信息中发现有用信息,进而有针对性地进行分析。在第2个数据集中,De-ISEE方法还可以作为分析人类基因的补充工具。
4 结论与展望
本文提出De-ISEE统计量,并且对其进行了仿真实验以及实例分析。与其他方法相比,由于ISEE点估计具有可伸缩、易调优等优点,De-ISEE统计量得出的平均覆盖率更接近于真实覆盖率,且计算更为快速,可以处理超高维矩阵。这对挖掘高维网络数据间的联系具有很重要的作用。例如在实例分析中分析的核黄素数据集以及前列腺肿瘤基因表达数据集,De-ISEE统计量可以精确恢复变量间的联系,从广泛的信息网中帮助研究者提取重要信息,也可作为研究人类基因联系的补充工具。
本文给出了De-ISEE统计量的实用价值,还尚需要一定的理论支撑,这将会是接下来研究的问题。此外,对图模型构建同时置信区间也将是我们进一步研究的问题。
